How Does the Database Understand and Execute Your Query?
 Cover image
Cover image
This article is transcreated by Angela Ni.
A vector query in Milvus is the process of retrieving vectors via scalar filtering based on boolean expression. With scalar filtering, users can limit their query results with certain conditions applied on attributes of data. For instance, if a user queries for films released during 1990-2010 and with scores higher than 8.5, only films whose attributes (release year and score) fulfill the condition.
This post aims to examine how a query is completed in Milvus from the input of a query expression to query plan generation and query execution.
Jump to:
Query expression
Expression of query with attribute filtering in Milvus adopts the EBNF(Extended Backus–Naur form) syntax. The image below is the expression rules in Milvus.
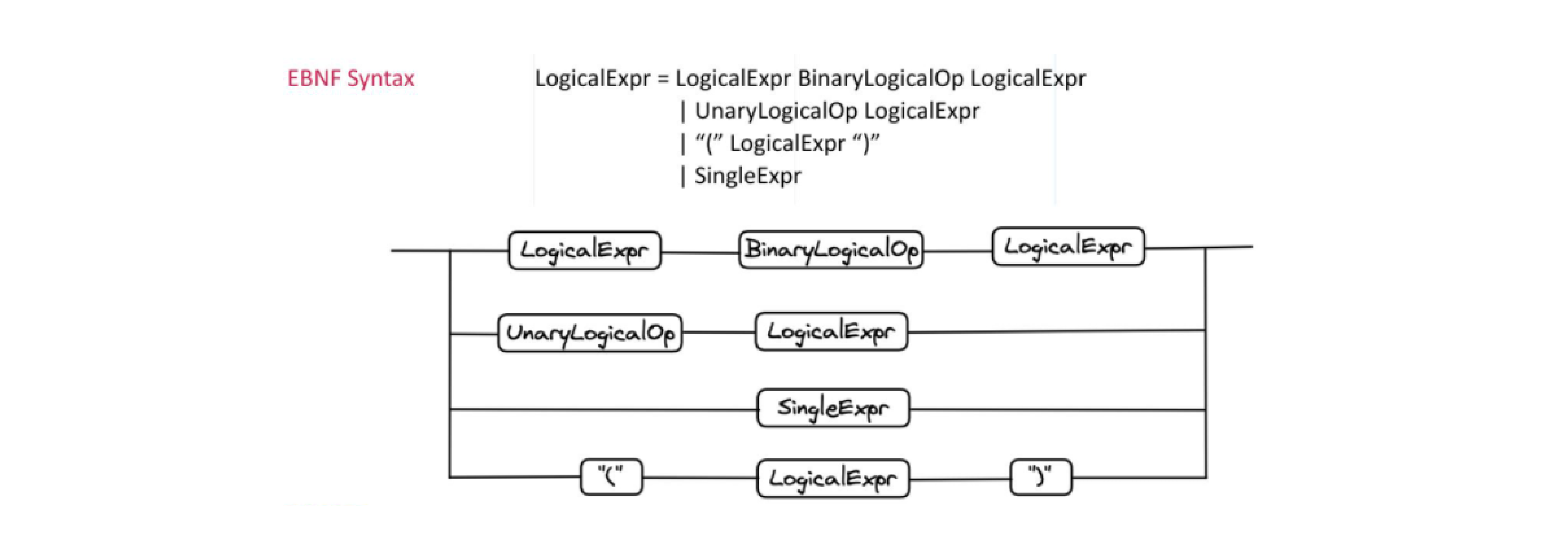 Expression Syntax
Expression Syntax
Logical expressions can be created using the combination of binary logical operators, unary logical operators, logical expressions, and single expressions. Since EBNF syntax is itself recursive, a logical expression can be the outcome of the combination or part of a bigger logical expression. A logical expression can contain many sub-logical expressions. The same rule applies in Milvus. If a user needs to filter the attributes of the results with many conditions, the user can create his own set of filtering conditions by combining different logical operators and expressions.
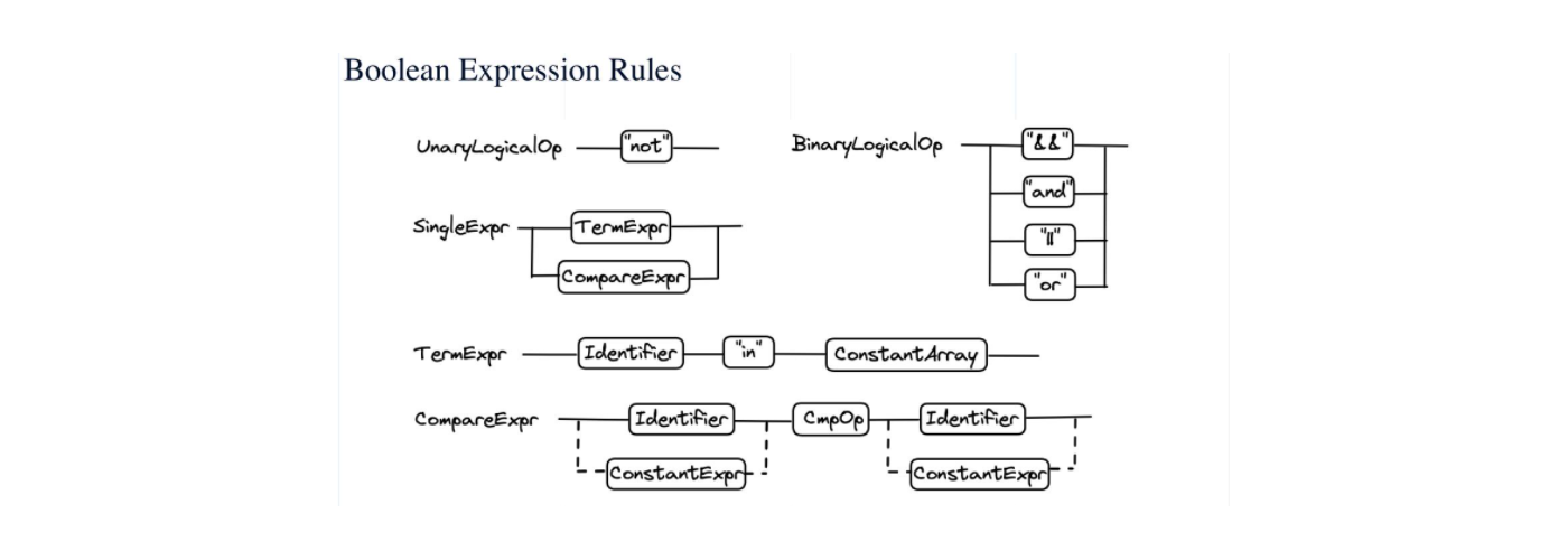 Boolean expression
Boolean expression
The image above shows part of the Boolean expression rules in Milvus. Unary logical operators can be added to an expression. Currently Milvus only supports the unary logical operator "not", which indicates that the system needs to take the vectors whose scalar field values do not satisfy the calculation results. Binary logical operators include “and” and "or". Single expressions include term expressions and compare expressions.
Basic arithmetic calculation like addition, subtraction, multiplication, and division is also supported during a query in Milvus. The following image demonstrates the precedence of the operations. Operators are listed from top to bottom in descending precedence.
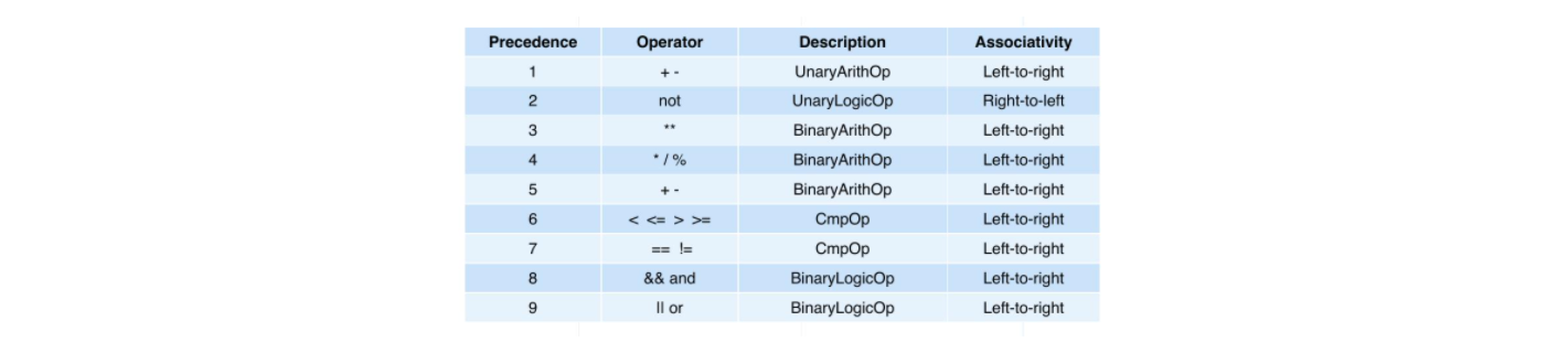 Precedence
Precedence
How a query expression on certain films is processed in Milvus?
Suppose there is an abundance of film data stored in Milvus and the user wants to query certain films. As an example, each film data stored in Milvus has the following five fields: film ID, release year, film type, score, and poster. In this example, the data type of film ID and release year is int64, while film scores are float point data. Also, film posters are stored in the format of float-point vectors, and film type in the format of string data. Notably, support for string data type is a new feature in Milvus 2.1.
For instance, if a user want to query the movies with scores higher than 8.5. The films should also be released during a decade before 2000 to a decade after 2000 or their types should be either comedy or action movie, the user need to input the following predicate expression: score > 8.5 && (2000 - 10 < release_year < 2000 + 10 || type in [comedy,action]).
Upon receiving the query expression, the system will execute it in the following precedence:
- Query for films with scores higher than 8.5. The query results are called "result1".
- Calculate 2000 - 10 to get “result2” (1990).
- Calculate 2000 + 10 to get “result3” (2010).
- Query for films with the value of
release_yeargreater than “result2” and smaller than "result3". That is to say, the system needs to query for films released between 1990 and 2010. The query results are called "result4". - Query for films that are either comedies or action movies. The query results are called "result5".
- Combine “result4” and “result5” to obtain films that are either released between 1990 and 2010 or belong to the category of comedy or action movie. The results are called "result6".
- Take the common part in “result1” and “result6” to obtain the final results satisfying all the conditions.
 Film example
Film example
Plan AST generation
Milvus leverages the open-source tool ANTLR (ANother Tool for Language Recognition) for plan AST (abstract syntax tree) generation. ANTLR is a powerful parser generator for reading, processing, executing, or translating structure text or binary files. More specifically, ANTLR can generate a parser for building and walking parse trees based on pre-defined syntax or rules. The following image is an example in which the input expression is "SP=100;". LEXER, the built-in language recognition functionality in ANTLR, generates four tokens for the input expression - "SP", "=", "100", and ";". Then the tool will further parse the four tokens to generate the corresponding parse tree.
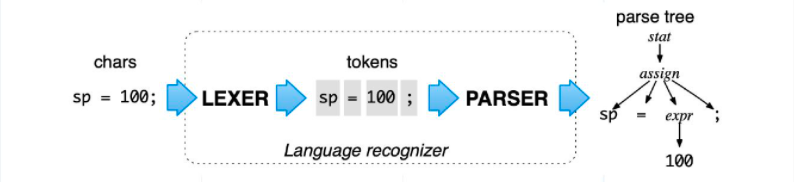 parse tree
parse tree
The walker mechanism is a crucial part in the ANTLR tool. It is designed to walk through all the parse trees to examine whether each node obeys the syntax rules, or to detect certain sensitive words. Some of the relevant APIs are listed in the image below. Since ANTLR starts from the root node and goes down all the way through each sub-node to the bottom, there is no need to differentiate the order of how to walk through the parse tree.
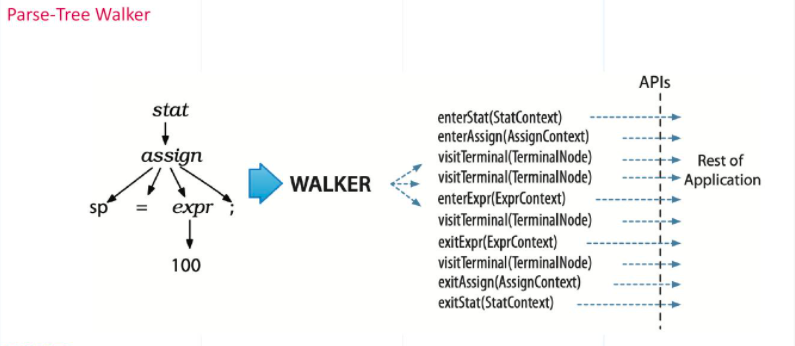 parse tree walker
parse tree walker
Milvus generates the PlanAST for query in a similar way to the ANTLR. However, using ANTLR requires redefining rather complicated syntax rules. Therefore, Milvus adopts one of the most prevalent rules - Boolean expression rules, and depends on the Expr package open sourced on GitHub to query and parse the syntax of query expressions.
During a query with attribute filtering, Milvus will generate a primitive unsolved plan tree using ant-parser, the parsing method provided by Expr, upon receiving the query expression. The primitive plan tree we will get is a simple binary tree. Then the plan tree is fine-tuned by Expr and the built-in optimizer in Milvus. The optimizer in Milvus is quite similar to the aforementioned walker mechanism. Since the plan tree optimization functionality provided by Expr is pretty sophisticated, the burden of the Milvus built-in optimizer is alleviated to a great extent. Ultimately, the analyzer analyzes the optimized plan tree in a recursive way to generate a plan AST in the structure of protocol buffers (protobuf).
 plan AST workflow
plan AST workflow
Query execution
Query execution is at root the execution of the plan AST generated in the previous steps.
In Milvus, a plan AST is defined in a proto structure. The image below is a message with the protobuf structure. There are six types of expressions, among which binary expression and unary expression can further have binary logical expression and unary logical expression.
 protobuf1
protobuf1
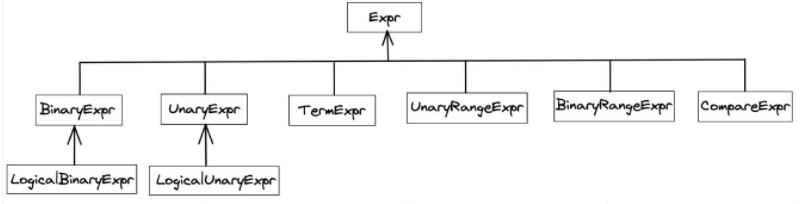 protobuf2
protobuf2
The image below is a UML image of the query expression. It demonstrates the basic class and derivative class of each expression. Each class comes with a method to accept visitor parameters. This is a typical visitor design pattern. Milvus uses this pattern to execute the plan AST as its biggest advantage is that users do not have to do anything to the primitive expressions but can directly access one of the methods in the patterns to modify certain query expression class and relevant elements.
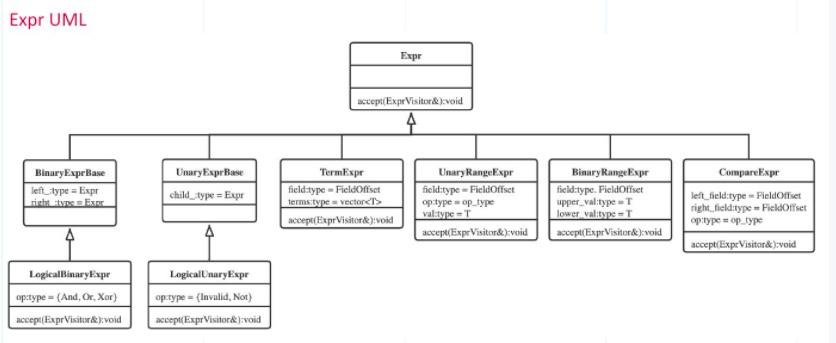 UML
UML
When executing a plan AST, Milvus first receives a proto-type plan node. Then a segcore-type plan node is obtained via the internal C++ proto parser. Upon obtaining the two types of plan nodes, Milvus accepts a series of class access and then modifies and executes in the internal structure of the plan nodes. Finally, Milvus searches through all the execution plan nodes to obtain the filtered results. The final results are output in the format of a bitmask. A bitmask is an array of bit numbers (“0” and “1”). Those data satisfying filter conditions are marked as “1” in the bitmask, while those do not meet the requirements are marked as “0” in the bitmask.
 execute workflow
execute workflow
About the Deep Dive Series
With the official announcement of general availability of Milvus 2.0, we orchestrated this Milvus Deep Dive blog series to provide an in-depth interpretation of the Milvus architecture and source code. Topics covered in this blog series include:
- Query expression
- How a query expression on certain films is processed in Milvus?
- Plan AST generation
- Query execution
- About the Deep Dive Series
On This Page
Try Managed Milvus for Free
Zilliz Cloud is hassle-free, powered by Milvus and 10x faster.
Get StartedLike the article? Spread the word



