Bringing Geospatial Filtering and Vector Search Together with Geometry Fields and RTREE in Milvus 2.6
As AI systems are increasingly applied to real-time decision-making, geospatial data becomes increasingly important in a growing set of applications—particularly those that operate in the physical world or serve users across real locations.
Consider food delivery platforms like DoorDash or Uber Eats. When a user places an order, the system isn’t simply calculating the shortest distance between two points. It evaluates restaurant quality, courier availability, live traffic conditions, service areas, and increasingly, user and item embeddings that represent personal preferences. Similarly, autonomous vehicles must perform path planning, obstacle detection, and scene-level semantic understanding under strict latency constraints—often within milliseconds. In these domains, effective decisions depend on combining spatial constraints with semantic similarity, rather than treating them as independent steps.
At the data layer, however, spatial and semantic data have traditionally been handled by separate systems.
Geospatial databases and spatial extensions are designed to store coordinates, polygons, and spatial relationships such as containment or distance.
Vector databases handle vector embeddings that represent the data’s semantic meaning.
When applications need both, they are often forced into multi-stage query pipelines—filtering by location in one system, then performing vector search in another. This separation increases system complexity, adds query latency, and makes it difficult to perform spatial–semantic reasoning efficiently at scale.
Milvus 2.6 addresses this problem by introducing the Geometry Field, which allows vector similarity search to be combined directly with spatial constraints. This enables use cases such as:
Location-Base Service (LBS): “find similar POIs within this city block”
Multi‑modal search: “retrieve similar photos within 1km of this point”
Maps & logistics: “assets inside a region” or “routes intersecting a path”
Paired with the new RTREE index—a tree-based structure optimized for spatial filtering—Milvus now supports efficient geospatial operators like st_contains, st_within, and st_dwithin alongside high-dimensional vector search. Together, they make spatially aware intelligent retrieval not just possible, but practical.
In this post, we’ll walk through how the Geometry Field and RTREE index work, and how they combine with vector similarity search to enable real-world, spatial-semantic applications.
What Is a Geometry Field in Milvus?
A Geometry field is a schema-defined data type (DataType.GEOMETRY) in Milvus used to store geometric data. Unlike systems that handle only raw coordinates, Milvus supports a range of spatial structures—including Point, LineString, and Polygon.
This makes it possible to represent real-world concepts such as restaurant locations (Point), delivery zones (Polygon), or autonomous-vehicle trajectories (LineString), all within the same database that stores semantic vectors. In other words, Milvus becomes a unified system for both where something is and what it means.
Geometry values are stored using the Well-Known Text (WKT) format, a human-readable standard for inserting and querying geometric data. This simplifies data ingestion and querying because WKT strings can be inserted directly into a Milvus record. For example:
data = [
{
"id": 1,
"geo": "POINT(116.4074 39.9042)",
"vector": vector,
}
]
What Is the RTREE Index and How Does It Work?
Once Milvus introduces the Geometry data type, it also needs an efficient way to filter spatial objects. Milvus handles this using a two-stage spatial filtering pipeline:
Coarse filtering: Quickly narrows down candidates using spatial indexes such as RTREE.
Fine filtering: Applies exact geometry checks on the candidates that remain, ensuring correctness at boundaries.
This design balances performance and accuracy. The spatial index aggressively prunes irrelevant data, while precise geometric checks ensure correct results for operators such as containment, intersection, and distance thresholds.
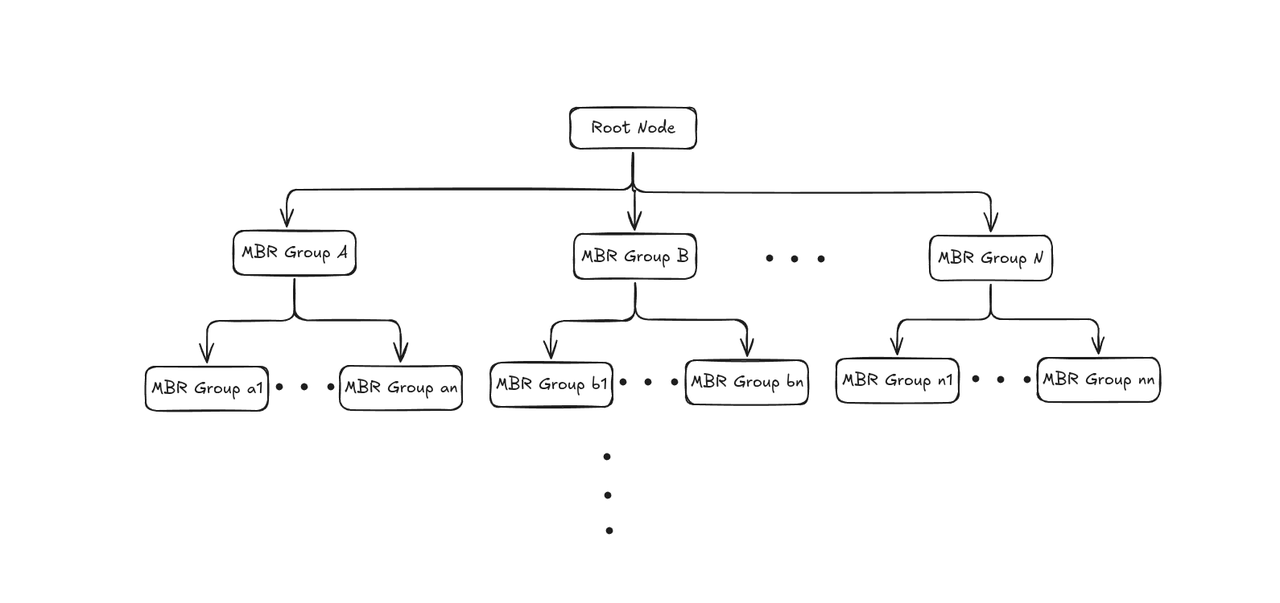
At the core of this pipeline is RTREE (Rectangle Tree), a spatial indexing structure designed to accelerate queries over geometric data. RTREE works by organizing objects hierarchically using Minimum Bounding Rectangles (MBRs), allowing large portions of the search space to be skipped during query execution.
Phase 1: Building the RTREE Index
RTREE construction follows a bottom-up process that groups nearby spatial objects into increasingly larger bounding regions:
1. Create leaf nodes: For each geometry object, calculate its Minimum Bounding Rectangle (MBR)—the smallest rectangle that fully contains the object—and store it as a leaf node.
2. Group into larger boxs: Cluster nearby leaf nodes and wrap each group inside a new MBR, producing internal nodes.
3. Add the root node: Create a root node whose MBR covers all internal groups, forming a height-balanced tree structure.
Phase 2: Accelerate queries
1. Form the query MBR: Calculate the MBR for the geometry used in your query.
2. Prune branches: Starting from the root, compare the query MBR with each internal node. Skip any branch whose MBR does not intersect with the query MBR.
3. Collect candidates: Descend into intersecting branches and gather the candidate leaf nodes.
4. Perform exact matching: For each candidate, run the spatial predicate to get precise results.
Why RTREE Is Fast
RTREE delivers strong performance in spatial filtering because of several key design features:
Every node stores an MBR: Each node approximates the area of all geometries in its subtree. This makes it easy to decide whether a branch should be explored during a query.
Fast pruning: Only subtrees whose MBR intersects the query region are explored. Irrelevant areas are ignored entirely.
Scales with data size: RTREE supports spatial searches in O(log N) time, enabling fast queries even as the dataset expands.
Boost.Geometry implementation: Milvus builds its RTREE index using Boost.Geometry, a widely used C++ library that provides optimized geometry algorithms and a thread-safe RTREE implementation suitable for concurrent workloads.
Supported geometry operators
Milvus provides a set of spatial operators that allow you to filter and retrieve entities based on geometric relationships. These operators are essential for workloads that need to understand how objects relate to one another in space.
The following table lists the geometry operators currently available in Milvus.
| Operator | Description |
|---|---|
| st_intersects(A, B) | Returns TRUE if geometries A and B share at least one common point. |
| st_contains(A, B) | Returns TRUE if geometry A completely contains geometry B (excluding the boundary). |
| st_within(A, B) | Returns TRUE if geometry A is completely contained within geometry B. This is the inverse of st_contains(A, B). |
| st_covers(A, B) | Returns TRUE if geometry A covers geometry B (including the boundary). |
| st_touches(A, B) | Returns TRUE if geometries A and B touch at their boundaries but do not intersect internally. |
| st_equals(A, B) | Returns TRUE if geometries A and B are spatially identical. |
| st_overlaps(A, B) | Returns TRUE if geometries A and B partially overlap and neither fully contains the other. |
| st_dwithin(A, B, d) | Returns TRUE if the distance between A and B is less than d. |
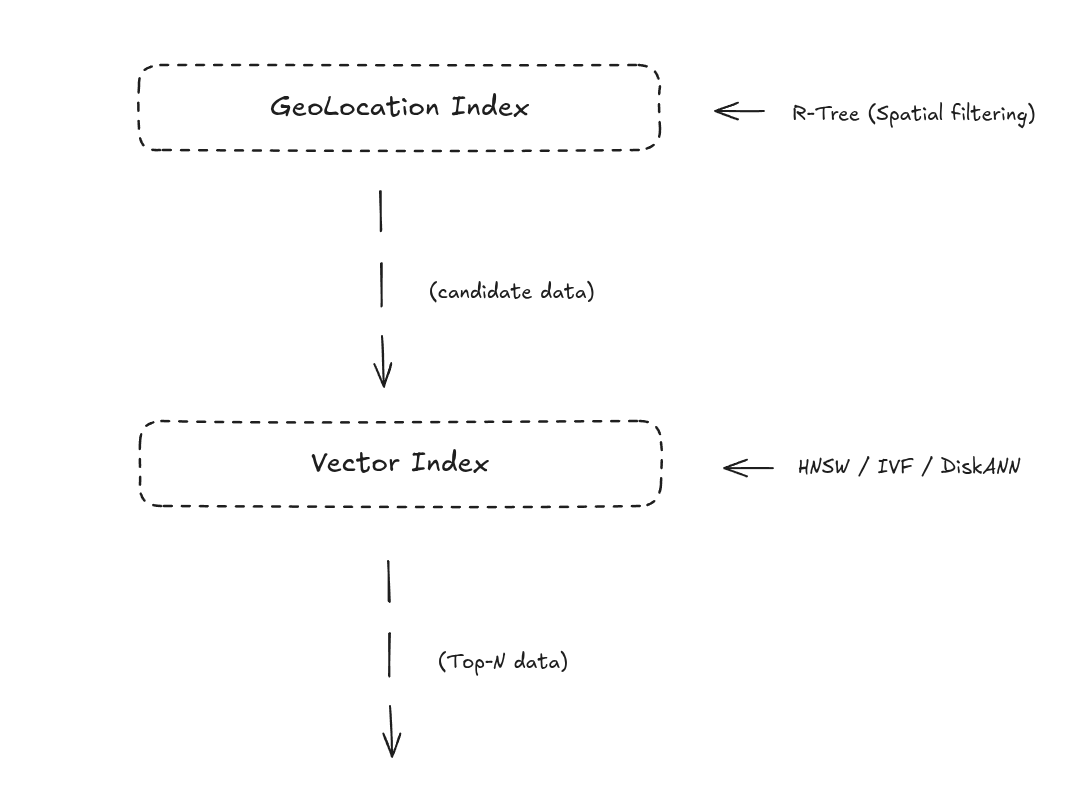
How to Combine Geolocation Index and Vector Index
With Geometry support and the RTREE index, Milvus can combine geospatial filtering with vector similarity search in a single workflow. The process works in two steps:
1. Filter by location using RTREE: Milvus first uses the RTREE index to narrow the search to entities within the specified geographic range (e.g., “within 2 km”).
2. Rank by semantics using vector search: From the remaining candidates, the vector index selects the Top-N most similar results based on embedding similarity.
Real-World Use Cases of Geo-Vector Retrieval
1. Delivery Services: Smarter, Location-Aware Recommendations
Platforms such as DoorDash or Uber Eats handle hundreds of millions of requests each day. The moment a user opens the app, the system must determine—based on the user’s location, time of day, taste preferences, estimated delivery times, real-time traffic, and courier availability—which restaurants or couriers are the best match right now.
Traditionally, this requires querying a geospatial database and a separate recommendation engine, followed by multiple rounds of filtering and re-ranking. With the Geolocation Index, Milvus greatly simplifies this workflow:
Unified storage — Restaurant coordinates, courier locations, and user preference embeddings all live in one system.
Joint retrieval — First apply a spatial filter (e.g., restaurants within 3 km), then use vector search to rank by similarity, taste preference, or quality.
Dynamic decision-making — Combine real-time courier distribution and traffic signals to quickly assign the nearest, most suitable courier.
This unified approach allows the platform to perform spatial and semantic reasoning in a single query. For example, when a user searches “curry rice,” Milvus retrieves restaurants that are semantically relevant and prioritizes those that are nearby, deliver quickly, and match the user’s historical taste profile.
2. Autonomous Driving: More Intelligent Decisions
In autonomous driving, geospatial indexing is fundamental to perception, localization, and decision-making. Vehicles must continuously align themselves to high-definition maps, detect obstacles, and plan safe trajectories—all within just a few milliseconds.
With Milvus, the Geometry type and RTREE index can store and query rich spatial structures such as:
Road boundaries (LineString)
Traffic regulation zones (Polygon)
Detected obstacles (Point)
These structures can be indexed efficiently, allowing geospatial data to take part directly in the AI decision loop. For example, an autonomous vehicle can quickly determine whether its current coordinates fall within a specific lane or intersect with a restricted area, simply through an RTREE spatial predicate.
When combined with vector embeddings generated by the perception system—such as scene embeddings that capture the current driving environment—Milvus can support more advanced queries, like retrieving historical driving scenarios similar to the current one within a 50-meter radius. This helps models interpret the environment faster and make better decisions.
Conclusion
Geolocation is more than latitude and longitude. In location-sensitive applications, it provides essential context about where events occur, how entities relate spatially, and how those relationships shape system behavior. When combined with semantic signals from machine learning models, geospatial data enables a richer class of queries that are difficult to express—or inefficient to execute—when spatial and vector data are handled separately.
With the introduction of the Geometry Field and the RTREE index, Milvus brings vector similarity search and spatial filtering into a single query engine. This allows applications to perform joint retrieval across vectors, geospatial data, and time, supporting use cases such as spatially aware recommendation systems, multimodal location-based search, and region- or path-constrained analytics. More importantly, it reduces architectural complexity by eliminating multi-stage pipelines that move data between specialized systems.
As AI systems continue to move closer to real-world decision-making, understanding what content is relevant will increasingly need to be paired with where it applies and when it matters. Milvus provides the building blocks for this class of spatial-semantic workloads in a way that is both expressive and practical for operating at scale.
For more information about the Geometry Field and the RTREE index, check the documentation below:
Have questions or want a deep dive on any feature of the latest Milvus? Join our Discord channel or file issues on GitHub. You can also book a 20-minute one-on-one session to get insights, guidance, and answers to your questions through Milvus Office Hours.
Learn More about Milvus 2.6 Features
Introducing Milvus 2.6: Affordable Vector Search at Billion Scale
Introducing the Embedding Function: How Milvus 2.6 Streamlines Vectorization and Semantic Search
JSON Shredding in Milvus: 88.9x Faster JSON Filtering with Flexibility
Unlocking True Entity-Level Retrieval: New Array-of-Structs and MAX_SIM Capabilities in Milvus
MinHash LSH in Milvus: The Secret Weapon for Fighting Duplicates in LLM Training Data
Bring Vector Compression to the Extreme: How Milvus Serves 3× More Queries with RaBitQ
Vector Search in the Real World: How to Filter Efficiently Without Killing Recall
- What Is a Geometry Field in Milvus?
- What Is the RTREE Index and How Does It Work?
- Phase 1: Building the RTREE Index
- Why RTREE Is Fast
- Supported geometry operators
- How to Combine Geolocation Index and Vector Index
- Real-World Use Cases of Geo-Vector Retrieval
- 1. Delivery Services: Smarter, Location-Aware Recommendations
- 2. Autonomous Driving: More Intelligent Decisions
- Conclusion
- Learn More about Milvus 2.6 Features
On This Page
Try Managed Milvus for Free
Zilliz Cloud is hassle-free, powered by Milvus and 10x faster.
Get StartedLike the article? Spread the word



