How to Compact Data in Milvus?
 Binlog Cover Image
Binlog Cover Image
By Bingyi Sun and Angela Ni.
With the official release of Milvus 2.0 GA, a list of new features are supported. Among those, compaction is one of the new features that can help you save storage space.
Compaction refers to the process of merging small segments into large ones and clean logically deleted data. In other words, compaction reduces usage of disk space by purging the deleted or expired entities in binlogs. It is a background task that is triggered by data coord and executed by data node in Milvus.
This article dissects the concept and implementation of compaction in Milvus.
What is compaction?
Before going deep into the details of how to implement compaction in Milvus 2.0, it is critical to figure out what compaction is in Milvus.
More often than not, as a Milvus user you might have been bothered by the increasing usage of hard disk space. Another issue is that a segment with less than 1,024 rows is not indexed and only supports brute-force search to process queries. Small segments caused by auto-flush or user-invoked flush might hamper query efficiency.
Therefore, to solve the two issues mentioned above and help reduce disk usage and improve query efficiency, Milvus supports compaction.
Databases like LevelDB and RocksDB append data to sorted strings tables (SSTables). The average disk reads per query increase with the number of SSTables, leading to inefficient queries. To reduce read amplification and release hard drive space, these databases compact SSTables into one. Compaction processes run in the background automatically.
Similarly, Milvus appends inserted and deleted data to binlogs. As the number of binlogs increases, more hard disk space is used. To release hard disk space, Milvus compacts binlogs of deleted and inserted data. If an entity is inserted but later deleted, it no longer exists in the binlogs that records data insertion or deletion once compacted. In addition, Milvus also compacts segments - data files automatically created by Milvus for holding inserted data.
How to configure compaction?
Configuration of compaction in Milvus mainly involves two parameters: dataCoord.enableCompaction and common.retentionDuration.
dataCoord.enableCompaction specifies whether to enable compaction. Its default value is true.
common.retentionDuration specifies a period when compaction does not run. Its unit is second. When you compact data, all deleted entities will be made unavailable for search with Time Travel. Therefore, if you plan to search with Time Travel, you have to specify a period of time during which compaction does not run and does not affect deleted data. To ensure accurate results of searches with Time Travel, Milvus retains data operated in a period specified by common.retentionDuration. That is, data operated in this period will not be compacted. For more details, see Search with Time Travel.
Compaction is enabled in Milvus by default. If you disabled compaction but later want to manually enable it, you can follow the steps below:
- Call the
collection.compact()method to trigger a global compaction process manually. However, please be noted that this operation might take a long time. - After calling the method, a compaction ID is returned. View the compaction status by calling the
collection.get_compaction_state()method.
After compaction is enabled, it runs in the background automatically. Since the compaction process might take a long time, compaction requests are processed asynchronously to save time.
How to implement compaction?
In Milvus, you can either implement compaction manually or automatically.
Manual compaction of binlogs or segments does not require meeting any trigger conditions. Therefore, if you manually invoke compaction, the binlogs or segments will be compacted no matter what.
However, if you want to enable automatic compaction, certain compaction trigger conditions need to be met in order for the system to compact your segments or binlogs.
Generally there are two types of objects that can be compacted in Milvus: binglogs and segments.
Binlog compaction
A binlog is a binary log, or a smaller unit in segment, that records and handles the updates and changes made to data in the Milvus vector database. Data from a segment is persisted in multiple binlogs. Binlog compaction involves two types of binlogs in Milvus: insert binlogs and delta binlogs.
Delta binlogs are generated when data is deleted while insert binlogs are generated under the following three circumstances.
- As inserted data is being appended, the segment reaches the upper limit of size and is automatically flushed to the disk.
- DataCoord automatically flushes segments that stay unsealed for a long time.
- Some APIs like
collection.num_entities,collection.load(), and more automatically invoke flush to write segments to disk.
Therefore, binlog compaction, as its name suggests, refers to compacting binlogs within a segment. More specifically, during binlog compaction, all delta binlogs and insert binlogs that are not retained are compacted.
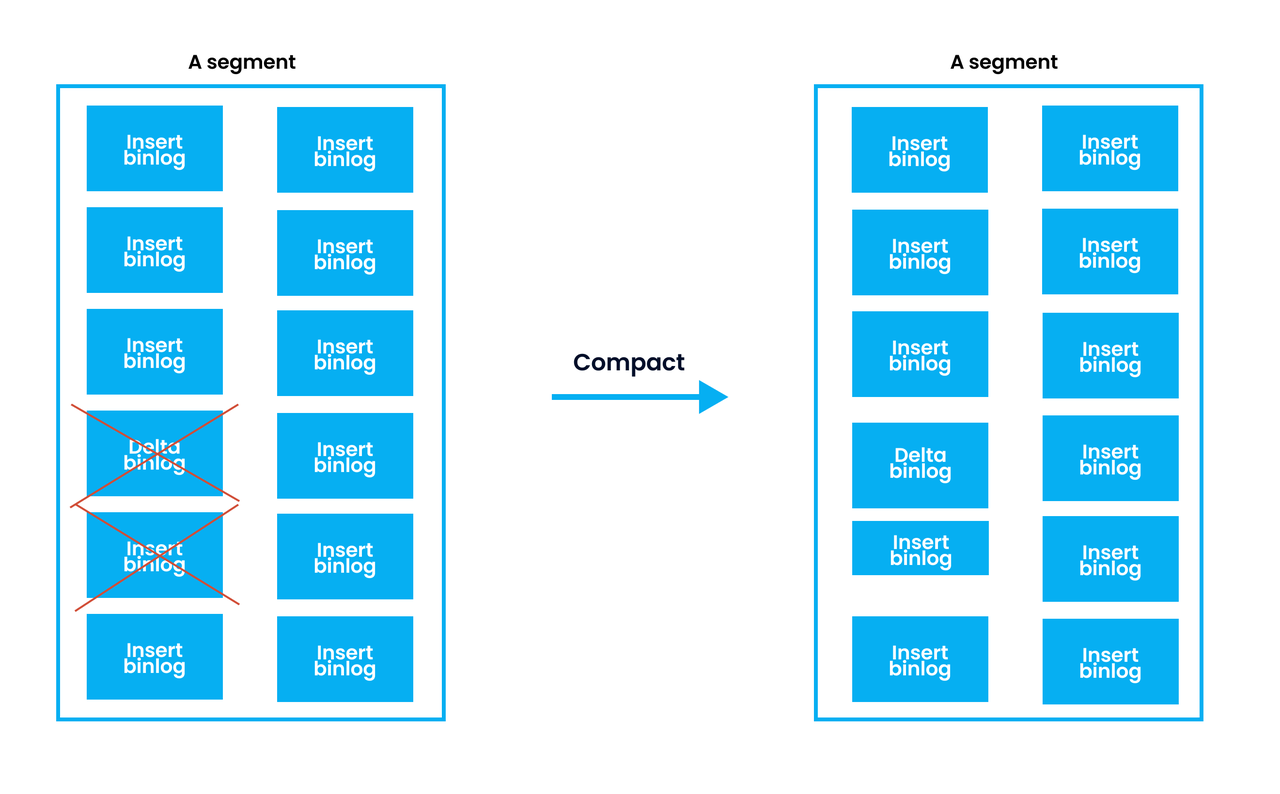 Binlog compaction
Binlog compaction
When a segment is flushed to disk, or when Milvus requests global compaction as compaction has not run for a long time, at least one of the following two conditions need to be met to trigger automatic compaction:
- Rows in delta binlogs are more than 20% of the total rows.
- The size of delta binlogs exceeds 10 MB.
Segment compaction
A segment is a data file automatically created by Milvus for holding inserted data. There are two types of segments in Milvus: growing segment and sealed segment.
A growing segment keeps receiving the newly inserted data until it is sealed. A sealed segment no longer receives any new data, and will be flushed to the object storage, leaving new data to be inserted into a newly created growing segment.
Therefore, segment compaction refers to compacting multiple sealed segments. More specifically, during segment compaction, small segments are compacted into bigger ones.
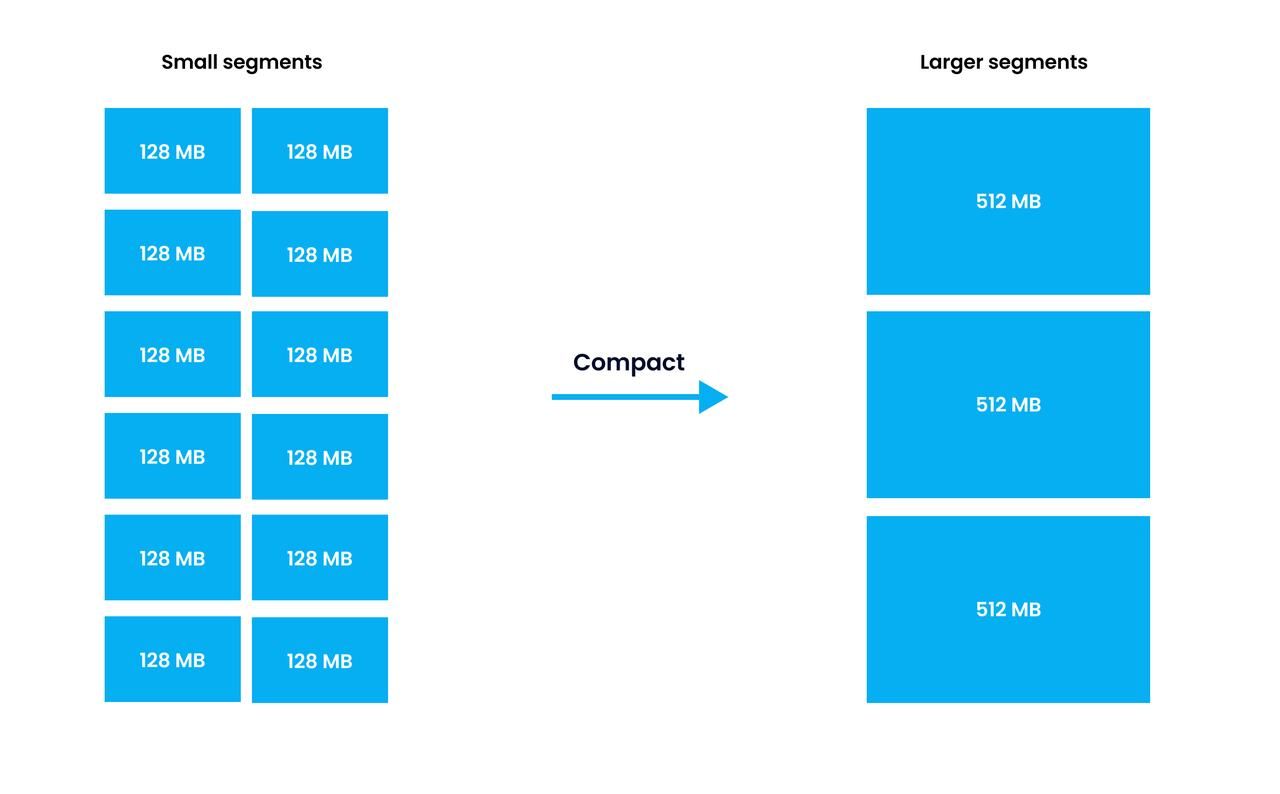 Segment compaction
Segment compaction
Each segment generated after compaction cannot exceed the upper limit of a segment size, which is 512 MB by default. Read system configurations to learn how to modify the upper limit of a segment size.
When a segment flushes to disk, or when Milvus requests global compaction as compaction has not run for a long time, the following condition needs to be met to trigger automatic compaction:
- Segments smaller than 0.5 *
MaxSegmentSizeis more than 10.
What’s next?
What’s next after learning the basics of compaction in Milvus? Currently, not all parameters for configuring compaction are in the milvus.yaml file, and plan generation strategies are relatively basic. Come and contribute to Milvus, the open-source project if you are interested!
Also, in the 2.0 new feature series blog, we aim to explain the design of the new features. Read more in this blog series!
- How Milvus Deletes Streaming Data in a Distributed Cluster
- How to Compact Data in Milvus?
- How Milvus Balances Query Load across Nodes?
- How Bitset Enables the Versatility of Vector Similarity Search
About the author
Bingyi Sun, Senior Software Engineer of the Milvus project, achieved his Master’s degree in software engineering at Shanghai Jiao Tong University. He is mainly responsible for developing storage related components in Milvus 2.0. His area of interest is database and distributed systems. He is great fan of open source projects and a gourmet who enjoys playing video games and reading in his spare time.
- What is compaction?
- How to configure compaction?
- How to implement compaction?
- Binlog compaction
- Segment compaction
- What's next?
- About the author
On This Page
Try Managed Milvus for Free
Zilliz Cloud is hassle-free, powered by Milvus and 10x faster.
Get StartedLike the article? Spread the word



