分组搜索
分组搜索允许 Milvus 根据指定字段的值对搜索结果进行分组,以便在更高层次上汇总数据。例如,您可以使用基本的 ANN 搜索来查找与手头的图书相似的图书,但也可以使用分组搜索来查找可能涉及该图书所讨论主题的图书类别。本主题将介绍如何使用分组搜索以及主要注意事项。
概述
当搜索结果中的实体在标量字段中共享相同值时,这表明它们在特定属性上相似,这可能会对搜索结果产生负面影响。
假设一个 Collections 存储了多个文档(用docId 表示)。在将文档转换成向量时,为了尽可能多地保留语义信息,每份文档都会被分割成更小的、易于管理的段落(或块),并作为单独的实体存储。即使文档被分割成较小的段落,用户通常仍希望识别哪些文档与他们的需求最相关。
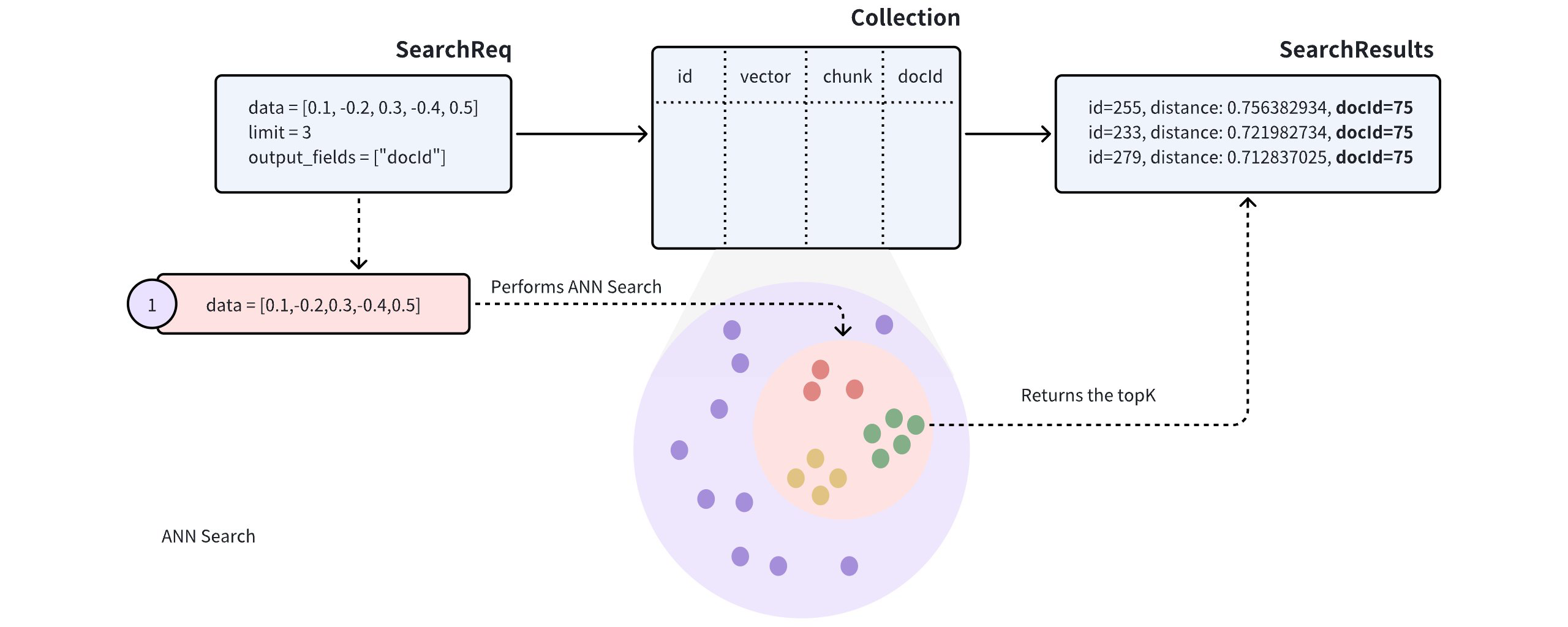 近似 搜索
近似 搜索
在对此类 Collections 执行近似近邻 (ANN) 搜索时,搜索结果可能包括同一文档中的多个段落,有可能导致其他文档被忽略,这可能与预期用例不符。
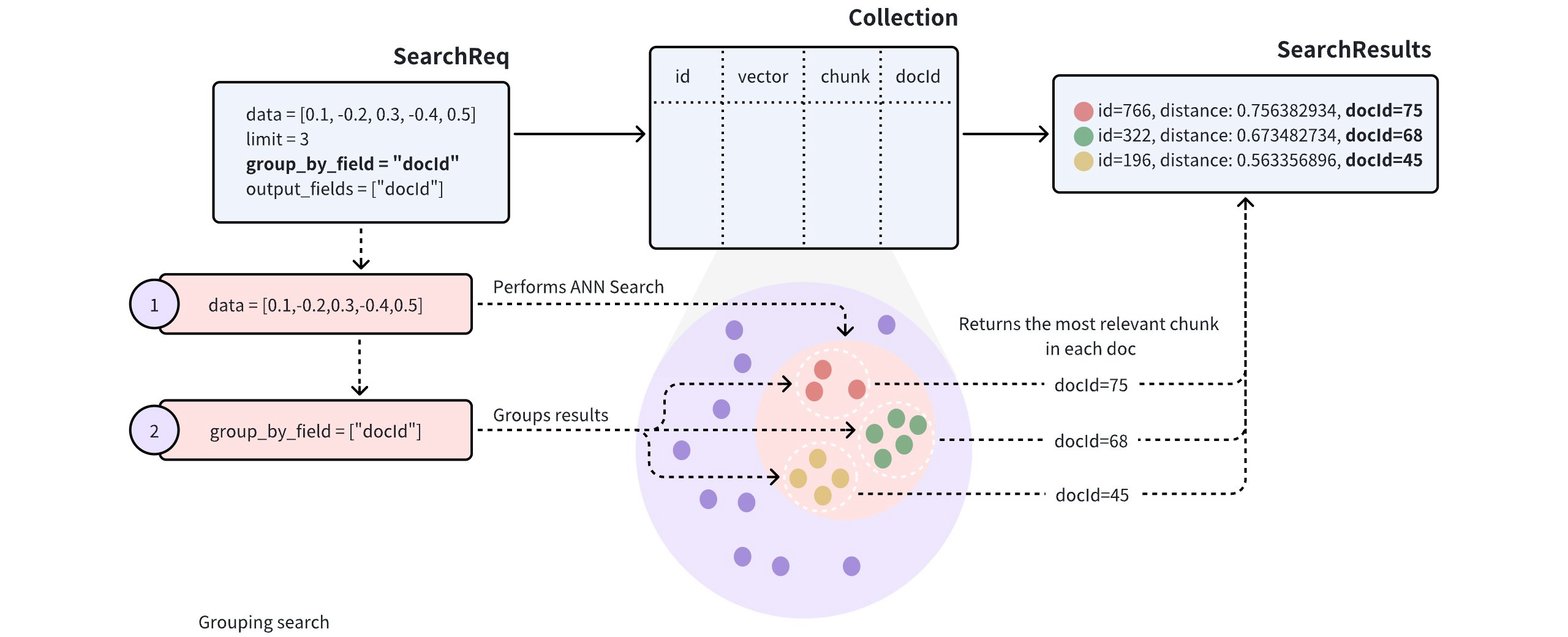 分组搜索
分组搜索
为了提高搜索结果的多样性,可以在搜索请求中添加group_by_field 参数来启用分组搜索。如图所示,您可以将group_by_field 设置为docId 。收到此请求后,Milvus 将
根据提供的查询向量执行 ANN 搜索,找到与查询最相似的所有实体。
按指定的
group_by_field对搜索结果进行分组,如docId。根据
limit参数的定义,返回每个组的顶部结果,并从每个组中选出最相似的实体。
默认情况下,分组搜索每个组只返回一个实体。如果要增加每个组返回结果的数量,可以使用group_size 和strict_group_size 参数进行控制。
执行分组搜索
本节提供示例代码,演示如何使用分组搜索。以下示例假定 Collections 包括id,vector,chunk 和docId 字段。
[
{"id": 0, "vector": [0.3580376395471989, -0.6023495712049978, 0.18414012509913835, -0.26286205330961354, 0.9029438446296592], "chunk": "pink_8682", "docId": 1},
{"id": 1, "vector": [0.19886812562848388, 0.06023560599112088, 0.6976963061752597, 0.2614474506242501, 0.838729485096104], "chunk": "red_7025", "docId": 5},
{"id": 2, "vector": [0.43742130801983836, -0.5597502546264526, 0.6457887650909682, 0.7894058910881185, 0.20785793220625592], "chunk": "orange_6781", "docId": 2},
{"id": 3, "vector": [0.3172005263489739, 0.9719044792798428, -0.36981146090600725, -0.4860894583077995, 0.95791889146345], "chunk": "pink_9298", "docId": 3},
{"id": 4, "vector": [0.4452349528804562, -0.8757026943054742, 0.8220779437047674, 0.46406290649483184, 0.30337481143159106], "chunk": "red_4794", "docId": 3},
{"id": 5, "vector": [0.985825131989184, -0.8144651566660419, 0.6299267002202009, 0.1206906911183383, -0.1446277761879955], "chunk": "yellow_4222", "docId": 4},
{"id": 6, "vector": [0.8371977790571115, -0.015764369584852833, -0.31062937026679327, -0.562666951622192, -0.8984947637863987], "chunk": "red_9392", "docId": 1},
{"id": 7, "vector": [-0.33445148015177995, -0.2567135004164067, 0.8987539745369246, 0.9402995886420709, 0.5378064918413052], "chunk": "grey_8510", "docId": 2},
{"id": 8, "vector": [0.39524717779832685, 0.4000257286739164, -0.5890507376891594, -0.8650502298996872, -0.6140360785406336], "chunk": "white_9381", "docId": 5},
{"id": 9, "vector": [0.5718280481994695, 0.24070317428066512, -0.3737913482606834, -0.06726932177492717, -0.6980531615588608], "chunk": "purple_4976", "docId": 3},
]
在搜索请求中,将group_by_field 和output_fields 都设置为docId 。Milvus 将根据指定字段对结果进行分组,并从每个分组中返回最相似的实体,包括每个返回实体的docId 值。
from pymilvus import MilvusClient
client = MilvusClient(
uri="http://localhost:19530",
token="root:Milvus"
)
query_vectors = [
[0.14529211512077012, 0.9147257273453546, 0.7965055218724449, 0.7009258593102812, 0.5605206522382088]]
# Group search results
res = client.search(
collection_name="my_collection",
data=query_vectors,
limit=3,
group_by_field="docId",
output_fields=["docId"]
)
# Retrieve the values in the `docId` column
doc_ids = [result['entity']['docId'] for result in res[0]]
import io.milvus.v2.client.ConnectConfig;
import io.milvus.v2.client.MilvusClientV2;
import io.milvus.v2.service.vector.request.SearchReq
import io.milvus.v2.service.vector.request.data.FloatVec;
import io.milvus.v2.service.vector.response.SearchResp
MilvusClientV2 client = new MilvusClientV2(ConnectConfig.builder()
.uri("http://localhost:19530")
.token("root:Milvus")
.build());
FloatVec queryVector = new FloatVec(new float[]{0.14529211512077012f, 0.9147257273453546f, 0.7965055218724449f, 0.7009258593102812f, 0.5605206522382088f});
SearchReq searchReq = SearchReq.builder()
.collectionName("my_collection")
.data(Collections.singletonList(queryVector))
.topK(3)
.groupByFieldName("docId")
.outputFields(Collections.singletonList("docId"))
.build();
SearchResp searchResp = client.search(searchReq);
List<List<SearchResp.SearchResult>> searchResults = searchResp.getSearchResults();
for (List<SearchResp.SearchResult> results : searchResults) {
System.out.println("TopK results:");
for (SearchResp.SearchResult result : results) {
System.out.println(result);
}
}
// Output
// TopK results:
// SearchResp.SearchResult(entity={docId=5}, score=0.74767184, id=1)
// SearchResp.SearchResult(entity={docId=2}, score=0.6254269, id=7)
// SearchResp.SearchResult(entity={docId=3}, score=0.3611898, id=3)
import (
"context"
"fmt"
"github.com/milvus-io/milvus/client/v2/entity"
"github.com/milvus-io/milvus/client/v2/milvusclient"
)
ctx, cancel := context.WithCancel(context.Background())
defer cancel()
milvusAddr := "localhost:19530"
client, err := milvusclient.New(ctx, &milvusclient.ClientConfig{
Address: milvusAddr,
})
if err != nil {
fmt.Println(err.Error())
// handle error
}
defer client.Close(ctx)
queryVector := []float32{0.3580376395471989, -0.6023495712049978, 0.18414012509913835, -0.26286205330961354, 0.9029438446296592}
resultSets, err := client.Search(ctx, milvusclient.NewSearchOption(
"my_collection", // collectionName
3, // limit
[]entity.Vector{entity.FloatVector(queryVector)},
).WithANNSField("vector").
WithGroupByField("docId").
WithOutputFields("docId"))
if err != nil {
fmt.Println(err.Error())
// handle error
}
for _, resultSet := range resultSets {
fmt.Println("IDs: ", resultSet.IDs.FieldData().GetScalars())
fmt.Println("Scores: ", resultSet.Scores)
fmt.Println("docId: ", resultSet.GetColumn("docId").FieldData().GetScalars())
}
import { MilvusClient, DataType } from "@zilliz/milvus2-sdk-node";
const address = "http://localhost:19530";
const token = "root:Milvus";
const client = new MilvusClient({address, token});
var query_vector = [0.3580376395471989, -0.6023495712049978, 0.18414012509913835, -0.26286205330961354, 0.9029438446296592]
res = await client.search({
collection_name: "my_collection",
data: [query_vector],
limit: 3,
group_by_field: "docId"
})
// Retrieve the values in the `docId` column
var docIds = res.results.map(result => result.entity.docId)
export CLUSTER_ENDPOINT="http://localhost:19530"
export TOKEN="root:Milvus"
curl --request POST \
--url "${CLUSTER_ENDPOINT}/v2/vectordb/entities/search" \
--header "Authorization: Bearer ${TOKEN}" \
--header "Content-Type: application/json" \
--header "Request-Timeout: 10" \
-d '{
"collectionName": "my_collection",
"data": [
[0.3580376395471989, -0.6023495712049978, 0.18414012509913835, -0.26286205330961354, 0.9029438446296592]
],
"annsField": "vector",
"limit": 3,
"groupingField": "docId",
"outputFields": ["docId"]
}'
在上面的请求中,limit=3 表示系统将从三个组中返回搜索结果,每个组都包含与查询向量最相似的单个实体。
配置组大小
默认情况下,分组搜索每个组只返回一个实体。如果希望每组有多个结果,请调整group_size 和strict_group_size 参数。
# Group search results
res = client.search(
collection_name="my_collection",
data=query_vectors, # query vector
limit=5, # number of groups to return
group_by_field="docId", # grouping field
group_size=2, # p to 2 entities to return from each group
strict_group_size=True, # return exact 2 entities from each group
output_fields=["docId"]
)
FloatVec queryVector = new FloatVec(new float[]{0.14529211512077012f, 0.9147257273453546f, 0.7965055218724449f, 0.7009258593102812f, 0.5605206522382088f});
SearchReq searchReq = SearchReq.builder()
.collectionName("my_collection")
.data(Collections.singletonList(queryVector))
.topK(5)
.groupByFieldName("docId")
.groupSize(2)
.strictGroupSize(true)
.outputFields(Collections.singletonList("docId"))
.build();
SearchResp searchResp = client.search(searchReq);
List<List<SearchResp.SearchResult>> searchResults = searchResp.getSearchResults();
for (List<SearchResp.SearchResult> results : searchResults) {
System.out.println("TopK results:");
for (SearchResp.SearchResult result : results) {
System.out.println(result);
}
}
// Output
// TopK results:
// SearchResp.SearchResult(entity={docId=5}, score=0.74767184, id=1)
// SearchResp.SearchResult(entity={docId=5}, score=-0.49148706, id=8)
// SearchResp.SearchResult(entity={docId=2}, score=0.6254269, id=7)
// SearchResp.SearchResult(entity={docId=2}, score=0.38515577, id=2)
// SearchResp.SearchResult(entity={docId=3}, score=0.3611898, id=3)
// SearchResp.SearchResult(entity={docId=3}, score=0.19556211, id=4)
import (
"context"
"fmt"
"github.com/milvus-io/milvus/client/v2/entity"
"github.com/milvus-io/milvus/client/v2/milvusclient"
)
ctx, cancel := context.WithCancel(context.Background())
defer cancel()
milvusAddr := "localhost:19530"
client, err := milvusclient.New(ctx, &milvusclient.ClientConfig{
Address: milvusAddr,
})
if err != nil {
fmt.Println(err.Error())
// handle error
}
defer client.Close(ctx)
queryVector := []float32{0.3580376395471989, -0.6023495712049978, 0.18414012509913835, -0.26286205330961354, 0.9029438446296592}
resultSets, err := client.Search(ctx, milvusclient.NewSearchOption(
"my_collection", // collectionName
5, // limit
[]entity.Vector{entity.FloatVector(queryVector)},
).WithANNSField("vector").
WithGroupByField("docId").
WithStrictGroupSize(true).
WithGroupSize(2).
WithOutputFields("docId"))
if err != nil {
fmt.Println(err.Error())
// handle error
}
for _, resultSet := range resultSets {
fmt.Println("IDs: ", resultSet.IDs.FieldData().GetScalars())
fmt.Println("Scores: ", resultSet.Scores)
fmt.Println("docId: ", resultSet.GetColumn("docId").FieldData().GetScalars())
}
import { MilvusClient, DataType } from "@zilliz/milvus2-sdk-node";
const address = "http://localhost:19530";
const token = "root:Milvus";
const client = new MilvusClient({address, token});
var query_vector = [0.3580376395471989, -0.6023495712049978, 0.18414012509913835, -0.26286205330961354, 0.9029438446296592]
res = await client.search({
collection_name: "my_collection",
data: [query_vector],
limit: 5,
group_by_field: "docId",
group_size: 2,
strict_group_size: true
})
// Retrieve the values in the `docId` column
var docIds = res.results.map(result => result.entity.docId)
curl --request POST \
--url "${CLUSTER_ENDPOINT}/v2/vectordb/entities/search" \
--header "Authorization: Bearer ${TOKEN}" \
--header "Content-Type: application/json" \
--header "Request-Timeout: 10" \
-d '{
"collectionName": "my_collection",
"data": [
[0.3580376395471989, -0.6023495712049978, 0.18414012509913835, -0.26286205330961354, 0.9029438446296592]
],
"annsField": "vector",
"limit": 5,
"groupingField": "docId",
"groupSize":2,
"strictGroupSize":true,
"outputFields": ["docId"]
}'
在上面的示例中
group_size:指定每个组要返回的实体数量。例如,设置group_size=2意味着每个组(或每个docId)最好返回两个最相似的段落(或块)。如果未设置group_size,系统将默认为每组返回一个结果。strict_group_size:这个布尔参数控制着系统是否应严格执行group_size设置的计数。当strict_group_size=True时,系统将尝试在每个组中包含group_size所指定的实体的确切数量(例如两个段落),除非该组中没有足够的数据。默认情况下(strict_group_size=False),系统会优先满足limit参数指定的组数,而不是确保每个组都包含group_size实体。在数据分布不均衡的情况下,这种方法通常更有效。
有关其他参数的详细信息,请参阅搜索。
按标量字段排列组Compatible with Milvus 3.0.x
您可以将分组搜索与order_by_fields 结合起来,按标量字段对分组排序。当您希望各组的结果各不相同,但又希望各组遵循与业务相关的顺序(如价格或评级)时,这种方法非常有用。
下面的示例按category 对搜索结果进行分组,每个分组最多返回三个实体,并按price 从低到高对返回的分组进行排序。
res = client.search(
collection_name="product_catalog",
data=query_vectors,
anns_field="embedding",
limit=20,
group_by_field="category",
group_size=3,
strict_group_size=True,
output_fields=["category", "price", "rating"],
order_by_fields=[
{"field": "price", "order": "asc"}
],
)
// java
// nodejs
// go
# restful
在上面的请求中,limit=20 表示 Milvus 最多选择 20 个组,而不是 20 个实体。因为group_size=3 ,平面结果列表总共最多可包含 60 个实体。
当你使用order_by_fields 和group_by_field 时,Milvus 会按照每个组的顶级实体的指定标量字段值对组进行排序。在每个组内,实体仍按其与查询向量的相似度得分排序。
注意事项
索引:此分组功能仅适用于使用这些索引类型编制索引的 Collections:flat、ivf_flat、ivf_sq8、hnsw、hnsw_pq、hnsw_prq、hnsw_sq、diskann、sparse_inverted_index。
组数:
limit参数控制返回搜索结果的组的数量,而不是每个组内实体的具体数量。设置适当的limit有助于控制搜索多样性和查询性能。如果数据分布密集或考虑性能问题,减少limit可以降低计算成本。每组实体:
group_size参数控制每个组返回的实体数量。根据使用情况调整group_size可以增加搜索结果的丰富性。但是,如果数据分布不均,某些组返回的实体数量可能少于group_size的指定数量,尤其是在数据有限的情况下。严格的组大小:当
strict_group_size=True时,系统将尝试为每个组返回指定数量的实体 (group_size),除非该组中没有足够的数据。此设置可确保每个组的实体数一致,但在数据分布不均或资源有限的情况下,可能会导致性能下降。如果不需要严格的实体计数,设置strict_group_size=False可以提高查询速度。如果查询向量已经存在于目标 Collections 中,可以考虑使用
ids,而不是在搜索前检索。有关详情,请参阅主键搜索。