Open Source Software (OSS) Quality Assurance - A Milvus Case Study
 Cover image
Cover image
This article is written by Wenxing Zhu and transcreated by Angela Ni.
Quality assurance (QA) is a systematic process of determining whether a product or service meets certain requirements. A QA system is an indispensable part of the R&D process because, as its name suggests, it ensures that quality of the product.
This post introduces the QA framework adopted in developing the Milvus vector database, aiming to provide a guideline for contributing developers and users to participate in the process. It will also cover the major test modules in Milvus as well as methods and tools that can be leveraged to improve the efficiency of QA testings.
Jump to:
- A general introduction to the Milvus QA system
- Test modules in Milvus
- Tools and methods for better QA efficiency
A general introduction to the Milvus QA system
The system architecture is critical to conducting QA testings. The more a QA engineer is familiar with the system, the more likely he or she is going to come up with a reasonable and efficient testing plan.
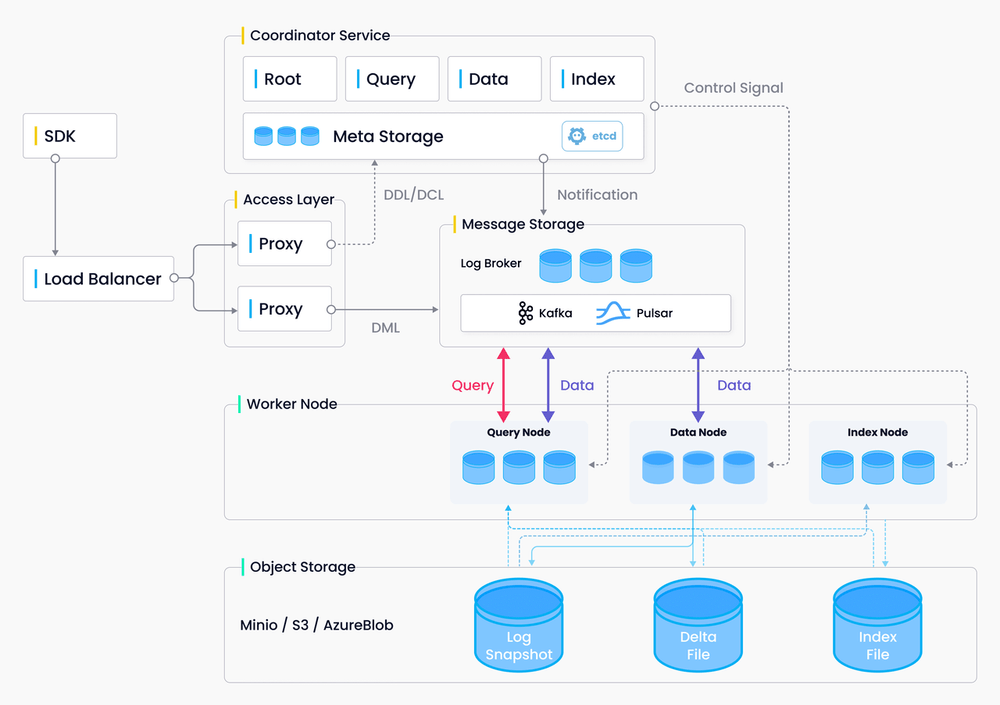 Milvus architecture
Milvus architecture
Milvus 2.0 adopts a cloud-native, distributed, and layered architecture, with SDK being the main entrance for data to flow in Milvus. The Milvus users leverage the SDK very frequently, hence functional testing on the SDK side is much needed. Also, function tests on SDK can help detect the internal issues that might exist within the Milvus system. Apart from function tests, other types of tests will also be conducted on the vector database, including unit tests, deployment tests, reliability tests, stability tests, and performance tests.
A cloud-native and distributed architecture brings both convenience and challenges to QA testings. Unlike systems that are deployed and run locally, a Milvus instance deployed and run on a Kubernetes cluster can ensure that software testing is carried out under the same circumstance as software development. However, the downside is that the complexity of distributed architecture brings more uncertainties that can make QA testing of the system even harder and strenuous. For instance, Milvus 2.0 uses microservices of different components, and this leads to an increased number of services and nodes, and a greater possibility of a system error. Consequently, a more sophisticated and comprehensive QA plan is needed for better testing efficiency.
QA testings and issue management
QA in Milvus involves both conducting tests and managing issues emerged during software development.
QA testings
Milvus conducts different types of QA testing according to Milvus features and user needs in order of priority as shown in the image below.
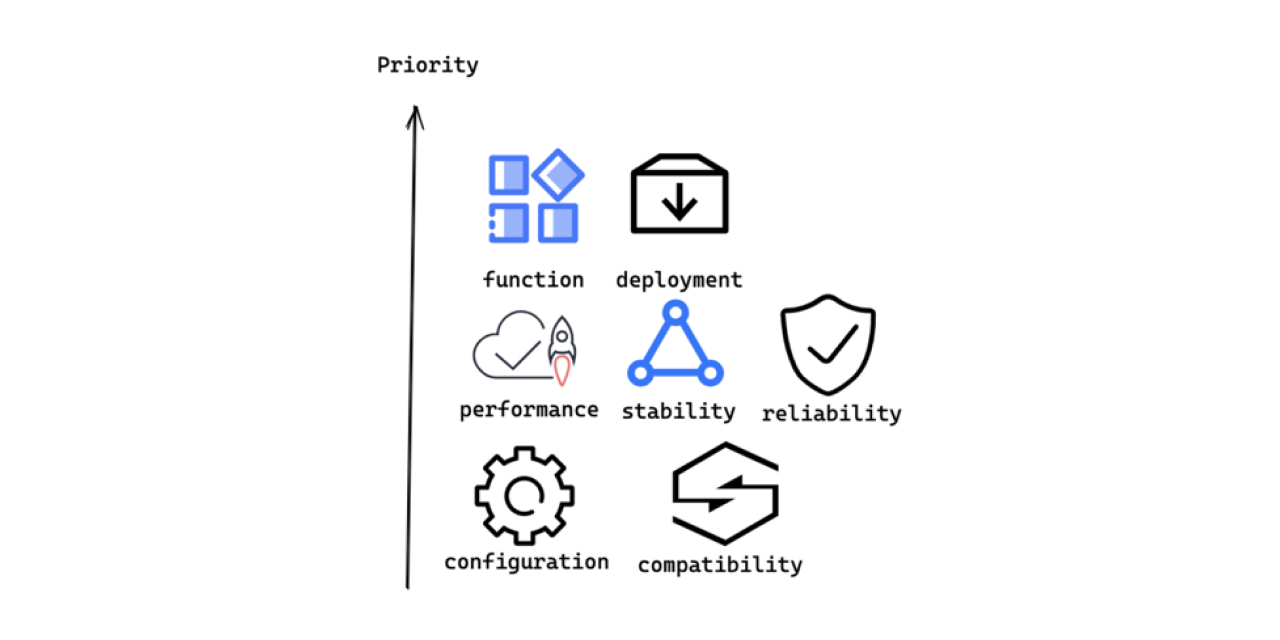 QA testing priority
QA testing priority
QA testings are conducted on the following aspects in Milvus in the following priority:
- Function: Verify if the functions and features work as originally designed.
- Deployment: Check if a user can deploy, reinstall, and upgrade both Mivus standalone version and Milvus cluster with different methods (Docker Compose, Helm, APT or YUM, etc.).
- Performance: Test the performance of data insertion, indexing, vector search and query in Milvus.
- Stability: Check if Milvus can run stably for 5-10 days under a normal level of workload.
- Reliability: Test if Milvus can still partly function if certain system error occurs.
- Configuration: Verify if Milvus works as expected under certain configuration.
- Compatibility: Test if Milvus is compatible with different types of hardware or software.
Issue management
Many issues may emerge during software development. The author of the templated issues can be QA engineers themselves or Milvus users from the open-source community. The QA team is responsible for figuring out the issues.
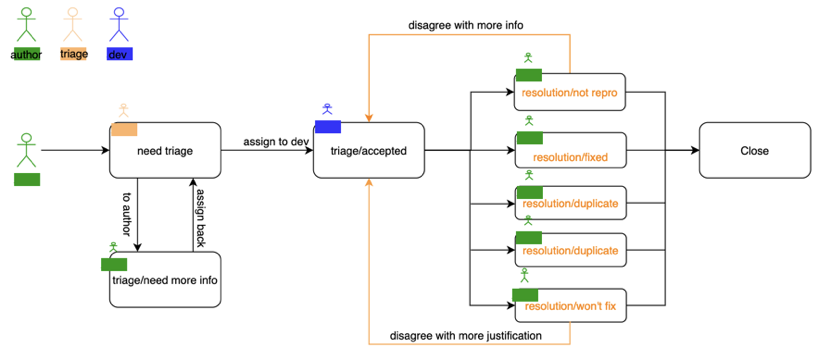 Issue management workflow
Issue management workflow
When an issue is created, it will go through triage first. During triage, new issues will be examined to ensure that sufficient details of the issues are provided. If the issue is confirmed, it will be accepted by the developers and they will try to fix the issues. Once development is done, the issue author needs to verify if it is fixed. If yes, the issue will be ultimately closed.
When is QA needed?
One common misconception is that QA and development are independent from each other. However, the truth is to ensure the quality of the system, efforts are needed from both developers and QA engineers. Therefore, QA needs to be involved throughout the whole lifecycle.
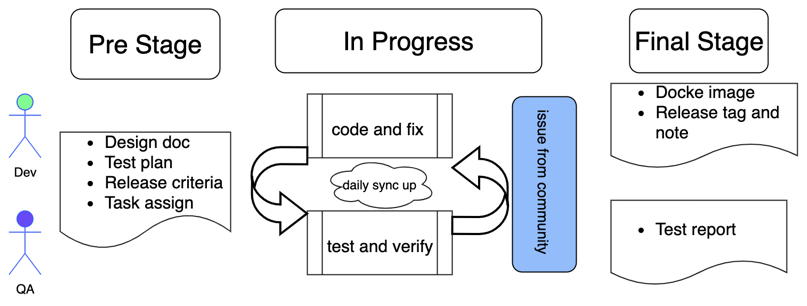 QA lifecycle
QA lifecycle
As shown in the figure above, a complete software R&D lifecycle includes three stages.
During the initial stage, the developers publish design documentation while QA engineers come up with test plans, define release criteria, and assign QA tasks. Developers and QA engineers need to be familiar with both the design doc and test plan so that a mutual understanding of the objective of the release (in terms of features, performance, stability, bug convergence, etc.) is shared among the two teams.
During R&D, development and QA testings interact frequently to develop and verify features and functions, and fix bugs and issues reported by the open-source community as well.
During the final stage, if the release criteria is met, a new Docker image of the new Milvus version will be released. A release note focusing on new features and fixed bugs and a release tag is needed for the official release. Then the QA team will also publish a testing report on this release.
Test modules in Milvus
There are several test modules in Milvus and this section will explain each module in detail.
Unit test
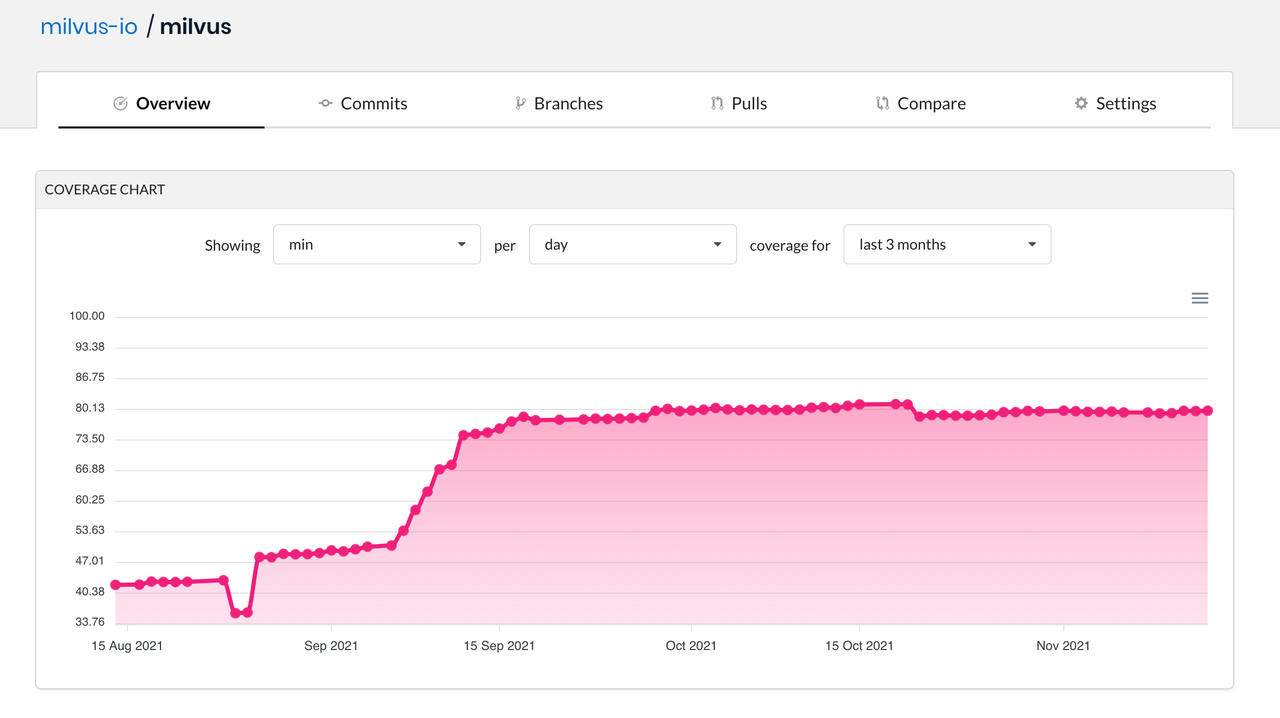 Unit test
Unit test
Unit tests can help identify software bugs at an early stage and provide a verification criteria for code restructuring. According to the Milvus pull request (PR) acceptance criteria, the coverage of code unit test should be 80%.
Function test
Function tests in Milvus are mainly organized around PyMilvus and SDKs. The main purpose of function tests are to verify if the interfaces can work as designed. Function tests have two facets:
- Test if SDKs can return expected results when correct parameters are passed.
- Test if SDKs can handle errors and return reasonable error messages when incorrect parameters are passed.
The figure below depicts the current framework for function tests which is based on the mainstream pytest framework. This framework adds a wrapper to PyMilvus and empowers testing with an automated testing interface.
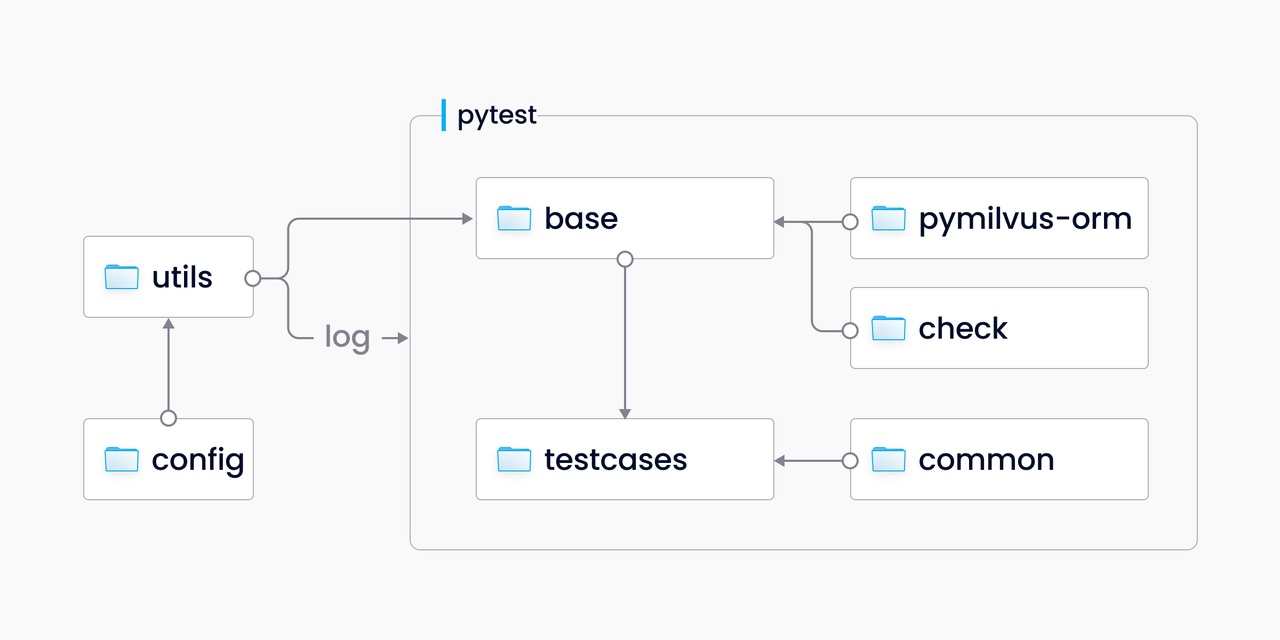 Function test
Function test
Considering a shared testing method is needed and some functions need to be reused, the above testing framework is adopted, rather than using the PyMilvus interface directly. A “check” module is also included in the framework to bring convenience to the verification of expected and actual values.
As many as 2,700 function test cases are incorporated into the tests/python_client/testcases directory, fully covering almost all the PyMilvus interfaces. These function tests strictly supervise the quality of each PR.
Deployment test
Milvus comes in two modes: standalone and cluster. And there are two major ways to deploy Milvus: using Docker Compose or Helm. And after deploying Milvus, users can also restart or upgrade the Milvus service. There are two main categories of deployment test: restart test and upgrade test.
Restart test refers to the process of testing data persistence, i.e. whether data are still available after a restart. Upgrade test refers to the process of testing data compatibility to prevent situations where incompatible formats of data are inserted into Milvus. Both the two types of deployment tests share the same workflow as illustrated in the image below.
 Deployment test
Deployment test
In a restart test, the two deployments uses the same docker image. However in an upgrade test, the first deployment uses a docker image of a previous version while the second deployment uses a docker image of a later version. The test results and data are saved in the Volumes file or persistent volume claim (PVC).
When running the first test, multiple collections are created and different operations are made to each of the collection. When running the second test, the main focus will be on verifying if the created collections are still available for CRUD operations, and if new collections can be further created.
Reliability test
Testings on the reliability of cloud-native distributed system usually adopt a chaos engineering method whose purpose is to nip errors and system failures in the bud. In other words, in an chaos engineering test, we purposefully create system failures to identify issues in pressure tests and fix system failures before they really start to do hazards. During a chaos test in Milvus, we choose Chaos Mesh as the tool to create a chaos. There are several types of failures that needs to be created:
- Pod kill: a simulation of the scenario where nodes are down.
- Pod failure: Test if one of the worker node pods fails whether the whole system can still continue to work.
- Memory stress: a simulation of heavy memory and CPU resources consumption from the work nodes.
- Network partition: Since Milvus separates storage from computing, the system relies heavily on the communication between various components. A simulation of the scenario where the communication between different pods are partitioned is needed to test the interdependency of different Milvus components.
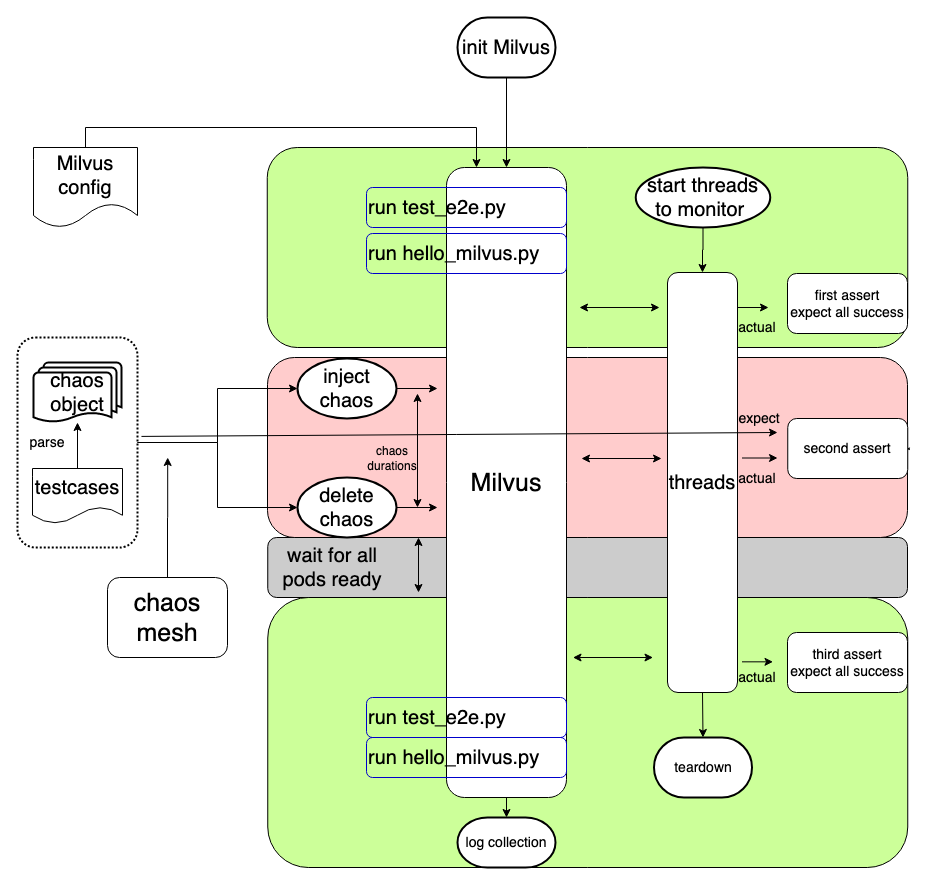 Reliability test
Reliability test
The figure above demonstrates the reliability test framework in Milvus that can automate chaos tests. The workflow of a reliability test is as follows:
- Initialize a Milvus cluster by reading the deployment configurations.
- When the cluster is ready, run
test_e2e.pyto test if the Milvus features are available. - Run
hello_milvus.pyto test data persistence. Create a collection named “hello_milvus” for data insertion, flush, index building, vector search and query. This collection will not be released or dropped during the test. - Create a monitoring object which will start six threads executing create, insert, flush, index, search and query operations.
checkers = {
Op.create: CreateChecker(),
Op.insert: InsertFlushChecker(),
Op.flush: InsertFlushChecker(flush=True),
Op.index: IndexChecker(),
Op.search: SearchChecker(),
Op.query: QueryChecker()
}
- Make the first assertion - all operations are successful as expected.
- Introduce a system failure to Milvus by using Chaos Mesh to parse the yaml file which defines the failure. A failure can be killing the query node every five seconds for instance.
- Make the second assertion while introducing a system failure - Judge whether the returned results of the operations in Milvus during a system failure matches the expectation.
- Eliminate the failure via Chaos Mesh.
- When the Milvus service is recovered (meaning all pods are ready), make the third assertion - all operations are successful as expected.
- Run
test_e2e.pyto test if the Milvus features are available. Some of the operations during the chaos might be blocked due to the third assertion. And even after the chaos is eliminated, some operations might continue to be blocked, hampering the third assertion from being successful as expected. This step aims to facilitate the third assertion and serves as a standard for checking if the Milvus service has recovered. - Run
hello_milvus.py, load the created collection, and conduct CRUP operations on the collection. Then, check if the data existing before the system failure are still available after failure recovery. - Collect logs.
Stability and performance test
The figure below describes the purposes, test scenarios, and metrics of stability and performance test.
| Stability test | Performance test | |
|---|---|---|
| Purposes | - Ensure that Milvus can work smoothly for a fixed period of time under normal workload. - Make sure resources are consumed stably when the Milvus service starts. | - Test the performance of alll Milvus interfaces. - Find the optimal configuration with the help of performance tests. - Serve as the benchmark for future releases. - Find the bottleneck that hampers a better performance. |
| Scenarios | - Offline read-intensive scenario where data are barely updated after insertion and the percentage of processing each type of request is: search request 90%, insert request 5%, others 5%. - Online write-intensive scenario where data are inserted and searched simultaneously and the percentage of processing each type of request is: insert request 50%, search request 40%, others 10%. | - Data insertion - Index building - Vector search |
| Metrics | - Memory usage - CPU consumption - IO latency - The status of Milvus pods - Response time of the Milvus service etc. | - Data throughput during data insertion - The time it takes to build an index - Response time during a vector search - Query per second (QPS) - Request per second - Recall rate etc. |
Both stability test and performance test share the same set of workflow:
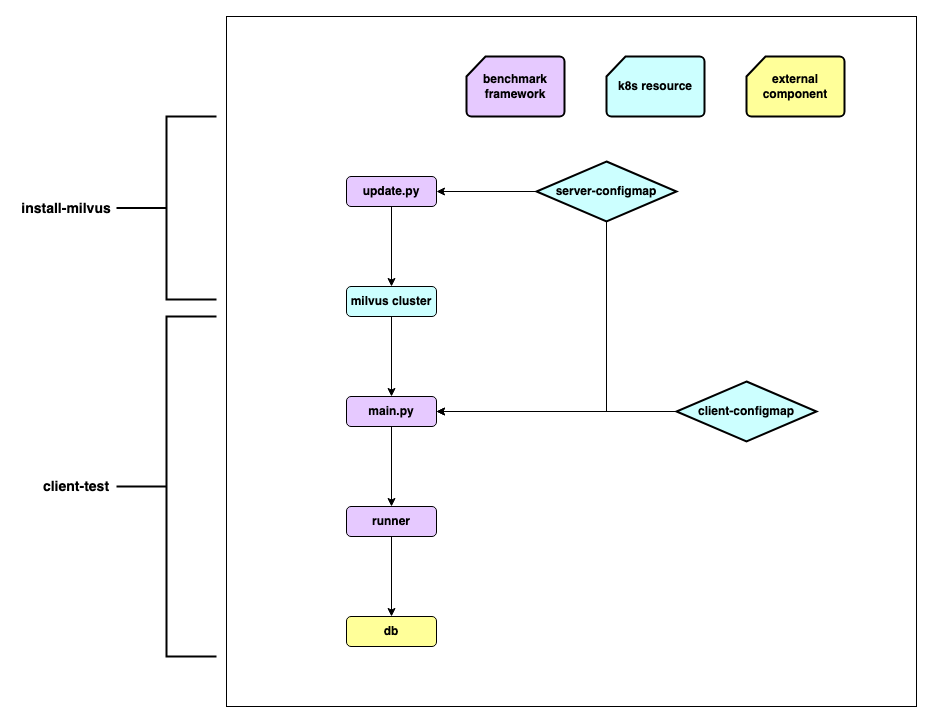 Stability and performance test
Stability and performance test
- Parse and update configurations, and define metrics. The
server-configmapcorresponds to the configuration of Milvus standalone or cluster whileclient-configmapcorresponds to the test case configurations. - Configure the server and the client.
- Data preparation
- Request interaction between the server and the client.
- Report and display metrics.
Tools and methods for better QA efficiency
From the module testing section, we can see that the procedure for most of the testings are in fact almost the same, mainly involving modifying Milvus server and client configurations, and passing API parameters. When there are multiple configurations, the more varied the combination of different configurations, the more testing scenarios these experiments and tests can cover. As a result, the reuse of codes and procedures is all the more critical to the process of enhancing testing efficiency.
SDK test framework
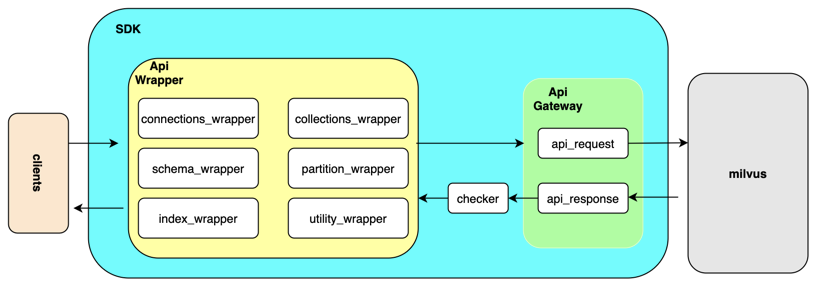 SDK test framework
SDK test framework
To accelerate the testing process, we can add an API_request wrapper to the original testing framework, and set it as something similar to the API gateway. This API gateway will be in charge of collecting all API requests and then pass them to Milvus to collectively receive responses. These responses will be passed back to the client afterwards. Such a design makes capturing certain log information like parameters, and returned results much more easier. In addition, the checker component in the SDK test framework can verify and examine the results from Milvus. And all checking methods can be defining within this checker component.
With the SDK test framework, some crucial initialization processes can be wrapped into one single function. By doing so, large chunks of tedious codes can be eliminated.
It is also noteworthy that each individual test case is related to its unique collection to ensure data isolation.
When executing test cases,pytest-xdist, the pytest extension, can be leveraged to execute all individual test cases in parallel, greatly boosting the efficiency.
GitHub action
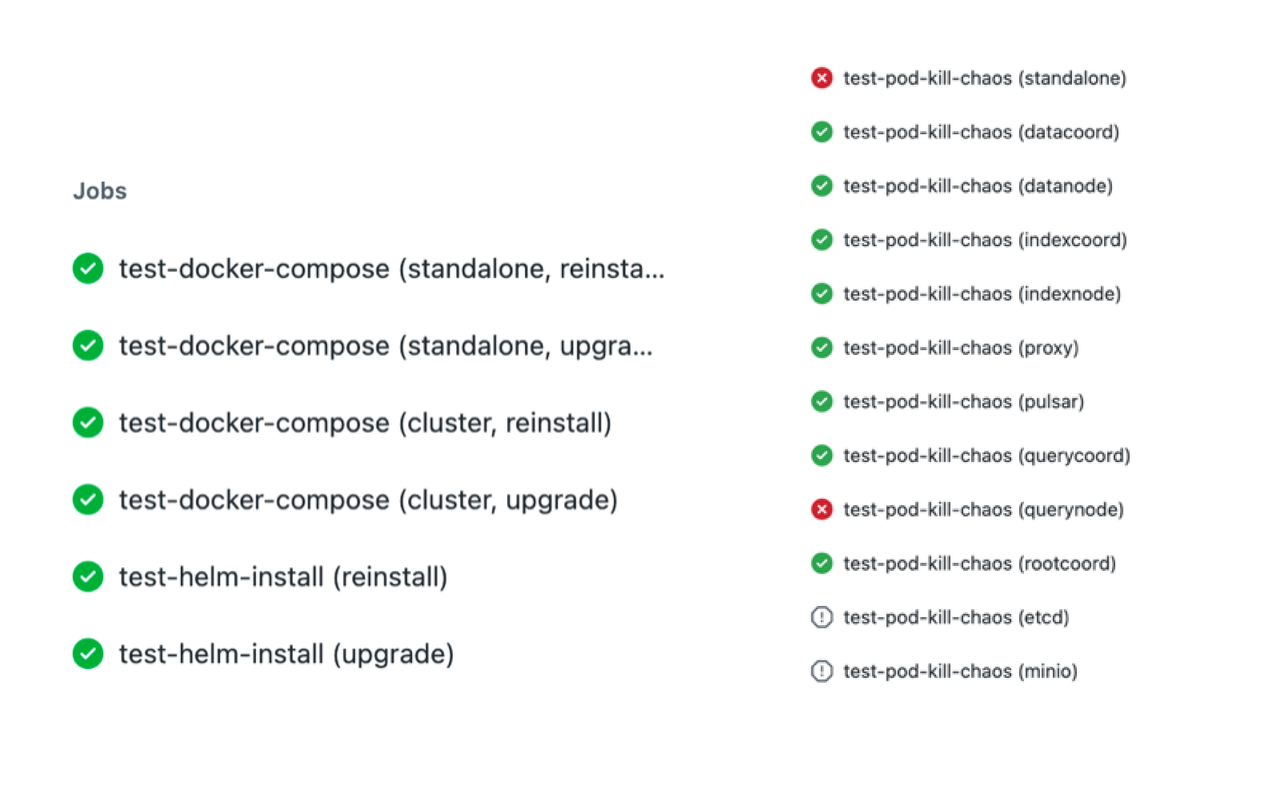 GitHub action
GitHub action
GitHub Action is also adopted to improve QA efficiency for its following characteristics:
- It is a native CI/CD tool deeply integrated with GitHub.
- It comes with a uniformly configured machine environment and pre-installed common software development tools including Docker, Docker Compose, etc.
- It supports multiple operating systems and versions including Ubuntu, MacOs, Windows-server, etc.
- It has a marketplace that offers rich extensions and out-of-box functions.
- Its matrix supports concurrent jobs, and reusing the same test flow to improve efficiency
Apart from the characteristics above, another reason for adopting GitHub action is that deployment tests and reliability tests require independent and isolated environment. And GitHub Action is ideal for daily inspection checks on small-scale datasets.
Tools for benchmark tests
To make QA tests more efficient, a number of tools are used.
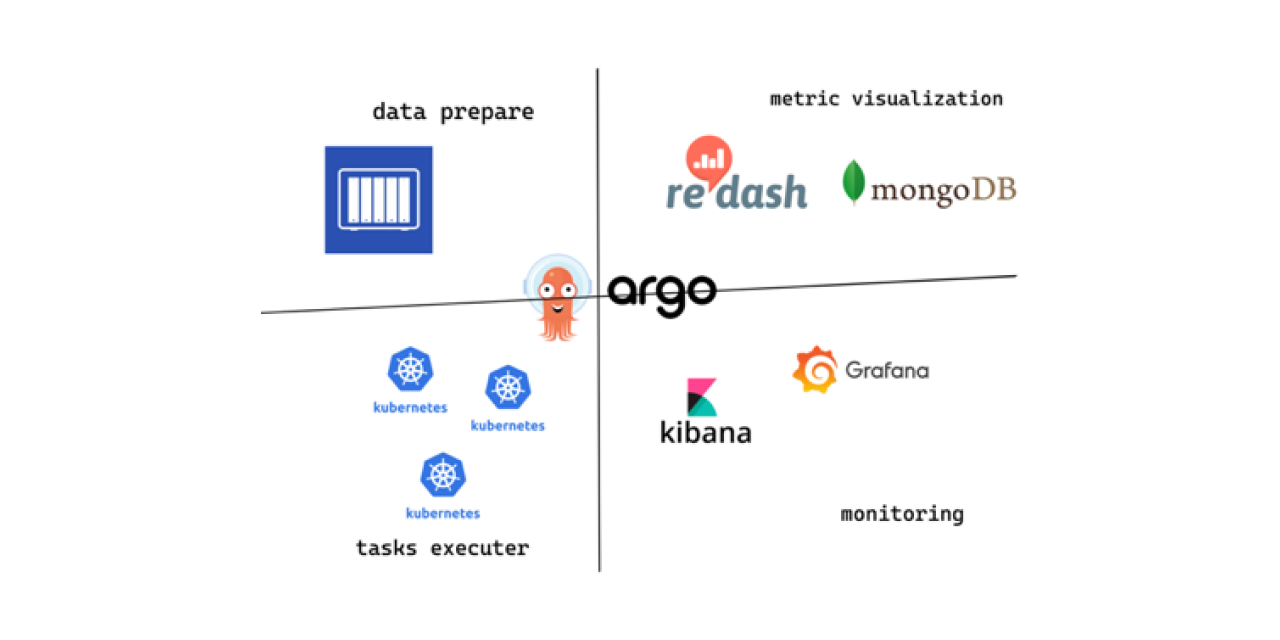 QA tools
QA tools
- Argo: a set of open-source tools for Kubernetes to run workflows and manage clusters by scheduling tasks. It can also enable running multiple tasks in parallel.
- Kubernetes dashboard: a web-based Kubernetes user interface for visualizing
server-configmapandclient-configmap. - NAS: Network attached storage (NAS) is a file-level computer data storage server for keeping common ANN-benchmark datasets.
- InfluxDB and MongoDB: Databases for saving results of benchmark tests.
- Grafana: An open-source analytics and monitoring solution for monitoring server resource metrics and client performance metrics.
- Redash: A service that helps visualize your data and create charts for benchmark tests.
About the Deep Dive Series
With the official announcement of general availability of Milvus 2.0, we orchestrated this Milvus Deep Dive blog series to provide an in-depth interpretation of the Milvus architecture and source code. Topics covered in this blog series include:
- A general introduction to the Milvus QA system
- Test modules in Milvus
- Tools and methods for better QA efficiency
- About the Deep Dive Series
On This Page
Try Managed Milvus for Free
Zilliz Cloud is hassle-free, powered by Milvus and 10x faster.
Get StartedLike the article? Spread the word



