Milvus Hybrid Search Retriever
Die hybride Suche kombiniert die Stärken verschiedener Suchparadigmen, um die Abrufgenauigkeit und Robustheit zu verbessern. Sie nutzt die Fähigkeiten sowohl der dichten Vektorsuche als auch der spärlichen Vektorsuche sowie Kombinationen mehrerer dichter Vektorsuchstrategien und gewährleistet so ein umfassendes und präzises Retrieval für verschiedene Abfragen.
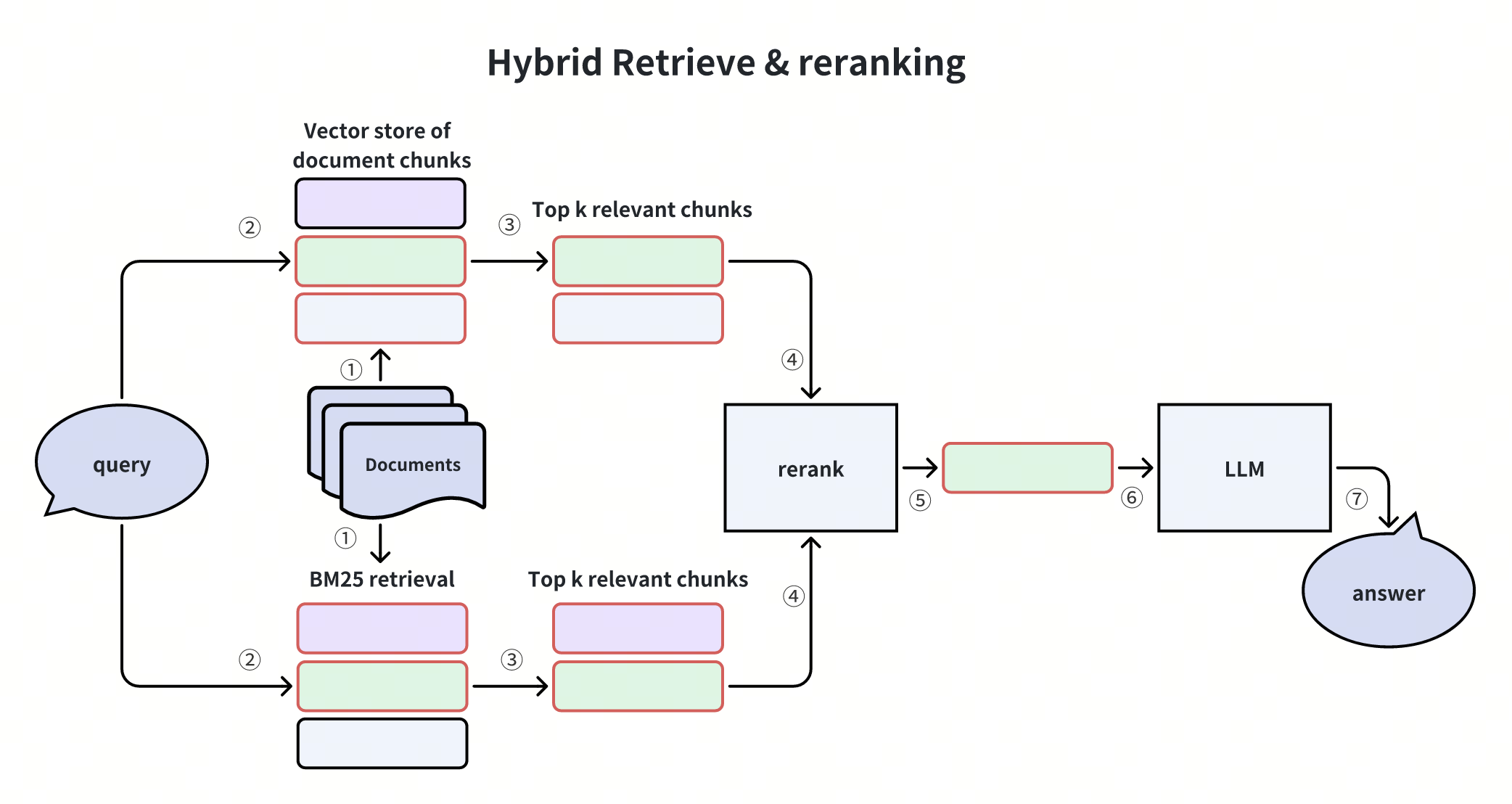
Dieses Diagramm veranschaulicht das häufigste Szenario der hybriden Suche, nämlich die dichte + spärliche hybride Suche. In diesem Fall werden die Kandidaten sowohl durch semantische Vektorähnlichkeit als auch durch präzisen Schlüsselwortabgleich abgerufen. Die Ergebnisse dieser Methoden werden zusammengeführt, neu eingestuft und an einen LLM weitergeleitet, um die endgültige Antwort zu generieren. Dieser Ansatz stellt ein Gleichgewicht zwischen Präzision und semantischem Verständnis her, was ihn für verschiedene Abfrageszenarien sehr effektiv macht.
Neben der Dense + Sparse-Hybridsuche können Hybridstrategien auch mehrere dichte Vektormodelle kombinieren. Ein dichtes Vektormodell könnte beispielsweise auf die Erfassung semantischer Nuancen spezialisiert sein, während ein anderes sich auf kontextuelle Einbettungen oder domänenspezifische Darstellungen konzentriert. Durch die Zusammenführung der Ergebnisse dieser Modelle und deren Neueinstufung gewährleistet diese Art der hybriden Suche einen nuancierteren und kontextbewussten Abrufprozess.
Die LangChain-Milvus-Integration bietet einen flexiblen Weg, die hybride Suche zu implementieren. Sie unterstützt eine beliebige Anzahl von Vektorfeldern und beliebige benutzerdefinierte dichte oder spärliche Einbettungsmodelle, wodurch sich LangChain Milvus flexibel an verschiedene Nutzungsszenarien der hybriden Suche anpassen lässt und gleichzeitig mit anderen Fähigkeiten von LangChain kompatibel ist.
In diesem Tutorial beginnen wir mit dem am häufigsten vorkommenden dichten + spärlichen Fall und stellen dann eine beliebige Anzahl von allgemeinen hybriden Suchansätzen vor.
Der MilvusCollectionHybridSearchRetriever, der eine weitere Implementierung der hybriden Suche mit Milvus und LangChain ist, wird demnächst veraltet sein. Bitte verwenden Sie den Ansatz in diesem Dokument, um die hybride Suche zu implementieren, da er flexibler und mit LangChain kompatibel ist.
Voraussetzungen
Vergewissern Sie sich, dass Sie die folgenden Abhängigkeiten installiert haben, bevor Sie dieses Notizbuch ausführen:
$ pip install --upgrade --quiet langchain langchain-core langchain-community langchain-text-splitters langchain-milvus langchain-openai bs4 pymilvus[model] #langchain-voyageai
Wenn Sie Google Colab verwenden, müssen Sie möglicherweise die Runtime neu starten, um die soeben installierten Abhängigkeiten zu aktivieren (klicken Sie auf das Menü "Runtime" am oberen Rand des Bildschirms und wählen Sie "Restart session" aus dem Dropdown-Menü).
Wir werden die Modelle von OpenAI verwenden. Sie sollten die Umgebungsvariablen OPENAI_API_KEY von OpenAI vorbereiten.
import os
os.environ["OPENAI_API_KEY"] = "sk-***********"
Geben Sie Ihren Milvus-Server URI (und optional die TOKEN) an. Wie Sie den Milvus-Server installieren und starten, erfahren Sie in dieser Anleitung.
URI = "http://localhost:19530"
# TOKEN = ...
Bereiten Sie einige Beispieldokumente vor, bei denen es sich um Zusammenfassungen fiktionaler Geschichten handelt, die nach Themen oder Genres geordnet sind.
from langchain_core.documents import Document
docs = [
Document(
page_content="In 'The Whispering Walls' by Ava Moreno, a young journalist named Sophia uncovers a decades-old conspiracy hidden within the crumbling walls of an ancient mansion, where the whispers of the past threaten to destroy her own sanity.",
metadata={"category": "Mystery"},
),
Document(
page_content="In 'The Last Refuge' by Ethan Blackwood, a group of survivors must band together to escape a post-apocalyptic wasteland, where the last remnants of humanity cling to life in a desperate bid for survival.",
metadata={"category": "Post-Apocalyptic"},
),
Document(
page_content="In 'The Memory Thief' by Lila Rose, a charismatic thief with the ability to steal and manipulate memories is hired by a mysterious client to pull off a daring heist, but soon finds themselves trapped in a web of deceit and betrayal.",
metadata={"category": "Heist/Thriller"},
),
Document(
page_content="In 'The City of Echoes' by Julian Saint Clair, a brilliant detective must navigate a labyrinthine metropolis where time is currency, and the rich can live forever, but at a terrible cost to the poor.",
metadata={"category": "Science Fiction"},
),
Document(
page_content="In 'The Starlight Serenade' by Ruby Flynn, a shy astronomer discovers a mysterious melody emanating from a distant star, which leads her on a journey to uncover the secrets of the universe and her own heart.",
metadata={"category": "Science Fiction/Romance"},
),
Document(
page_content="In 'The Shadow Weaver' by Piper Redding, a young orphan discovers she has the ability to weave powerful illusions, but soon finds herself at the center of a deadly game of cat and mouse between rival factions vying for control of the mystical arts.",
metadata={"category": "Fantasy"},
),
Document(
page_content="In 'The Lost Expedition' by Caspian Grey, a team of explorers ventures into the heart of the Amazon rainforest in search of a lost city, but soon finds themselves hunted by a ruthless treasure hunter and the treacherous jungle itself.",
metadata={"category": "Adventure"},
),
Document(
page_content="In 'The Clockwork Kingdom' by Augusta Wynter, a brilliant inventor discovers a hidden world of clockwork machines and ancient magic, where a rebellion is brewing against the tyrannical ruler of the land.",
metadata={"category": "Steampunk/Fantasy"},
),
Document(
page_content="In 'The Phantom Pilgrim' by Rowan Welles, a charismatic smuggler is hired by a mysterious organization to transport a valuable artifact across a war-torn continent, but soon finds themselves pursued by deadly assassins and rival factions.",
metadata={"category": "Adventure/Thriller"},
),
Document(
page_content="In 'The Dreamwalker's Journey' by Lyra Snow, a young dreamwalker discovers she has the ability to enter people's dreams, but soon finds herself trapped in a surreal world of nightmares and illusions, where the boundaries between reality and fantasy blur.",
metadata={"category": "Fantasy"},
),
]
Dichte Einbettung + Spärliche Einbettung
Option 1 (empfohlen): dichte Einbettung + integrierte Funktion von Milvus BM25
Verwenden Sie die dichte Einbettung + die integrierte Funktion von Milvus BM25, um die Instanz des hybriden Abrufvektorspeichers zusammenzustellen.
from langchain_milvus import Milvus, BM25BuiltInFunction
from langchain_openai import OpenAIEmbeddings
vectorstore = Milvus.from_documents(
documents=docs,
embedding=OpenAIEmbeddings(),
builtin_function=BM25BuiltInFunction(), # output_field_names="sparse"),
vector_field=["dense", "sparse"],
connection_args={
"uri": URI,
},
consistency_level="Bounded", # Supported values are (`"Strong"`, `"Session"`, `"Bounded"`, `"Eventually"`). See https://milvus.io/docs/tune_consistency.md#Consistency-Level for more details.
drop_old=False,
)
- Wenn Sie
BM25BuiltInFunctionverwenden, beachten Sie bitte, dass die Volltextsuche in Milvus Standalone und Milvus Distributed verfügbar ist, aber nicht in Milvus Lite, obwohl sie auf der Roadmap für eine zukünftige Aufnahme steht. Sie wird demnächst auch in der Zilliz Cloud (vollständig verwaltetes Milvus) verfügbar sein. Bitte wenden Sie sich an support@zilliz.com für weitere Informationen.
Im obigen Code definieren wir eine Instanz von BM25BuiltInFunction und übergeben sie an das Milvus Objekt. BM25BuiltInFunction ist eine leichtgewichtige Wrapper-Klasse für Function in Milvus. Wir können sie zusammen mit OpenAIEmbeddings verwenden, um eine Instanz des Milvus-Vektorspeichers mit dichter und spärlicher Hybrid-Suche zu initialisieren.
BM25BuiltInFunction erfordert nicht, dass der Client einen Korpus oder ein Training übergibt, alles wird automatisch auf dem Milvus-Server verarbeitet, so dass sich die Benutzer nicht um Vokabular und Korpus kümmern müssen. Darüber hinaus können die Benutzer den Analyzer auch anpassen, um die benutzerdefinierte Textverarbeitung im BM25 zu implementieren.
Weitere Informationen zu BM25BuiltInFunction finden Sie in der Volltextsuche und der Verwendung der Volltextsuche mit LangChain und Milvus.
Option 2: Dense und angepasste LangChain Sparse Embedding verwenden
Sie können die Klasse BaseSparseEmbedding von langchain_milvus.utils.sparse erben und die Methoden embed_query und embed_documents implementieren, um den Sparse-Embedding-Prozess anzupassen. So können Sie jede Sparse Embedding-Methode anpassen, die auf Termhäufigkeitsstatistiken (z. B. BM25) oder neuronalen Netzen (z. B. SPADE) basiert.
Hier ist ein Beispiel:
from typing import Dict, List
from langchain_milvus.utils.sparse import BaseSparseEmbedding
class MyCustomEmbedding(BaseSparseEmbedding): # inherit from BaseSparseEmbedding
def __init__(self, model_path): ... # code to init or load model
def embed_query(self, query: str) -> Dict[int, float]:
... # code to embed query
return { # fake embedding result
1: 0.1,
2: 0.2,
3: 0.3,
# ...
}
def embed_documents(self, texts: List[str]) -> List[Dict[int, float]]:
... # code to embed documents
return [ # fake embedding results
{
1: 0.1,
2: 0.2,
3: 0.3,
# ...
}
] * len(texts)
Wir haben eine Demoklasse BM25SparseEmbedding, die von BaseSparseEmbedding in langchain_milvus.utils.sparse geerbt wurde. Sie können sie in die Initialisierungseinbettungsliste der Milvus-Vektorspeicherinstanz genauso wie andere Langchain-Dense-Einbettungsklassen übergeben.
# BM25SparseEmbedding is inherited from BaseSparseEmbedding
from langchain_milvus.utils.sparse import BM25SparseEmbedding
embedding1 = OpenAIEmbeddings()
corpus = [doc.page_content for doc in docs]
embedding2 = BM25SparseEmbedding(
corpus=corpus
) # pass in corpus to initialize the statistics
vectorstore = Milvus.from_documents(
documents=docs,
embedding=[embedding1, embedding2],
vector_field=["dense", "sparse"],
connection_args={
"uri": URI,
},
consistency_level="Bounded", # Supported values are (`"Strong"`, `"Session"`, `"Bounded"`, `"Eventually"`). See https://milvus.io/docs/tune_consistency.md#Consistency-Level for more details.
drop_old=False,
)
Obwohl dies eine Möglichkeit ist, BM25 zu verwenden, erfordert es, dass der Benutzer das Korpus für die Termhäufigkeitsstatistik verwaltet. Wir empfehlen stattdessen die Verwendung der eingebauten BM25-Funktion (Option 1), da diese alles auf der Milvus-Server-Seite erledigt. Dadurch müssen sich die Benutzer nicht mehr um die Verwaltung des Korpus oder das Training eines Vokabulars kümmern. Für weitere Informationen lesen Sie bitte den Abschnitt Volltextsuche mit LangChain und Milvus.
Definieren Sie mehrere beliebige Vektorfelder
Bei der Initialisierung des Milvus-Vektorspeichers können Sie die Liste der Einbettungen (und in Zukunft auch die Liste der eingebauten Funktionen) übergeben, um die Mehrfachsuche zu implementieren und diese Kandidaten dann neu zu ordnen. Hier ein Beispiel:
# from langchain_voyageai import VoyageAIEmbeddings
embedding1 = OpenAIEmbeddings(model="text-embedding-ada-002")
embedding2 = OpenAIEmbeddings(model="text-embedding-3-large")
# embedding3 = VoyageAIEmbeddings(model="voyage-3") # You can also use embedding from other embedding model providers, e.g VoyageAIEmbeddings
vectorstore = Milvus.from_documents(
documents=docs,
embedding=[embedding1, embedding2], # embedding3],
builtin_function=BM25BuiltInFunction(output_field_names="sparse"),
# `sparse` is the output field name of BM25BuiltInFunction, and `dense1` and `dense2` are the output field names of embedding1 and embedding2
vector_field=["dense1", "dense2", "sparse"],
connection_args={
"uri": URI,
},
consistency_level="Bounded", # Supported values are (`"Strong"`, `"Session"`, `"Bounded"`, `"Eventually"`). See https://milvus.io/docs/tune_consistency.md#Consistency-Level for more details.
drop_old=False,
)
vectorstore.vector_fields
['dense1', 'dense2', 'sparse']
In diesem Beispiel haben wir drei Vektorfelder. Davon wird sparse als Ausgabefeld für BM25BuiltInFunction verwendet, während die beiden anderen, dense1 und dense2, automatisch als Ausgabefelder für die beiden OpenAIEmbeddings -Modelle zugewiesen werden (basierend auf der Reihenfolge).
Festlegen der Index-Parameter für Multi-Vektorfelder
Standardmäßig werden die Indextypen der einzelnen Vektorfelder automatisch durch den Typ der Einbettung oder der eingebauten Funktion bestimmt. Sie können jedoch auch den Indextyp für jedes Vektorfeld angeben, um die Suchleistung zu optimieren.
dense_index_param_1 = {
"metric_type": "COSINE",
"index_type": "HNSW",
}
dense_index_param_2 = {
"metric_type": "IP",
"index_type": "HNSW",
}
sparse_index_param = {
"metric_type": "BM25",
"index_type": "AUTOINDEX",
}
vectorstore = Milvus.from_documents(
documents=docs,
embedding=[embedding1, embedding2],
builtin_function=BM25BuiltInFunction(output_field_names="sparse"),
index_params=[dense_index_param_1, dense_index_param_2, sparse_index_param],
vector_field=["dense1", "dense2", "sparse"],
connection_args={
"uri": URI,
},
consistency_level="Bounded", # Supported values are (`"Strong"`, `"Session"`, `"Bounded"`, `"Eventually"`). See https://milvus.io/docs/tune_consistency.md#Consistency-Level for more details.
drop_old=False,
)
vectorstore.vector_fields
['dense1', 'dense2', 'sparse']
Bitte achten Sie darauf, dass die Reihenfolge der Liste der Indexparameter mit der Reihenfolge von vectorstore.vector_fields übereinstimmt, um Verwechslungen zu vermeiden.
Neueinstufung der Kandidaten
Nach der ersten Stufe der Suche müssen wir die Kandidaten neu bewerten, um ein besseres Ergebnis zu erhalten. Sie können je nach Ihren Anforderungen WeightedRanker oder RRFRanker wählen. Weitere Informationen finden Sie im Abschnitt Reranking.
Hier ist ein Beispiel für gewichtetes Reranking:
vectorstore = Milvus.from_documents(
documents=docs,
embedding=OpenAIEmbeddings(),
builtin_function=BM25BuiltInFunction(),
vector_field=["dense", "sparse"],
connection_args={
"uri": URI,
},
consistency_level="Bounded", # Supported values are (`"Strong"`, `"Session"`, `"Bounded"`, `"Eventually"`). See https://milvus.io/docs/tune_consistency.md#Consistency-Level for more details.
drop_old=False,
)
query = "What are the novels Lila has written and what are their contents?"
vectorstore.similarity_search(
query, k=1, ranker_type="weighted", ranker_params={"weights": [0.6, 0.4]}
)
[Document(metadata={'pk': 454646931479252186, 'category': 'Heist/Thriller'}, page_content="In 'The Memory Thief' by Lila Rose, a charismatic thief with the ability to steal and manipulate memories is hired by a mysterious client to pull off a daring heist, but soon finds themselves trapped in a web of deceit and betrayal.")]
Hier ist ein Beispiel für RRF-Reranking:
vectorstore.similarity_search(query, k=1, ranker_type="rrf", ranker_params={"k": 100})
[Document(metadata={'category': 'Heist/Thriller', 'pk': 454646931479252186}, page_content="In 'The Memory Thief' by Lila Rose, a charismatic thief with the ability to steal and manipulate memories is hired by a mysterious client to pull off a daring heist, but soon finds themselves trapped in a web of deceit and betrayal.")]
Wenn Sie keine Parameter für das Reranking übergeben, wird standardmäßig die durchschnittliche gewichtete Rerank-Strategie verwendet.
Verwendung von hybrider Suche und Reranking in RAG
Im Szenario von RAG ist der am weitesten verbreitete Ansatz für die hybride Suche Dense + Sparse Retrieval, gefolgt von Reranking. Das folgende Beispiel zeigt einen unkomplizierten End-to-End-Code.
Vorbereiten der Daten
Wir verwenden den Langchain WebBaseLoader, um Dokumente aus Webquellen zu laden und sie mit dem RecursiveCharacterTextSplitter in Stücke zu zerlegen.
import bs4
from langchain_community.document_loaders import WebBaseLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
# Create a WebBaseLoader instance to load documents from web sources
loader = WebBaseLoader(
web_paths=(
"https://lilianweng.github.io/posts/2023-06-23-agent/",
"https://lilianweng.github.io/posts/2023-03-15-prompt-engineering/",
),
bs_kwargs=dict(
parse_only=bs4.SoupStrainer(
class_=("post-content", "post-title", "post-header")
)
),
)
# Load documents from web sources using the loader
documents = loader.load()
# Initialize a RecursiveCharacterTextSplitter for splitting text into chunks
text_splitter = RecursiveCharacterTextSplitter(chunk_size=2000, chunk_overlap=200)
# Split the documents into chunks using the text_splitter
docs = text_splitter.split_documents(documents)
# Let's take a look at the first document
docs[1]
Document(metadata={'source': 'https://lilianweng.github.io/posts/2023-06-23-agent/'}, page_content='Fig. 1. Overview of a LLM-powered autonomous agent system.\nComponent One: Planning#\nA complicated task usually involves many steps. An agent needs to know what they are and plan ahead.\nTask Decomposition#\nChain of thought (CoT; Wei et al. 2022) has become a standard prompting technique for enhancing model performance on complex tasks. The model is instructed to “think step by step” to utilize more test-time computation to decompose hard tasks into smaller and simpler steps. CoT transforms big tasks into multiple manageable tasks and shed lights into an interpretation of the model’s thinking process.\nTree of Thoughts (Yao et al. 2023) extends CoT by exploring multiple reasoning possibilities at each step. It first decomposes the problem into multiple thought steps and generates multiple thoughts per step, creating a tree structure. The search process can be BFS (breadth-first search) or DFS (depth-first search) with each state evaluated by a classifier (via a prompt) or majority vote.\nTask decomposition can be done (1) by LLM with simple prompting like "Steps for XYZ.\\n1.", "What are the subgoals for achieving XYZ?", (2) by using task-specific instructions; e.g. "Write a story outline." for writing a novel, or (3) with human inputs.\nAnother quite distinct approach, LLM+P (Liu et al. 2023), involves relying on an external classical planner to do long-horizon planning. This approach utilizes the Planning Domain Definition Language (PDDL) as an intermediate interface to describe the planning problem. In this process, LLM (1) translates the problem into “Problem PDDL”, then (2) requests a classical planner to generate a PDDL plan based on an existing “Domain PDDL”, and finally (3) translates the PDDL plan back into natural language. Essentially, the planning step is outsourced to an external tool, assuming the availability of domain-specific PDDL and a suitable planner which is common in certain robotic setups but not in many other domains.\nSelf-Reflection#')
Laden des Dokuments in den Milvus-Vektorspeicher
Wie oben beschrieben, initialisieren und laden wir die vorbereiteten Dokumente in den Milvus-Vektorspeicher, der zwei Vektorfelder enthält: dense ist für die OpenAI-Einbettung und sparse ist für die BM25-Funktion.
vectorstore = Milvus.from_documents(
documents=docs,
embedding=OpenAIEmbeddings(),
builtin_function=BM25BuiltInFunction(),
vector_field=["dense", "sparse"],
connection_args={
"uri": URI,
},
consistency_level="Bounded", # Supported values are (`"Strong"`, `"Session"`, `"Bounded"`, `"Eventually"`). See https://milvus.io/docs/tune_consistency.md#Consistency-Level for more details.
drop_old=False,
)
RAG-Kette aufbauen
Wir bereiten die LLM-Instanz und die Eingabeaufforderung vor und verbinden sie dann mit Hilfe der LangChain Expression Language zu einer RAG-Pipeline.
from langchain_core.runnables import RunnablePassthrough
from langchain_core.prompts import PromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langchain_openai import ChatOpenAI
# Initialize the OpenAI language model for response generation
llm = ChatOpenAI(model_name="gpt-4o", temperature=0)
# Define the prompt template for generating AI responses
PROMPT_TEMPLATE = """
Human: You are an AI assistant, and provides answers to questions by using fact based and statistical information when possible.
Use the following pieces of information to provide a concise answer to the question enclosed in <question> tags.
If you don't know the answer, just say that you don't know, don't try to make up an answer.
<context>
{context}
</context>
<question>
{question}
</question>
The response should be specific and use statistics or numbers when possible.
Assistant:"""
# Create a PromptTemplate instance with the defined template and input variables
prompt = PromptTemplate(
template=PROMPT_TEMPLATE, input_variables=["context", "question"]
)
# Convert the vector store to a retriever
retriever = vectorstore.as_retriever()
# Define a function to format the retrieved documents
def format_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)
Verwenden Sie die LCEL (LangChain Expression Language), um eine RAG-Kette zu erstellen.
# Define the RAG (Retrieval-Augmented Generation) chain for AI response generation
rag_chain = (
{"context": retriever | format_docs, "question": RunnablePassthrough()}
| prompt
| llm
| StrOutputParser()
)
# rag_chain.get_graph().print_ascii()
Rufen Sie die RAG-Kette mit einer bestimmten Frage auf und rufen Sie die Antwort ab
query = "What is PAL and PoT?"
res = rag_chain.invoke(query)
res
'PAL (Program-aided Language models) and PoT (Program of Thoughts prompting) are approaches that involve using language models to generate programming language statements to solve natural language reasoning problems. This method offloads the solution step to a runtime, such as a Python interpreter, allowing for complex computation and reasoning to be handled externally. PAL and PoT rely on language models with strong coding skills to effectively perform these tasks.'
Herzlichen Glückwunsch! Sie haben eine hybride (dichte Vektor- + spärliche bm25-Funktion) RAG-Kette auf der Grundlage von Milvus und LangChain erstellt.