Introducing Milvus 2.6: Affordable Vector Search at Billion Scale
As AI-powered search has evolved from experimental projects to mission-critical infrastructure, the demands on vector databases have intensified. Organizations need to handle billions of vectors while managing infrastructure costs, supporting real-time data ingestion, and providing sophisticated retrieval beyond basic similarity search. To tackle these evolving challenges, we’ve been hard at work developing and refining Milvus. The community response has been incredibly encouraging, with valuable feedback helping shape our direction.
After months of intensive development, we’re excited to announce that Milvus 2.6 is now available. This release directly addresses the most pressing challenges in vector search today: scaling efficiently while keeping costs under control.
Milvus 2.6 delivers breakthrough innovations across three critical areas: cost reduction, advanced search capabilities, and architectural improvements for massive scale. The results speak for themselves:
72% memory reduction with RaBitQ 1-bit quantization while delivering 4x faster queries
50% cost savings through intelligent tiered storage
4x faster full-text search than Elasticsearch with our enhanced BM25 implementation
100x faster JSON filtering with the newly introduced Path Index
Search freshness is achieved economically with the new zero-disk architecture
Streamlined embedding workflow with the new “data in and data out” experience
Up to 100K collections in a single cluster for future-proof multi-tenancy
Innovations for Cost Reduction: Making Vector Search Affordable
Memory consumption presents one of the biggest challenges when scaling vector search to billions of records. Milvus 2.6 introduces several key optimizations that significantly reduce your infrastructure costs while also improving performance.
RaBitQ 1-bit Quantization: 72% Memory Reduction with 4× Performance
Traditional quantization methods force you to trade in search quality for memory savings. Milvus 2.6 changes this with RaBitQ 1-bit quantization combined with an intelligent refinement mechanism.
The new IVF_RABITQ index compresses the main index to 1/32 of its original size through 1-bit quantization. When used together with an optional SQ8 refinement, this approach maintains high search quality (95% recall) using only 1/4 of the original memory footprint.
Our preliminary benchmarks reveal promising results:
| Performance Metric | Traditional IVF_FLAT | RaBitQ (1-bit) Only | RaBitQ (1-bit) + SQ8 Refine |
|---|---|---|---|
| Memory Footprint | 100% (baseline) | 3% (97% reduction) | 28% (72% reduction) |
| Recall | 95.2% | 76.3% | 94.9% |
| Search Throughput (QPS) | 236 | 648 (2.7× faster) | 946 (4× faster) |
Table: VectorDBBench evaluation with 1M vectors of 768 dimensions, tested on AWS m6id.2xlarge
The real breakthrough here isn’t just the 72% memory reduction, but achieving this while simultaneously delivering a 4× throughput improvement. This means you can serve the same workload with 75% fewer servers or handle 4× more traffic on your existing infrastructure, all without sacrificing the recall.
For enterprise users utilizing fully managed Milvus on Zilliz Cloud, we’re developing an automated strategy that dynamically adjusts RaBitQ parameters based on your specific workload characteristics and precision requirements. You will simply enjoy greater cost-effectiveness across all Zilliz Cloud CU types.
Hot-Cold Tiered Storage: 50% Cost Reduction Through Intelligent Data Placement
Real-world vector search workloads contain data with vastly different access patterns. Frequently accessed data needs instant availability, while archival data can tolerate slightly higher latency in exchange for dramatically lower storage costs.
Milvus 2.6 introduces a tiered storage architecture that automatically classifies data based on access patterns and places it in appropriate storage tiers:
Intelligent data classification: Milvus automatically identifies hot (frequently accessed) and cold (rarely accessed) data segments based on access patterns
Optimized storage placement: Hot data remains in high-performance memory/SSD, while cold data moves to more economical object storage
Dynamic data movement: As usage patterns change, data automatically migrates between tiers
Transparent retrieval: When queries touch cold data, it’s automatically loaded on demand
The result is up to 50% reduction in storage costs while maintaining query performance for active data.
Additional Cost Optimizations
Milvus 2.6 also introduces Int8 vector support for HNSW indexes, Storage v2 format for optimized structure that reduces IOPS and memory requirements, and easier installation directly through APT/YUM package managers.
Advanced Search Capabilities: Beyond Basic Vector Similarity
Vector search alone isn’t enough for modern AI applications. Users demand the precision of traditional information retrieval combined with the semantic understanding of vector embeddings. Milvus 2.6 introduces a suite of advanced search features that bridge this gap.
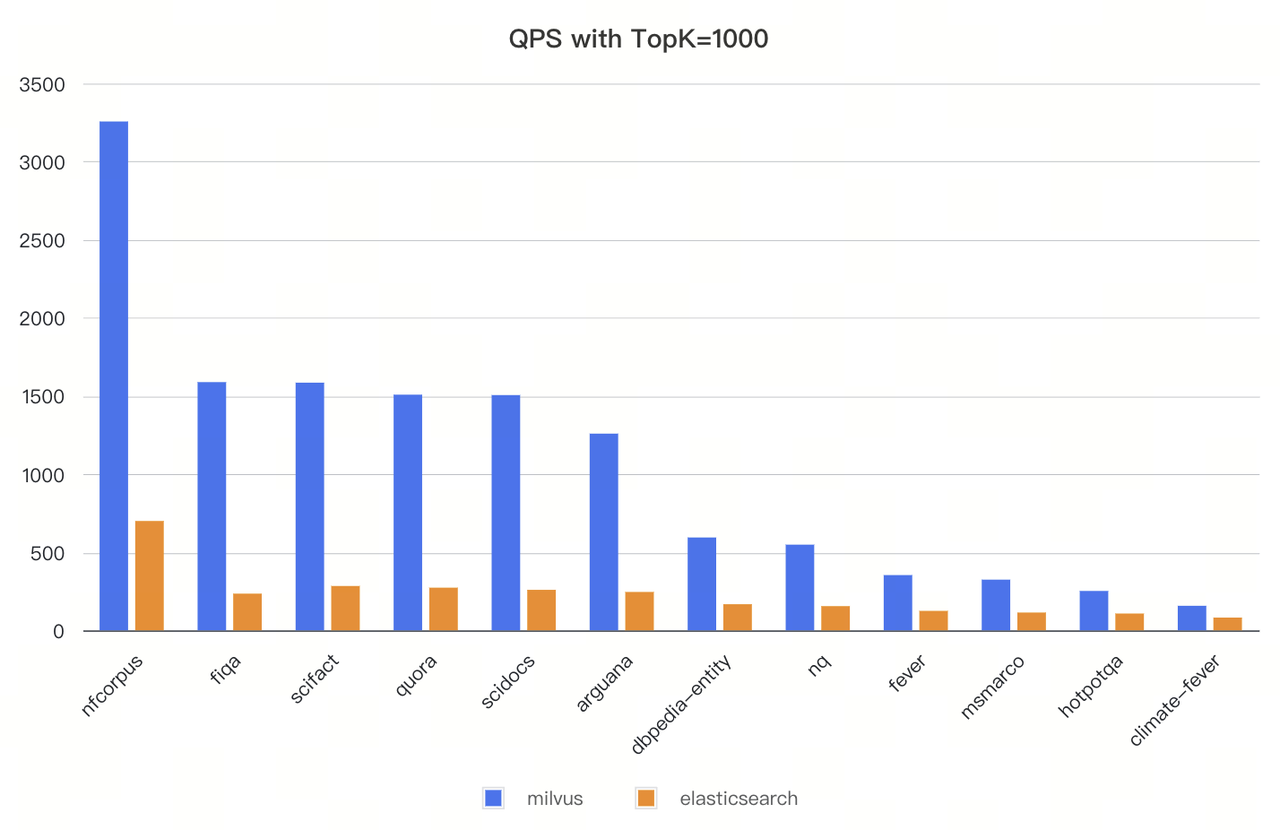
Turbocharged BM25: 400% Faster Full-Text Search Than Elasticsearch
Full-text search has become essential for building hybrid retrieval systems in vector databases. In Milvus 2.6, significant performance improvements have been made to full-text search, building on the BM25 implementation introduced since version 2.5. For example, this release introduces new parameters like drop_ratio_search and dim_max_score_ratio, enhancing precision and speed tuning and offering more fine-grained search controls.
Our benchmarks against the industry-standard BEIR dataset show Milvus 2.6 achieving 3-4× higher throughput than Elasticsearch with equivalent recall rates. For specific workloads, the improvement reaches 7× higher QPS.
JSON Path Index: 100x Faster Filtering
Milvus has supported JSON data type for a long time, but filtering on JSON fields was slow due to the lack of index support. Milvus 2.6 adds support for JSON path index to boost the performance significantly.
Consider a user profile database where each record contains nested metadata like:
{
"user": {
"location": {
"city": "San Francisco",
"country": "USA"
},
"interests": ["AI", "Databases", "Cloud Computing"]
},
"subscription": {
"plan": "enterprise",
"status": "active"
}
}
For a semantic search “users interested in AI” scoped to only San Francisco, Milvus used to parse and evaluate the entire JSON object for every record, making the query very expensive and slow.
Now, Milvus allows you to create indexes on specific paths within JSON fields to speed up the search:
index_params.add_index(
field_name="metadata",
index_type="INVERTED",
index_name="json_index",
params={
"json_path": "metadata[\"user\"][\"location\"][\"city\"]",
"json_cast_type": "varchar"
}
In our performance testing with 100M+ records, JSON Path Index reduced filter latency from 140ms (P99: 480ms) to just 1.5ms (P99: 10ms)—a 99% latency reduction that makes such searches practical in production.
This feature is particularly valuable for:
Recommendation systems with complex user attribute filtering
RAG applications that filter documents by metadata
Multi-tenant systems where data segmentation is critical
Enhanced Text Processing and Time-Aware Search
Milvus 2.6 introduces a completely revamped text analysis pipeline with sophisticated language handling, including the Lindera tokenizer for Japanese and Korean, the ICU tokenizer for comprehensive multilingual support, and enhanced Jieba with custom dictionary integration.
Phrase Match Intelligence captures semantic nuance in word order, distinguishing between “machine learning techniques” and "learning machine techniques":
PHRASE_MATCH(document_text, "artificial intelligence research", slop=1)
Time-Aware Decay Functions automatically prioritize fresh content by adjusting relevance scores based on document age, with configurable decay rates and function types (exponential, Gaussian, or linear).
Streamlined Search: Data in, Data Out Experience
The disconnect between raw data and vector embeddings is another pain point for developers using vector databases. Before data reaches Milvus for indexing and vector search, it often undergoes preprocessing using external models that convert raw text, images, or audio into vector representations. After retrieval, additional downstream processing is also required, such as mapping result IDs back to the original content.
Milvus 2.6 simplifies these embedding workflows with the new Function interface that integrates third-party embedding models directly into your search pipeline. Instead of pre-computing embeddings, you can now:
Insert raw data directly: Submit text, images, or other content to Milvus
Configure embedding providers: Connect to embedding API services from OpenAI, AWS Bedrock, Google Vertex AI, Hugging Face, and more.
Query using natural language: Search using raw text queries directly
This creates a “Data-In, Data-Out” experience where Milvus streamlines all the behind-the-scenes vector transformations for you.
Architectural Evolution: Scaling to Tens of Billions of Vectors
Milvus 2.6 introduces fundamental architectural innovations that enable cost-effective scaling to tens of billions of vectors.
Replacing Kafka and Pulsar with a New Woodpecker WAL
Previous Milvus deployments relied on external message queues, such as Kafka or Pulsar, as the Write-Ahead Log (WAL) system. While these systems initially worked well, they introduced significant operational complexity and resource overhead.
Milvus 2.6 introduces Woodpecker, a purpose-built, cloud-native WAL system that eliminates these external dependencies through a revolutionary zero-disk design:
Everything on object storage: All log data is persisted in object storage like S3, Google Cloud Storage, or MinIO
Distributed metadata: Metadata is still managed by the etcd key-value store
No local disk dependencies: A choice to eliminate complex architecture and operational overhead involved in distributed local permanent state.
We ran comprehensive benchmarks comparing Woodpecker’s performance:
| System | Kafka | Pulsar | WP MinIO | WP Local | WP S3 |
|---|---|---|---|---|---|
| Throughput | 129.96 MB/s | 107 MB/s | 71 MB/s | 450 MB/s | 750 MB/s |
| Latency | 58 ms | 35 ms | 184 ms | 1.8 ms | 166 ms |
Woodpecker consistently reaches 60-80% of the theoretical maximum throughput for each storage backend, with local file system mode achieving 450 MB/s—3.5× faster than Kafka—and S3 mode reaching 750 MB/s, 5.8× higher than Kafka.
For more details about Woodpecker, check out this blog: We Replaced Kafka/Pulsar with a Woodpecker for Milvus.
Search Freshness Achieved Economically
Mission-critical search usually requires newly ingested data to be instantly searchable. Milvus 2.6 replaces message queue dependency to fundamentally improve the handling of fresh updates and provide search freshness at lower resource overhead. The new architecture adds the new Streaming Node, a dedicated component that works in close coordination with other Milvus components like the Query Node and Data Node. Streaming Node is built on top of Woodpecker, our lightweight, cloud-native Write-Ahead Log (WAL) system.
This new component enables:
Great compatibility: Works with both the new Woodpecker WAL and is backward compatible with Kafka, Pulsar, and other streaming platforms
Incremental indexing: New data becomes searchable immediately, without batch delays
Continuous query serving: Simultaneous high-throughput ingestion and low-latency querying
By isolating streaming from batch processing, the Streaming Node helps Milvus maintain stable performance and search freshness even during high-volume data ingestion. It’s designed with horizontal scalability in mind, dynamically scaling node capacity based on data throughput.
Enhanced Multi-tenancy Capability: Scaling to 100k Collections Per Cluster
Enterprise deployments often require tenant-level isolation. Milvus 2.6 dramatically increases the multi-tenancy support by allowing up to 100,000 collections per cluster. This is a crucial improvement for organizations running a monolithic large cluster serving many tenants.
This improvement is made possible by numerous engineering optimizations on metadata management, resource allocation, and query planning. Milvus users can now enjoy stable performance even with tens of thousands of collections.
Other Improvements
Milvus 2.6 offers more architectural enhancements, such as CDC + BulkInsert for simplified data replication across geographic regions and Coord Merge for better cluster coordination in large-scale deployments.
Getting Started with Milvus 2.6
Milvus 2.6 represents a massive engineering effort with dozens of new features and performance optimizations, developed collaboratively by Zilliz engineers and our amazing community contributors. While we’ve covered the headline features here, there’s more to discover. We highly recommend diving into our comprehensive release notes to explore everything this release has to offer!
Complete documentation, migration guides, and tutorials are available on the Milvus website. For questions and community support, join our Discord channel or file issues on GitHub.
- Innovations for Cost Reduction: Making Vector Search Affordable
- RaBitQ 1-bit Quantization: 72% Memory Reduction with 4× Performance
- Hot-Cold Tiered Storage: 50% Cost Reduction Through Intelligent Data Placement
- Additional Cost Optimizations
- Advanced Search Capabilities: Beyond Basic Vector Similarity
- Turbocharged BM25: 400% Faster Full-Text Search Than Elasticsearch
- JSON Path Index: 100x Faster Filtering
- Enhanced Text Processing and Time-Aware Search
- Streamlined Search: Data in, Data Out Experience
- Architectural Evolution: Scaling to Tens of Billions of Vectors
- Replacing Kafka and Pulsar with a New Woodpecker WAL
- Search Freshness Achieved Economically
- Enhanced Multi-tenancy Capability: Scaling to 100k Collections Per Cluster
- Other Improvements
- Getting Started with Milvus 2.6
On This Page
Try Managed Milvus for Free
Zilliz Cloud is hassle-free, powered by Milvus and 10x faster.
Get StartedLike the article? Spread the word



