Increase Your Vector Database Read Throughput with In-Memory Replicas
 Cover_image
Cover_image
This article is co-authored by Congqi Xia and Angela Ni.
With its official release, Milvus 2.1 comes with many new features to provide convenience and a better user experience. Though the concept of in-memory replica is nothing new to the world of distributed databases, it is a critical feature that can help you boost system performance and enhance system availability in an effortless way. Therefore, this post sets out to explain what in-memory replica is and why it is important, and then introduces how to enable this new feature in Milvus, a vector database for AI.
Jump to:
Concepts related to in-memory replica
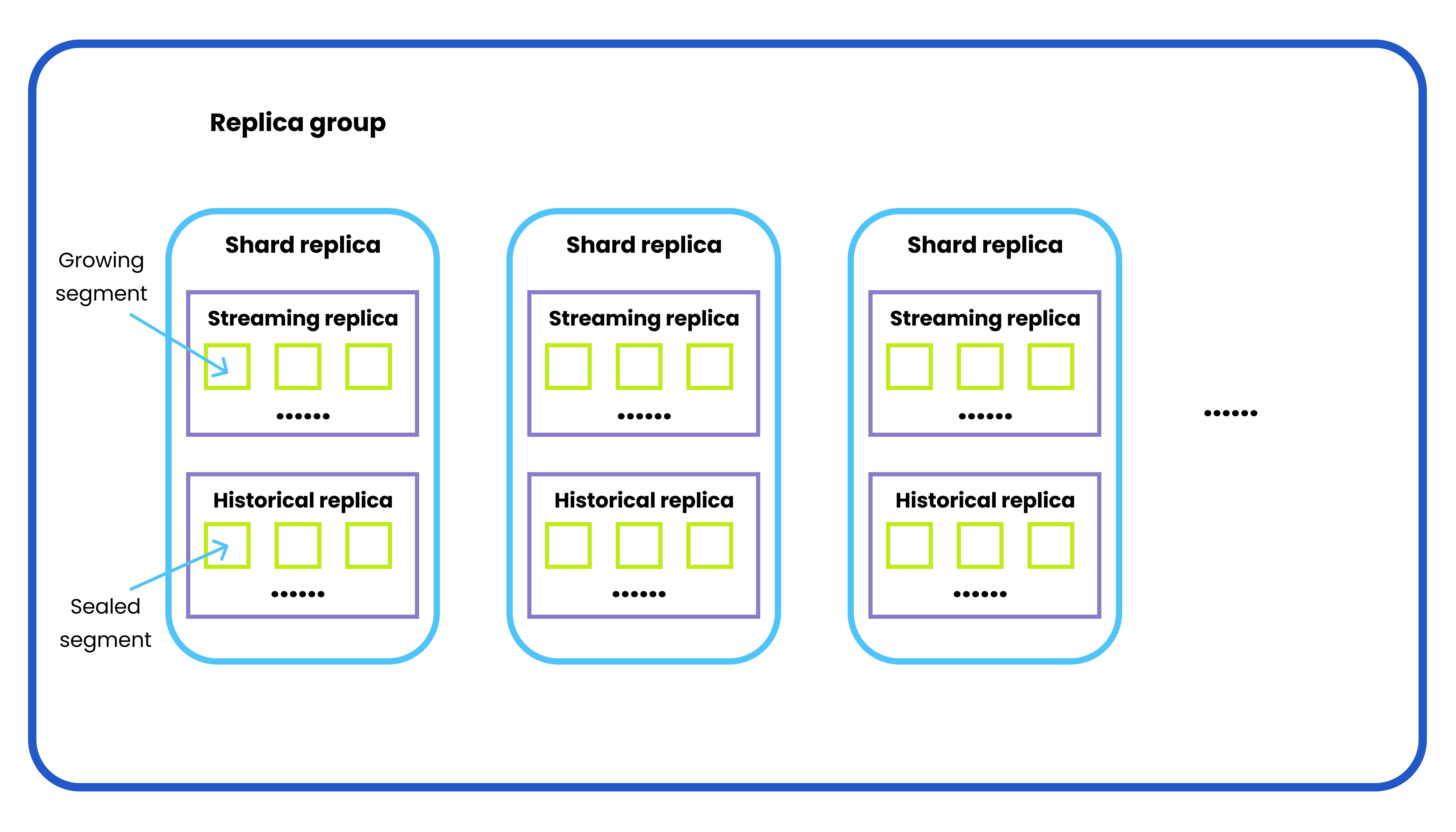
Before getting to know what in-memory replica is and why it is important, we need to first understand a few relevant concepts including replica group, shard replica, streaming replica, historical replica, and shard leader. The image below is an illustration of these concepts.
 Replica_concepts
Replica_concepts
Replica group
A replica group consists of multiple query nodes that are responsible for handling historical data and replicas.
Shard replica
A shard replica consists of a streaming replica and a historical replica, both belonging to the same shard (i.e DML channel). Multiple shard replicas make up a replica group. And the exact number of shard replicas in a replica group is determined by the number of shards in a specified collection.
Streaming replica
A streaming replica contains all the growing segments from the same DML channel. Technically speaking, a streaming replica should be served by only one query node in one replica.
Historical replica
A historical replica contains all the sealed segments from the same DML channel. The sealed segments of one historical replica can be distributed on several query nodes within the same replica group.
Shard leader
A shard leader is the query node serving the streaming replica in a shard replica.
What is in-memory replica?
Enabling in-memory replicas allows you to load data in a collection on multiple query nodes so that you can leverage extra CPU and memory resources. This feature is very useful if you have a relatively small dataset but want to increase read throughput and enhance the utilization of hardware resources.
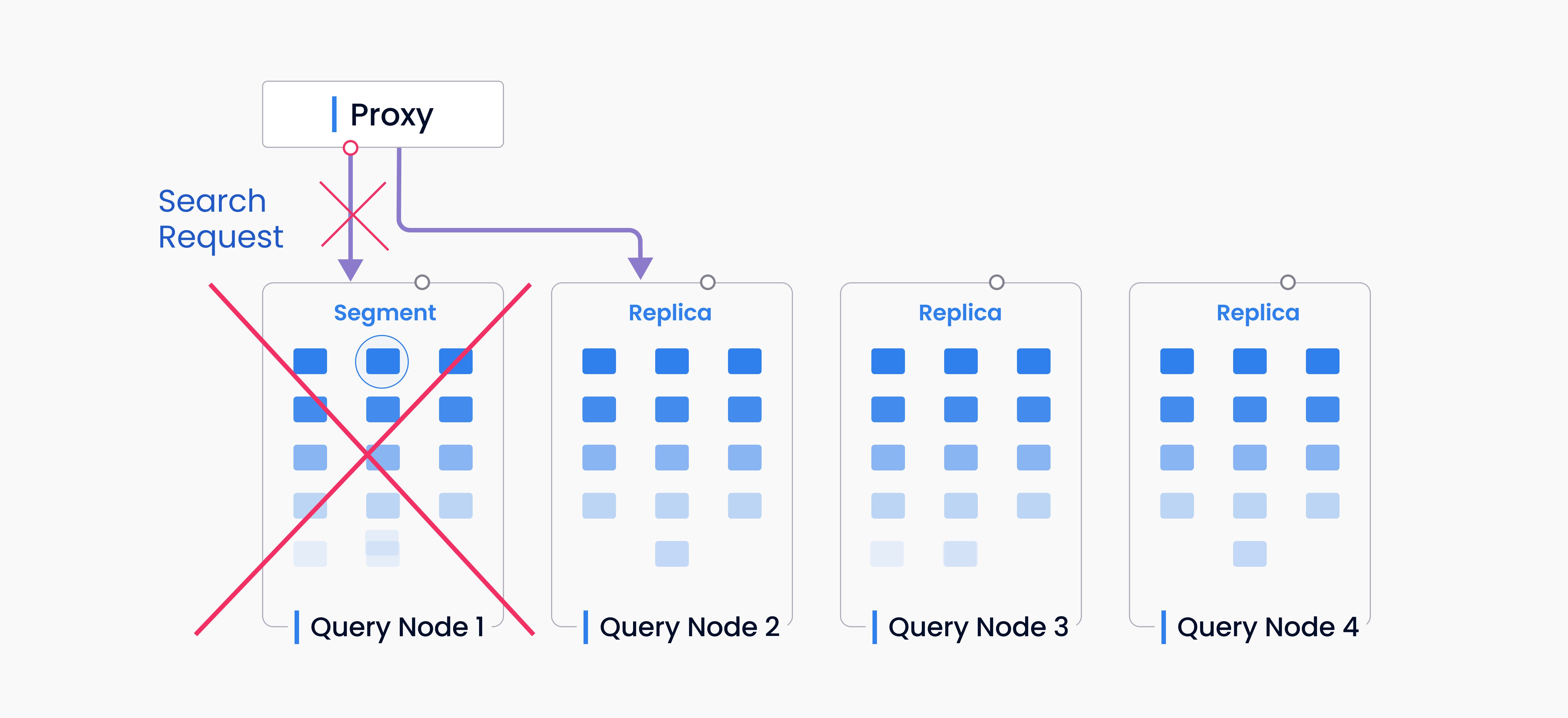
The Milvus vector database holds one replica for each segment in memory for now. However, with in-memory replicas, you can have multiple replications of a segment on different query nodes. This means if one query node is conducting a search on a segment, an incoming new search request can be assigned to another idle query node as this query node has a replication of exactly the same segment.
In addition, if we have multiple in-memory replicas, we can better cope with the situation in which a query node crashes. Before, we have to wait for the segment to be reloaded in order to continue and search on another query node. However, with in-memory replication, the search request can be resent to a new query node immediately without having to reload the data again.
 Replication
Replication
Why are in-memory replicas important?
One of the most significant benefits of enabling in-memory replicas is the increase in overall QPS (query per second) and throughput. Furthermore, multiple segment replicas can be maintained and the system is more resilient in the face of a failover.
Enable in-memory replicas in the Milvus vector database
Enabling the new feature of in-memory replicas is effortless in the Milvus vector database. All you need to do is simply specify the number of replicas you want when loading a collection (ie. calling collection.load()).
In the following example tutorial, we suppose you have already created a collection named “book” and inserted data into it. Then you can run the following command to create two replicas when loading a book collection.
from pymilvus import Collection
collection = Collection("book") # Get an existing collection.
collection.load(replica_number=2) # load collection as 2 replicas
You can flexibly modify the number of replicas in the example code above to best suit your application scenario. Then you can directly conduct a vector similarity search or query on multiple replicas without running any extra commands. However, it should be noted that the maximum number of replicas allowed is limited by the total amount of usable memory to run the query nodes. If the number of replicas you specify exceeds the limitations of usable memory, an error will be returned during data load.
You can also check the information of the in-memory replicas you created by running collection.get_replicas(). The information of replica groups and the corresponding query nodes and shards will be returned. The following is an example of the output.
Replica groups:
- Group: <group_id:435309823872729305>, <group_nodes:(21, 20)>, <shards:[Shard: <channel_name:milvus-zong-rootcoord-dml_27_435367661874184193v0>, <shard_leader:21>, <shard_nodes:[21]>, Shard: <channel_name:milvus-zong-rootcoord-dml_28_435367661874184193v1>, <shard_leader:20>, <shard_nodes:[20, 21]>]>
- Group: <group_id:435309823872729304>, <group_nodes:(25,)>, <shards:[Shard: <channel_name:milvus-zong-rootcoord-dml_28_435367661874184193v1>, <shard_leader:25>, <shard_nodes:[25]>, Shard: <channel_name:milvus-zong-rootcoord-dml_27_435367661874184193v0>, <shard_leader:25>, <shard_nodes:[25]>]>
What’s next
With the official release of Milvus 2.1, we have prepared a series of blogs introducing the new features. Read more in this blog series:
- How to Use String Data to Empower Your Similarity Search Applications
- Using Embedded Milvus to Instantly Install and Run Milvus with Python
- Increase Your Vector Database Read Throughput with In-Memory Replicas
- Understanding Consistency Level in the Milvus Vector Database
- Understanding Consistency Level in the Milvus Vector Database (Part II)
- How Does the Milvus Vector Database Ensure Data Security?
- Concepts related to in-memory replica
- Replica group
- Shard replica
- Streaming replica
- Historical replica
- Shard leader
- What is in-memory replica?
- Why are in-memory replicas important?
- Enable in-memory replicas in the Milvus vector database
- What's next
On This Page
Try Managed Milvus for Free
Zilliz Cloud is hassle-free, powered by Milvus and 10x faster.
Get StartedLike the article? Spread the word



