How Is Data Processed in a Vector Database?
 Cover image
Cover image
This article is written by Zhenshan Cao and transcreated by Angela Ni.
In the previous two posts in this blog series, we have already covered the system architecture of Milvus, the world’s most advanced vector database, and its Python SDK and API.
This post mainly aims to help you understand how data is processed in Milvus by going deep into the Milvus system and examining the interaction between the data processing components.
Some useful resources before getting started are listed below. We recommend reading them first to better understand the topic in this post.
- Deep dive into the Milvus architecture
- Milvus data model
- The role and function of each Milvus component
- Data processing in Milvus
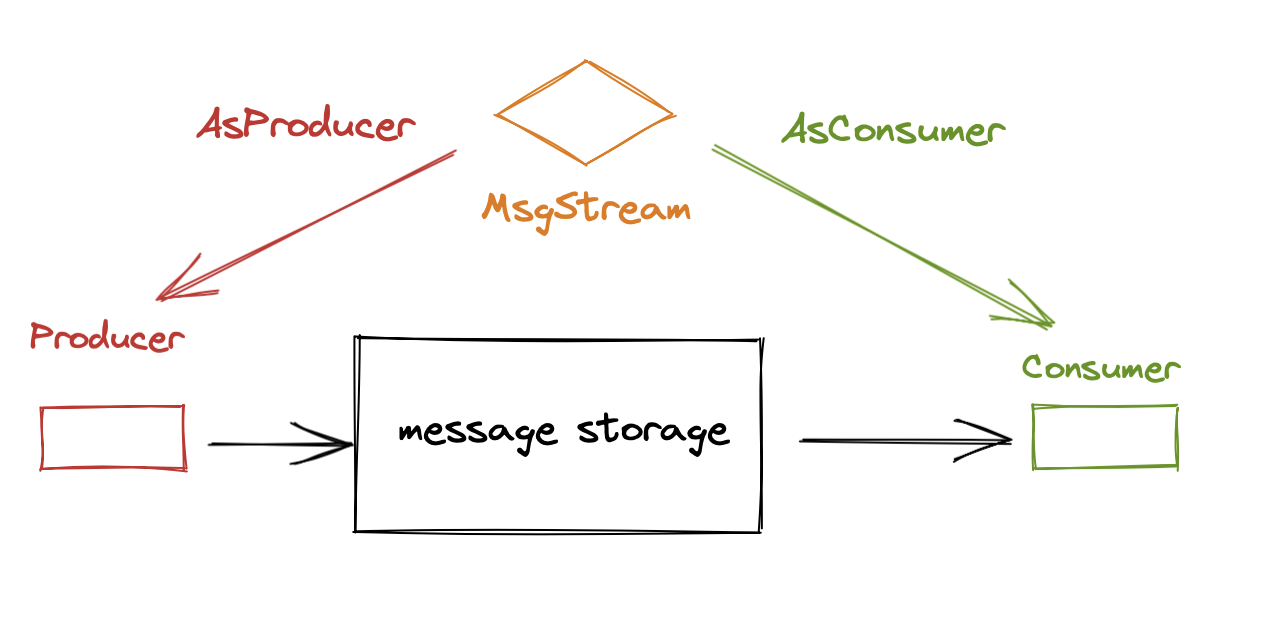
MsgStream interface
MsgStream interface is crucial to data processing in Milvus. When Start() is called, the coroutine in the background writes data into the log broker or reads data from there. When Close() is called, the coroutine stops.
 MsgStream interface
MsgStream interface
The MsgStream can serve as a producer and a consumer. The AsProducer(channels []string) interface defines MsgStream as a producer while the AsConsumer(channels []string, subNamestring)defines it as a consumer. The parameter channels is shared in both interfaces and it is used to define which (physical) channels to writes data into or read data from.
The number of shards in a collection can be specified when a collection is created. Each shard corresponds to a virtual channel (vchannel). Therefore, a collection can have multiple vchannels. Milvus assigns each vchannel in the log broker a physical channel (pchannel).
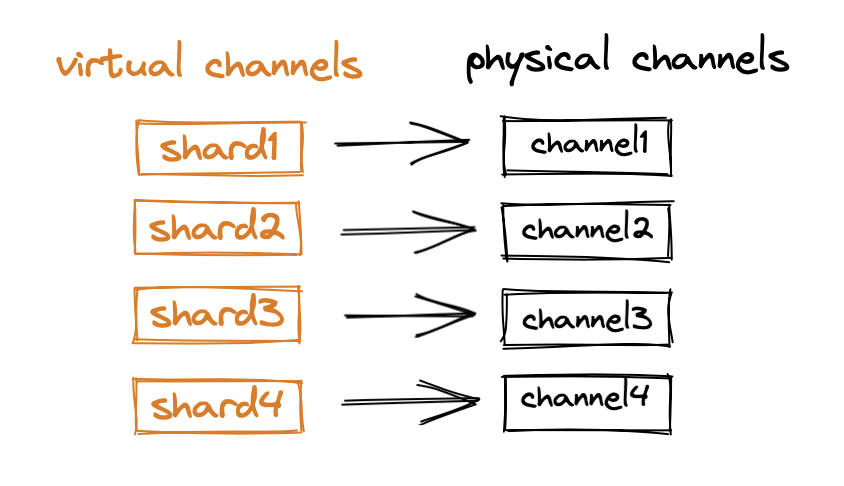 Each virtual channel/shard corresponds to a physical channel.
Each virtual channel/shard corresponds to a physical channel.
Produce() in the MsgStream interface in charge of writing data into the pchannels in log broker. Data can be written in two ways:
- Single write: entities are written into different shards (vchannel) by the hash values of primary keys. Then these entities flow into corresponding pchannels in the log broker.
- Broadcast write: entities are written into all of the pchannels specified by the parameter
channels.
Consume() is a type of blocking API. If there is no data available in the specified pchannel, the coroutine will be blocked when Consume() is called in MsgStream interface. On the other hand, Chan() is a non-blocking API, which means that the coroutine reads and processes data only if there is existing data in the specified pchannel. Otherwise, the coroutine can process other tasks and will not be blocked when there is no data available.
Seek() is method for failure recovery. When a new node is started, the data consumption record can be obtained and data consumption can resume from where it was interrupted by calling Seek().
Write data
The data written into different vchannels (shards) can either be insert message or delete message. These vchannels can also be called DmChannels (data manipulation channels).
Different collections may share the same pchannels in the log broker. One collection can have multiple shards and hence multiple corresponding vchannels. The entities in the same collection consequently flow into multiple corresponding pchannels in the log broker. As a result, the benefit of sharing pchannels is an increased volume of throughput enabled by high concurrency of the log broker.
When a collection is created, not only the number of shards is specified, but also the mapping between vchannels and pchannels in the log broker is decided.
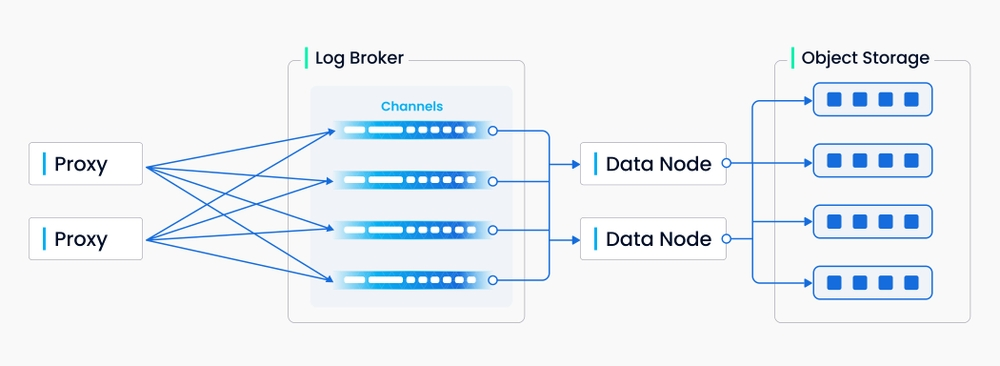 Write path in Milvus
Write path in Milvus
As shown in the illustration above, in the write path, proxies write data into the log broker via the AsProducer() interface of the MsgStream. Then data nodes consume the data, then convert and store the consumed data in object storage. The storage path is a type of meta information which will be recorded in etcd by data coordinators.
Flowgraph
Since different collections may share the same pchannels in the log broker, when consuming data, data nodes or query nodes need to judge to which collection the data in a pchannel belongs. To solve this problem, we introduced flowgraph in Milvus. It is mainly in charge of filtering data in a shared pchannel by collection IDs. So, we can say that each flowgraph handles the data stream in a corresponding shard (vchannel) in a collection.
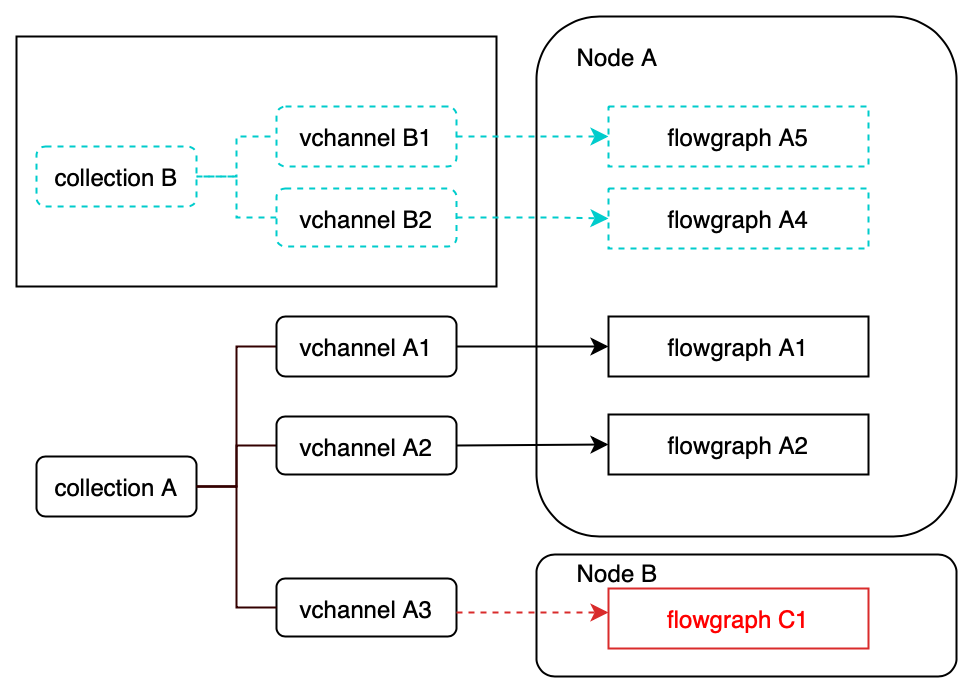 Flowgraph in write path
Flowgraph in write path
MsgStream creation
When writing data, MsgStream object is created in the following two scenarios:
- When the proxy receives a data insertion request, it first tries to obtain the mapping between vchannels and pchannels via root coordinator (root coord). Then the proxy creates an MsgStream object.
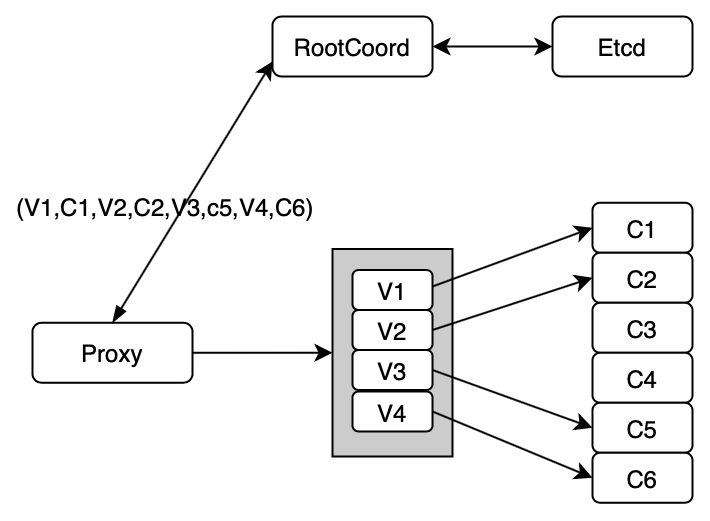 Scenario 1
Scenario 1
- When data node starts and reads the meta information of channels in etcd, the MsgStream object is created.
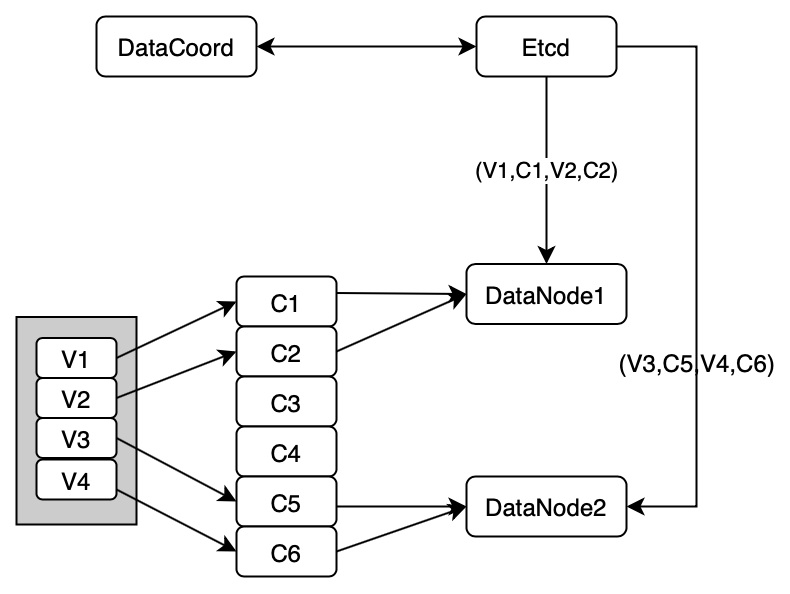 Scenario 2
Scenario 2
Read data
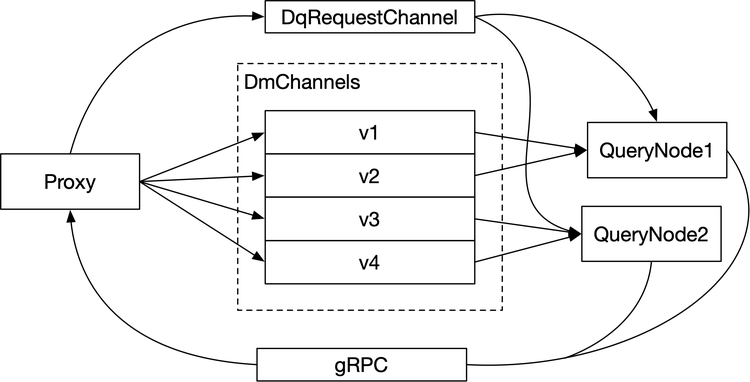 Read path in Milvus
Read path in Milvus
The general workflow of reading data is illustrated in the image above. Query requests are broadcast via DqRequestChannel to query nodes. The query nodes execute the query tasks in parallel. The query results from query nodes go through gRPC and proxy aggregate the results and returns them to the client.
To take a closer look at the data reading process, we can see that the proxy writes query requests into DqRequestChannel. Query nodes then consume message by subscribing to DqRequestChannel. Each message in the DqRequestChannel is broadcast so that all subscribed query nodes can receive the message.
When query nodes receive query requests, they conduct a local query on both batch data stored in sealed segments and streaming data that are dynamically inserted into Milvus and stored in growing segments. Afterwards, query nodes need to aggregate the query results in both sealed and growing segments. These aggregated results are passed on to proxy via gRPC.
The proxy collects all the results from multiple query nodes and then aggregate them to obtain the final results. Then the proxy returns the final query results to the client. Since each query request and its corresponding query results are labelled by the same unique requestID, proxy can figure out which query results correspond to which query request.
Flowgraph
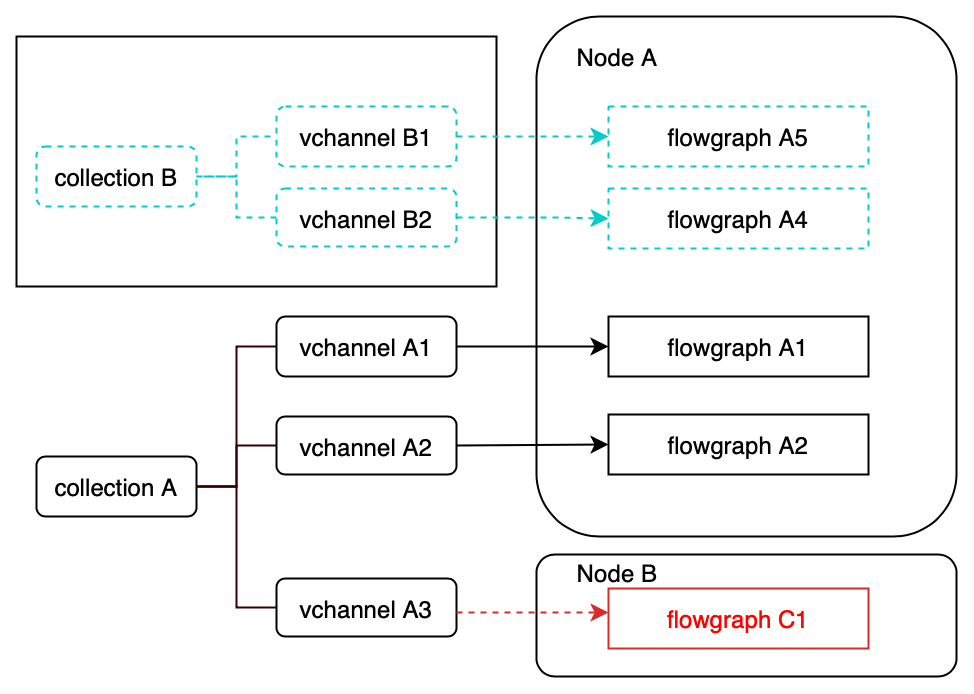 Flowgraph in read path
Flowgraph in read path
Similar to the write path, flowgraphs are also introduced in the read path. Milvus implements the unified Lambda architecture, which integrates the processing of the incremental and historical data. Therefore, query nodes need to obtain real-time streaming data as well. Similarly, flowgraphs in read path filters and differentiates data from different collections.
MsgStream creation
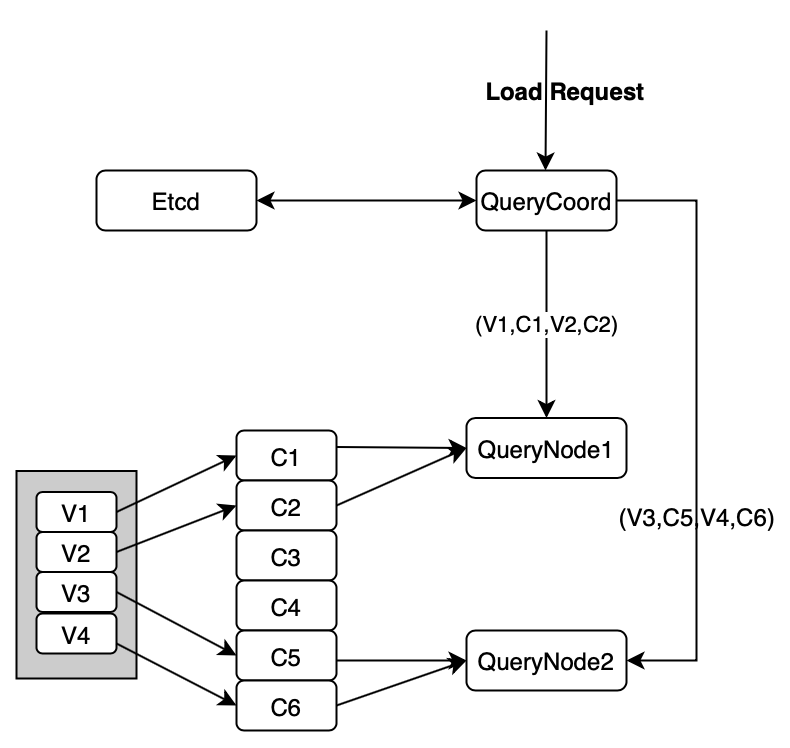 Creating MsgStream object in read path
Creating MsgStream object in read path
When reading data, the MsgStream object is created in the following scenario:
- In Milvus, data cannot be read unless they are loaded. When the proxy receives a data load request, it sends the request to query coordinator which decides the way of assigning shards to different query nodes. The assigning information (i.e. The names of vchannels and the mapping between vchannels and their corresponding pchannels) is sent to query nodes via method call or RPC (remote procedure call). Subsequently, the query nodes create corresponding MsgStream objects to consume data.
DDL operations
DDL stands for data definition language. DDL operations on metadata can be categorized into write requests and read requests. However, these two types of requests are treated equally during metadata processing.
Read requests on metadata include:
- Query collection schema
- Query indexing information And more
Write requests include:
- Create a collection
- Drop a collection
- Build an index
- Drop an index And more
DDL requests are sent to the proxy from the client, and the proxy further passes on these requests in the received order to the root coord which assigns a timestamp for each DDL request and conducts dynamic checks on the requests. Proxy handles each request in a serial manner, meaning one DDL request at a time. The proxy will not process the next request until it completes processing the previous request and receive results from the root coord.
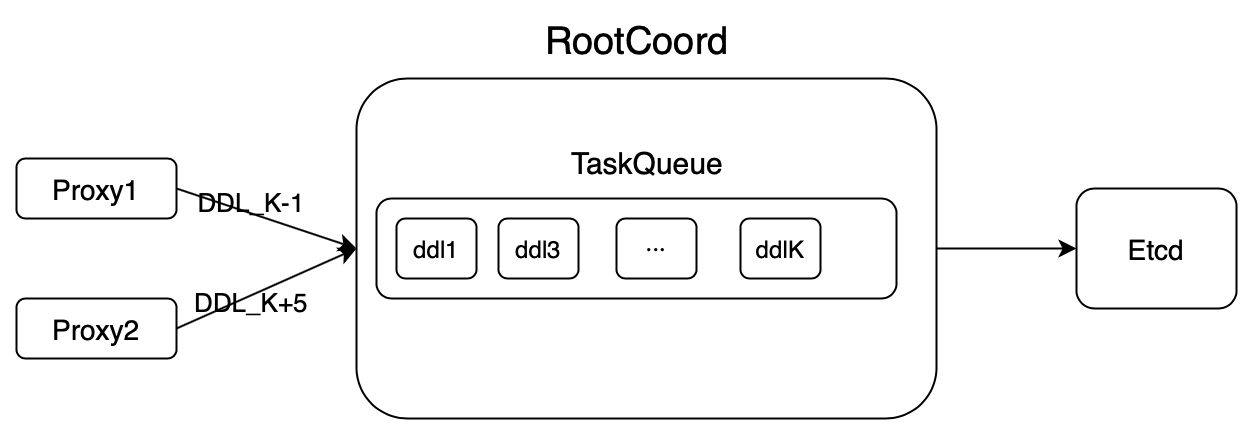 DDL operations.
DDL operations.
As shown in the illustration above, there are K DDL requests in the Root coord task queue. The DDL requests in the task queue are arranged in the order they are received by the root coord. So, ddl1 is the first sent to root coord, and ddlK is the last one in this batch. The root coord processes the requests one by one in the time order.
In a distributed system, the communication between the proxies and the root coord is enabled by gRPC. The root coord keeps a record of the maximum timestamp value of the executed tasks to ensure that all DDL requests are processed in time order.
Suppose there are two independent proxies, proxy 1 and proxy 2. They both send DDL requests to the same root coord. However, one problem is that earlier requests are not necessarily sent to the root coord before those requests received by another proxy later. For instance, in the image above, when DDL_K-1 is sent to the root coord from proxy 1, DDL_K from proxy 2 has already been accepted and executed by the root coord. As recorded by the root coord, the maximum timestamp value of the executed tasks at this point is K. So in order not to interrupt the time order, the request DDL_K-1 will be rejected by the root coord’s task queue . However, if proxy 2 sends the request DDL_K+5 to the root coord at this point, the request will be accepted to the task queue and will be executed later according to its timestamp value.
Indexing
Building an index
Upon receiving index building requests from the client, the proxy first carries out static checks on the requests and sends them to the root coord. Then the root coord persists these index building requests into meta storage (etcd) and sends the requests to the index coordinator (index coord).
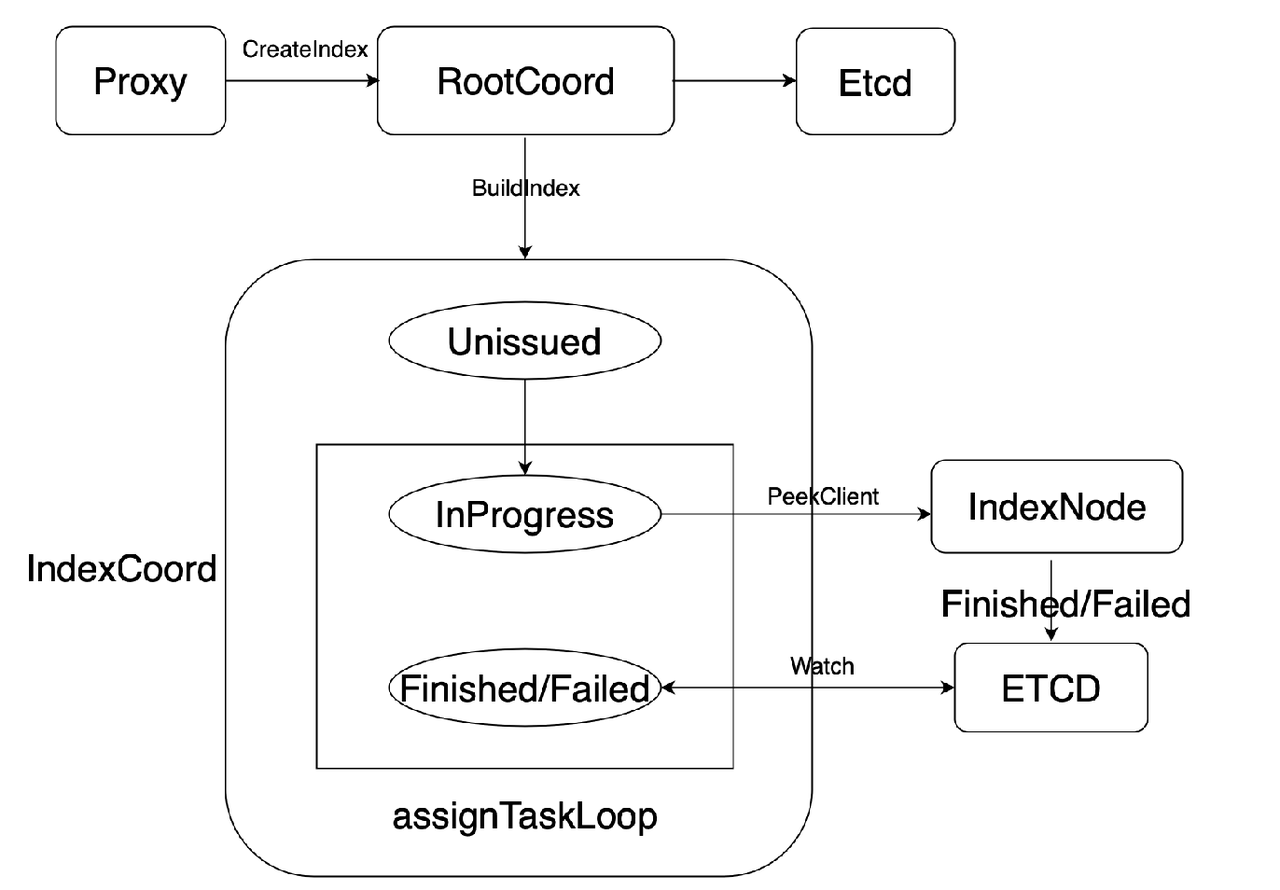 Building an index.
Building an index.
As illustrated above, when the index coord receives index building requests from the root coord, it first persists the task in etcd for meta store. The initial status of the index building task is Unissued. The index coord maintains a record of the task load of each index node, and sends to inbound tasks to a less loaded index node. Upon completion of the task, the index node writes the status of the task, either Finished or Failed into meta storage, which is etcd in Milvus. Then the index coord will understand if the index building task succeeds or fails by looking up in etcd. If the task fails due to limited system resources or dropout of the index node, the index coord will re-trigger the whole process and assign the same task to another index node.
Dropping an index
In addition, the index coord is also in charge of the requests of dropping indexes.
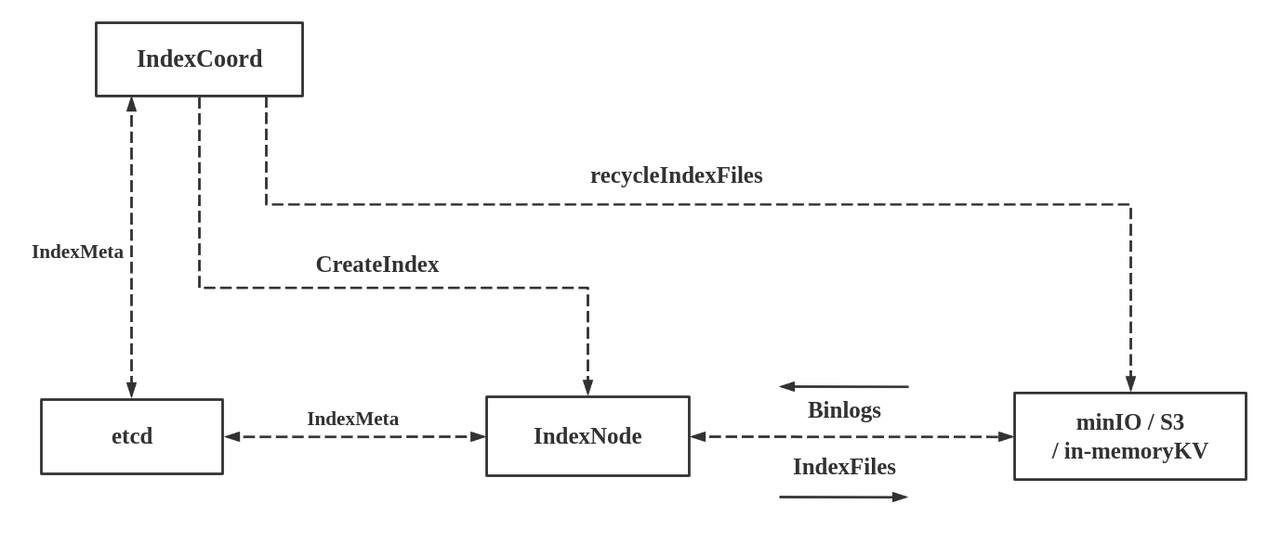 Dropping an index.
Dropping an index.
When the root coord receives a request of dropping an index from the client, it first marks the index as "dropped", and returns the result to the client while notifying the index coord. Then the index coord filters all indexing tasks with the IndexID and those tasks matching the condition are dropped.
The background coroutine of the index coord will gradually delete all indexing tasks marked as “dropped” from object storage (MinIO and S3). This process involves the recycleIndexFiles interface. When all corresponding index files are deleted, the meta information of the deleted indexing tasks are removed from meta storage (etcd).
About the Deep Dive Series
With the official announcement of general availability of Milvus 2.0, we orchestrated this Milvus Deep Dive blog series to provide an in-depth interpretation of the Milvus architecture and source code. Topics covered in this blog series include:
Try Managed Milvus for Free
Zilliz Cloud is hassle-free, powered by Milvus and 10x faster.
Get StartedLike the article? Spread the word



