Menggunakan Pencarian Teks Lengkap dengan LangChain dan Milvus
![]()
Pencarian teks lengkap adalah metode tradisional untuk mengambil dokumen dengan mencocokkan kata kunci atau frasa tertentu dalam teks. Metode ini memberi peringkat hasil berdasarkan skor relevansi yang dihitung dari faktor-faktor seperti frekuensi istilah. Meskipun pencarian semantik lebih baik dalam memahami makna dan konteks, pencarian teks lengkap unggul dalam pencocokan kata kunci yang tepat, menjadikannya pelengkap yang berguna untuk pencarian semantik. Algoritma BM25 banyak digunakan untuk menentukan peringkat dalam pencarian teks lengkap dan memainkan peran penting dalam Retrieval-Augmented Generation (RAG).
Milvus 2.5 memperkenalkan kemampuan pencarian teks lengkap menggunakan BM25. Pendekatan ini mengubah teks menjadi vektor jarang yang mewakili skor BM25. Anda cukup memasukkan teks mentah dan Milvus akan secara otomatis menghasilkan dan menyimpan vektor jarang, tanpa perlu melakukan pembuatan embedding jarang secara manual.
Integrasi LangChain dengan Milvus juga telah memperkenalkan fitur ini, menyederhanakan proses penggabungan pencarian teks lengkap ke dalam aplikasi RAG. Dengan menggabungkan pencarian teks lengkap dengan pencarian semantik dengan vektor padat, Anda dapat mencapai pendekatan hibrida yang memanfaatkan konteks semantik dari sematan padat dan relevansi kata kunci yang tepat dari pencocokan kata. Integrasi ini meningkatkan akurasi, relevansi, dan pengalaman pengguna sistem pencarian.
Tutorial ini akan menunjukkan cara menggunakan LangChain dan Milvus untuk mengimplementasikan pencarian teks lengkap dalam aplikasi Anda.
- Pencarian teks lengkap saat ini tersedia di Milvus Standalone, Milvus Distributed, dan Zilliz Cloud, meskipun belum didukung di Milvus Lite (yang memiliki fitur ini yang direncanakan untuk implementasi di masa depan). Hubungi support@zilliz.com untuk informasi lebih lanjut.
- Sebelum melanjutkan dengan tutorial ini, pastikan Anda memiliki pemahaman dasar tentang pencarian teks lengkap dan penggunaan dasar integrasi LangChain Milvus.
Prasyarat
Sebelum menjalankan buku catatan ini, pastikan Anda telah menginstal dependensi berikut ini:
$ pip install --upgrade --quiet langchain langchain-core langchain-community langchain-text-splitters langchain-milvus langchain-openai bs4 #langchain-voyageai
Jika Anda menggunakan Google Colab, untuk mengaktifkan dependensi yang baru saja terinstal, Anda mungkin perlu memulai ulang runtime (klik menu "Runtime" di bagian atas layar, dan pilih "Restart session" dari menu tarik-turun).
Kita akan menggunakan model dari OpenAI. Anda harus menyiapkan variabel lingkungan OPENAI_API_KEY dari OpenAI.
import os
os.environ["OPENAI_API_KEY"] = "sk-***********"
Tentukan server Milvus Anda URI (dan secara opsional TOKEN). Untuk cara menginstal dan menjalankan server Milvus, ikuti panduan ini.
URI = "http://localhost:19530"
# TOKEN = ...
Siapkan beberapa contoh dokumen:
from langchain_core.documents import Document
docs = [
Document(page_content="I like this apple", metadata={"category": "fruit"}),
Document(page_content="I like swimming", metadata={"category": "sport"}),
Document(page_content="I like dogs", metadata={"category": "pets"}),
]
Inisialisasi dengan Fungsi BM25
Pencarian Hibrida
Untuk pencarian teks lengkap, Milvus VectorStore menerima parameter builtin_function. Melalui parameter ini, Anda dapat mengoper sebuah instance dari BM25BuiltInFunction. Ini berbeda dengan pencarian semantik yang biasanya mengoper sematan padat ke VectorStore,
Berikut ini adalah contoh sederhana dari pencarian hibrida di Milvus dengan sematan padat OpenAI untuk pencarian semantik dan BM25 untuk pencarian teks lengkap:
from langchain_milvus import Milvus, BM25BuiltInFunction
from langchain_openai import OpenAIEmbeddings
vectorstore = Milvus.from_documents(
documents=docs,
embedding=OpenAIEmbeddings(),
builtin_function=BM25BuiltInFunction(),
# `dense` is for OpenAI embeddings, `sparse` is the output field of BM25 function
vector_field=["dense", "sparse"],
connection_args={
"uri": URI,
},
drop_old=False,
)
Pada kode di atas, kita mendefinisikan sebuah instance dari BM25BuiltInFunction dan meneruskannya ke objek Milvus. BM25BuiltInFunction adalah kelas pembungkus yang ringan untuk Function di Milvus.
Anda bisa menentukan kolom input dan output untuk fungsi ini di parameter BM25BuiltInFunction:
input_field_names(str): Nama field input, defaultnya adalahtext. Ini mengindikasikan field mana yang dibaca oleh fungsi ini sebagai input.output_field_names(str): Nama bidang keluaran, standarnya adalahsparse. Ini menunjukkan ke bidang mana fungsi ini mengeluarkan hasil perhitungan.
Perhatikan bahwa dalam parameter inisialisasi Milvus yang disebutkan di atas, kita juga menentukan vector_field=["dense", "sparse"]. Karena bidang sparse diambil sebagai bidang keluaran yang ditentukan oleh BM25BuiltInFunction, bidang dense lainnya akan secara otomatis ditetapkan ke bidang keluaran OpenAIEmbeddings.
Dalam praktiknya, terutama ketika menggabungkan beberapa embeddings atau fungsi, kami merekomendasikan untuk menentukan secara eksplisit bidang input dan output untuk setiap fungsi untuk menghindari ambiguitas.
Pada contoh berikut, kami menentukan bidang input dan output BM25BuiltInFunction secara eksplisit, sehingga memperjelas bidang mana yang akan digunakan oleh fungsi bawaan.
# from langchain_voyageai import VoyageAIEmbeddings
embedding1 = OpenAIEmbeddings(model="text-embedding-ada-002")
embedding2 = OpenAIEmbeddings(model="text-embedding-3-large")
# embedding2 = VoyageAIEmbeddings(model="voyage-3") # You can also use embedding from other embedding model providers, e.g VoyageAIEmbeddings
vectorstore = Milvus.from_documents(
documents=docs,
embedding=[embedding1, embedding2],
builtin_function=BM25BuiltInFunction(
input_field_names="text", output_field_names="sparse"
),
text_field="text", # `text` is the input field name of BM25BuiltInFunction
# `sparse` is the output field name of BM25BuiltInFunction, and `dense1` and `dense2` are the output field names of embedding1 and embedding2
vector_field=["dense1", "dense2", "sparse"],
connection_args={
"uri": URI,
},
drop_old=False,
)
vectorstore.vector_fields
['dense1', 'dense2', 'sparse']
Dalam contoh ini, kita memiliki tiga bidang vektor. Diantaranya, sparse digunakan sebagai bidang keluaran untuk BM25BuiltInFunction, sedangkan dua lainnya, dense1 dan dense2, secara otomatis ditetapkan sebagai bidang keluaran untuk dua model OpenAIEmbeddings (berdasarkan urutan).
Dengan cara ini, Anda dapat mendefinisikan beberapa bidang vektor dan menetapkan kombinasi penyematan atau fungsi yang berbeda untuk mengimplementasikan pencarian hibrida.
Ketika melakukan pencarian hibrida, kita hanya perlu memasukkan teks kueri dan secara opsional mengatur parameter topK dan reranker. Instance vectorstore akan secara otomatis menangani penyematan vektor dan fungsi bawaan dan akhirnya menggunakan reranker untuk menyaring hasil. Detail implementasi yang mendasari proses pencarian disembunyikan dari pengguna.
vectorstore.similarity_search(
"Do I like apples?", k=1
) # , ranker_type="weighted", ranker_params={"weights":[0.3, 0.3, 0.4]})
[Document(metadata={'category': 'fruit', 'pk': 454646931479251897}, page_content='I like this apple')]
Untuk informasi lebih lanjut tentang pencarian hybrid, Anda dapat merujuk ke pengenalan Pencarian Hybrid dan tutorial pencarian hybrid LangChain Milvus ini.
Pencarian BM25 tanpa penyematan
Jika Anda hanya ingin melakukan pencarian teks lengkap dengan fungsi BM25 tanpa menggunakan pencarian semantik berbasis penyematan, Anda dapat mengatur parameter penyematan ke None dan hanya menyimpan builtin_function yang ditetapkan sebagai contoh fungsi BM25. Bidang vektor hanya memiliki bidang "jarang". Sebagai contoh:
vectorstore = Milvus.from_documents(
documents=docs,
embedding=None,
builtin_function=BM25BuiltInFunction(
output_field_names="sparse",
),
vector_field="sparse",
connection_args={
"uri": URI,
},
drop_old=False,
)
vectorstore.vector_fields
['sparse']
Menyesuaikan penganalisis
Penganalisis sangat penting dalam pencarian teks lengkap dengan memecah kalimat menjadi token dan melakukan analisis leksikal seperti stemming dan penghilangan kata. Penganalisis biasanya khusus untuk bahasa tertentu. Anda dapat merujuk ke panduan ini untuk mempelajari lebih lanjut tentang penganalisis di Milvus.
Milvus mendukung dua jenis penganalisis: Penganalisis bawaan dan Penganalisis Khusus. Secara default, BM25BuiltInFunction akan menggunakan penganalisis bawaan standar, yang merupakan penganalisis paling dasar yang menandai teks dengan tanda baca.
Jika Anda ingin menggunakan penganalisis yang berbeda atau menyesuaikan penganalisis, Anda dapat memasukkan parameter analyzer_params dalam inisialisasi BM25BuiltInFunction.
analyzer_params_custom = {
"tokenizer": "standard",
"filter": [
"lowercase", # Built-in filter
{"type": "length", "max": 40}, # Custom filter
{"type": "stop", "stop_words": ["of", "to"]}, # Custom filter
],
}
vectorstore = Milvus.from_documents(
documents=docs,
embedding=OpenAIEmbeddings(),
builtin_function=BM25BuiltInFunction(
output_field_names="sparse",
enable_match=True,
analyzer_params=analyzer_params_custom,
),
vector_field=["dense", "sparse"],
connection_args={
"uri": URI,
},
drop_old=False,
)
Kita dapat melihat skema koleksi Milvus dan memastikan penganalisis yang disesuaikan diatur dengan benar.
vectorstore.col.schema
{'auto_id': True, 'description': '', 'fields': [{'name': 'text', 'description': '', 'type': <DataType.VARCHAR: 21>, 'params': {'max_length': 65535, 'enable_match': True, 'enable_analyzer': True, 'analyzer_params': {'tokenizer': 'standard', 'filter': ['lowercase', {'type': 'length', 'max': 40}, {'type': 'stop', 'stop_words': ['of', 'to']}]}}}, {'name': 'pk', 'description': '', 'type': <DataType.INT64: 5>, 'is_primary': True, 'auto_id': True}, {'name': 'dense', 'description': '', 'type': <DataType.FLOAT_VECTOR: 101>, 'params': {'dim': 1536}}, {'name': 'sparse', 'description': '', 'type': <DataType.SPARSE_FLOAT_VECTOR: 104>, 'is_function_output': True}, {'name': 'category', 'description': '', 'type': <DataType.VARCHAR: 21>, 'params': {'max_length': 65535}}], 'enable_dynamic_field': False, 'functions': [{'name': 'bm25_function_de368e79', 'description': '', 'type': <FunctionType.BM25: 1>, 'input_field_names': ['text'], 'output_field_names': ['sparse'], 'params': {}}]}
Untuk detail konsep lebih lanjut, misalnya, analyzer, tokenizer, filter, enable_match, analyzer_params, silakan merujuk ke dokumentasi penganalisis.
Menggunakan Pencarian Hibrida dan Pemeringkatan Ulang di RAG
Kita telah mempelajari bagaimana cara menggunakan fungsi bawaan BM25 dasar di LangChain dan Milvus. Mari kita perkenalkan implementasi RAG yang dioptimalkan dengan pencarian hybrid dan pemeringkatan ulang.
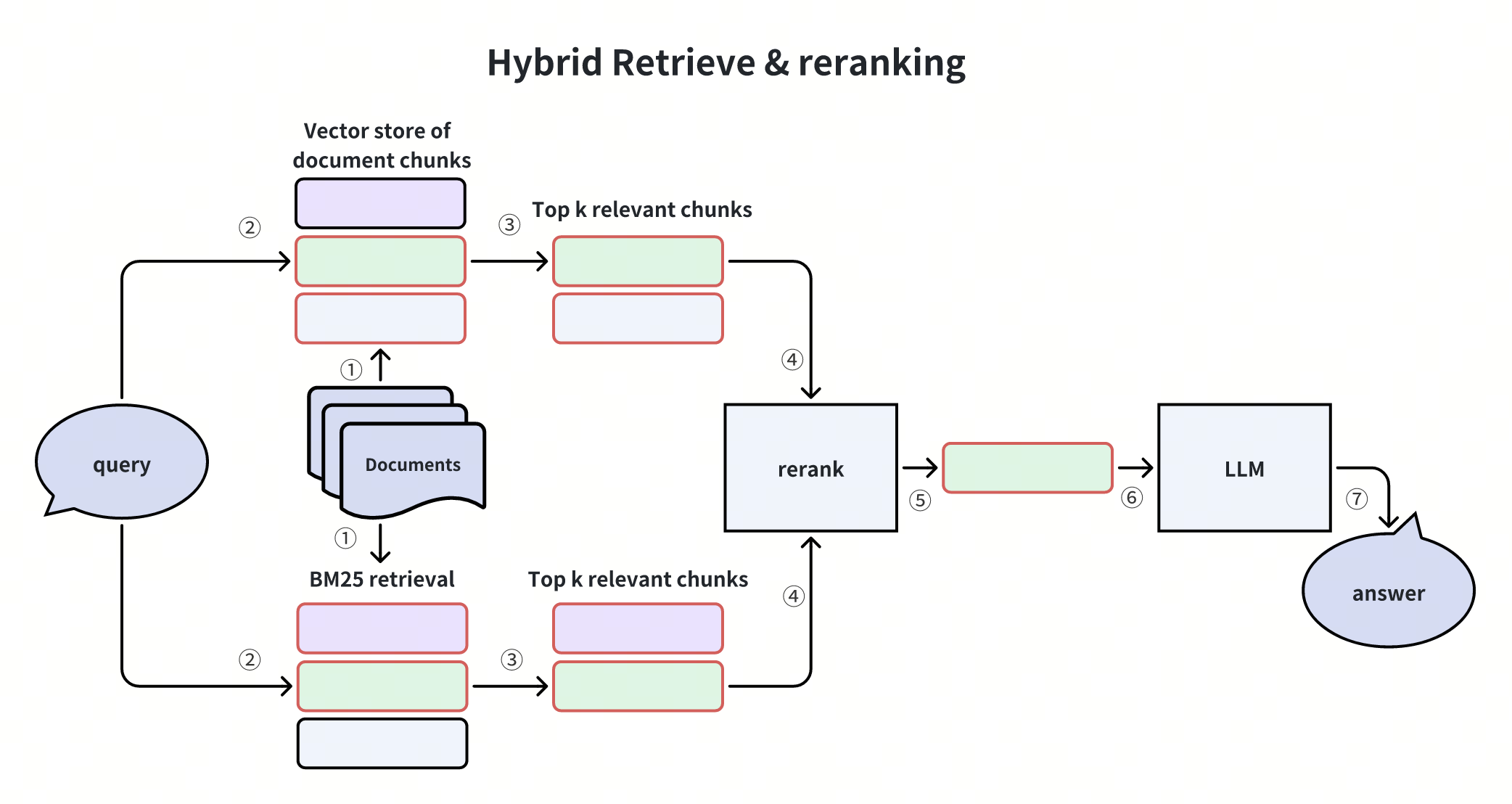
Diagram ini menunjukkan proses Hybrid Retrieve & Reranking, menggabungkan BM25 untuk pencocokan kata kunci dan pencarian vektor untuk pencarian semantik. Hasil dari kedua metode tersebut digabungkan, di-reranking, dan diteruskan ke LLM untuk menghasilkan jawaban akhir.
Pencarian hybrid menyeimbangkan ketepatan dan pemahaman semantik, meningkatkan akurasi dan ketahanan untuk beragam pertanyaan. Metode ini mengambil kandidat dengan pencarian teks lengkap BM25 dan pencarian vektor, memastikan pencarian yang semantik, sadar konteks, dan akurat.
Mari kita mulai dengan sebuah contoh.
Siapkan data
Kami menggunakan Langchain WebBaseLoader untuk memuat dokumen dari sumber web dan membaginya menjadi beberapa bagian menggunakan RecursiveCharacterTextSplitter.
import bs4
from langchain_community.document_loaders import WebBaseLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
# Create a WebBaseLoader instance to load documents from web sources
loader = WebBaseLoader(
web_paths=(
"https://lilianweng.github.io/posts/2023-06-23-agent/",
"https://lilianweng.github.io/posts/2023-03-15-prompt-engineering/",
),
bs_kwargs=dict(
parse_only=bs4.SoupStrainer(
class_=("post-content", "post-title", "post-header")
)
),
)
# Load documents from web sources using the loader
documents = loader.load()
# Initialize a RecursiveCharacterTextSplitter for splitting text into chunks
text_splitter = RecursiveCharacterTextSplitter(chunk_size=2000, chunk_overlap=200)
# Split the documents into chunks using the text_splitter
docs = text_splitter.split_documents(documents)
# Let's take a look at the first document
docs[1]
Document(metadata={'source': 'https://lilianweng.github.io/posts/2023-06-23-agent/'}, page_content='Fig. 1. Overview of a LLM-powered autonomous agent system.\nComponent One: Planning#\nA complicated task usually involves many steps. An agent needs to know what they are and plan ahead.\nTask Decomposition#\nChain of thought (CoT; Wei et al. 2022) has become a standard prompting technique for enhancing model performance on complex tasks. The model is instructed to “think step by step” to utilize more test-time computation to decompose hard tasks into smaller and simpler steps. CoT transforms big tasks into multiple manageable tasks and shed lights into an interpretation of the model’s thinking process.\nTree of Thoughts (Yao et al. 2023) extends CoT by exploring multiple reasoning possibilities at each step. It first decomposes the problem into multiple thought steps and generates multiple thoughts per step, creating a tree structure. The search process can be BFS (breadth-first search) or DFS (depth-first search) with each state evaluated by a classifier (via a prompt) or majority vote.\nTask decomposition can be done (1) by LLM with simple prompting like "Steps for XYZ.\\n1.", "What are the subgoals for achieving XYZ?", (2) by using task-specific instructions; e.g. "Write a story outline." for writing a novel, or (3) with human inputs.\nAnother quite distinct approach, LLM+P (Liu et al. 2023), involves relying on an external classical planner to do long-horizon planning. This approach utilizes the Planning Domain Definition Language (PDDL) as an intermediate interface to describe the planning problem. In this process, LLM (1) translates the problem into “Problem PDDL”, then (2) requests a classical planner to generate a PDDL plan based on an existing “Domain PDDL”, and finally (3) translates the PDDL plan back into natural language. Essentially, the planning step is outsourced to an external tool, assuming the availability of domain-specific PDDL and a suitable planner which is common in certain robotic setups but not in many other domains.\nSelf-Reflection#')
Memuat dokumen ke dalam penyimpanan vektor Milvus
Seperti pengantar di atas, kita menginisialisasi dan memuat dokumen yang telah disiapkan ke dalam penyimpanan vektor Milvus, yang berisi dua bidang vektor: dense untuk penyematan OpenAI dan sparse untuk fungsi BM25.
vectorstore = Milvus.from_documents(
documents=docs,
embedding=OpenAIEmbeddings(),
builtin_function=BM25BuiltInFunction(),
vector_field=["dense", "sparse"],
connection_args={
"uri": URI,
},
drop_old=False,
)
Membangun rantai RAG
Kami menyiapkan instance dan prompt LLM, lalu menggabungkannya ke dalam pipeline RAG menggunakan Bahasa Ekspresi LangChain.
from langchain_core.runnables import RunnablePassthrough
from langchain_core.prompts import PromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langchain_openai import ChatOpenAI
# Initialize the OpenAI language model for response generation
llm = ChatOpenAI(model_name="gpt-4o", temperature=0)
# Define the prompt template for generating AI responses
PROMPT_TEMPLATE = """
Human: You are an AI assistant, and provides answers to questions by using fact based and statistical information when possible.
Use the following pieces of information to provide a concise answer to the question enclosed in <question> tags.
If you don't know the answer, just say that you don't know, don't try to make up an answer.
<context>
{context}
</context>
<question>
{question}
</question>
The response should be specific and use statistics or numbers when possible.
Assistant:"""
# Create a PromptTemplate instance with the defined template and input variables
prompt = PromptTemplate(
template=PROMPT_TEMPLATE, input_variables=["context", "question"]
)
# Convert the vector store to a retriever
retriever = vectorstore.as_retriever()
# Define a function to format the retrieved documents
def format_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)
Gunakan LCEL (LangChain Expression Language) untuk membangun rantai RAG.
# Define the RAG (Retrieval-Augmented Generation) chain for AI response generation
rag_chain = (
{"context": retriever | format_docs, "question": RunnablePassthrough()}
| prompt
| llm
| StrOutputParser()
)
# rag_chain.get_graph().print_ascii()
Panggil rantai RAG dengan pertanyaan spesifik dan ambil jawabannya
query = "What is PAL and PoT?"
res = rag_chain.invoke(query)
res
'PAL (Program-aided Language models) and PoT (Program of Thoughts prompting) are approaches that involve using language models to generate programming language statements to solve natural language reasoning problems. This method offloads the solution step to a runtime, such as a Python interpreter, allowing for complex computation and reasoning to be handled externally. PAL and PoT rely on language models with strong coding skills to effectively generate and execute these programming statements.'
Selamat! Anda telah membangun rantai RAG pencarian hibrida (vektor padat + fungsi bm25 yang jarang) yang diberdayakan oleh Milvus dan LangChain.