Building a Vector Database for Scalable Similarity Search
 Cover image
Cover image
This article is written by Xiaofan Luan and transcreated by Angela Ni and Claire Yu.
According to statistics, about 80%-90% of the world’s data is unstructured. Fueled by the rapid growth of the Internet, an explosion of unstructured data is expected in the coming years. Consequently, companies are in urgent need of a powerful database that can help them better handle and understand such kind of data. However, developing a database is always easier said than done. This article aims to share the thinking process and design principles of building Milvus, an open-source, cloud-native vector database for scalable similarity search. This article also explains the Milvus architecture in detail.
Jump to:
- Unstructured data requires a complete basic software stack
- The design principles of Milvus 2.0
- Building a vector database for scalable similarity search
Unstructured data requires a complete basic software stack
As the Internet grew and evolved, unstructured data became more and more common, including emails, papers, IoT sensor data, Facebook photos, protein structures, and much more. In order for computers to understand and process unstructured data, these are converted into vectors using embedding techniques.
Milvus stores and indexes these vectors, and analyzes the correlation between two vectors by calculating their similarity distance. If the two embedding vectors are very similar, it means that the original data sources are similar as well.
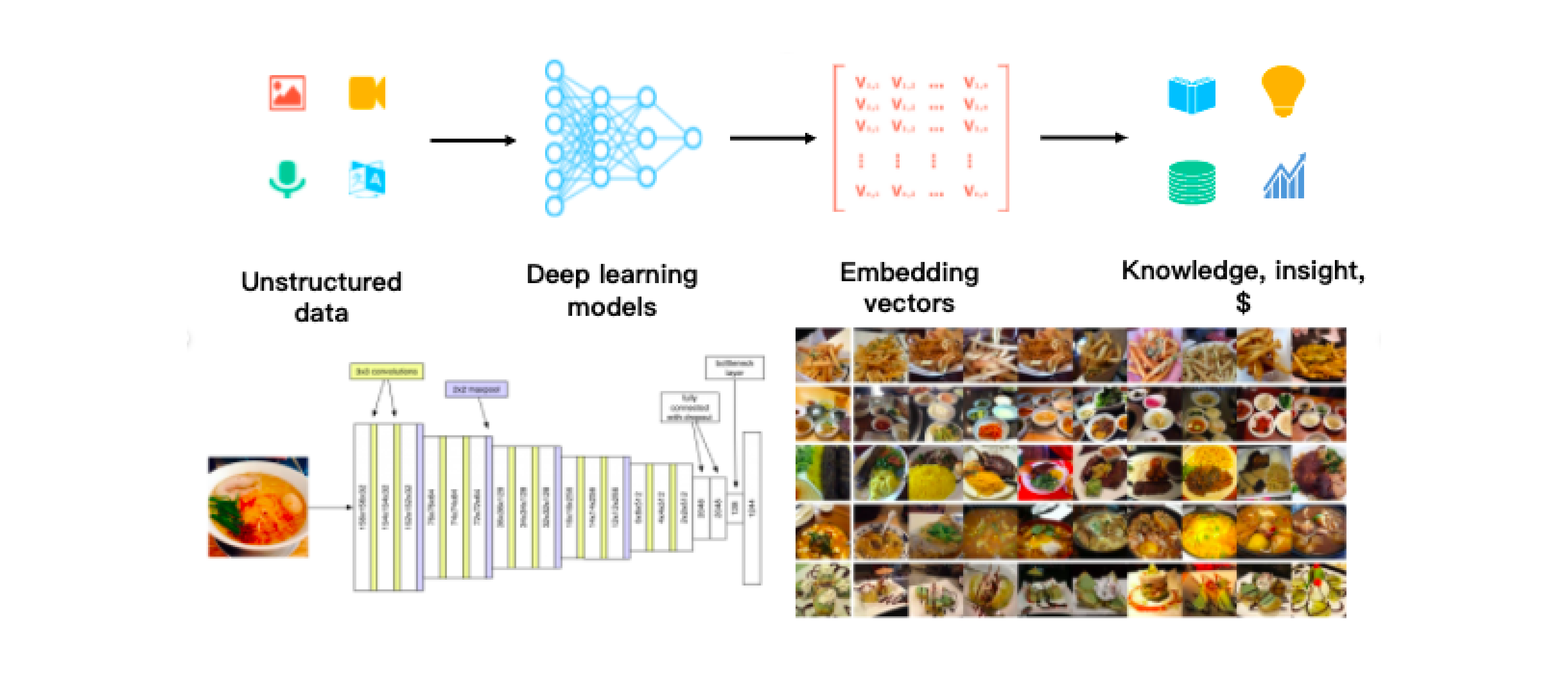 The workflow of processing unstructured data.
The workflow of processing unstructured data.
Vectors and scalars
A scalar is a quantity that is described only in one measurement - magnitude. A scalar can be represented as a number. For instance, a car is traveling at the speed of 80 km/h. Here, the speed (80km/h) is a scalar. Meanwhile, a vector is a quantity that is described in at least two measurements - magnitude and direction. If a car is traveling towards west at the speed of 80 km/h, here the velocity (80 km/h west) is a vector. The image below is an example of common scalars and vectors.
 Scalars vs. Vectors
Scalars vs. Vectors
Since most of the important data have more than one attribute, we can understand these data better if we convert them into vectors. One common way for us to manipulate vector data is to calculate the distance between vectors using metrics such as Euclidean distance, inner product, Tanimoto distance, Hamming distance, etc. The closer the distance, the more similar the vectors are. To query a massive vector dataset efficiently, we can organize vector data by building indexes on them. After the dataset is indexed, queries can be routed to clusters, or subsets of data, that are most likely to contain vectors similar to an input query.
To learn more about the indexes, refer to Vector Index.
From vector search engine to vector database
From the very beginning, Milvus 2.0 is designed to serve not only as a search engine, but more importantly, as a powerful vector database.
One way to help you understand the difference here is by drawing an analogy between InnoDB and MySQL, or Lucene and Elasticsearch.
Just like MySQL and Elasticsearch, Milvus is also built on top of open-source libraries such as Faiss, HNSW, Annoy, which focus on providing search functionalities and ensuring search performance. However, it would be unfair to degrade Milvus to merely a layer atop Faiss as it stores, retrieves, analyzes vectors, and, just as with any other database, also provides a standard interface for CRUD operations. In addition, Milvus also boasts features including:
- Sharding and partitioning
- Replication
- Disaster recovery
- Load balance
- Query parser or optimizer
 Vector database
Vector database
For a more comprehensive understanding of what a vector database is, read the blog here.
A cloud-native first approach
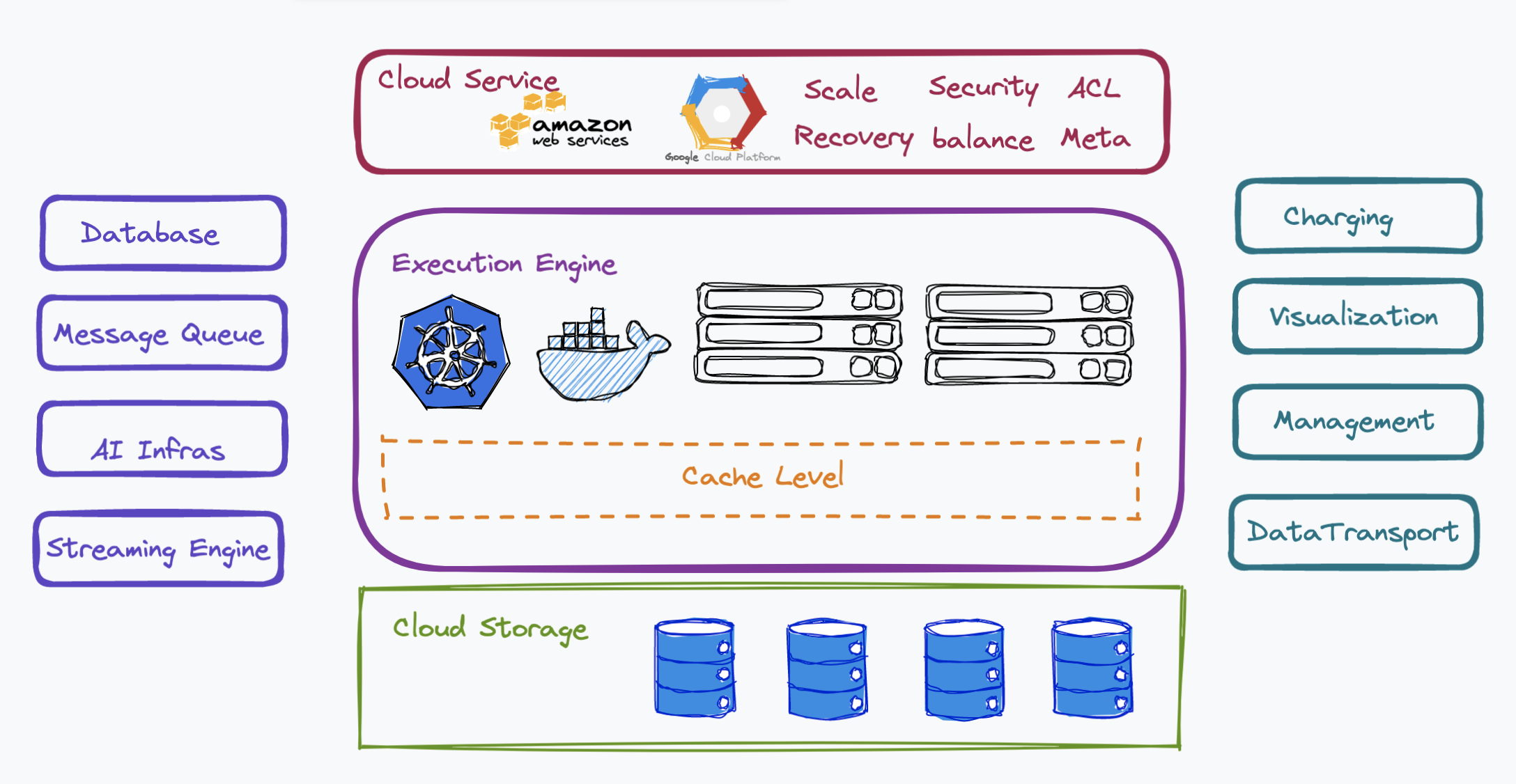 Could-native approach
Could-native approach
From shared nothing, to shared storage, then to shared something
Traditional databases used to adopt a “shared nothing” architecture in which nodes in the distributed systems are independent but connected by a network. No memory or storage are shared among the nodes. However, Snowflake revolutionized the industry by introducing a “shared storage” architecture in which compute (query processing) is separated from storage (database storage). With a shared storage architecture, databases can achieve greater availability, scalability, and a reduction of data duplication. Inspired by Snowflake, many companies started to leverage cloud-based infrastructure for data persistence while using local storage for caching. This type of database architecture is called “shared something” and has become the mainstream architecture in most applications today.
Apart from the “shared something” architecture, Milvus supports flexible scaling of each component by using Kubernetes to manage its execution engine and separating read, write and other services with microservices.
Database as a service (DBaaS)
Database as a service is a hot trend as many users not only care about regular database functionalities but also yearn for more varied services. This means that apart from the traditional CRUD operations, our database has to enrich the type of services it can provide, such as database management, data transport, charging, visualization, etc.
Synergy with the broader open-source ecosystem
Another trend in database development is leveraging the synergy between the database and other cloud-native infrastructure. In the case of Milvus, it relies on some open-source systems. For instance, Milvus uses etcd for storing metadata. It also adopts message queue, a type of asynchronous service-to-service communication used in microservices architecture, which can help export incremental data.
In the future, we hope to build Milvus on top of AI infrastructures such as Spark or Tensorflow, and integrate Milvus with streaming engines so that we can better support unified stream and batch processing to meet the various needs of Milvus users.
The design principles of Milvus 2.0
As our next-generation cloud-native vector database, Milvus 2.0 is built around the following three principles.
Log as data
A log in a database serially records all the changes made to data. As shown in the figure below, from left to right are “old data” and "new data". And the logs are in time order. Milvus has a global timer mechanism assigning one globally unique and auto-incremental timestamp.
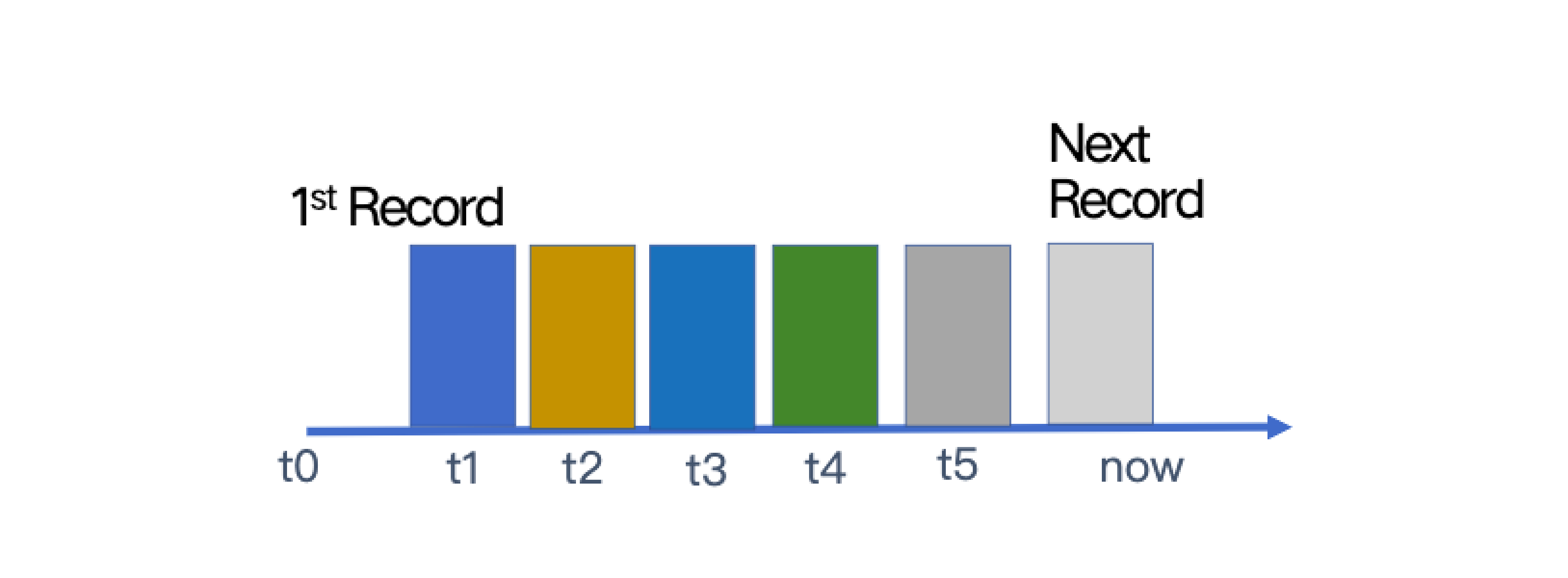 Logs
Logs
In Milvus 2.0, the log broker serves as the system’s backbone: all data insert and update operations must go through the log broker, and worker nodes execute CRUD operations by subscribing to and consuming logs.
Duality of table and log
Both the table and the log are data, and they are but just two different forms. Tables are bounded data while logs are unbounded. Logs can be converted into tables. In the case of Milvus, it aggregates logs using a processing window from TimeTick. Based on log sequence, multiple logs are aggregated into one small file called log snapshot. Then these log snapshots are combined to form a segment, which can be used individually for load balance.
Log persistency
Log persistency is one of the tricky issues faced by many databases. The storage of logs in a distributed system usually depends on replication algorithms.
Unlike databases such as Aurora, HBase, Cockroach DB, and TiDB, Milvus takes a ground-breaking approach and introduces a publish-subscribe (pub/sub) system for log storage and persistency. A pub/sub system is analogous to the message queue in Kafka or Pulsar. All nodes within the system can consume the logs. In Milvus, this kind of system is called a log broker. Thanks to the log broker, logs are decoupled from the server, ensuring that Milvus is itself stateless and better positioned to quickly recover from system failure.
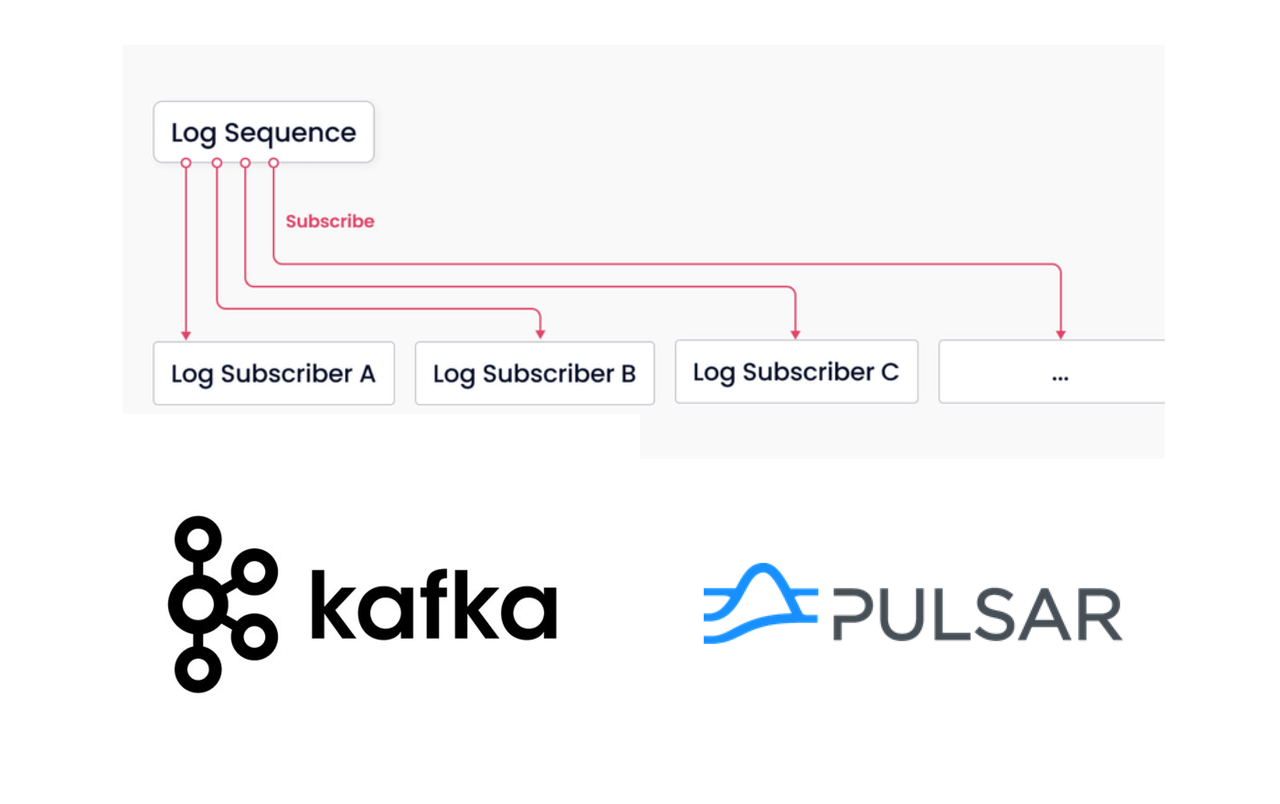 Log broker
Log broker
Building a vector database for scalable similarity search
Built on top of popular vector search libraries including Faiss, ANNOY, HNSW, and more, Milvus was designed for similarity search on dense vector datasets containing millions, billions, or even trillions of vectors.
Standalone and cluster
Milvus offers two ways of deployment - standalone or cluster. In Milvus standalone, since all nodes are deployed together, we can see Milvus as one single process. Currently, Milvus standalone relies on MinIO and etcd for data persistence and metadata storage. In future releases, we hope to eliminate these two third-party dependencies to ensure the simplicity of the Milvus system. Milvus cluster includes eight microservice components and three third-party dependencies: MinIO, etcd, and Pulsar. Pulsar serves as the log broker and provides log pub/sub services.
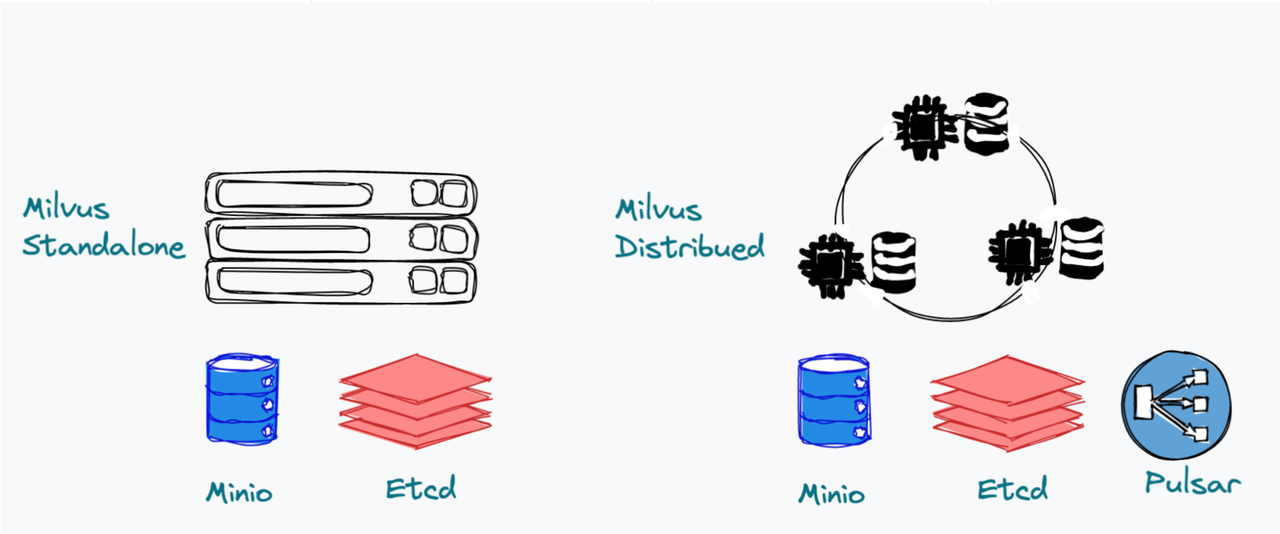 Standalone and cluster
Standalone and cluster
A bare-bones skeleton of the Milvus architecture
Milvus separates data flow from control flow, and is divided into four layers that are independent in terms of scalability and disaster recovery.
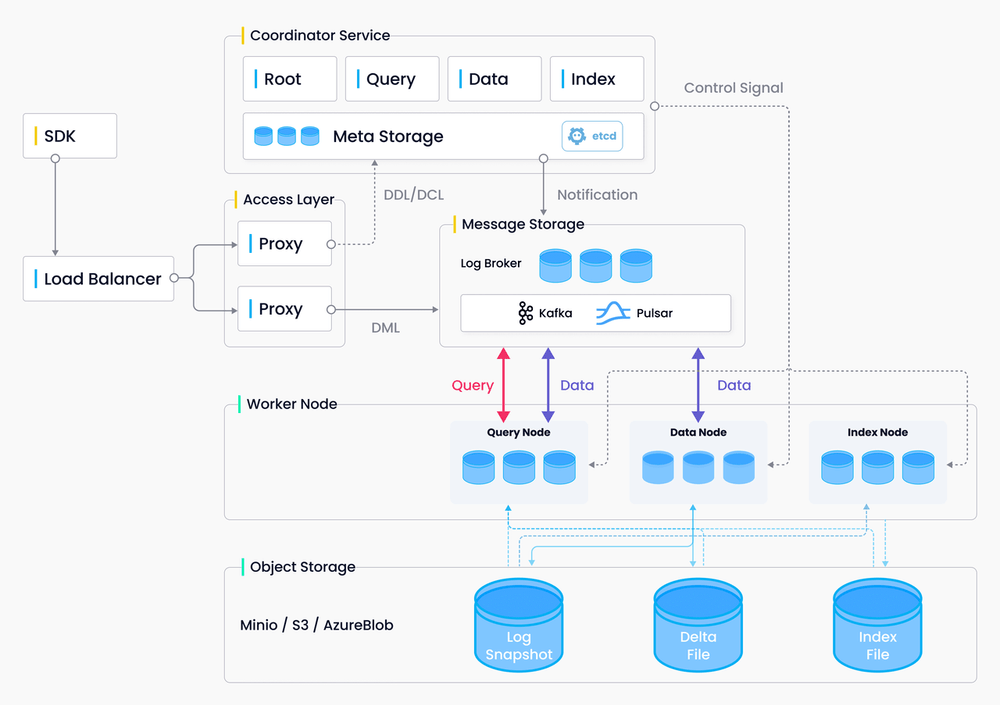 Milvus architecture
Milvus architecture
Access layer
The access layer acts as the system’s face, exposing the endpoint of the client connection to the outside world. It is responsible for processing client connections, carrying out static verification, basic dynamic checks for user requests, forwarding requests, and gathering and returning results to the client. The proxy itself is stateless and provides unified access addresses and services to the outside world through load balancing components (Nginx, Kubernetess Ingress, NodePort, and LVS). Milvus uses a massively parallel processing (MPP) architecture, where proxies return results gathered from worker nodes after global aggregation and post-processing.
Coordinator service
The coordinator service is the system’s brain, responsible for cluster topology node management, load balancing, timestamp generation, data declaration, and data management. For a detailed explanation of the function of each coordinator service, read the Milvus technical documentation.
Worker nodes
The worker, or execution, node acts as the limbs of the system, executing instructions issued by the coordinator service and the data manipulation language (DML) commands initiated by the proxy. A worker node in Milvus is similar to a data node in Hadoop, or a region server in HBase. Each type of worker node corresponds to a coord service. For a detailed explanation of the function of each worker node, read the Milvus technical documentation.
Storage
Storage is the cornerstone of Milvus, responsible for data persistence. The storage layer is divided into three parts:
- Meta store: Responsible for storing snapshots of meta data such as collection schema, node status, message consumption checkpoints, etc. Milvus relies on etcd for these functions and Etcd also assumes the responsibility of service registration and health checks.
- Log broker: A pub/sub system that supports playback and is responsible for streaming data persistence, reliable asynchronous query execution, event notifications, and returning query results. When nodes are performing downtime recovery, the log broker ensures the integrity of incremental data through log broker playback. Milvus cluster uses Pulsar as its log broker, while the standalone mode uses RocksDB. Streaming storage services such as Kafka and Pravega can also be used as log brokers.
- Object storage: Stores snapshot files of logs, scalar/vector index files, and intermediate query processing results. Milvus supports AWS S3 and Azure Blob, as well as MinIO, a lightweight, open-source object storage service. Due to the high access latency and billing per query of object storage services, Milvus will soon support memory/SSD-based cache pools and hot/cold data separation to improve performance and reduce costs.
Data Model
The data model organizes the data in a database. In Milvus, all data are organized by collection, shard, partition, segment, and entity.
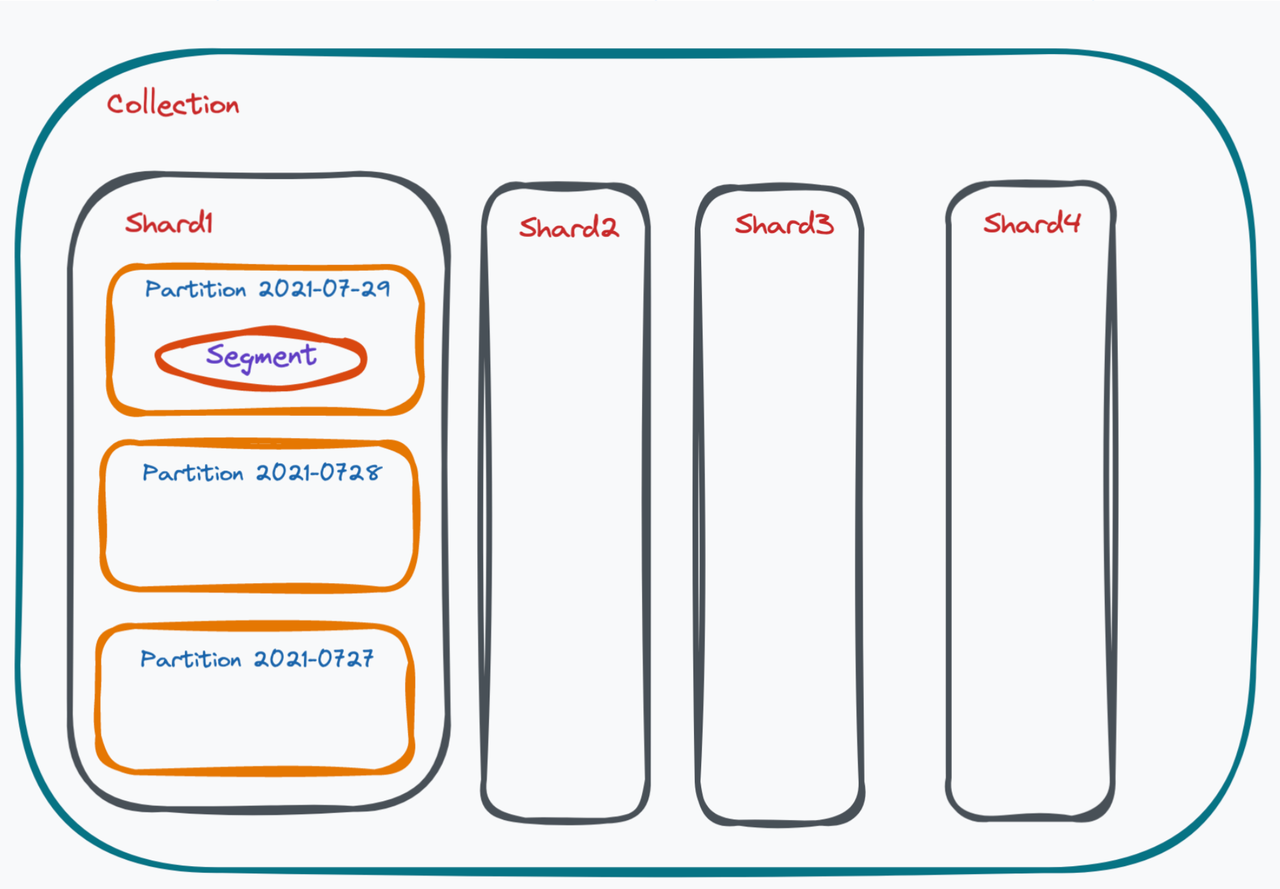 Data model 1
Data model 1
Collection
A collection in Milvus can be likened to a table in a relational storage system. Collection is the biggest data unit in Milvus.
Shard
To take full advantage of the parallel computing power of clusters when writing data, collections in Milvus must spread data writing operations to different nodes. By default, a single collection contains two shards. Depending on your dataset volume, you can have more shards in a collection. Milvus uses a master key hashing method for sharding.
Partition
There are also multiple partitions in a shard. A partition in Milvus refers to a set of data marked with the same label in a collection. Common partitioning methods including partitioning by date, gender, user age, and more. Creating partitions can benefit the query process as tremendous data can be filtered by partition tag.
In comparison, sharding is more of scaling capabilities when writing data, while partitioning is more of enhancing system performance when reading data.
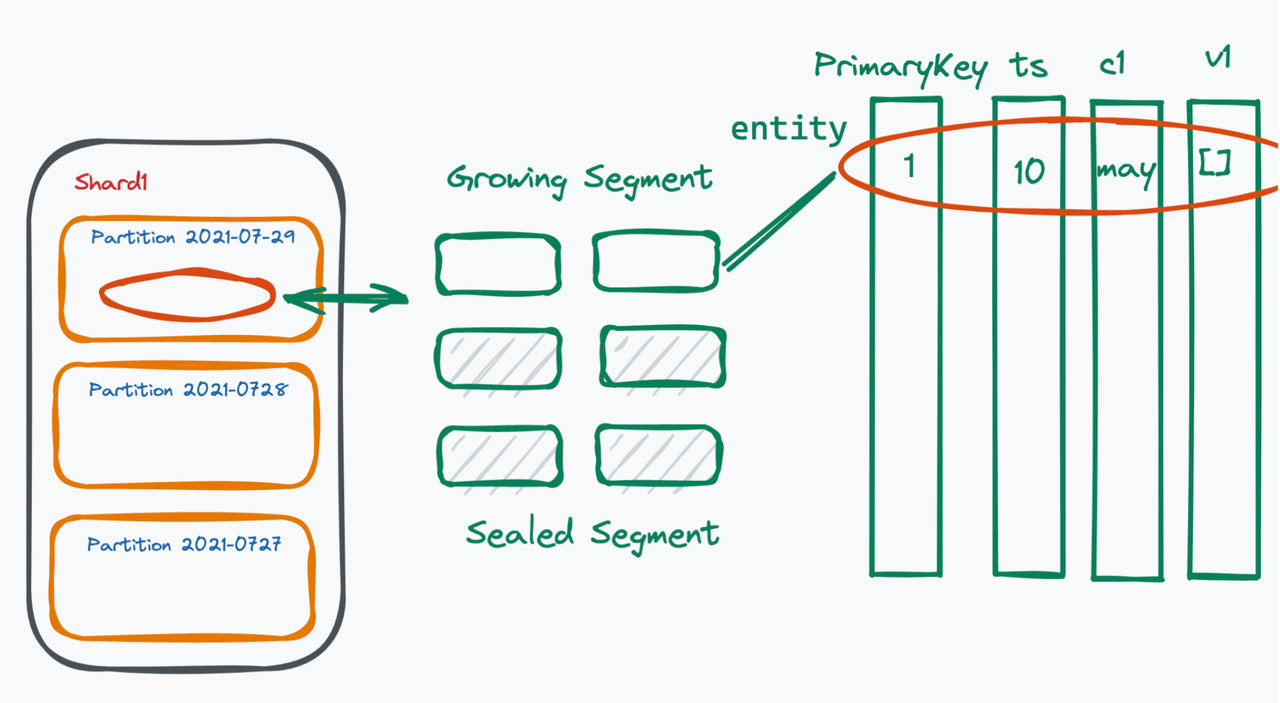 Data model 2
Data model 2
Segments
Within each partition, there are multiple small segments. A segment is the smallest unit for system scheduling in Milvus. There are two types of segments, growing and sealed. Growing segments are subscribed by query nodes. The Milvus user keeps writing data into growing segments. When the size of a growing segment reaches an upper limit (512 MB by default), the system will not allow writing extra data into this growing segment, hence sealing this segment. Indexes are built on sealed segments.
To access data in real time, the system reads data in both growing segments and sealed segments.
Entity
Each segment contains massive amount of entities. An entity in Milvus is equivalent to a row in a traditional database. Each entity has a unique primary key field, which can also be automatically generated. Entities must also contain timestamp (ts), and vector field - the core of Milvus.
About the Deep Dive Series
With the official announcement of general availability of Milvus 2.0, we orchestrated this Milvus Deep Dive blog series to provide an in-depth interpretation of the Milvus architecture and source code. Topics covered in this blog series include:
- Unstructured data requires a complete basic software stack
- Vectors and scalars
- From vector search engine to vector database
- A cloud-native first approach
- The design principles of Milvus 2.0
- Log as data
- Duality of table and log
- Log persistency
- Building a vector database for scalable similarity search
- Standalone and cluster
- A bare-bones skeleton of the Milvus architecture
- Data Model
- About the Deep Dive Series
On This Page
Try Managed Milvus for Free
Zilliz Cloud is hassle-free, powered by Milvus and 10x faster.
Get StartedLike the article? Spread the word



