No Python, No Problem: Model Inference with ONNX in Java, or Any Other Language
It has never been easier to build Generative AI applications. A rich ecosystem of tools, AI models, and datasets allows even non-specialized software engineers to build impressive chatbots, image generators, and more. This tooling, for the most part, is made for Python and builds on top of PyTorch. But what about when you don’t have access to Python in production and need to use Java, Golang, Rust, C++, or another language?
We will restrict ourselves to model inference, including both embedding models and foundation models; other tasks, such as model training and fine-tuning, are not typically completed at deployment time. What are our options for model inference without Python? The most obvious solution is to utilize an online service from providers like Anthropic or Mistral. They typically provide an SDK for languages other than Python, and if they didn’t, it would require only simple REST API calls. But what if our solution has to be entirely local due to, for example, compliance or privacy concerns?
Another solution is to run a Python server locally. The original problem was posed as being unable to run Python in production, so that rules out using a local Python server. Related local solutions will likely suffer similar legal, security-based, or technical restrictions. We need a fully contained solution that allows us to call the model directly from Java or another non-Python language.

Figure 1: A Python metamorphoses into an Onyx butterfly.
What is ONNX (Open Neural Network Exchange)?
ONNX (Open Neural Network Exchange) is a platform-agnostic ecosystem of tools for performing neural network model inference. It was initially developed by the PyTorch team at Meta (then Facebook), with further contributions from Microsoft, IBM, Huawei, Intel, AMD, Arm, and Qualcomm. Currently, it is an open-source project owned by the Linux Foundation for AI and Data. ONNX is the de facto method for distributing platform-agnostic neural network models.
![]()
Figure 2: A (partial) ONNX computational graph for a NN transformer
We typically use “ONNX” in a narrower sense to refer to its file format. An ONNX model file represents a computational graph, often including the weight values of a mathematical function, and the standard defines common operations for neural networks. You can think of it similarly to the computational graph created when you use autodiff with PyTorch. From another perspective, the ONNX file format serves as an intermediate representation (IR) for neural networks, much like native code compilation, which also involves an IR step. See the illustration above visualizing an ONNX computational graph.
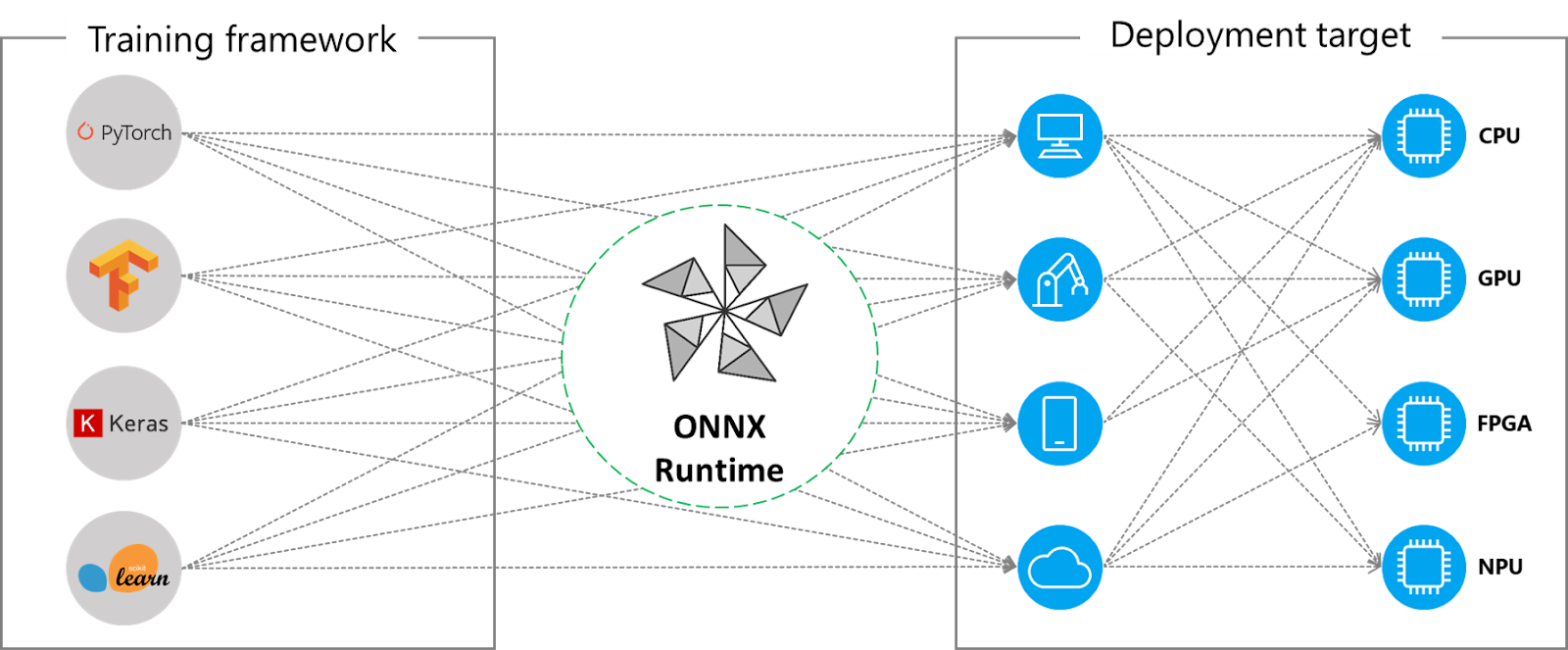
Figure 3: An IR allows many combinations of front-ends and back-ends
The ONNX file format is just one part of the ONNX ecosystem, which also includes libraries for manipulating computational graphs and libraries for loading and running ONNX model files. These libraries span languages and platforms. Since ONNX is just an IR (Intermediate Representation Language), optimizations specific to a given hardware platform can be applied before running it with native code. See the figure above illustrating combinations of front-ends and back-ends.
ONNX Workflow
For discussion purposes, we will investigate calling a text embedding model from Java, for example, in preparation for data ingestion to the open-source vector database Milvus. So, if we are to call our embedding or foundation model from Java, is it as simple as using the ONNX library on the corresponding model file? Yes, but we will need to procure files for both the model and the tokenizer encoder (and decoder for foundation models). We can produce these ourselves using Python offline, that is, before production, which we now explain.
Exporting NN Models from Python
Let’s open a common text embedding model, all-MiniLM-L6-v2, from Python using HuggingFace’s sentence-transformers library. We will use the HF library indirectly via .txtai’s util library since we need a wrapper around sentence-transformers that also exports the pooling and normalization layers after the transformer function. (These layers take the context-dependent token embeddings, that is, the output of the transformer, and transform it into a single text embedding.)
from txtai.pipeline import HFOnnx
path = "sentence-transformers/all-MiniLM-L6-v2"
onnx_model = HFOnnx()
model = onnx_model(path, "pooling", "model.onnx", True)
We instruct the library to export sentence-transformers/all-MiniLM-L6-v2 from the HuggingFace model hub as ONNX, specifying the task as text embedding and enabling model quantization. Calling onnx_model() will download the model from the model hub if it does not already exist locally, convert the three layers to ONNX, and combine their computational graphs.
Are we ready now to perform inference in Java? Not quite so fast. The model inputs a list of tokens (or a list of lists for more than one sample) corresponding to the tokenization of the text we wish to embed. Therefore, unless we can perform all tokenization before production time, we will need to run the tokenizer from within Java.
There are a few options for this. One involves either implementing or finding an implementation of the tokenizer for the model in question in Java or another language, and calling it from Java as a static or dynamically linked library. An easier solution is to convert the tokenizer to an ONNX file and use it from Java, just as we use the model ONNX file.
Plain ONNX, however, does not contain the necessary operations to implement the computational graph of a tokenizer. For this reason, Microsoft created a library to augment ONNX called ONNXRuntime-Extensions. It defines useful operations for all manner of data pre- and postprocessing, not only text tokenizers.
Here is how we export our tokenizer as an ONNX file:
from onnxruntime_extensions import gen_processing_models
from sentence_transformers import SentenceTransformer
embedding_model = SentenceTransformer('all-MiniLM-L6-v2')
tok_encode, _ = gen_processing_models(embedding_model.tokenizer, pre_kwargs={})
onnx_tokenizer_path = "tokenizer.onnx"
with open(tokenizer_path, "wb") as f:
f.write(tok_encode.SerializeToString())
We have discarded the decoder of the tokenizer, since embedding sentences doesn’t require it. Now, we have two files: tokenizer.onnx for tokenizing text, and model.onnx for embedding strings of tokens.
Model Inference in Java
Running our model from within Java is now trivial. Here are some of the important lines of code from the full example:
// Imports required for Java/ONNX integration
import ai.onnxruntime.*;
import ai.onnxruntime.extensions.*;
…
// Set up inference sessions for tokenizer and model
var env = OrtEnvironment.getEnvironment();
var sess_opt = new OrtSession.SessionOptions();
sess_opt.registerCustomOpLibrary(OrtxPackage.getLibraryPath());
var tokenizer = env.createSession("app/tokenizer.onnx", sess_opt);
var model = env.createSession("app/model.onnx", sess_opt);
…
// Perform inference and extract text embeddings into native Java
var results = session.run(inputs).get("embeddings");
float[][] embeddings = (float[][]) results.get().getValue();
A full working example can be found in the resources section.
Summary
We have seen in this post how it is possible to export open-source models from HuggingFace’s model hub and use them directly from languages other than Python. We note, however, some caveats:
First, the ONNX libraries and runtime extensions have varying levels of feature support. It may not be possible to use all models across all languages until a future SDK update is released. The ONNX runtime libraries for Python, C++, Java, and JavaScript are the most comprehensive.
Second, the HuggingFace hub contains pre-exported ONNX, but these models don’t include the final pooling and normalization layers. You should be aware of how sentence-transformers works if you intend to use torch.onnx directly.
Nevertheless, ONNX has the backing of major industry leaders and is on a trajectory to become a frictionless means of cross-platform Generative AI.
Resources
- What is ONNX (Open Neural Network Exchange)?
- ONNX Workflow
- Exporting NN Models from Python
- Model Inference in Java
- Summary
- Resources
On This Page
Try Managed Milvus for Free
Zilliz Cloud is hassle-free, powered by Milvus and 10x faster.
Get StartedLike the article? Spread the word



