Vector Search in the Real World: How to Filter Efficiently Without Killing Recall
Many people think vector search is simply about implementing an ANN (Approximate Nearest Neighbor) algorithm and calling it a day. But if you run vector search in production, you know the truth: it gets complicated fast.
Imagine you’re building a product search engine. A user might ask, “Show me shoes similar to this photo, but only in red and under $100.” Serving this query requires applying a metadata filter to the semantic similarity search results. Sounds as simple as applying a filter after your vector search returns? Well, not quite.
What happens when your filtering condition is highly selective? You might not return enough results. And simply increasing the vector search’s topK parameter may quickly degrade performance and consume significantly more resources to handle the same search volume.

Under the hood, efficient metadata filtering is pretty challenging. Your vector database needs to scan the graph index, apply metadata filters, and still respond within a tight latency budget, say, 20 milliseconds. Serving thousands of such queries per second without going bankrupt requires thoughtful engineering and careful optimization.
This blog explores popular filtering techniques in vector search, along with the innovative optimizations we built into the Milvus vector database and its fully managed cloud service (Zilliz Cloud). We’ll also share a benchmark test demonstrating how much more performance the fully-managed Milvus can achieve with a $1000 cloud budget over the other vector databases.
Graph Index Optimization
Vector databases need efficient indexing methods to handle large datasets. Without indexes, a database must compare your query against every vector in the dataset (brute-force scanning), which becomes extremely slow as your data grows.
Milvus supports various index types to solve this performance challenge. The most popular ones are graph-based index types: HNSW (runs entirely in memory) and DiskANN (efficiently uses both memory and SSD). These indexes organize vectors into a network structure where neighborhoods of vectors are connected on a map, allowing searches to quickly navigate to relevant results while checking only a small fraction of all vectors. Zilliz Cloud, the fully-managed Milvus service, takes one step further by introducing Cardinal, an advanced proprietary vector search engine, further enhancing these indexes for even better performance.
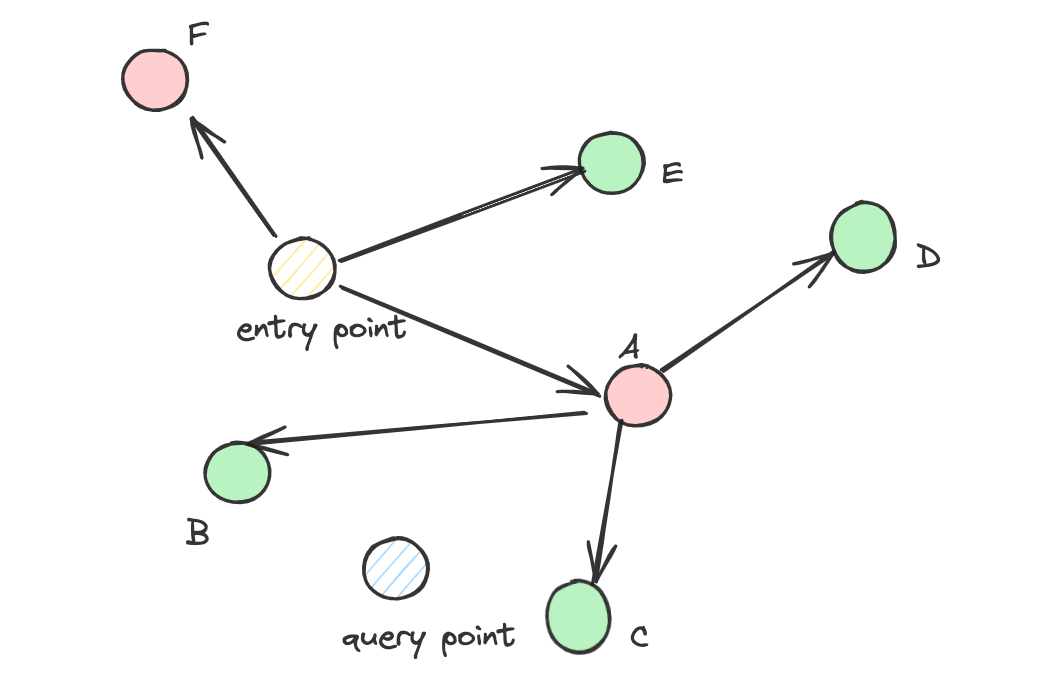
However, when we add filtering requirements (like “only show products less than $100”), a new problem emerges. The standard approach is creating a bitset - a list marking which vectors meet the filter criteria. During search, the system only considers vectors marked as valid in this bitset. This approach seems logical, but it creates a serious problem: broken connectivity. When many vectors get filtered out, the carefully constructed paths in our graph index get disrupted.
Here’s a simple example of the problem: In the diagram below, Point A connects to B, C and D, but B, C, and D don’t directly connect to each other. If our filter removes point A (perhaps it’s too expensive), then even if B, C, and D are relevant to our search, the path between them is broken. This creates “islands” of disconnected vectors that become unreachable during search, hurting the quality of results (recall).
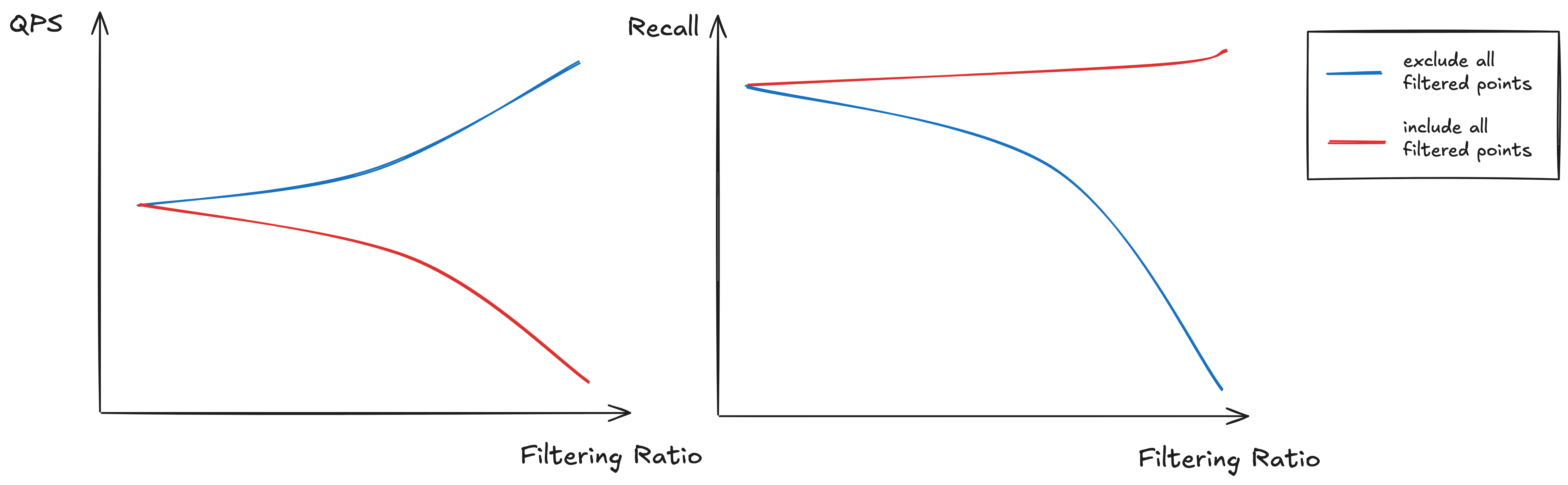
There are two common approaches to filtering during graph traversal: exclude all filtered-out points upfront, or include everything and apply the filter afterward. As illustrated in the diagram below, neither approach is ideal. Skipping filtered points entirely can cause recall to collapse as the filtering ratio nears 1 (blue line), while visiting every point regardless of its metadata bloats the search space and slows down performance significantly (red line).
Researchers have proposed several approaches to strike a balance between recall and performance:
- Alpha Strategy: This introduces a probabilistic approach: even though a vector doesn’t match the filter, we might still visit it during search with some probability. This probability (alpha) depends on the filtering ratio - how strict the filter is. This helps maintain essential connections in the graph without visiting too many irrelevant vectors.
- ACORN Method [1]: In standard HNSW, edge pruning is used during index construction to create a sparse graph and speed up search. The ACORN method deliberately skips this pruning step to retain more edges and strengthen connectivity—crucial when filters might exclude many nodes. In some cases, ACORN also expands each node’s neighbor list by gathering additional approximate nearest neighbors, further reinforcing the graph. Moreover, its traversal algorithm looks two steps ahead (i.e., examines neighbors of neighbors), improving the chances of finding valid paths even under high filtering ratios.
- Dynamically Selected Neighbors: A method improves over Alpha Strategy. Instead of relying on probabilistic skipping, this approach adaptively selects the next nodes during search. It offers more control than Alpha Strategy.
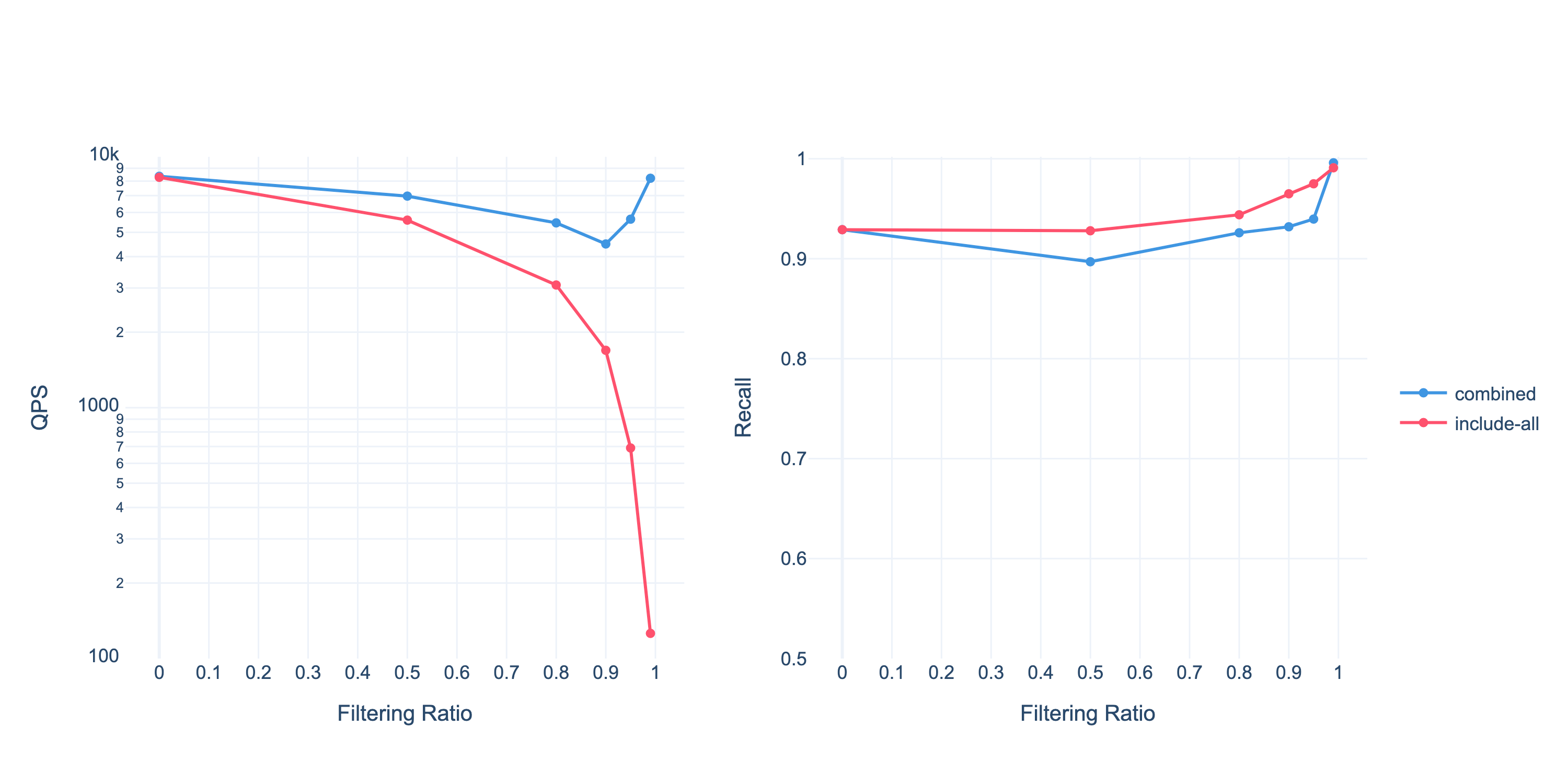
In Milvus, we implemented the Alpha strategy alongside other optimization techniques. For example, it dynamically switches strategies when detecting extremely selective filters: when, say, approximately 99% of the data doesn’t match the filtering expression, the “include-all” strategy would cause graph traversal paths to lengthen significantly, resulting in performance degradation and isolated “islands” of data. In such cases, Milvus automatically falls back to a brute-force scan, bypassing the graph index entirely for better efficiency. In Cardinal, the vector search engine powering fully-managed Milvus (Zilliz Cloud), we’ve taken this further by implementing a dynamic combination of “include-all” and “exclude-all” traversal methods that intelligently adapts based on data statistics to optimize query performance.
Our experiments on the Cohere 1M dataset (dimension = 768) using an AWS r7gd.4xlarge instance demonstrate the effectiveness of this approach. In the chart below, the blue line represents our dynamic combination strategy, while the red line illustrates the baseline approach that traverses all filtered points in the graph.
Metadata-Aware Indexing
Another challenge comes from how metadata and vector embeddings relate to each other. In most applications, an item’s metadata properties (e.g., a product’s price) have minimal connection to what the vector actually represents (the semantic meaning or visual features). For example, a 90 belt share the same price point but exhibit completely different visual characteristics. This disconnect makes combining filtering with vector search inherently inefficient.
To solve this problem, we’ve developed metadata-aware vector indexes. Instead of having just one graph for all vectors, it builds specialized “subgraphs” for different metadata values. For example, if your data has fields for “color” and “shape,” it creates separate graph structures for these fields.
When you search with a filter like “color = blue,” it uses the color-specific subgraph rather than the main graph. This is much faster because the subgraph is already organized around the metadata you’re filtering by.
In the figure below, the main graph index is called the base graph, while the specialized graphs built for specific metadata fields are called column graphs. To manage memory usage effectively, it limits how many connections each point can have (out-degree). When a search doesn’t include any metadata filters, it defaults to the base graph. When filters are applied, it switches to the appropriate column graph, offering a significant speed advantage.

Iterative Filtering
Sometimes the filtering itself becomes the bottleneck, not the vector search. This happens especially with complex filters like JSON conditions or detailed string comparisons. The traditional approach (filter first, then search) can be extremely slow because the system has to evaluate these expensive filters on potentially millions of records before even starting the vector search.
You might think: “Why not do vector search first, then filter the top results?” This approach works sometimes, but has a major flaw: if your filter is strict and filters out most results, you might end up with too few (or zero) results after filtering.
To solve this dilemma, we created Iterative Filtering in Milvus and Zilliz Cloud, inspired by VBase. Instead of an all-or-nothing approach, Iterative Filtering works in batches:
Get a batch of the closest vector matches
Apply filters to this batch
If we don’t have enough filtered results, get another batch
Repeat until we have the required number of results
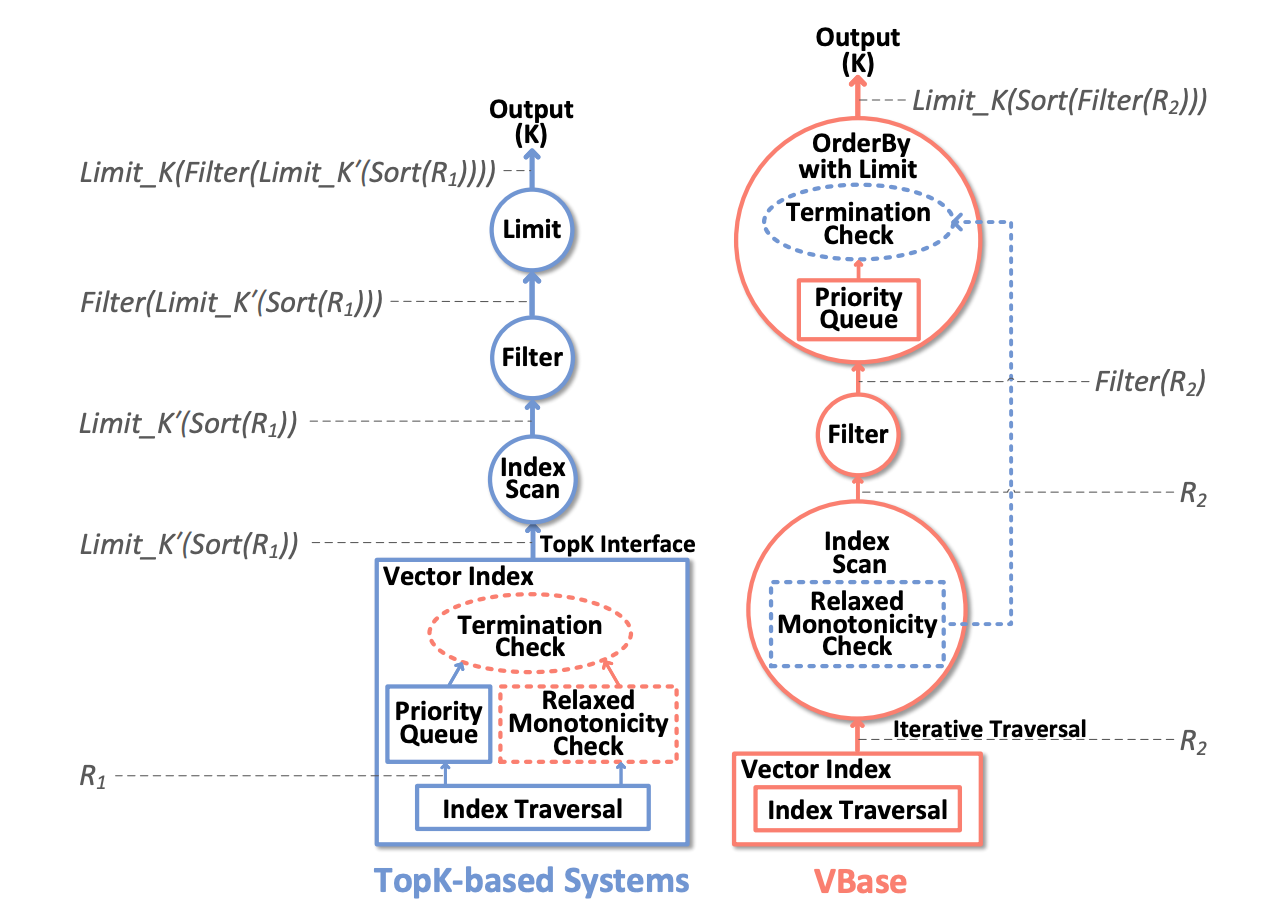
This approach dramatically reduces how many expensive filter operations we need to perform while still ensuring we get enough high-quality results. For more information on enabling iterative filtering, please refer to this iterative filtering doc page.
External Filtering
Many real-world applications split their data across different systems - vectors in a vector database and metadata in traditional databases. For example, many organizations store product descriptions and user reviews as vectors in Milvus for semantic search, while keeping inventory status, pricing, and other structured data in traditional databases like PostgreSQL or MongoDB.
This separation makes sense architecturally but creates a challenge for filtered searches. The typical workflow becomes:
Query your relational database for records matching filter criteria (e.g., “in-stock items under $50”)
Get the matching IDs and send them to Milvus to filter the vector search
Perform semantic search only on vectors that match these IDs
This sounds simple—but when the number of rows grows beyond millions, it becomes a bottleneck. Transferring large lists of IDs consumes network bandwidth, and executing massive filter expressions in Milvus adds overhead.
To address this, we introduced External Filtering in Milvus, a lightweight SDK-level solution that uses the search iterator API and reverses the traditional workflow.
Performs vector search first, retrieving batches of the most semantically relevant candidates
Applies your custom filter function to each batch on the client side
Automatically fetches more batches until you have enough filtered results
This batched, iterative approach significantly reduces both network traffic and processing overhead, since you’re only working with the most promising candidates from the vector search.
Here’s an example of how to use External Filtering in pymilvus:
vector_to_search = rng.random((1, DIM), np.float32)
expr = f"10 <= {AGE} <= 25"
valid_ids = [1, 12, 123, 1234]
def external_filter_func(hits: Hits):
return list(filter(lambda hit: hit.id in valid_ids, hits))
search_iterator = milvus_client.search_iterator(
collection_name=collection_name,
data=vector_to_search,
batch_size=100,
anns_field=PICTURE,
filter=expr,
external_filter_func=external_filter_func,
output_fields=[USER_ID, AGE]
)
while True:
res = search_iterator.next()
if len(res) == 0:
search_iterator.close()
break
for i in range(len(res)):
print(res[i])
Unlike Iterative Filtering, which operates on segment-level iterators, External Filtering works at the global query level. This design minimizes metadata evaluation and avoids executing large filters within Milvus, resulting in leaner and faster end-to-end performance.
AutoIndex
Vector search always involves a tradeoff between accuracy and speed - the more vectors you check, the better your results but the slower your query. When you add filters, this balance becomes even trickier to get right.
In Zilliz Cloud, we’ve created AutoIndex - an ML-based optimizer that automatically fine-tunes this balance for you. Instead of manually configuring complex parameters, AutoIndex uses machine learning to determine the optimal settings for your specific data and query patterns.
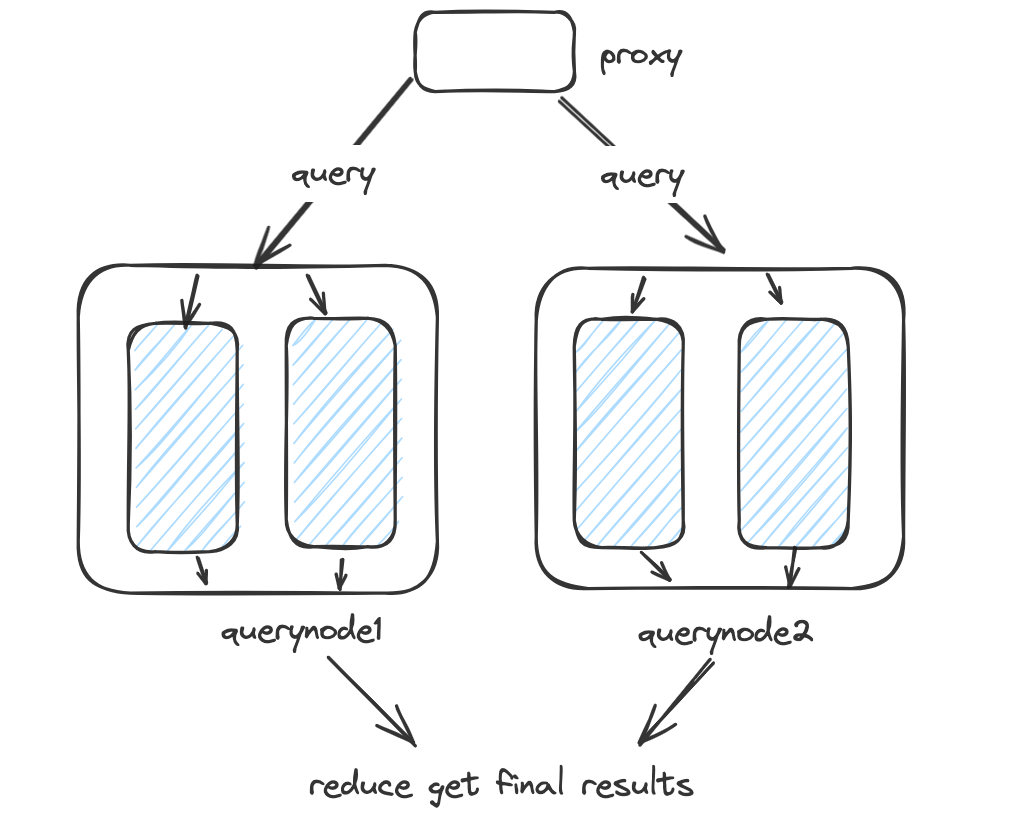
To understand how this works, it helps to know a bit about Milvus’s architecture since Zilliz is built on top of Milvus: Queries are distributed across multiple QueryNode instances. Each node handles a portion of your data (a segment), performs its search, and then results are merged together.
AutoIndex analyzes statistics from these segments and makes intelligent adjustments. For low filtering ratio, the index query range is widened to increase recall. For high filtering ratio, the query range is narrowed to avoid wasted effort on unlikely candidates. These decisions are guided by statistical models that predict the most effective search strategy for each specific filtering scenario.
AutoIndex goes beyond indexing parameters. It also helps select the best filter evaluation strategy. By parsing filter expressions and sampling segment data, it can estimate evaluation cost. If it detects high evaluation costs, it automatically switches to more efficient techniques such as Iterative Filtering. This dynamic adjustment ensures you’re always using the best-fit strategy for each query.
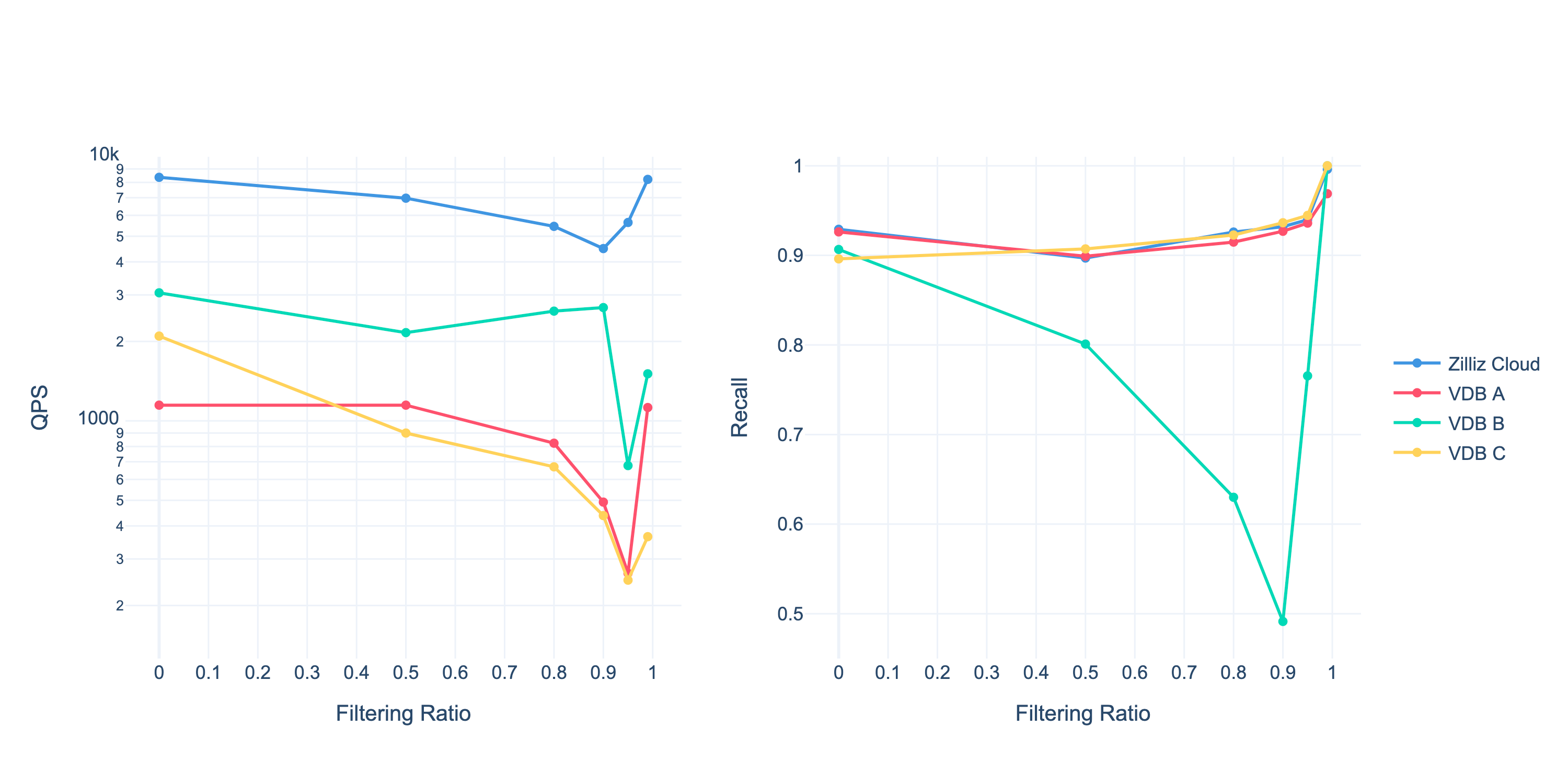
Performance on a $1,000 Budget
While theoretical improvements are important, real-world performance is what matters to most developers. We wanted to test how these optimizations translate to actual application performance under realistic budget constraints.
We benchmarked several vector database solutions with a practical $1,000 monthly budget - a reasonable amount that many companies would allocate to vector search infrastructure. For each solution, we selected the highest-performing instance configuration possible within this budget constraint.
Our testing used:
The Cohere 1M dataset with 1 million 768-dimensional vectors
A mix of real-world filtered and unfiltered search workloads
The open-source vdb-bench benchmark tool for consistent comparisons
The competing solutions (anonymized as “VDB A,” “VDB B,” and “VDB C”) were all configured optimally within the budget. The results showed that fully-managed Milvus (Zilliz Cloud) consistently achieved the highest throughput across both filtered and unfiltered queries. With the same $1000 budge, our optimization techniques deliver the most performance at competitive recall.
Conclusion
Vector search with filtering might look simple on the surface - just add a filter clause to your query and you’re done. However, as we’ve demonstrated in this blog, achieving both high performance and accurate results at scale requires sophisticated engineering solutions. Milvus and Zilliz Cloud address these challenges through several innovative approaches:
Graph Index Optimization: Preserves paths between similar items even when filters remove connecting nodes, preventing the “islands” problem that reduces result quality.
Metadata-Aware Indexing: Creates specialized paths for common filter conditions, making filtered searches significantly faster without sacrificing accuracy.
Iterative Filtering: Processes results in batches, applying complex filters only to the most promising candidates instead of the entire dataset.
AutoIndex: Uses machine learning to automatically tune search parameters based on your data and queries, balancing speed and accuracy without manual configuration.
External Filtering: Bridges vector search with external databases efficiently, eliminating network bottlenecks while maintaining result quality.
Milvus and Zilliz Cloud continue to evolve with new capabilities that further improve filtered search performance. Features like Partition Key allow for even more efficient data organization based on filtering patterns, and advanced subgraph routing techniques are pushing performance boundaries even further.
The volume and complexity of unstructured data continue to grow exponentially, creating new challenges for search systems everywhere. Our team is constantly pushing the boundaries of what’s possible with vector databases to deliver faster, more scalable AI-powered search.
If your applications are hitting performance bottlenecks with filtered vector search, we invite you to join our active developer community at milvus.io/community - where you can share challenges, access expert guidance, and discover emerging best practices.
References
- Graph Index Optimization
- Metadata-Aware Indexing
- Iterative Filtering
- External Filtering
- AutoIndex
- Performance on a $1,000 Budget
- Conclusion
- References
On This Page
Try Managed Milvus for Free
Zilliz Cloud is hassle-free, powered by Milvus and 10x faster.
Get StartedLike the article? Spread the word



