How Milvus Deletes Streaming Data in a Distributed Cluster
Featuring unified batch-and-stream processing and cloud-native architecture, Milvus 2.0 poses a greater challenge than its predecessor did during the development of the DELETE function. Thanks to its advanced storage-computation disaggregation design and the flexible publication/subscription mechanism, we are proud to announce that we made it happen. In Milvus 2.0, you can delete an entity in a given collection with its primary key so that the deleted entity will no longer be listed in the result of a search or a query.
Please note that the DELETE operation in Milvus refers to logical deletion, whereas physical data cleanup occurs during the Data Compaction. Logical deletion not only greatly boosts the search performance constrained by the I/O speed, but also facilitates data recovery. Logically deleted data can still be retrieved with the help of the Time Travel function.
Usage
Let’s try out the DELETE function in Milvus 2.0 first. (The following example uses PyMilvus 2.0.0 on Milvus 2.0.0).
from pymilvus import connections, utility, Collection, DataType, FieldSchema, CollectionSchema
# Connect to Milvus
connections.connect(
alias="default",
host='x.x.x.x',
port='19530'
)
# Create a collection with Strong Consistency level
pk_field = FieldSchema(
name="id",
dtype=DataType.INT64,
is_primary=True,
)
vector_field = FieldSchema(
name="vector",
dtype=DataType.FLOAT_VECTOR,
dim=2
)
schema = CollectionSchema(
fields=[pk_field, vector_field],
description="Test delete"
)
collection_name = "test_delete"
collection = Collection(
name=collection_name,
schema=schema,
using='default',
shards_num=2,
consistency_level="Strong"
)
# Insert randomly generated vectors
import random
data = [
[i for i in range(100)],
[[random.random() for _ in range(2)] for _ in range(100)],
]
collection.insert(data)
# Query to make sure the entities to delete exist
collection.load()
expr = "id in [2,4,6,8,10]"
pre_del_res = collection.query(
expr,
output_fields = ["id", "vector"]
)
print(pre_del_res)
# Delete the entities with the previous expression
collection.delete(expr)
# Query again to check if the deleted entities exist
post_del_res = collection.query(
expr,
output_fields = ["id", "vector"]
)
print(post_del_res)
Implementation
In a Milvus instance, a data node is mainly responsible for packing streaming data (logs in log broker) as historical data (log snapshots) and automatically flushing them to object storage. A query node executes search requests on full data, i.e. both streaming data and historical data.
To make the most of the data writing capacity of parallel nodes in a cluster, Milvus adopts a sharding strategy based on primary key hashing to distribute writing operations evenly to different worker nodes. That is to say, proxy will route the Data Manipulation Language (DML) messages (i.e. requests) of an entity to the same data node and query node. These messages are published through the DML-Channel and consumed by the data node and query node separately to provide search and query services together.
Data node
Having received data INSERT messages, the data node inserts the data in a growing segment, which is a new segment created to receive streaming data in memory. If either the data row count or the duration of the growing segment reaches the threshold, the data node seals it to prevent any incoming data. The data node then flushes the sealed segment, which contains the historical data, to the object storage. Meanwhile, the data node generates a bloom filter based on the primary keys of the new data, and flushed it to the object storage together with the sealed segment, saving the bloom filter as a part of the statistics binary log (binlog), which contains the statistical information of the segment.
A bloom filter is a probabilistic data structure that consists of a long binary vector and a series of random mapping functions. It can be used to test whether an element is a member of a set, but might return false positive matches. —— Wikipedia
When data DELETE messages come in, data node buffers all bloom filters in the corresponding shard, and matches them with the primary keys provided in the messages to retrieve all segments (from both growing and sealed ones) that possibly include the entities to delete. Having pinpointed the corresponding segments, data node buffers them in memory to generate the Delta binlogs to record the delete operations, and then flushes those binlogs together with the segments back to the object storage.
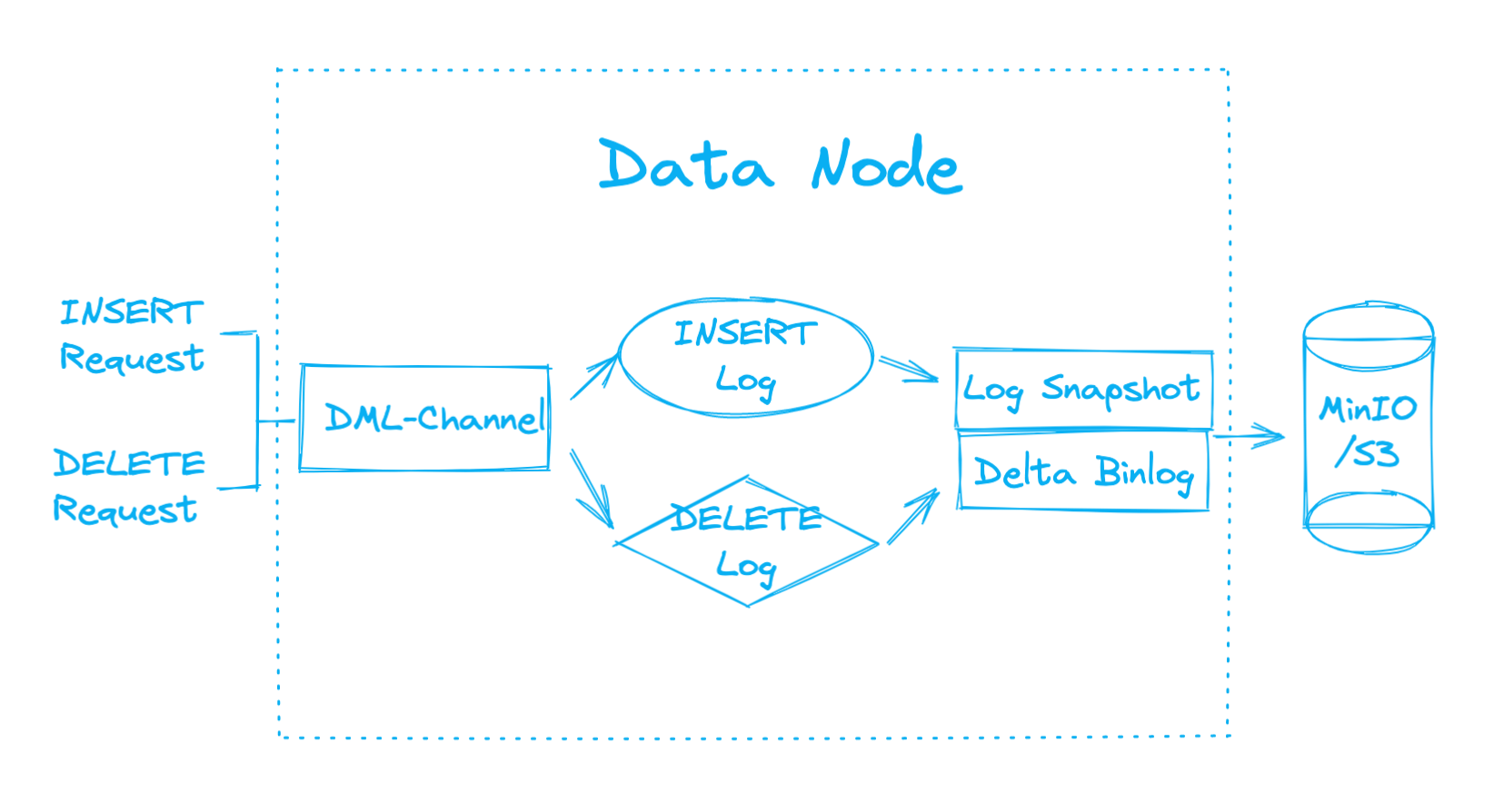 Data Node
Data Node
Since one shard is only assigned with one DML-Channel, extra query nodes added to the cluster will not be able to subscribe to the DML-Channel. To ensure that all query nodes can receive the DELETE messages, data nodes filter the DELETE messages from the DML-Channel, and forward them to Delta-Channel to notify all query nodes of the delete operations.
Query node
When loading a collection from object storage, the query node first obtains each shard’s checkpoint, which marks the DML operations since the last flush operation. Based on the checkpoint, the query node loads all sealed segments together with their Delta binlog and bloom filters. With all data loaded, the query node then subscribes to DML-Channel, Delta-Channel, and Query-Channel.
If more data INSERT messages come after the collection is loaded to memory, query node first pinpoints the growing segments according to the messages, and updates corresponding bloom filters in memory for query purposes only. Those query-dedicated bloom filters will not be flushed to object storage after the query is finished.
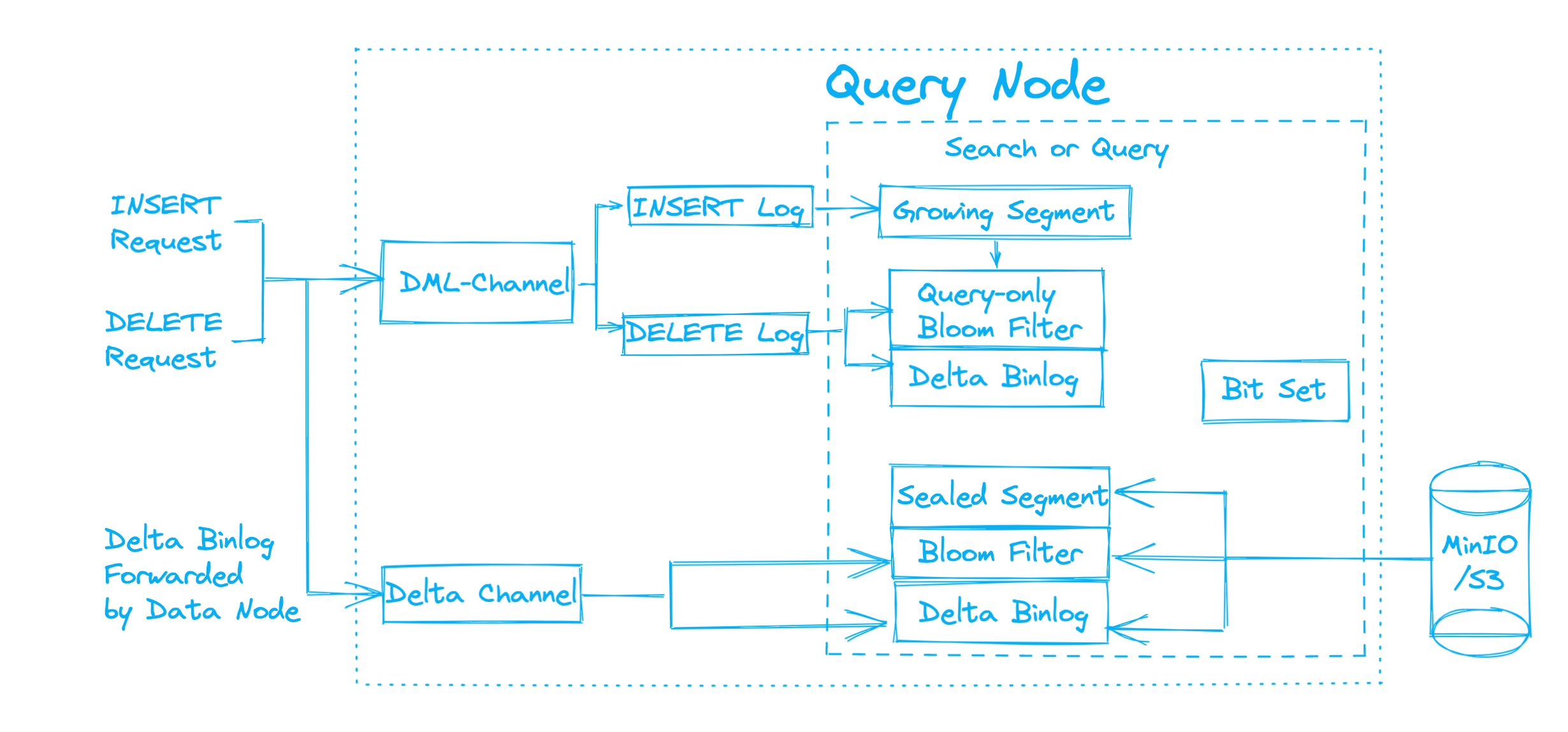 Query Node
Query Node
As mentioned above, only a certain number of query nodes can receive DELETE messages from the DML-Channel, meaning only they can execute the DELETE requests in growing segments. For those query nodes which have subscribed to the DML-Channel, they first filter the DELETE messages in the growing segments, locate the entities by matching the provided primary keys with those query-dedicated bloom filters of the growing segments, and then record the delete operations in the corresponding segments.
Query nodes that cannot subscribe to the DML-Channel are only allowed to process search or query requests on sealed segments because they can only subscribe to the Delta-Channel, and receive the DELETE messages forwarded by data nodes. Having collected all DELETE messages in the sealed segments from Delta-Channel, the query nodes locate the entities by matching the provided primary keys with the bloom filters of the sealed segments, and then record the delete operations in the corresponding segments.
Eventually, in a search or query, the query nodes generate a bitset based on the delete records to omit the deleted entities, and search among the remaining entities from all segments, regardless of the segment status. Last but not least, the consistency level affects the visibility of the deleted data. Under Strong Consistency Level (as shown in the previous code sample), the deleted entities are immediately invisible after deletion. While Bounded Consistency Level is adopted, there will be several seconds of latency before the deleted entities become invisible.
What’s next?
In the 2.0 new feature series blog, we aim to explain the design of the new features. Read more in this blog series!
Try Managed Milvus for Free
Zilliz Cloud is hassle-free, powered by Milvus and 10x faster.
Get StartedLike the article? Spread the word



