Analyzer Überblick
In der Textverarbeitung ist ein Analyzer eine entscheidende Komponente, die Rohtext in ein strukturiertes, durchsuchbares Format umwandelt. Jeder Analyzer besteht in der Regel aus zwei Kernelementen: Tokenizer und Filter. Gemeinsam wandeln sie den Eingabetext in Token um, verfeinern diese Token und bereiten sie für eine effiziente Indizierung und Suche vor.
In Milvus werden die Analyzer während der Erstellung der Sammlung konfiguriert, wenn Sie VARCHAR Felder zum Schema der Sammlung hinzufügen. Die von einem Analyzer erzeugten Token können zum Aufbau eines Indexes für den Schlüsselwortabgleich verwendet oder in Sparse Embeddings für die Volltextsuche konvertiert werden. Weitere Informationen finden Sie unter Volltextsuche, Phrasenabgleich oder Textabgleich.
Die Verwendung von Analyzern kann die Leistung beeinträchtigen:
Volltextsuche: Bei der Volltextsuche verbrauchen die DataNode- und QueryNode-Channels die Daten langsamer, da sie auf den Abschluss der Tokenisierung warten müssen. Infolgedessen dauert es länger, bis neu eingegebene Daten für die Suche verfügbar sind.
Schlüsselwort-Abgleich: Beim Stichwortabgleich ist die Indexerstellung ebenfalls langsamer, da die Tokenisierung abgeschlossen werden muss, bevor ein Index erstellt werden kann.
Anatomie eines Analyzers
Ein Analyzer in Milvus besteht aus genau einem Tokenizer und null oder mehr Filtern.
Tokenisierer: Der Tokenisierer zerlegt den Eingabetext in diskrete Einheiten, die Token genannt werden. Diese Token können Wörter oder Phrasen sein, je nach Tokenizer-Typ.
Filter: Filter können auf Token angewandt werden, um sie weiter zu verfeinern, z. B. indem sie kleingeschrieben oder gemeinsame Wörter entfernt werden.
Tokenizer unterstützen nur das UTF-8-Format. Die Unterstützung für andere Formate wird in zukünftigen Versionen hinzugefügt.
Der folgende Arbeitsablauf zeigt, wie ein Analysator Text verarbeitet.
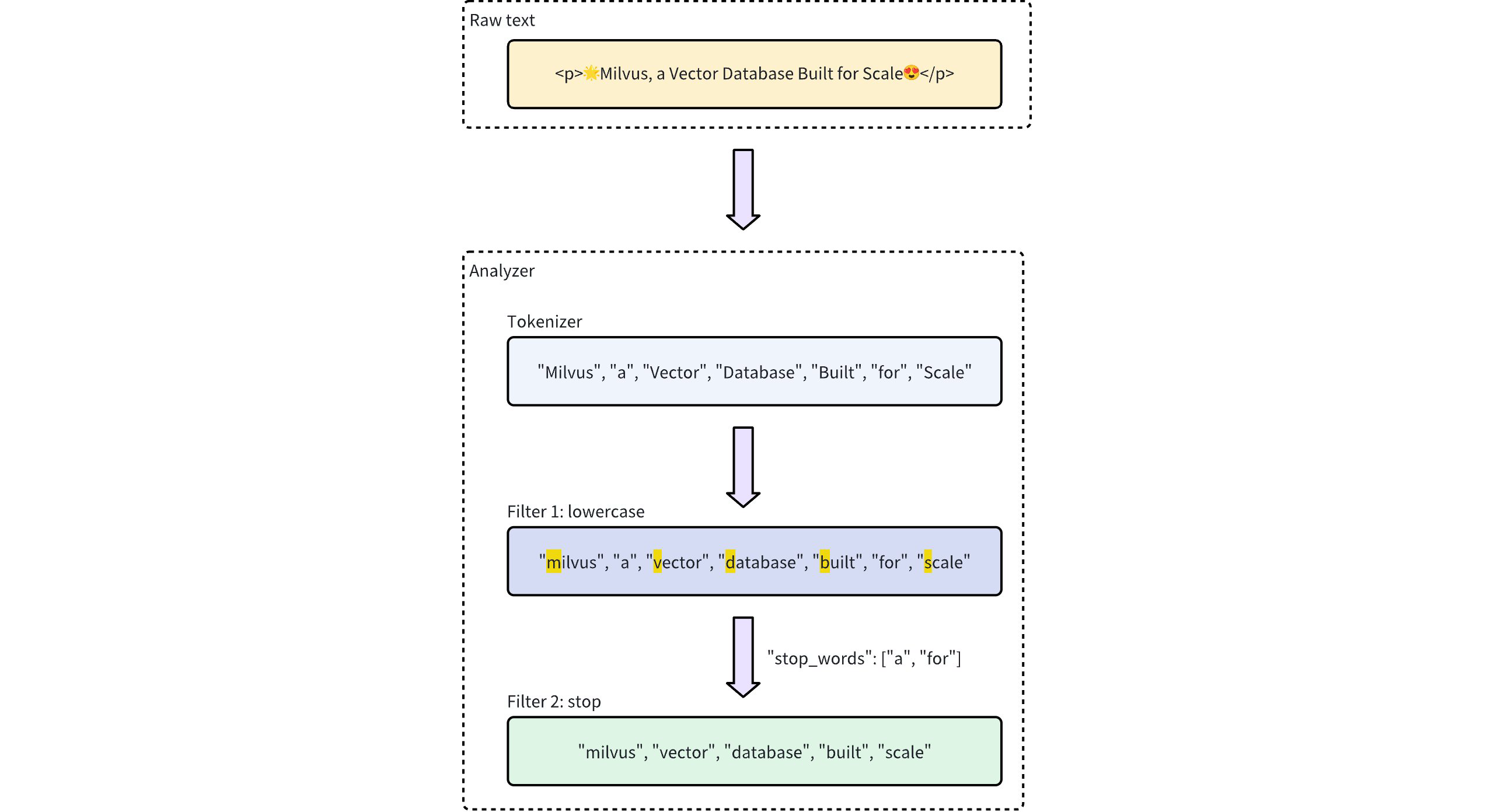 Analyzer-Prozess-Workflow
Analyzer-Prozess-Workflow
Analyzer-Typen
Milvus bietet zwei Arten von Analysatoren, um unterschiedliche Anforderungen an die Textverarbeitung zu erfüllen:
Eingebauter Analysator: Hierbei handelt es sich um vordefinierte Konfigurationen, die gängige Textverarbeitungsaufgaben mit minimaler Einrichtung abdecken. Eingebaute Analysatoren sind ideal für allgemeine Suchen, da sie keine komplexe Konfiguration erfordern.
Benutzerdefinierter Analyzer: Für anspruchsvollere Anforderungen können Sie mit benutzerdefinierten Analysatoren Ihre eigene Konfiguration definieren, indem Sie sowohl den Tokenizer als auch null oder mehr Filter angeben. Dieser Grad der Anpassung ist besonders nützlich für spezielle Anwendungsfälle, bei denen eine genaue Kontrolle über die Textverarbeitung erforderlich ist.
- Wenn Sie bei der Erstellung der Sammlung keine Analysator-Konfigurationen vornehmen, verwendet Milvus standardmäßig den
standardAnalysator für die gesamte Textverarbeitung. Weitere Informationen finden Sie unter Standard-Analysator. - Um eine optimale Such- und Abfrageleistung zu erzielen, wählen Sie einen Analyzer, der der Sprache Ihrer Textdaten entspricht. Der
standardAnalyzer ist zwar vielseitig, aber für Sprachen mit einzigartigen grammatikalischen Strukturen wie Chinesisch, Japanisch oder Koreanisch ist er möglicherweise nicht die beste Wahl. In solchen Fällen sollten Sie einen sprachspezifischen Analyzer wiechineseoder benutzerdefinierte Analysatoren mit spezialisierten Tokenizern (wie z. B.lindera,icu) und Filtern wird dringend empfohlen, um eine genaue Tokenisierung und bessere Suchergebnisse zu gewährleisten.
Eingebauter Analyzer
Eingebaute Analysatoren in Milvus sind mit spezifischen Tokenizern und Filtern vorkonfiguriert, so dass Sie sie sofort verwenden können, ohne diese Komponenten selbst definieren zu müssen. Jeder eingebaute Analyzer dient als Vorlage, die einen voreingestellten Tokenizer und Filter mit optionalen Parametern zur Anpassung enthält.
Um zum Beispiel den eingebauten Analyzer standard zu verwenden, geben Sie einfach seinen Namen standard als type an und fügen optional zusätzliche Konfigurationen hinzu, die für diesen Analyzer-Typ spezifisch sind, wie stop_words:
analyzer_params = {
"type": "standard", # Uses the standard built-in analyzer
"stop_words": ["a", "an", "for"] # Defines a list of common words (stop words) to exclude from tokenization
}
Map<String, Object> analyzerParams = new HashMap<>();
analyzerParams.put("type", "standard");
analyzerParams.put("stop_words", Arrays.asList("a", "an", "for"));
const analyzer_params = {
"type": "standard", // Uses the standard built-in analyzer
"stop_words": ["a", "an", "for"] // Defines a list of common words (stop words) to exclude from tokenization
};
analyzerParams := map[string]any{"type": "standard", "stop_words": []string{"a", "an", "for"}}
export analyzerParams='{
"type": "standard",
"stop_words": ["a", "an", "for"]
}'
Um das Ergebnis der Ausführung eines Analyzers zu überprüfen, verwenden Sie die Methode run_analyzer:
# Sample text to analyze
text = "An efficient system relies on a robust analyzer to correctly process text for various applications."
# Run analyzer
result = client.run_analyzer(
text,
analyzer_params
)
import io.milvus.v2.service.vector.request.RunAnalyzerReq;
import io.milvus.v2.service.vector.response.RunAnalyzerResp;
List<String> texts = new ArrayList<>();
texts.add("An efficient system relies on a robust analyzer to correctly process text for various applications.");
RunAnalyzerResp resp = client.runAnalyzer(RunAnalyzerReq.builder()
.texts(texts)
.analyzerParams(analyzerParams)
.build());
List<RunAnalyzerResp.AnalyzerResult> results = resp.getResults();
// javascrip# Sample text to analyze
const text = "An efficient system relies on a robust analyzer to correctly process text for various applications."
// Run analyzer
const result = await client.run_analyzer({
text,
analyzer_params
});
import (
"context"
"encoding/json"
"fmt"
"github.com/milvus-io/milvus/client/v2/milvusclient"
)
bs, _ := json.Marshal(analyzerParams)
texts := []string{"An efficient system relies on a robust analyzer to correctly process text for various applications."}
option := milvusclient.NewRunAnalyzerOption(texts).
WithAnalyzerParams(string(bs))
result, err := client.RunAnalyzer(ctx, option)
if err != nil {
fmt.Println(err.Error())
// handle error
}
# restful
Die Ausgabe wird sein:
['efficient', 'system', 'relies', 'on', 'robust', 'analyzer', 'to', 'correctly', 'process', 'text', 'various', 'applications']
Dies zeigt, dass der Analyzer den Eingabetext richtig tokenisiert, indem er die Stoppwörter "a", "an" und "for" herausfiltert und die verbleibenden sinnvollen Token zurückgibt.
Die obige Konfiguration des eingebauten Analysators standard entspricht dem Einrichten eines benutzerdefinierten Analysators mit den folgenden Parametern, wobei die Optionen tokenizer und filter explizit definiert werden, um eine ähnliche Funktionalität zu erreichen:
analyzer_params = {
"tokenizer": "standard",
"filter": [
"lowercase",
{
"type": "stop",
"stop_words": ["a", "an", "for"]
}
]
}
Map<String, Object> analyzerParams = new HashMap<>();
analyzerParams.put("tokenizer", "standard");
analyzerParams.put("filter",
Arrays.asList("lowercase",
new HashMap<String, Object>() {{
put("type", "stop");
put("stop_words", Arrays.asList("a", "an", "for"));
}}));
const analyzer_params = {
"tokenizer": "standard",
"filter": [
"lowercase",
{
"type": "stop",
"stop_words": ["a", "an", "for"]
}
]
};
analyzerParams = map[string]any{"tokenizer": "standard",
"filter": []any{"lowercase", map[string]any{
"type": "stop",
"stop_words": []string{"a", "an", "for"},
}}}
export analyzerParams='{
"type": "standard",
"filter": [
"lowercase",
{
"type": "stop",
"stop_words": ["a", "an", "for"]
}
]
}'
Milvus bietet die folgenden eingebauten Analyzer, die jeweils für spezifische Textverarbeitungsbedürfnisse entwickelt wurden:
standard: Geeignet für die allgemeine Textverarbeitung, mit Standard-Tokenisierung und Kleinbuchstaben-Filterung.english: Optimiert für englischsprachige Texte, mit Unterstützung für englische Stoppwörter.chinese: Spezialisiert auf die Verarbeitung chinesischer Texte, einschließlich Tokenisierung, die an die Strukturen der chinesischen Sprache angepasst ist.
Benutzerdefinierter Analysator
Für fortgeschrittene Textverarbeitung können Sie mit den benutzerdefinierten Analysatoren in Milvus eine maßgeschneiderte Textverarbeitungspipeline aufbauen, indem Sie sowohl einen Tokenizer als auch Filter angeben. Diese Konfiguration ist ideal für spezielle Anwendungsfälle, bei denen eine präzise Kontrolle erforderlich ist.
Tokenisierer
Der Tokenizer ist eine obligatorische Komponente für einen benutzerdefinierten Analyzer, der die Analyzer-Pipeline startet, indem er den Eingabetext in diskrete Einheiten oder Token zerlegt. Die Tokenisierung folgt je nach Tokenizer-Typ bestimmten Regeln, wie z. B. der Aufteilung nach Leerzeichen oder Interpunktion. Dieser Prozess ermöglicht eine präzisere und unabhängige Behandlung jedes Worts oder Satzes.
Ein Tokenizer würde zum Beispiel den Text "Vector Database Built for Scale" in einzelne Token umwandeln:
["Vector", "Database", "Built", "for", "Scale"]
Beispiel für die Angabe eines Tokenizers:
analyzer_params = {
"tokenizer": "whitespace",
}
Map<String, Object> analyzerParams = new HashMap<>();
analyzerParams.put("tokenizer", "whitespace");
const analyzer_params = {
"tokenizer": "whitespace",
};
analyzerParams = map[string]any{"tokenizer": "whitespace"}
export analyzerParams='{
"type": "whitespace"
}'
Filter
Filter sind optionale Komponenten, die mit den vom Tokenizer erzeugten Token arbeiten und sie je nach Bedarf transformieren oder verfeinern. Nach Anwendung eines lowercase -Filters auf die tokenisierten Begriffe ["Vector", "Database", "Built", "for", "Scale"] könnte das Ergebnis zum Beispiel so aussehen:
["vector", "database", "built", "for", "scale"]
Filter in einem benutzerdefinierten Analyzer können entweder eingebaut oder benutzerdefiniert sein, je nach Konfigurationsbedarf.
Eingebaute Filter: Sie sind von Milvus vorkonfiguriert und erfordern nur eine minimale Einrichtung. Sie können diese Filter sofort verwenden, indem Sie ihre Namen angeben. Die folgenden Filter sind für den direkten Gebrauch eingebaut:
lowercase: Konvertiert Text in Kleinbuchstaben, um die Groß-/Kleinschreibung nicht zu berücksichtigen. Einzelheiten finden Sie unter Kleinschreibung.asciifolding: Konvertiert Nicht-ASCII-Zeichen in ASCII-Äquivalente und vereinfacht so die Handhabung mehrsprachiger Texte. Weitere Informationen finden Sie unter ASCII-Faltung.alphanumonly: Behält nur alphanumerische Zeichen bei und entfernt andere. Details finden Sie unter Alphanumonly.cnalphanumonly: Entfernt Token, die andere Zeichen als chinesische Zeichen, englische Buchstaben oder Ziffern enthalten. Für weitere Informationen siehe Cnalphanumonly.cncharonly: Entfernt Token, die nicht-chinesische Zeichen enthalten. Einzelheiten finden Sie unter Cncharonly.
Beispiel für die Verwendung eines eingebauten Filters:
analyzer_params = { "tokenizer": "standard", # Mandatory: Specifies tokenizer "filter": ["lowercase"], # Optional: Built-in filter that converts text to lowercase }Map<String, Object> analyzerParams = new HashMap<>(); analyzerParams.put("tokenizer", "standard"); analyzerParams.put("filter", Collections.singletonList("lowercase"));const analyzer_params = { "tokenizer": "standard", // Mandatory: Specifies tokenizer "filter": ["lowercase"], // Optional: Built-in filter that converts text to lowercase }analyzerParams = map[string]any{"tokenizer": "standard", "filter": []any{"lowercase"}}export analyzerParams='{ "type": "standard", "filter": ["lowercase"] }'Benutzerdefinierte Filter: Benutzerdefinierte Filter ermöglichen spezielle Konfigurationen. Sie können einen benutzerdefinierten Filter definieren, indem Sie einen gültigen Filtertyp auswählen (
filter.type) und spezifische Einstellungen für jeden Filtertyp hinzufügen. Beispiele für Filtertypen, die Anpassungen unterstützen:stop: Entfernt bestimmte gebräuchliche Wörter, indem eine Liste von Stopp-Wörtern festgelegt wird (z. B."stop_words": ["of", "to"]). Einzelheiten finden Sie unter Stopp.length: Schließt Token aufgrund von Längenkriterien aus, z. B. durch Festlegen einer maximalen Tokenlänge. Weitere Informationen finden Sie unter Länge.stemmer: Reduziert Wörter auf ihre Stammformen für eine flexiblere Anpassung. Weitere Informationen finden Sie unter Stemmer.
Beispiel für die Konfiguration eines benutzerdefinierten Filters:
analyzer_params = { "tokenizer": "standard", # Mandatory: Specifies tokenizer "filter": [ { "type": "stop", # Specifies 'stop' as the filter type "stop_words": ["of", "to"], # Customizes stop words for this filter type } ] }Map<String, Object> analyzerParams = new HashMap<>(); analyzerParams.put("tokenizer", "standard"); analyzerParams.put("filter", Collections.singletonList(new HashMap<String, Object>() {{ put("type", "stop"); put("stop_words", Arrays.asList("a", "an", "for")); }}));const analyzer_params = { "tokenizer": "standard", // Mandatory: Specifies tokenizer "filter": [ { "type": "stop", // Specifies 'stop' as the filter type "stop_words": ["of", "to"], // Customizes stop words for this filter type } ] };analyzerParams = map[string]any{"tokenizer": "standard", "filter": []any{map[string]any{ "type": "stop", "stop_words": []string{"of", "to"}, }}}export analyzerParams='{ "type": "standard", "filter": [ { "type": "stop", "stop_words": ["a", "an", "for"] } ] }'
Beispiel für die Verwendung
In diesem Beispiel erstellen Sie ein Sammlungsschema, das Folgendes enthält:
Ein Vektorfeld für Einbettungen.
Zwei
VARCHARFelder für die Textverarbeitung:Ein Feld verwendet einen eingebauten Analyzer.
Das andere verwendet einen benutzerdefinierten Analyzer.
Bevor Sie diese Konfigurationen in Ihre Sammlung aufnehmen, werden Sie jeden Analyzer mit der Methode run_analyzer überprüfen.
Schritt 1: MilvusClient initialisieren und Schema erstellen
Beginnen Sie mit dem Einrichten des Milvus-Clients und dem Erstellen eines neuen Schemas.
from pymilvus import MilvusClient, DataType
# Set up a Milvus client
client = MilvusClient(uri="http://localhost:19530")
# Create a new schema
schema = client.create_schema(auto_id=True, enable_dynamic_field=False)
import io.milvus.v2.client.ConnectConfig;
import io.milvus.v2.client.MilvusClientV2;
import io.milvus.v2.common.DataType;
import io.milvus.v2.common.IndexParam;
import io.milvus.v2.service.collection.request.AddFieldReq;
import io.milvus.v2.service.collection.request.CreateCollectionReq;
// Set up a Milvus client
ConnectConfig config = ConnectConfig.builder()
.uri("http://localhost:19530")
.build();
MilvusClientV2 client = new MilvusClientV2(config);
// Create schema
CreateCollectionReq.CollectionSchema schema = CreateCollectionReq.CollectionSchema.builder()
.enableDynamicField(false)
.build();
import { MilvusClient, DataType } from "@zilliz/milvus2-sdk-node";
// Set up a Milvus client
const client = new MilvusClient("http://localhost:19530");
import (
"context"
"fmt"
"github.com/milvus-io/milvus/client/v2/column"
"github.com/milvus-io/milvus/client/v2/entity"
"github.com/milvus-io/milvus/client/v2/index"
"github.com/milvus-io/milvus/client/v2/milvusclient"
)
ctx, cancel := context.WithCancel(context.Background())
defer cancel()
cli, err := milvusclient.New(ctx, &milvusclient.ClientConfig{
Address: "localhost:19530",
})
if err != nil {
fmt.Println(err.Error())
// handle err
}
defer client.Close(ctx)
schema := entity.NewSchema().WithAutoID(true).WithDynamicFieldEnabled(false)
# restful
Schritt 2: Konfigurationen für den Analyzer definieren und verifizieren
Konfigurieren und verifizieren Sie einen eingebauten Analyzer (
english):Konfiguration: Definieren Sie die Analyzer-Parameter für den integrierten englischen Analyzer.
Überprüfen: Verwenden Sie
run_analyzer, um zu überprüfen, ob die Konfiguration die erwartete Tokenisierung erzeugt.
# Built-in analyzer configuration for English text processing analyzer_params_built_in = { "type": "english" } # Verify built-in analyzer configuration sample_text = "Milvus simplifies text analysis for search." result = client.run_analyzer(sample_text, analyzer_params_built_in) print("Built-in analyzer output:", result) # Expected output: # Built-in analyzer output: ['milvus', 'simplifi', 'text', 'analysi', 'search']Map<String, Object> analyzerParamsBuiltin = new HashMap<>(); analyzerParamsBuiltin.put("type", "english"); List<String> texts = new ArrayList<>(); texts.add("Milvus simplifies text ana lysis for search."); RunAnalyzerResp resp = client.runAnalyzer(RunAnalyzerReq.builder() .texts(texts) .analyzerParams(analyzerParams) .build()); List<RunAnalyzerResp.AnalyzerResult> results = resp.getResults();// Use a built-in analyzer for VARCHAR field `title_en` const analyzerParamsBuiltIn = { type: "english", }; const sample_text = "Milvus simplifies text analysis for search."; const result = await client.run_analyzer({ text: sample_text, analyzer_params: analyzer_params_built_in });analyzerParams := map[string]any{"type": "english"} bs, _ := json.Marshal(analyzerParams) texts := []string{"Milvus simplifies text analysis for search."} option := milvusclient.NewRunAnalyzerOption(texts). WithAnalyzerParams(string(bs)) result, err := client.RunAnalyzer(ctx, option) if err != nil { fmt.Println(err.Error()) // handle error }# restfulKonfigurieren und überprüfen Sie einen benutzerdefinierten Analyzer:
Konfiguration: Definieren Sie einen benutzerdefinierten Analyzer, der einen Standard-Tokenizer zusammen mit einem eingebauten Kleinbuchstabenfilter und benutzerdefinierten Filtern für Tokenlänge und Stoppwörter verwendet.
Überprüfen: Verwenden Sie
run_analyzer, um sicherzustellen, dass die benutzerdefinierte Konfiguration Text wie vorgesehen verarbeitet.
# Custom analyzer configuration with a standard tokenizer and custom filters analyzer_params_custom = { "tokenizer": "standard", "filter": [ "lowercase", # Built-in filter: convert tokens to lowercase { "type": "length", # Custom filter: restrict token length "max": 40 }, { "type": "stop", # Custom filter: remove specified stop words "stop_words": ["of", "for"] } ] } # Verify custom analyzer configuration sample_text = "Milvus provides flexible, customizable analyzers for robust text processing." result = client.run_analyzer(sample_text, analyzer_params_custom) print("Custom analyzer output:", result) # Expected output: # Custom analyzer output: ['milvus', 'provides', 'flexible', 'customizable', 'analyzers', 'robust', 'text', 'processing']// Configure a custom analyzer Map<String, Object> analyzerParams = new HashMap<>(); analyzerParams.put("tokenizer", "standard"); analyzerParams.put("filter", Arrays.asList("lowercase", new HashMap<String, Object>() {{ put("type", "length"); put("max", 40); }}, new HashMap<String, Object>() {{ put("type", "stop"); put("stop_words", Arrays.asList("of", "for")); }} ) ); List<String> texts = new ArrayList<>(); texts.add("Milvus provides flexible, customizable analyzers for robust text processing."); RunAnalyzerResp resp = client.runAnalyzer(RunAnalyzerReq.builder() .texts(texts) .analyzerParams(analyzerParams) .build()); List<RunAnalyzerResp.AnalyzerResult> results = resp.getResults();// Configure a custom analyzer for VARCHAR field `title` const analyzerParamsCustom = { tokenizer: "standard", filter: [ "lowercase", { type: "length", max: 40, }, { type: "stop", stop_words: ["of", "to"], }, ], }; const sample_text = "Milvus provides flexible, customizable analyzers for robust text processing."; const result = await client.run_analyzer({ text: sample_text, analyzer_params: analyzer_params_built_in });analyzerParams = map[string]any{"tokenizer": "standard", "filter": []any{"lowercase", map[string]any{ "type": "length", "max": 40, map[string]any{ "type": "stop", "stop_words": []string{"of", "to"}, }}} bs, _ := json.Marshal(analyzerParams) texts := []string{"Milvus provides flexible, customizable analyzers for robust text processing."} option := milvusclient.NewRunAnalyzerOption(texts). WithAnalyzerParams(string(bs)) result, err := client.RunAnalyzer(ctx, option) if err != nil { fmt.Println(err.Error()) // handle error }# curl
Schritt 3: Felder zum Schema hinzufügen
Nachdem Sie Ihre Analysator-Konfigurationen überprüft haben, fügen Sie diese zu Ihren Schemafeldern hinzu:
# Add VARCHAR field 'title_en' using the built-in analyzer configuration
schema.add_field(
field_name='title_en',
datatype=DataType.VARCHAR,
max_length=1000,
enable_analyzer=True,
analyzer_params=analyzer_params_built_in,
enable_match=True,
)
# Add VARCHAR field 'title' using the custom analyzer configuration
schema.add_field(
field_name='title',
datatype=DataType.VARCHAR,
max_length=1000,
enable_analyzer=True,
analyzer_params=analyzer_params_custom,
enable_match=True,
)
# Add a vector field for embeddings
schema.add_field(field_name="embedding", datatype=DataType.FLOAT_VECTOR, dim=3)
# Add a primary key field
schema.add_field(field_name="id", datatype=DataType.INT64, is_primary=True)
schema.addField(AddFieldReq.builder()
.fieldName("title")
.dataType(DataType.VarChar)
.maxLength(1000)
.enableAnalyzer(true)
.analyzerParams(analyzerParams)
.enableMatch(true) // must enable this if you use TextMatch
.build());
// Add vector field
schema.addField(AddFieldReq.builder()
.fieldName("embedding")
.dataType(DataType.FloatVector)
.dimension(3)
.build());
// Add primary field
schema.addField(AddFieldReq.builder()
.fieldName("id")
.dataType(DataType.Int64)
.isPrimaryKey(true)
.autoID(true)
.build());
// Create schema
const schema = {
auto_id: true,
fields: [
{
name: "id",
type: DataType.INT64,
is_primary: true,
},
{
name: "title_en",
data_type: DataType.VARCHAR,
max_length: 1000,
enable_analyzer: true,
analyzer_params: analyzerParamsBuiltIn,
enable_match: true,
},
{
name: "title",
data_type: DataType.VARCHAR,
max_length: 1000,
enable_analyzer: true,
analyzer_params: analyzerParamsCustom,
enable_match: true,
},
{
name: "embedding",
data_type: DataType.FLOAT_VECTOR,
dim: 4,
},
],
};
schema.WithField(entity.NewField().
WithName("id").
WithDataType(entity.FieldTypeInt64).
WithIsPrimaryKey(true).
WithIsAutoID(true),
).WithField(entity.NewField().
WithName("embedding").
WithDataType(entity.FieldTypeFloatVector).
WithDim(3),
).WithField(entity.NewField().
WithName("title").
WithDataType(entity.FieldTypeVarChar).
WithMaxLength(1000).
WithEnableAnalyzer(true).
WithAnalyzerParams(analyzerParams).
WithEnableMatch(true),
)
# restful
Schritt 4: Bereiten Sie die Indexparameter vor und erstellen Sie die Sammlung
# Set up index parameters for the vector field
index_params = client.prepare_index_params()
index_params.add_index(field_name="embedding", metric_type="COSINE", index_type="AUTOINDEX")
# Create the collection with the defined schema and index parameters
client.create_collection(
collection_name="my_collection",
schema=schema,
index_params=index_params
)
// Set up index params for vector field
List<IndexParam> indexes = new ArrayList<>();
indexes.add(IndexParam.builder()
.fieldName("embedding")
.indexType(IndexParam.IndexType.AUTOINDEX)
.metricType(IndexParam.MetricType.COSINE)
.build());
// Create collection with defined schema
CreateCollectionReq requestCreate = CreateCollectionReq.builder()
.collectionName("my_collection")
.collectionSchema(schema)
.indexParams(indexes)
.build();
client.createCollection(requestCreate);
// Set up index params for vector field
const indexParams = [
{
name: "embedding",
metric_type: "COSINE",
index_type: "AUTOINDEX",
},
];
// Create collection with defined schema
await client.createCollection({
collection_name: "my_collection",
schema: schema,
index_params: indexParams,
});
console.log("Collection created successfully!");
idx := index.NewAutoIndex(index.MetricType(entity.COSINE))
indexOption := milvusclient.NewCreateIndexOption("my_collection", "embedding", idx)
err = client.CreateCollection(ctx,
milvusclient.NewCreateCollectionOption("my_collection", schema).
WithIndexOptions(indexOption))
if err != nil {
fmt.Println(err.Error())
// handle error
}
# restful
Wie geht es weiter?
Nachdem Sie einen Analyzer konfiguriert haben, können Sie die von Milvus bereitgestellten Textabfragefunktionen integrieren. Für Details: