クラスタリング・コンパクション
クラスタリング・コンパクションは、大規模なコレクションの検索パフォーマンスを向上させ、コストを削減するために設計されています。このガイドでは、クラスタリング・コンパクションと、この機能による検索パフォーマンスの向上について説明します。
概要
Milvusは入力されたエンティティをコレクション内のセグメントに格納し、セグメントが一杯になるとそのセグメントを封印します。この場合、追加のエンティティを収容するために新しいセグメントが作成されます。その結果、エンティティはセグメント間で任意に分散される。この分散によって、Milvus は複数のセグメントを検索して、与えられたクエリベクトルに最も近いものを見つける必要がある。
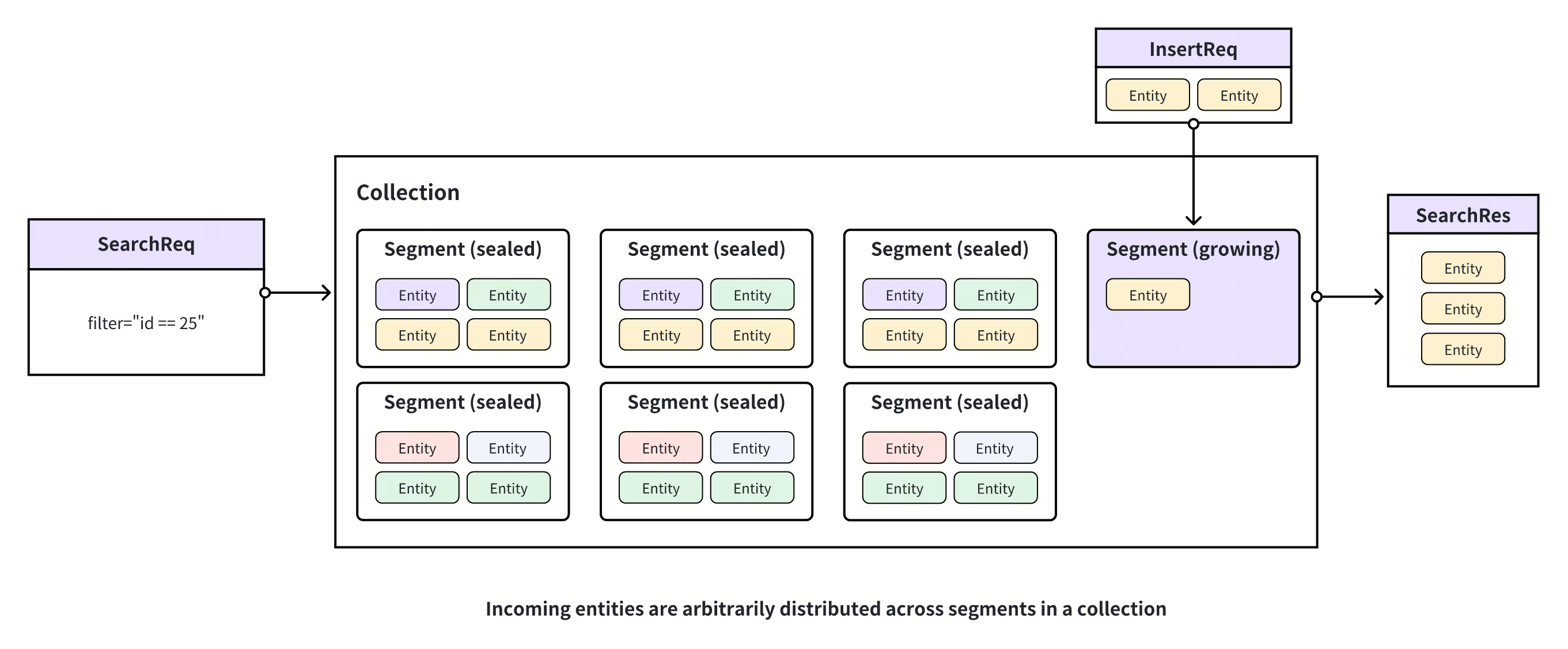 クラスタリングなしの場合
クラスタリングなしの場合
Milvus が特定のフィールドの値に基づいてエンティティをセグメント間に分散させることができれば、検索範囲をセグメント内に制限することができ、検索性能が向上します。
クラスタリングコンパクションはMilvusの機能で、スカラーフィールドの値に基づいてコレクション内のセグメント間でエンティティを再分配します。この機能を有効にするには、まずクラスタリングキーとしてスカラーフィールドを選択する必要があります。これにより、Milvusはクラスタリングキーの値が特定の範囲内にあるエンティティをセグメントに再分配することができます。クラスタリングコンパクションをトリガーすると、MilvusはPartitionStatsと呼ばれるグローバルインデックスを生成/更新し、セグメントとクラスタリングキー値のマッピング関係を記録します。
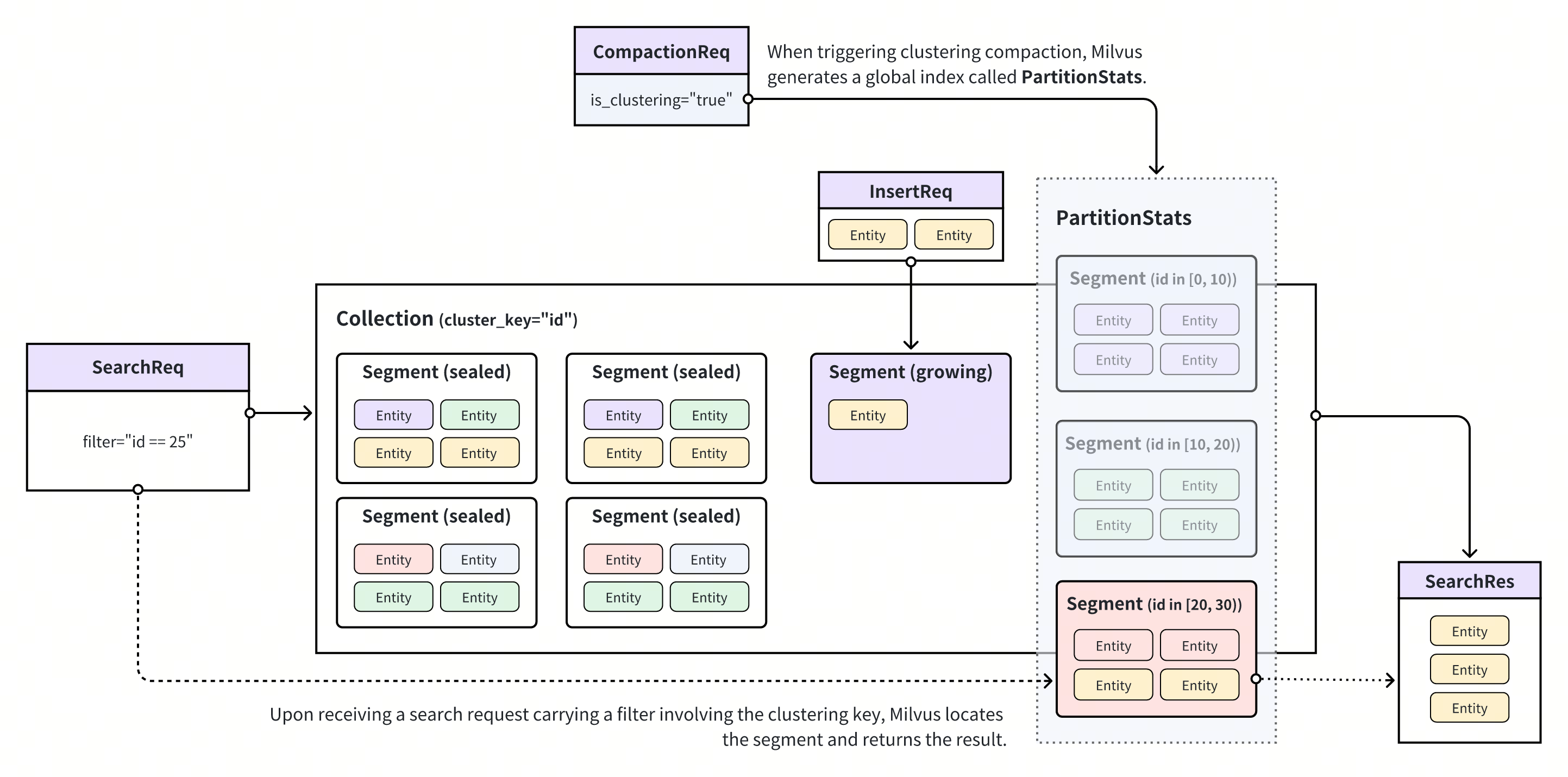 クラスタリングコンパクションの場合
クラスタリングコンパクションの場合
PartitionStatsを参照することで、Milvusはクラスタリングキー値を持つ検索/クエリリクエストを受信した際に無関係なデータを削除し、その値にマッピングされるセグメント内で検索範囲を制限することができ、検索パフォーマンスを向上させることができます。性能向上の詳細については、ベンチマークテストを参照してください。
クラスタリング・コンパクションの使用
MilvusのClustering Compaction機能は高度な設定が可能です。手動で起動させることも、Milvusが一定間隔で自動的に起動させるように設定することもできます。クラスタリングコンパクションを有効にするには、次のようにします:
グローバル設定
Milvusの設定ファイルを以下のように変更する必要があります。
dataCoord:
compaction:
clustering:
enable: true
autoEnable: false
triggerInterval: 600
minInterval: 3600
maxInterval: 259200
newDataSizeThreshold: 512m
timeout: 7200
queryNode:
enableSegmentPrune: true
datanode:
clusteringCompaction:
memoryBufferRatio: 0.1
workPoolSize: 8
common:
usePartitionKeyAsClusteringKey: true
dataCoord.compaction.clustering設定項目 設定項目 デフォルト値 enableクラスタリングコンパクションを有効にするかどうかを指定します。
クラスタリングキーを持つすべてのコレクションでこの機能を有効にする必要がある場合は、trueに設定します。falseautoEnable自動的にトリガーされるコンパクションを有効にするかどうかを指定します。
これをtrueに設定すると、Milvusは指定された間隔でクラスタリングキーを持つコレクションを圧縮します。falsetriggerIntervalMilvusがクラスタリング圧縮を開始する間隔をミリ秒単位で指定します。
このパラメータはautoEnableがtrueに設定されている場合のみ有効です。- minInterval最小間隔を秒単位で指定します。
このパラメータはautoEnableがtrueに設定されている場合のみ有効です。
triggerIntervalより大きい整数に設定することで、短時間に繰り返しコンパクションが行われるのを防ぐことができます。- maxInterval最大間隔を秒単位で指定する。
このパラメータは、autoEnableがtrueに設定されている場合のみ有効です。
Milvusは、コレクションがこの値よりも長い期間クラスタリング圧縮されていないことを検出すると、強制的にクラスタリング圧縮を行います。- newDataSizeThresholdクラスタリング圧縮をトリガする上限しきい値を指定します。
このパラメータは、autoEnableがtrueに設定されている場合にのみ有効です。
Milvusはコレクションのデータ量がこの値を超えたことを検出すると、クラスタリングコンパクションプロセスを開始します。- timeoutクラスタリングコンパクションのタイムアウト時間を指定します。
実行時間がこの値を超えると、クラスタリングコンパクションは失敗します。- queryNode設定項目 説明 デフォルト値 enableSegmentPruneMilvusが検索/クエリ要求を受信した際に、PartitionStatsを参照してデータをプルーンするかどうかを指定します。
これをtrueに設定すると、Milvus は検索/クエリ要求時にセグメントから無関係なデータを削除します。falsedataNode.clusteringCompaction設定項目 設定項目 デフォルト値 memoryBufferRatioクラスタリング圧縮タスクのメモリバッファ比率を指定します。
Milvusは、データサイズがこの比率を使用して計算された割り当てバッファサイズを超えると、データをフラッシュします。- workPoolSizeクラスタリング・コンパクション・タスクのワーカープールサイズを指定します。 - common設定項目 設定項目 デフォルト値 usePartitionKeyAsClusteringKeyコレクション内のパーティション・キーをクラスタリング・キーとして使用するかどうかを指定します。
これをtrueに設定すると、パーティション・キーがクラスタリング・キーとして使用されます。
クラスタリング・キーを明示的に設定することで、コレクション内のこの設定を常に上書きできます。false
上記の変更をMilvusクラスタに適用するには、Configure Milvus with HelmおよびConfigure Milvus with Milvus Operatorsの手順に従ってください。
コレクションの構成
特定のコレクションでクラスタリングコンパクトを行うには、コレクションからスカラフィールドをクラスタリングキーとして選択する必要があります。
default_fields = [
FieldSchema(name="id", dtype=DataType.INT64, is_primary=True),
FieldSchema(name="key", dtype=DataType.INT64, is_clustering_key=True),
FieldSchema(name="var", dtype=DataType.VARCHAR, max_length=1000, is_primary=False),
FieldSchema(name="embeddings", dtype=DataType.FLOAT_VECTOR, dim=dim)
]
default_schema = CollectionSchema(
fields=default_fields,
description="test clustering-key collection"
)
coll1 = Collection(name="clustering_test", schema=default_schema)
Int8,Int16,Int32,Int64,Float,Double, およびVarChar.
クラスタリング・コンパクションのトリガ
自動クラスタリングコンパクションを有効にしている場合、Milvusは指定された間隔で自動的にコンパクションをトリガします。または、次のように手動でコンパクションをトリガすることもできます:
coll1.compact(is_clustering=True)
coll1.get_compaction_state(is_clustering=True)
coll1.wait_for_compaction_completed(is_clustering=True)
ベンチマークテスト
データ量とクエリパターンの組み合わせにより、クラスタリングコンパクションがもたらすパフォーマンスの向上が決まります。社内のベンチマーク・テストでは、クラスタリング・コンパクションによって1秒あたりのクエリ数(QPS)が最大25倍向上することが実証されています。
このベンチマークテストは、2,000万、768次元のLAIONデータセットから、キーフィールドをクラスタリングキーとして指定したエンティティを含むコレクションを対象としたものです。コレクション内でクラスタリング圧縮がトリガーされた後、CPU使用率が高水準に達するまで同時検索が送信される。
| 検索フィルター | プルーンの比率 | 待ち時間 (ms) | QPS (reqs/s) | ||||
|---|---|---|---|---|---|---|---|
| 平均 | 最小 | 最大 | 中央値 | TP99 | |||
| なし | 0% | 1685 | 672 | 2294 | 1710 | 2291 | 17.75 |
| キー > 200 および キー < 800 | 40.2% | 1045 | 47 | 1828 | 1085 | 1617 | 28.38 |
| キー>200かつキー<600 | 59.8% | 829 | 45 | 1483 | 882 | 1303 | 35.78 |
| キー > 200 かつ キー < 400 | 79.5% | 550 | 100 | 985 | 584 | 898 | 54.00 |
| キー== 1000 | 99% | 68 | 24 | 1273 | 70 | 246 | 431.41 |
検索フィルターで検索範囲を狭めると、プルーンの比率が高くなる。これは、検索プロセスでより多くのエンティティがスキップされることを意味します。最初の行と最後の行の統計値を比較すると、クラスタリング・コンパクションなしの検索では、コレクション全体をスキャンする必要があることがわかります。一方、特定のキーを使用してクラスタリング・コンパクションを行う検索では、最大25倍の改善が得られます。
ベストプラクティス
クラスタリングコンパクションを効率的に使用するためのヒントをいくつか紹介します:
データ・ボリュームの大きいコレクションでこれを有効にする。 コレクションのデータ・ボリュームが大きくなると、検索パフォーマンスが向上します。100万エンティティを超えるコレクションでは、この機能を有効にすることをお勧めします。
適切なクラスタリングキーを選択します。 フィルタリング条件として一般的に使用されるスカラーフィールドをクラスタリングキーとして使用できます。複数のテナントからのデータを保持するコレクションでは、あるテナントと別のテナントを区別するフィールドをクラスタリ ング・キーとして使用できます。
パーティションキーをクラスタリングキーとして使用する milvusインスタンスのすべてのコレクションでこの機能を有効にしたい場合、またはパーティションキーを持つ大規模なコレクションでパフォーマンスの問題にまだ直面している場合は、
common.usePartitionKeyAsClusteringKeyを true に設定できます。そうすることで、コレクション内のスカラーフィールドをパーティションキーとして選択した場合、クラスタリングキーとパーティションキーを持つことになります。この設定は、別のスカラー・フィールドをクラスタリング・キーとして選択することを妨げるものではありません。明示的に指定されたクラスタリング・キーが常に優先されます。