How Milvus Balances Query Load across Nodes?
 Binlog Cover Image
Binlog Cover Image
By Xi Ge.
In previous blog articles, we have successively introduced the Deletion, Bitset, and Compaction functions in Milvus 2.0. To culminate this series, we would like to share the design behind Load Balance, a vital function in the distributed cluster of Milvus.
Implementation
Whereas the number and size of segments buffered in query nodes differ, the search performance across the query nodes may also vary. The worst case could happen when a few query nodes are exhausted searching on a large amount of data, but newly created query nodes remain idle because no segment is distributed to them, causing a massive waste of CPU resources and a huge drop in search performance.
To avoid such circumstances, the query coordinator (query coord) is programmed to distribute segments evenly to each query node according to the RAM usage of the nodes. Therefore, CPU resources are consumed equally across the nodes, thereby significantly improving search performance.
Trigger automatic load balance
According to the default value of the configuration queryCoord.balanceIntervalSeconds, the query coord checks the RAM usage (in percentage) of all query nodes every 60 seconds. If either of the following conditions is satisfied, the query coord starts to balance the query load across the query node:
- RAM usage of any query node in the cluster is larger than
queryCoord.overloadedMemoryThresholdPercentage(default: 90); - Or the absolute value of any two query nodes’ RAM usage difference is larger than
queryCoord.memoryUsageMaxDifferencePercentage(default: 30).
After the segments are transferred from the source query node to the destination query node, they should also satisfy both the following conditions:
- RAM usage of the destination query node is no larger than
queryCoord.overloadedMemoryThresholdPercentage(default: 90); - The absolute value of the source and destination query nodes’ RAM usage difference after load balancing is less than that before load balancing.
With the above conditions satisfied, the query coord proceeds to balance the query load across the nodes.
Load balance
When load balance is triggered, the query coord first loads the target segment(s) to the destination query node. Both query nodes return search results from the target segment(s) at any search request at this point to guarantee the completeness of the result.
After the destination query node successfully loads the target segment, the query coord publishes a sealedSegmentChangeInfo to the Query Channel. As shown below, onlineNodeID and onlineSegmentIDs indicate the query node that loads the segment and the segment loaded respectively, and offlineNodeID and offlineSegmentIDs indicate the query node that needs to release the segment and the segment to release respectively.
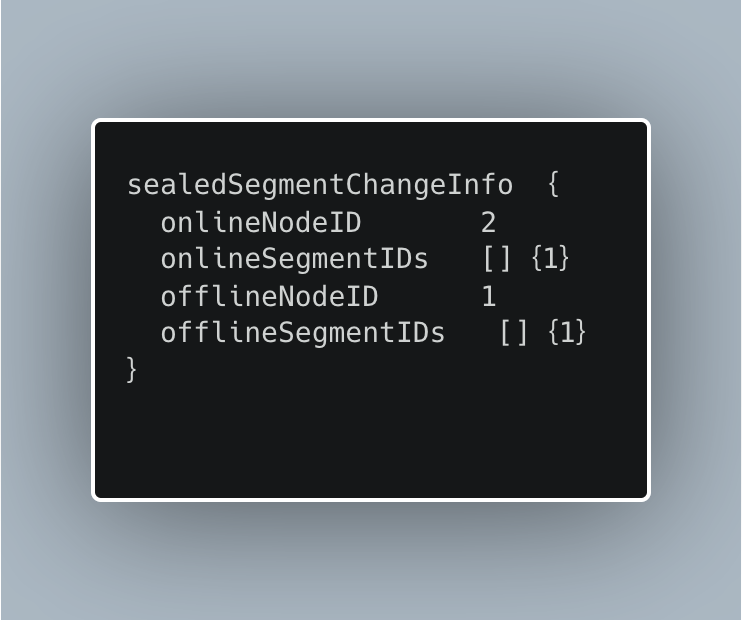 sealedSegmentChangeInfo
sealedSegmentChangeInfo
Having received the sealedSegmentChangeInfo, the source query node then releases the target segment.
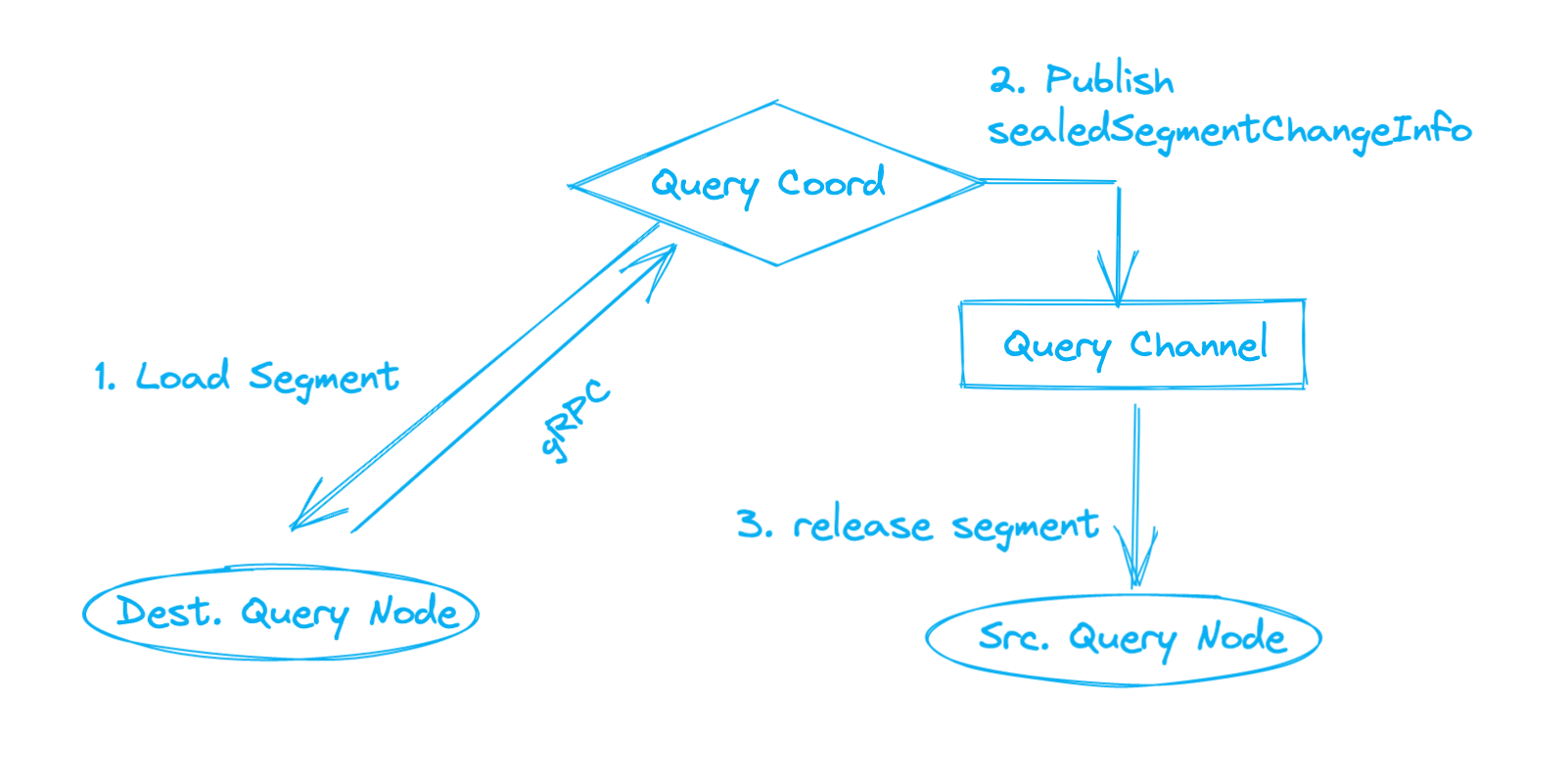 Load Balance Workflow
Load Balance Workflow
The whole process succeeds when the source query node releases the target segment. By completing that, the query load is set balanced across the query nodes, meaning the RAM usage of all query nodes is no larger than queryCoord.overloadedMemoryThresholdPercentage, and the absolute value of the source and destination query nodes’ RAM usage difference after load balancing is less than that before load balancing.
What’s next?
In the 2.0 new feature series blog, we aim to explain the design of the new features. Read more in this blog series!
- How Milvus Deletes Streaming Data in a Distributed Cluster
- How to Compact Data in Milvus?
- How Milvus Balances Query Load across Nodes?
- How Bitset Enables the Versatility of Vector Similarity Search
This is the finale of the Milvus 2.0 new feature blog series. Following this series, we are planning a new series of Milvus Deep Dive, which introduces the basic architecture of Milvus 2.0. Please stay tuned.
- Implementation
- Load balance
- What's next?
On This Page
Try Managed Milvus for Free
Zilliz Cloud is hassle-free, powered by Milvus and 10x faster.
Get StartedLike the article? Spread the word



