Data Insertion and Data Persistence in a Vector Database
 Cover image
Cover image
This article is written by Bingyi Sun and transcreated by Angela Ni.
In the previous post in the Deep Dive series, we have introduced how data is processed in Milvus, the world’s most advanced vector database. In this article, we will continue to examine the components involved in data insertion, illustrate the data model in detail, and explain how data persistence is achieved in Milvus.
Jump to:
- Milvus architecture recap
- The portal of data insertion requests
- Data coord and data node
- Root coord and Time Tick
- Data organization: collection, partition, shard (channel), segment
- Data allocation: when and how
- Binlog file structure and data persistence
Milvus architecture recap
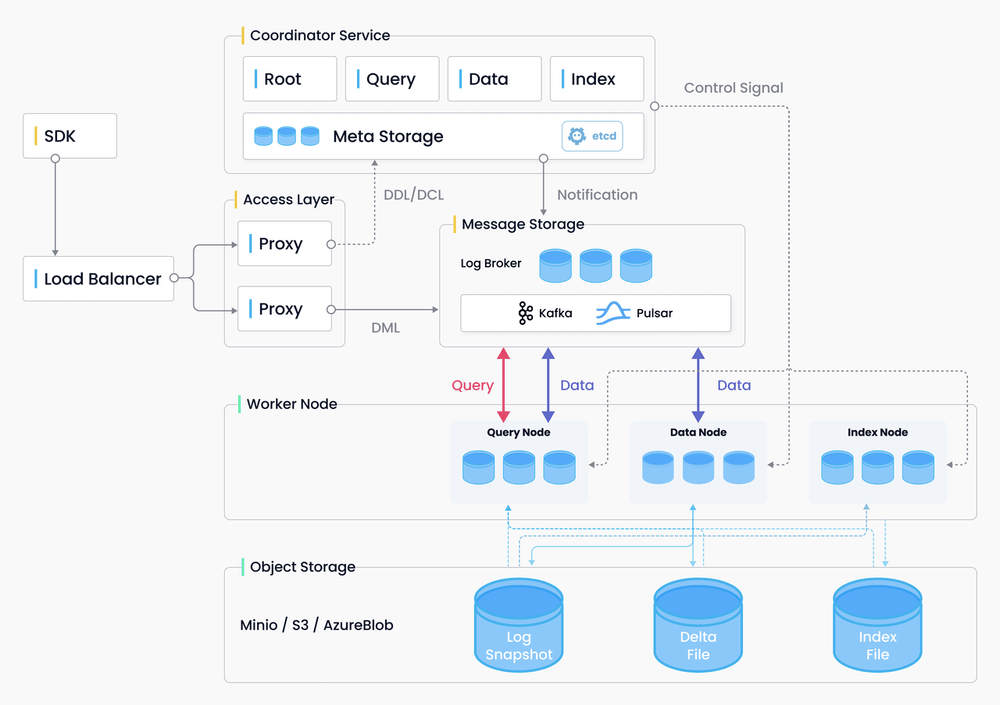 Milvus architecture.
Milvus architecture.
SDK sends data requests to proxy, the portal, via load balancer. Then the proxy interacts with coordinator service to write DDL (data definition language) and DML (data manipulation language) requests into message storage.
Worker nodes, including query node, data node, and index node, consume the requests from message storage. More specifically, the query node is in charge of data query; the data node is responsible for data insertion and data persistence; and the index node mainly deals with index building and query acceleration.
The bottom layer is object storage, which mainly leverages MinIO, S3, and AzureBlob for storing logs, delta binlogs, and index files.
The portal of data insertion requests
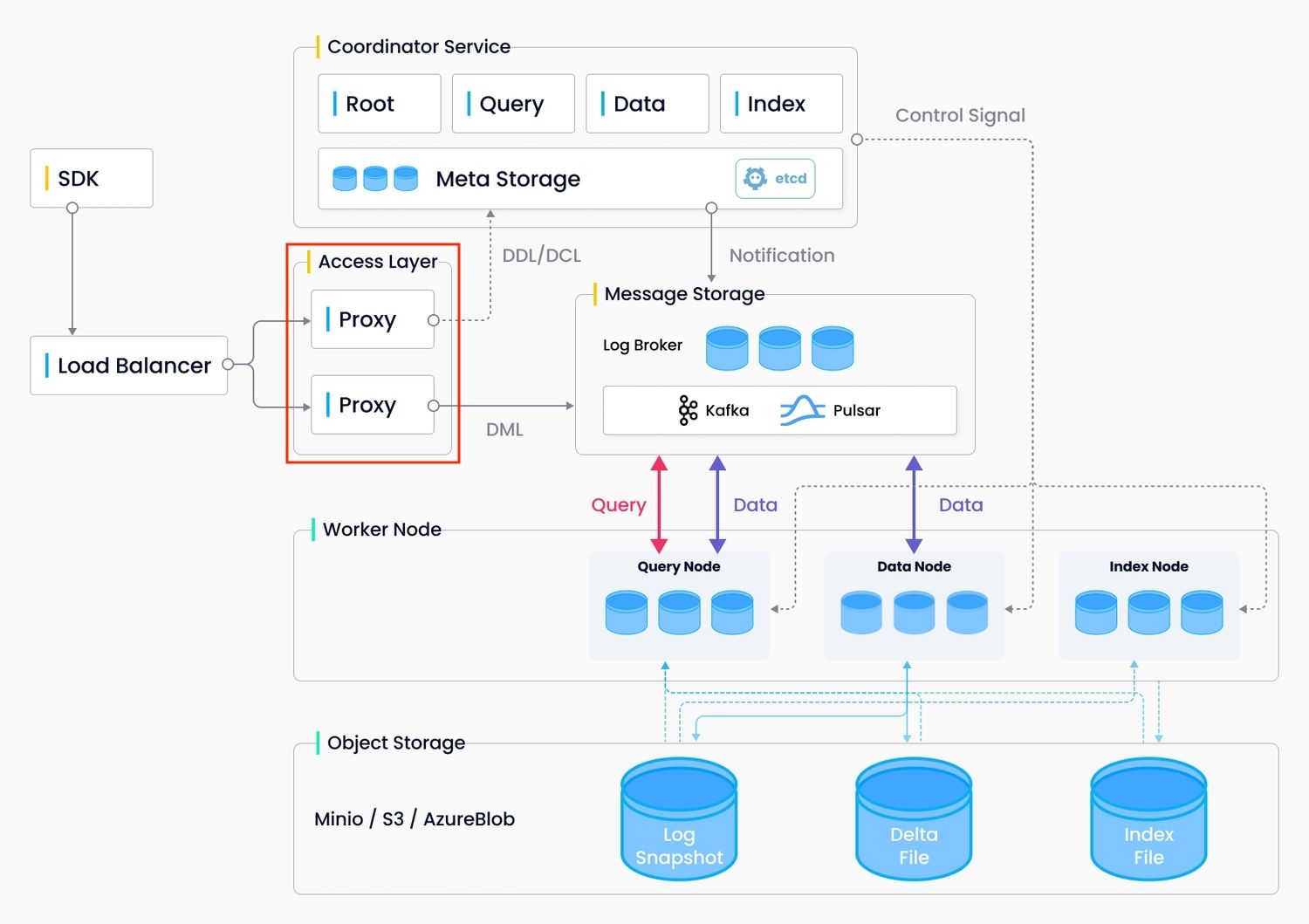 Proxy in Milvus.
Proxy in Milvus.
Proxy serves as a portal of data insertion requests.
- Initially, proxy accepts data insertion requests from SDKs, and allocates those requests into several buckets using hash algorithm.
- Then the proxy requests data coord to assign segments, the smallest unit in Milvus for data storage.
- Afterwards, the proxy inserts information of the requested segments into message store so that these information will not be lost.
Data coord and data node
The main function of data coord is to manage channel and segment allocation while the main function of data node is to consume and persist inserted data.
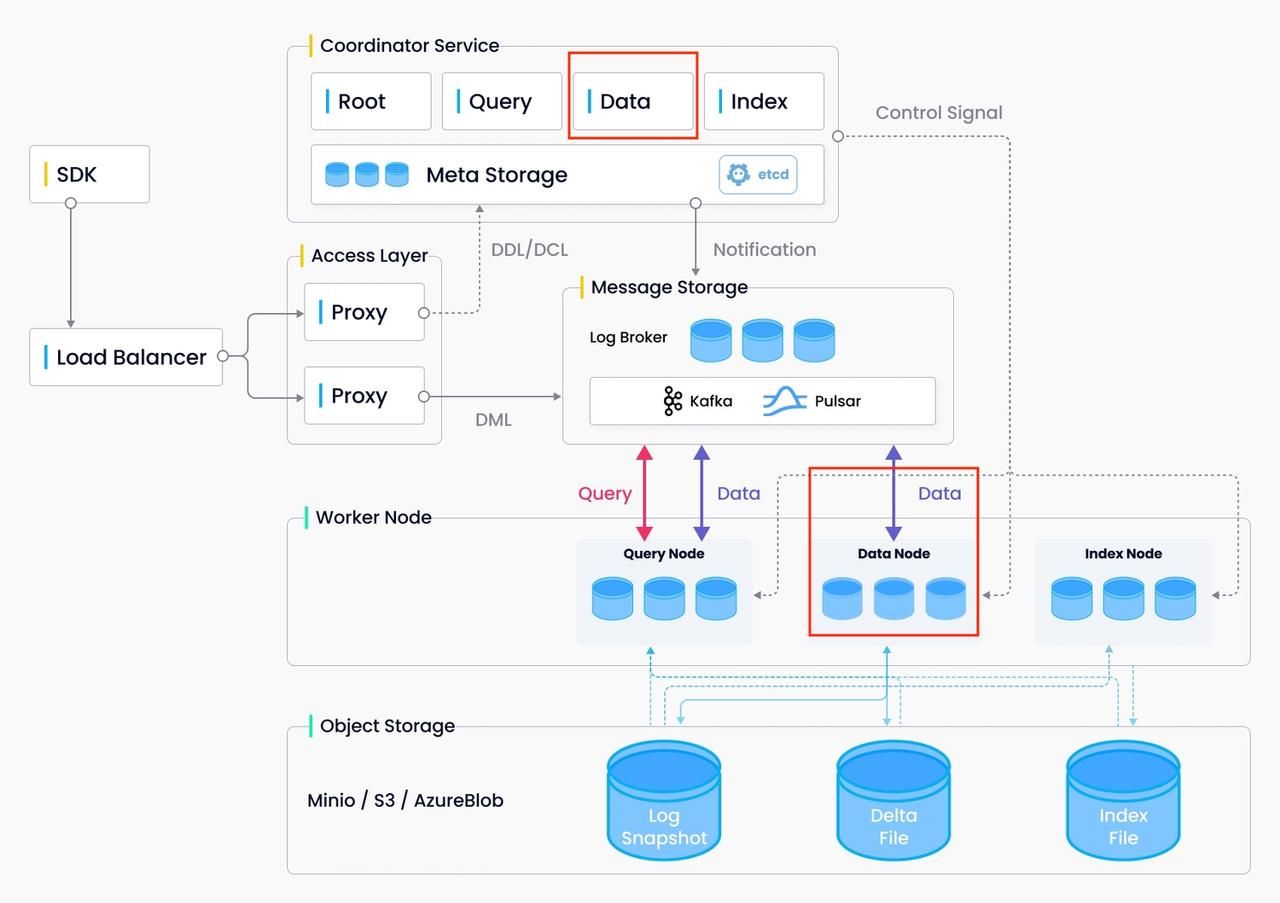 Data coord and data node in Milvus.
Data coord and data node in Milvus.
Function
Data coord serves in the following aspects:
Allocate segment space Data coord allocates space in growing segments to the proxy so that the proxy can use free space in segments to insert data.
Record segment allocation and the expiry time of the allocated space in the segment The space within each segment allocated by the data coord is not permanent, therefore, the data coord also needs to keep a record of the expiry time of each segment allocation.
Automatically flush segment data If the segment is full, the data coord automatically triggers data flush.
Allocate channels to data nodes A collection can have multiple vchannels. Data coord determines which vchannels are consumed by which data nodes.
Data node serves in the following aspects:
Consume data Data node consumes data from the channels allocated by data coord and creates a sequence for the data.
Data persistence Cache inserted data in memory and auto-flush those inserted data to disk when data volume reach a certain threshold.
Workflow
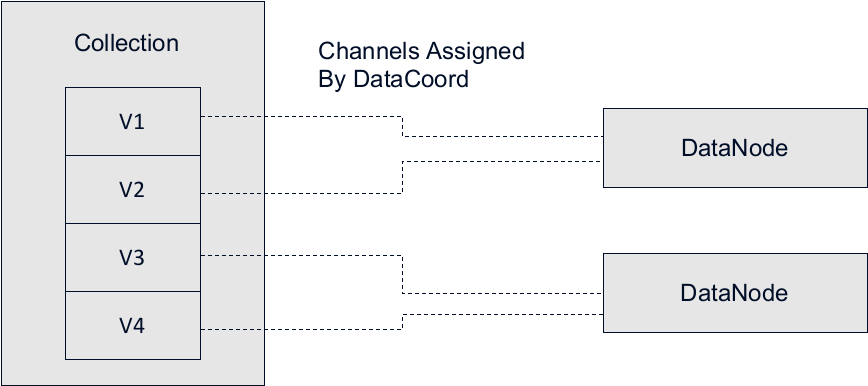 One vchannel can only be assigned to one data node.
One vchannel can only be assigned to one data node.
As shown in the image above, the collection has four vchannels (V1, V2, V3, and V4) and there are two data nodes. It is very likely that data coord will assign one data node to consume data from V1 and V2, and the other data node from V3 and V4. One single vchannel cannot be assigned to multiple data nodes and this is to prevent repetition of data consumption, which will otherwise cause the same batch of data being inserted into the same segment repetitively.
Root coord and Time Tick
Root coord manages TSO (timestamp Oracle), and publishes time tick messages globally. Each data insertion request has a timestamp assigned by root coord. Time Tick is the cornerstone of Milvus which acts like a clock in Milvus and signifies at which point of time is the Milvus system in.
When data are written in Milvus, each data insertion request carries a timestamp. During data consumption, each time data node consumes data whose timestamps are within a certain range.
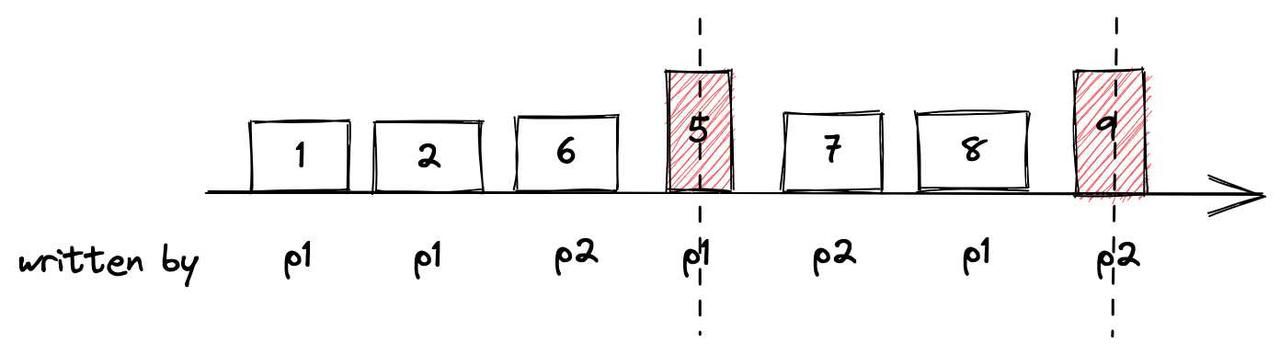 An example of data insertion and data consumption based on timestamp.
An example of data insertion and data consumption based on timestamp.
The image above is the process of data insertion. The value of the timestamps are represented by numbers 1,2,6,5,7,8. The data are written into the system by two proxies: p1 and p2. During data consumption, if the current time of the Time Tick is 5, data nodes can only read data 1 and 2. Then during the second read, if the current time of the Time Tick becomes 9, data 6,7,8 can be read by data node.
Data organization: collection, partition, shard (channel), segment
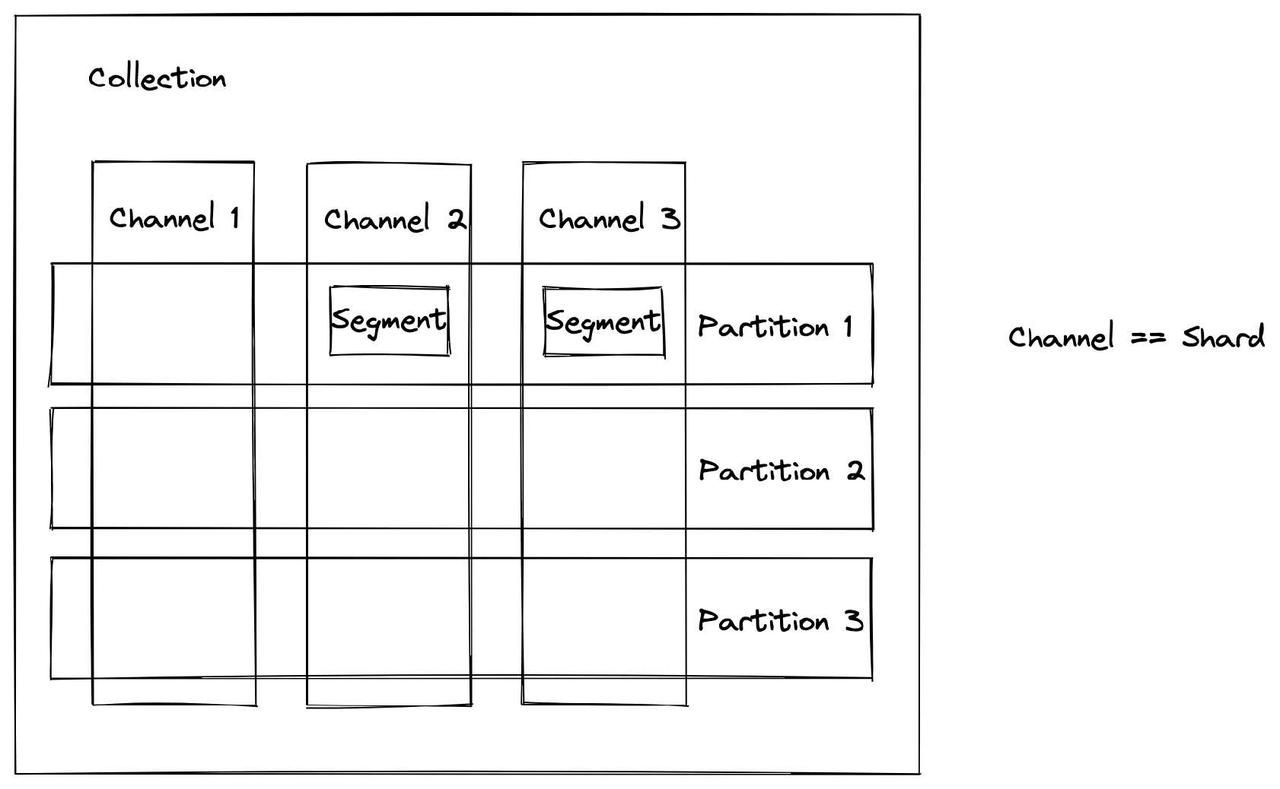 Data organization in Milvus.
Data organization in Milvus.
Read this article first to understand the data model in Milvus and the concepts of collection, shard, partition, and segment.
In summary, the largest data unit in Milvus is a collection which can be likened to a table in a relational database. A collection can have multiple shards (each corresponding to a channel) and multiple partitions within each shard. As shown in the illustration above, channels (shards) are the vertical bars while the partitions are the horizontal ones. At each intersection is the concept of segment, the smallest unit for data allocation. In Milvus, indexes are built on segments. During a query, the Milvus system also balances query loads in different query nodes and this process is conducted based on the unit of segments. Segments contain several binlogs, and when the segment data are consumed, a binlog file will be generated.
Segment
There are three types of segments with different status in Milvus: growing, sealed, and flushed segment.
Growing segment
A growing segment is a newly created segment that can be allocated to the proxy for data insertion. The internal space of a segment can be used, allocated, or free.
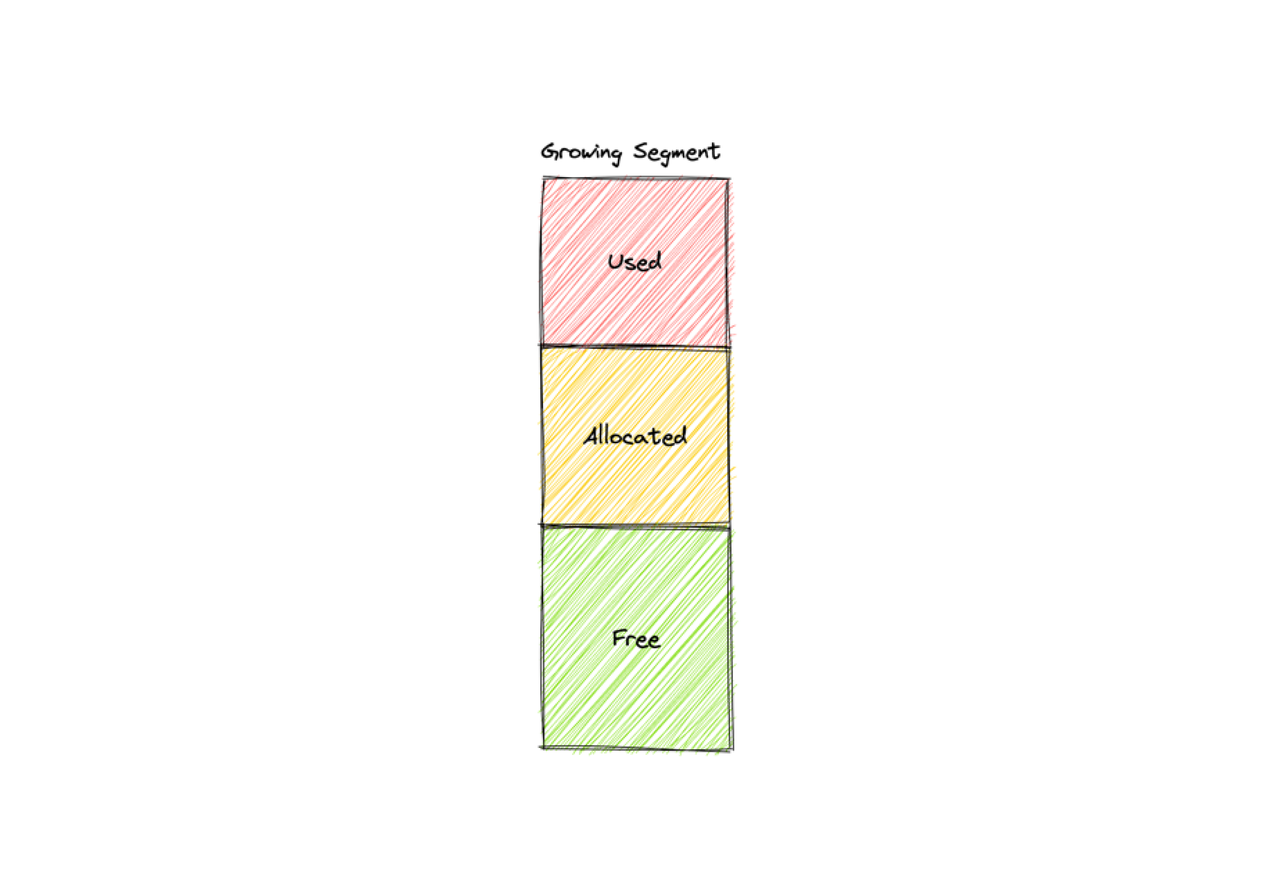 Three status in a growing segment
Three status in a growing segment
- Used: this part of space of a growing segment has been consumed by data node.
- Allocated: this part of space of a growing segment has been requested by the proxy and allocated by data coord. Allocated space will expire after a certain period time.
- Free: this part of space of a growing segment has not been used. The value of free space equals the overall space of the segment subtracted by the value of used and allocated space. So the free space of a segment increases as the allocated space expires.
Sealed segment
A sealed segment is a closed segment that can no longer be allocated to the proxy for data insertion.
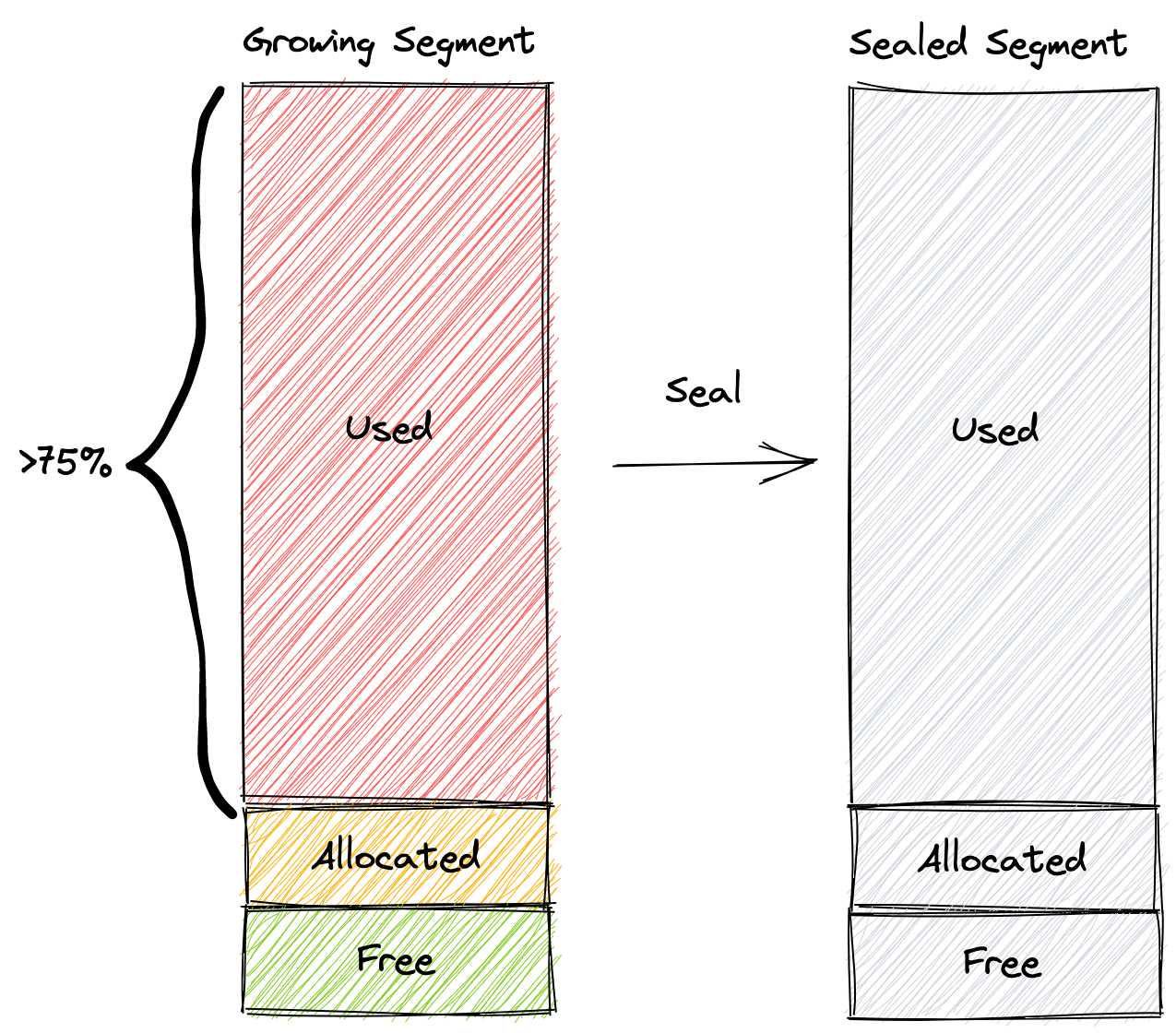 Sealed segment in Milvus
Sealed segment in Milvus
A growing segment is sealed in the following circumstances:
- If the used space in a growing segment reaches 75% of the total space, the segment will be sealed.
- Flush() is manually called by a Milvus user to persist all data in a collection.
- Growing segments that are not sealed after a long period of time will be sealed as too many growing segments cause data nodes to over-consume memory.
Flushed segment
A flushed segment is a segment that has already been written into disk. Flush refers to storing segment data to object storage for the sake of data persistence. A segment can only be flushed when the allocated space in a sealed segment expires. When flushed, the sealed segment turns into a flushed segment.
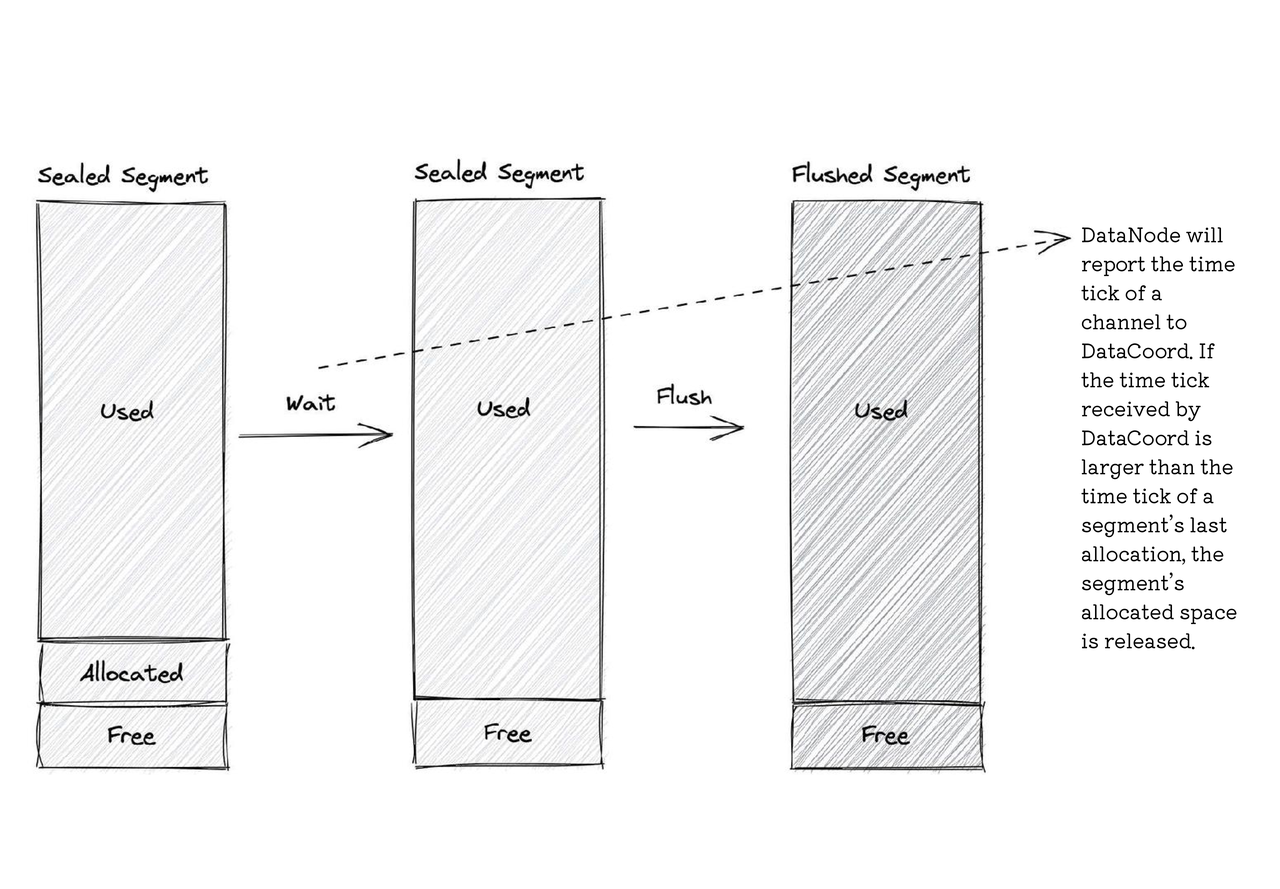 Flushed segment in Milvus
Flushed segment in Milvus
Channel
A channel is allocated :
- When data node starts or shuts down; or
- When segment space allocated is requested by proxy.
Then there are several strategies of channel allocation. Milvus supports 2 of the strategies:
- Consistent hashing
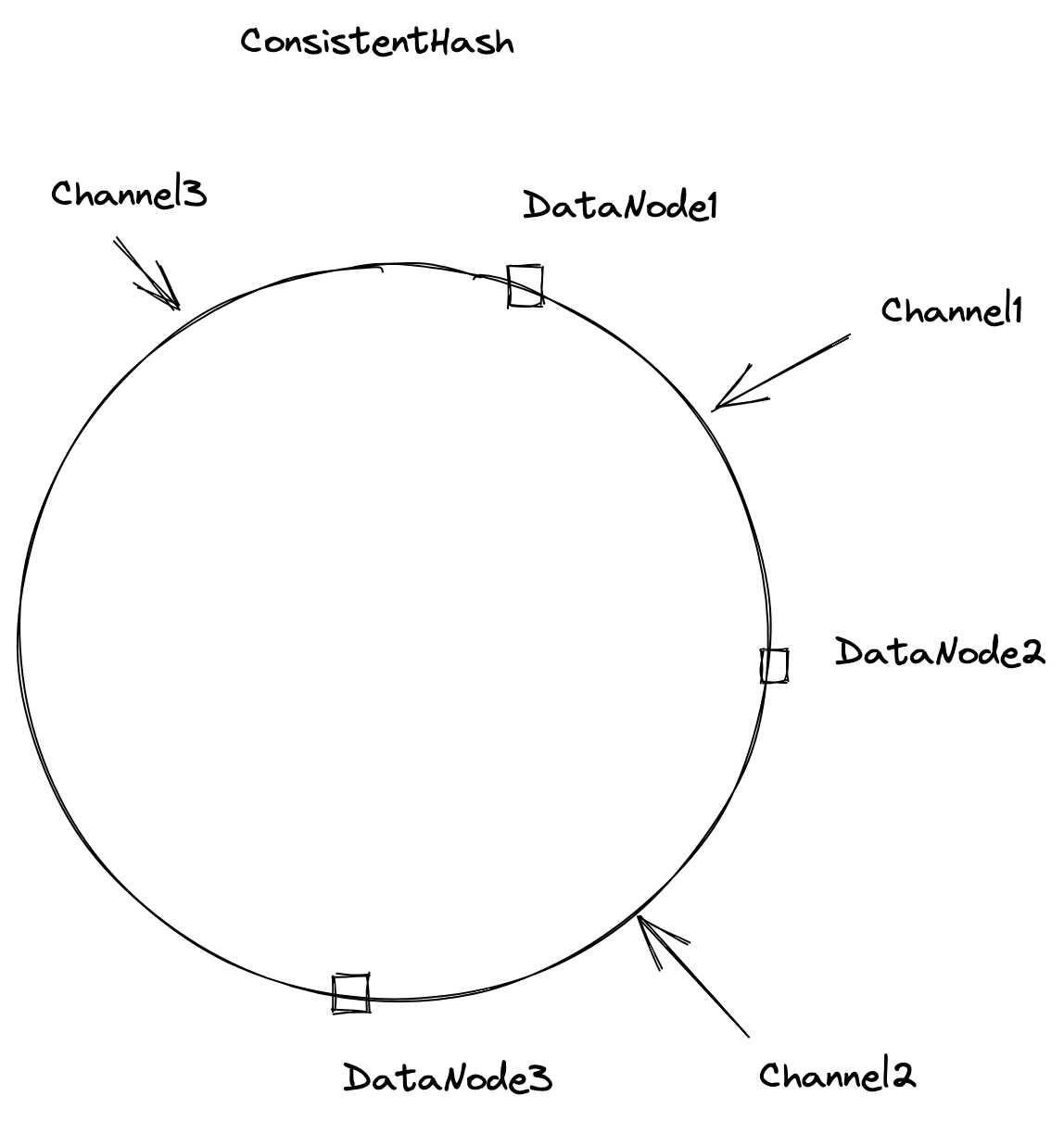 Consistency hashing in Milvus
Consistency hashing in Milvus
The default strategy in Milvus. This strategy leverages the hashing technique to assign each channel a position on the ring, then searches in a clock-wise direction to find the nearest data node to a channel. Thus, in the illustration above, channel 1 is allocated to data node 2, while channel 2 is allocated to data node 3.
However, one problem with this strategy is that the increase or decrease in the number of data nodes (eg. A new data node starts or a data node suddenly shuts down) can affect the process of channel allocation. To solve this issue, data coord monitors the status of data nodes via etcd so that data coord can be immediately notified if there is any change in the status of data nodes. Then data coord further determines to which data node to allocate the channels properly.
- Load balancing
The second strategy is to allocate channels of the same collection to different data nodes, ensuring the channels are evenly allocated. The purpose of this strategy is to achieve load balance.
Data allocation: when and how
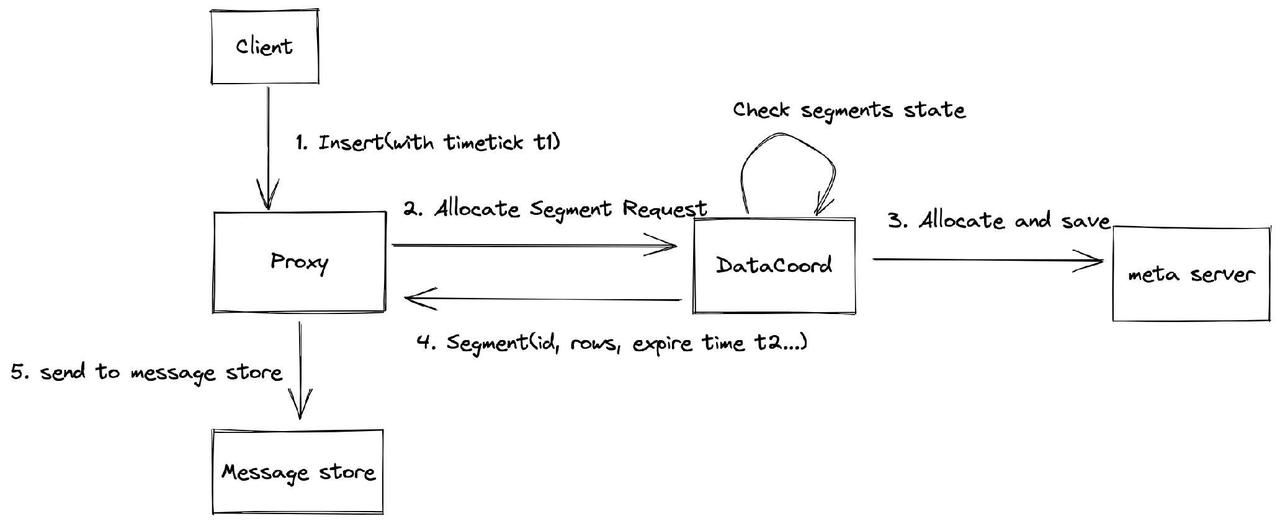 The process of data allocation in Milvus
The process of data allocation in Milvus
The process of data allocation starts from the client. It first sends data insertion requests with a timestamp t1 to proxy. Then the proxy sends a request to data coord for segment allocation.
Upon receiving the segment allocation request, the data coord checks segment status and allocates segment. If the current space of the created segments is sufficient for the newly inserted rows of data, the data coord allocates those created segments. However, if the space available in current segments is not sufficient, the data coord will allocate a new segment. The data coord can return one or more segments upon each request. In the meantime, the data coord also saves the allocated segment in meta server for data persistence.
Subsequently, the data coord returns the information of the allocated segment (including segment ID, number of rows, expiry time t2, etc.) to the proxy. The proxy sends such information of the allocated segment to message store so that these information are properly recorded. Note that the value of t1 must be smaller than that of t2. The default value of t2 is 2,000 millisecond and it can be changed by configuring the parameter segment.assignmentExpiration in the data_coord.yaml file.
Binlog file structure and data persistence
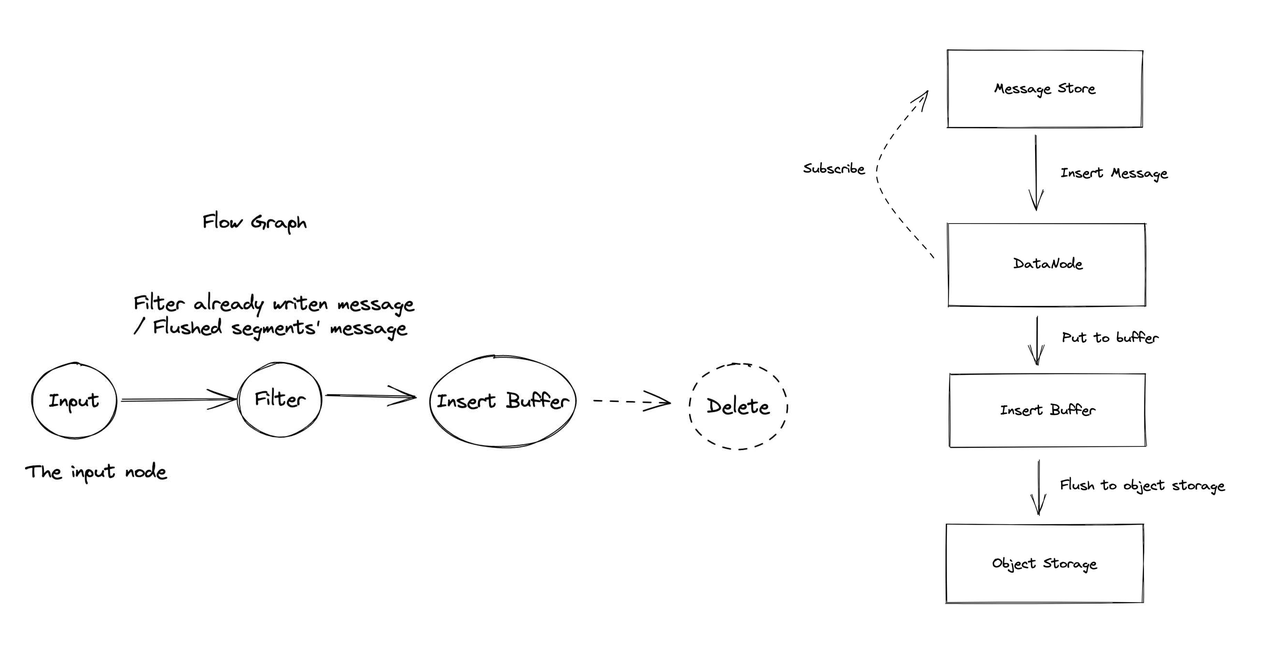 Data node flush
Data node flush
Data node subscribes to the message store because data insertion requests are kept in the message store and the data nodes can thus consume insert messages. The data nodes first place insert requests in an insert buffer, and as the requests accumulate, they will be flushed to object storage after reaching a threshold.
Binlog file structure
 Binlog file structure.
Binlog file structure.
The binlog file structure in Milvus is similar to that in MySQL. Binlog is used to serve two functions: data recovery and index building.
A binlog contains many events. Each event has an event header and event data.
Metadata including binlog creation time, write node ID, event length, and NextPosition (offset of the next event), etc. are written in the event header.
Event data can be divided into two parts: fixed and variable.
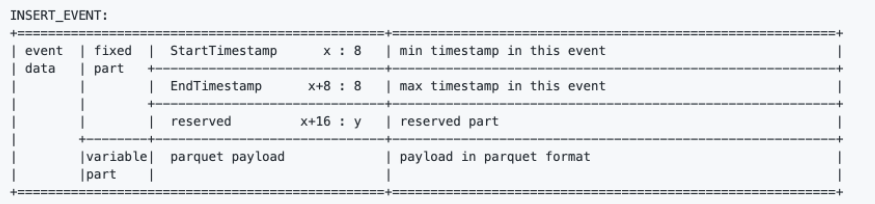 File structure of an insert event.
File structure of an insert event.
The fixed part in the event data of an INSERT_EVENT contains StartTimestamp, EndTimestamp, and reserved.
The variable part in fact stores inserted data. The insert data are sequenced into the format of parquet and stored in this file.
Data persistence
If there are multiple columns in schema, Milvus will store binlogs in columns.
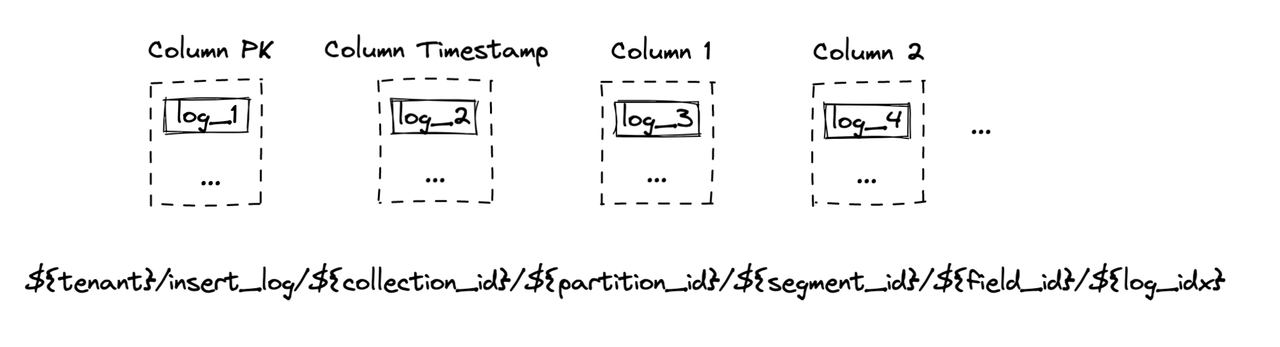 Binlog data persistence.
Binlog data persistence.
As illustrated in the image above, the first column is primary key binlog. The second one is timestamp column. The rest are the columns defined in schema. The file path of binlogs in MinIO is also indicated in the image above.
About the Deep Dive Series
With the official announcement of general availability of Milvus 2.0, we orchestrated this Milvus Deep Dive blog series to provide an in-depth interpretation of the Milvus architecture and source code. Topics covered in this blog series include:
- Milvus architecture recap
- The portal of data insertion requests
- Data coord and data node
- Function
- Workflow
- Root coord and Time Tick
- Data organization: collection, partition, shard (channel), segment
- Segment
- Channel
- Data allocation: when and how
- Binlog file structure and data persistence
- Binlog file structure
- Data persistence
- About the Deep Dive Series
On This Page
Try Managed Milvus for Free
Zilliz Cloud is hassle-free, powered by Milvus and 10x faster.
Get StartedLike the article? Spread the word



