Pesquisa híbrida multi-vetorial
Em muitas aplicações, um objeto pode ser pesquisado por um conjunto rico de informações, como o título e a descrição, ou com várias modalidades, como texto, imagens e áudio. Por exemplo, um tweet com um pedaço de texto e uma imagem deve ser pesquisado se o texto ou a imagem corresponderem à semântica da consulta de pesquisa. A pesquisa híbrida melhora a experiência de pesquisa ao combinar pesquisas nestes diversos domínios. O Milvus suporta isto ao permitir a pesquisa em vários campos vectoriais, realizando várias pesquisas ANN (Approximate Nearest Neighbor) em simultâneo. A pesquisa híbrida multi-vetorial é particularmente útil se pretender pesquisar texto e imagens, vários campos de texto que descrevem o mesmo objeto, ou vectores densos e esparsos para melhorar a qualidade da pesquisa.
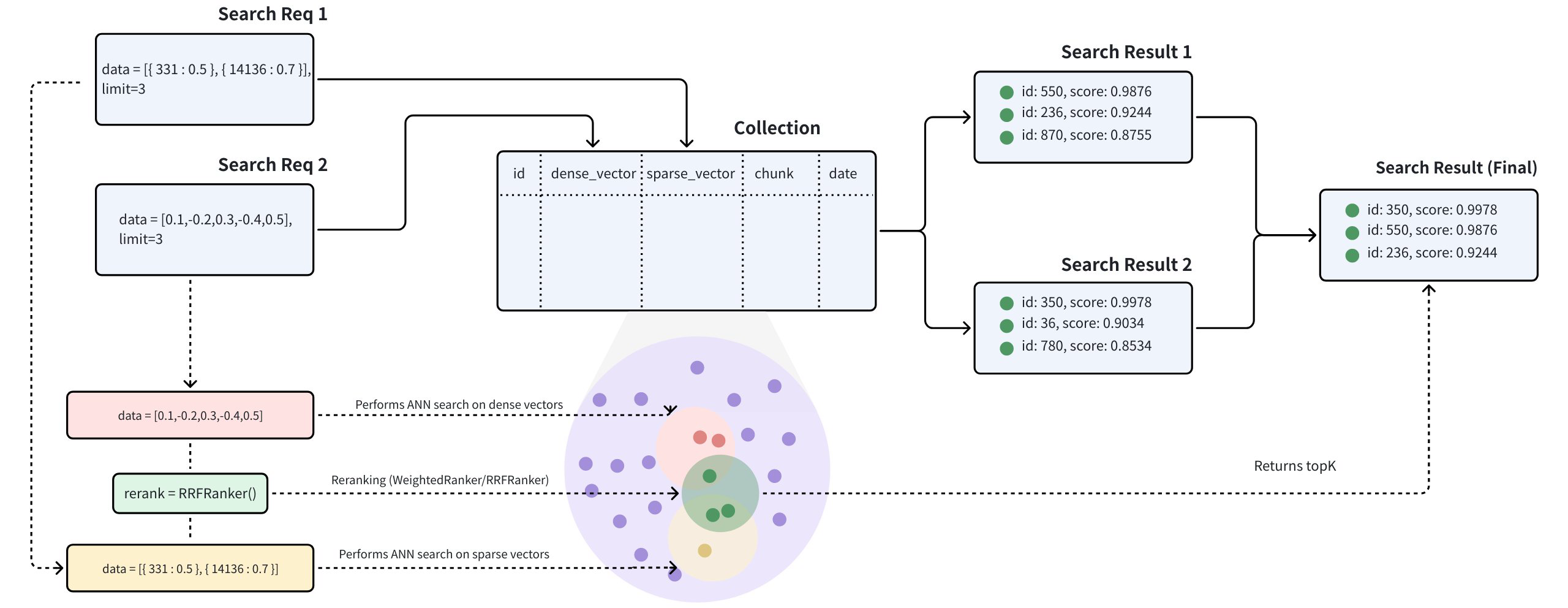 Fluxo de trabalho de pesquisa híbrida
Fluxo de trabalho de pesquisa híbrida
A pesquisa híbrida multi-vetorial integra diferentes métodos de pesquisa ou abrange embeddings de várias modalidades:
Pesquisa de vectores esparsos e densos: Os vectores densos são excelentes para captar relações semânticas, enquanto os vectores esparsos são altamente eficazes para uma correspondência precisa de palavras-chave. A pesquisa híbrida combina estas abordagens para proporcionar uma compreensão concetual ampla e a relevância exacta do termo, melhorando assim os resultados da pesquisa. Ao aproveitar os pontos fortes de cada método, a pesquisa híbrida supera as limitações das abordagens individuais, oferecendo um melhor desempenho para consultas complexas. Aqui está um guia mais detalhado sobre a recuperação híbrida que combina a pesquisa semântica com a pesquisa de texto integral.
Pesquisa vetorial multimodal: A pesquisa vetorial multimodal é uma técnica poderosa que permite pesquisar em vários tipos de dados, incluindo texto, imagens, áudio e outros. A principal vantagem desta abordagem é a sua capacidade de unificar diferentes modalidades numa experiência de pesquisa perfeita e coesa. Por exemplo, na pesquisa de produtos, um utilizador pode introduzir uma consulta de texto para encontrar produtos descritos com texto e imagens. Ao combinar estas modalidades através de um método de pesquisa híbrido, pode aumentar a precisão da pesquisa ou enriquecer os resultados da pesquisa.
Exemplo
Consideremos um caso de utilização do mundo real em que cada produto inclui uma descrição de texto e uma imagem. Com base nos dados disponíveis, podemos efetuar três tipos de pesquisas:
Pesquisa de texto semântico: Trata-se de consultar a descrição de texto do produto utilizando vectores densos. Os textos incorporados podem ser gerados utilizando modelos como o BERT e o Transformers ou serviços como o OpenAI.
Pesquisa de texto completo: Aqui, consultamos a descrição do texto do produto utilizando uma correspondência de palavras-chave com vectores esparsos. Algoritmos como o BM25 ou modelos de incorporação esparsos como o BGE-M3 ou o SPLADE podem ser utilizados para este fim.
Pesquisa de imagens multimodais: Este método consulta a imagem utilizando uma consulta de texto com vectores densos. Os embeddings de imagem podem ser gerados com modelos como o CLIP.
Este guia irá guiá-lo através de um exemplo de uma pesquisa multimodal híbrida que combina os métodos de pesquisa acima referidos, tendo em conta a descrição de texto em bruto e as imagens incorporadas dos produtos. Demonstraremos como armazenar dados multi-vectoriais e efetuar pesquisas híbridas com uma estratégia de reranking.
Criar uma coleção com vários campos vectoriais
O processo de criação de uma coleção envolve três passos fundamentais: definir o esquema da coleção, configurar os parâmetros do índice e criar a coleção.
Definir o esquema
Para a pesquisa híbrida multi-vetorial, devemos definir vários campos vectoriais num esquema de coleção. Para mais informações sobre os limites do número de campos vectoriais permitidos numa coleção, consulte Zilliz Cloud Limits. No entanto, se necessário, é possível ajustar o proxy.maxVectorFieldNum para incluir até 10 campos de vetor em uma coleção, conforme necessário.
Este exemplo incorpora os seguintes campos no esquema:
id: Serve como chave primária para armazenar IDs de texto. Este campo é do tipo de dadosINT64.text: Utilizado para armazenar conteúdo textual. Este campo é do tipo de dadosVARCHARcom um comprimento máximo de 1000 bytes. A opçãoenable_analyzeré definida comoTruepara facilitar a pesquisa de texto integral.text_dense: Utilizado para armazenar vectores densos dos textos. Este campo é do tipo de dadosFLOAT_VECTORcom uma dimensão vetorial de 768.text_sparse: Utilizado para armazenar vectores esparsos dos textos. Este campo é do tipo de dadosSPARSE_FLOAT_VECTOR.image_dense: Utilizado para armazenar os vectores densos das imagens dos produtos. Este campo é do tipo de dadosFLOAT_VETORcom uma dimensão vetorial de 512.
Uma vez que utilizaremos o algoritmo BM25 incorporado para efetuar uma pesquisa de texto completo no campo de texto, é necessário adicionar o Milvus Function ao esquema. Para mais pormenores, consulte Pesquisa de texto completo.
from pymilvus import (
MilvusClient, DataType, Function, FunctionType
)
client = MilvusClient(
uri="http://localhost:19530",
token="root:Milvus"
)
# Init schema with auto_id disabled
schema = client.create_schema(auto_id=False)
# Add fields to schema
schema.add_field(field_name="id", datatype=DataType.INT64, is_primary=True, description="product id")
schema.add_field(field_name="text", datatype=DataType.VARCHAR, max_length=1000, enable_analyzer=True, description="raw text of product description")
schema.add_field(field_name="text_dense", datatype=DataType.FLOAT_VECTOR, dim=768, description="text dense embedding")
schema.add_field(field_name="text_sparse", datatype=DataType.SPARSE_FLOAT_VECTOR, description="text sparse embedding auto-generated by the built-in BM25 function")
schema.add_field(field_name="image_dense", datatype=DataType.FLOAT_VECTOR, dim=512, description="image dense embedding")
# Add function to schema
bm25_function = Function(
name="text_bm25_emb",
input_field_names=["text"],
output_field_names=["text_sparse"],
function_type=FunctionType.BM25,
)
schema.add_function(bm25_function)
import io.milvus.v2.client.ConnectConfig;
import io.milvus.v2.client.MilvusClientV2;
import io.milvus.v2.common.DataType;
import io.milvus.common.clientenum.FunctionType;
import io.milvus.v2.service.collection.request.AddFieldReq;
import io.milvus.v2.service.collection.request.CreateCollectionReq;
import io.milvus.v2.service.collection.request.CreateCollectionReq.Function;
import java.util.*;
MilvusClientV2 client = new MilvusClientV2(ConnectConfig.builder()
.uri("http://localhost:19530")
.token("root:Milvus")
.build());
CreateCollectionReq.CollectionSchema schema = client.createSchema();
schema.addField(AddFieldReq.builder()
.fieldName("id")
.dataType(DataType.Int64)
.isPrimaryKey(true)
.autoID(false)
.build());
schema.addField(AddFieldReq.builder()
.fieldName("text")
.dataType(DataType.VarChar)
.maxLength(1000)
.enableAnalyzer(true)
.build());
schema.addField(AddFieldReq.builder()
.fieldName("text_dense")
.dataType(DataType.FloatVector)
.dimension(768)
.build());
schema.addField(AddFieldReq.builder()
.fieldName("text_sparse")
.dataType(DataType.SparseFloatVector)
.build());
schema.addField(AddFieldReq.builder()
.fieldName("image_dense")
.dataType(DataType.FloatVector)
.dimension(512)
.build());
schema.addFunction(Function.builder()
.functionType(FunctionType.BM25)
.name("text_bm25_emb")
.inputFieldNames(Collections.singletonList("text"))
.outputFieldNames(Collections.singletonList("text_sparse"))
.build());
import (
"context"
"fmt"
"github.com/milvus-io/milvus/client/v2/column"
"github.com/milvus-io/milvus/client/v2/entity"
"github.com/milvus-io/milvus/client/v2/index"
"github.com/milvus-io/milvus/client/v2/milvusclient"
)
ctx, cancel := context.WithCancel(context.Background())
defer cancel()
milvusAddr := "localhost:19530"
client, err := milvusclient.New(ctx, &milvusclient.ClientConfig{
Address: milvusAddr,
})
if err != nil {
fmt.Println(err.Error())
// handle error
}
defer client.Close(ctx)
function := entity.NewFunction().
WithName("text_bm25_emb").
WithInputFields("text").
WithOutputFields("text_sparse").
WithType(entity.FunctionTypeBM25)
schema := entity.NewSchema()
schema.WithField(entity.NewField().
WithName("id").
WithDataType(entity.FieldTypeInt64).
WithIsPrimaryKey(true),
).WithField(entity.NewField().
WithName("text").
WithDataType(entity.FieldTypeVarChar).
WithEnableAnalyzer(true).
WithMaxLength(1000),
).WithField(entity.NewField().
WithName("text_dense").
WithDataType(entity.FieldTypeFloatVector).
WithDim(768),
).WithField(entity.NewField().
WithName("text_sparse").
WithDataType(entity.FieldTypeSparseVector),
).WithField(entity.NewField().
WithName("image_dense").
WithDataType(entity.FieldTypeFloatVector).
WithDim(512),
).WithFunction(function)
import { MilvusClient, DataType } from "@zilliz/milvus2-sdk-node";
const address = "http://localhost:19530";
const token = "root:Milvus";
const client = new MilvusClient({address, token});
// Define fields
const fields = [
{
name: "id",
data_type: DataType.Int64,
is_primary_key: true,
auto_id: false
},
{
name: "text",
data_type: DataType.VarChar,
max_length: 1000,
enable_match: true
},
{
name: "text_dense",
data_type: DataType.FloatVector,
dim: 768
},
{
name: "text_sparse",
data_type: DataType.SPARSE_FLOAT_VECTOR
},
{
name: "image_dense",
data_type: DataType.FloatVector,
dim: 512
}
];
// define function
const functions = [
{
name: "text_bm25_emb",
description: "text bm25 function",
type: FunctionType.BM25,
input_field_names: ["text"],
output_field_names: ["text_sparse"],
params: {},
},
];
export bm25Function='{
"name": "text_bm25_emb",
"type": "BM25",
"inputFieldNames": ["text"],
"outputFieldNames": ["text_sparse"],
"params": {}
}'
export schema='{
"autoId": false,
"functions": [$bm25Function],
"fields": [
{
"fieldName": "id",
"dataType": "Int64",
"isPrimary": true
},
{
"fieldName": "text",
"dataType": "VarChar",
"elementTypeParams": {
"max_length": 1000,
"enable_analyzer": true
}
},
{
"fieldName": "text_dense",
"dataType": "FloatVector",
"elementTypeParams": {
"dim": "768"
}
},
{
"fieldName": "text_sparse",
"dataType": "SparseFloatVector"
},
{
"fieldName": "image_dense",
"dataType": "FloatVector",
"elementTypeParams": {
"dim": "512"
}
}
]
}'
Criar índice
Depois de definir o esquema da coleção, o passo seguinte é configurar os índices vectoriais e especificar as métricas de semelhança. No exemplo dado:
text_dense_index: é criado um índice do tipoAUTOINDEXcom o tipo de métricaIPpara o campo de vetor denso de texto.text_sparse_index: um índice do tipoSPARSE_INVERTED_INDEXcom o tipo de métricaBM25é utilizado para o campo de vetor esparso de texto.image_dense_indexUm índice do tipoAUTOINDEXcom o tipo métricoIPé criado para o campo vetorial denso de imagem.
Pode escolher outros tipos de índice, conforme necessário, para melhor se adequar às suas necessidades e tipos de dados. Para mais informações sobre os tipos de índice suportados, consulte a documentação sobre os tipos de índice disponíveis.
# Prepare index parameters
index_params = client.prepare_index_params()
# Add indexes
index_params.add_index(
field_name="text_dense",
index_name="text_dense_index",
index_type="AUTOINDEX",
metric_type="IP"
)
index_params.add_index(
field_name="text_sparse",
index_name="text_sparse_index",
index_type="SPARSE_INVERTED_INDEX",
metric_type="BM25",
params={"inverted_index_algo": "DAAT_MAXSCORE"}, # or "DAAT_WAND" or "TAAT_NAIVE"
)
index_params.add_index(
field_name="image_dense",
index_name="image_dense_index",
index_type="AUTOINDEX",
metric_type="IP"
)
import io.milvus.v2.common.IndexParam;
import java.util.*;
Map<String, Object> denseParams = new HashMap<>();
IndexParam indexParamForTextDense = IndexParam.builder()
.fieldName("text_dense")
.indexName("text_dense_index")
.indexType(IndexParam.IndexType.AUTOINDEX)
.metricType(IndexParam.MetricType.IP)
.build();
Map<String, Object> sparseParams = new HashMap<>();
sparseParams.put("inverted_index_algo": "DAAT_MAXSCORE");
IndexParam indexParamForTextSparse = IndexParam.builder()
.fieldName("text_sparse")
.indexName("text_sparse_index")
.indexType(IndexParam.IndexType.SPARSE_INVERTED_INDEX)
.metricType(IndexParam.MetricType.BM25)
.extraParams(sparseParams)
.build();
IndexParam indexParamForImageDense = IndexParam.builder()
.fieldName("image_dense")
.indexName("image_dense_index")
.indexType(IndexParam.IndexType.AUTOINDEX)
.metricType(IndexParam.MetricType.IP)
.build();
List<IndexParam> indexParams = new ArrayList<>();
indexParams.add(indexParamForTextDense);
indexParams.add(indexParamForTextSparse);
indexParams.add(indexParamForImageDense);
indexOption1 := milvusclient.NewCreateIndexOption("my_collection", "text_dense",
index.NewAutoIndex(index.MetricType(entity.IP)))
indexOption2 := milvusclient.NewCreateIndexOption("my_collection", "text_sparse",
index.NewSparseInvertedIndex(entity.BM25, 0.2))
indexOption3 := milvusclient.NewCreateIndexOption("my_collection", "image_dense",
index.NewAutoIndex(index.MetricType(entity.IP)))
)
const index_params = [{
field_name: "text_dense",
index_name: "text_dense_index",
index_type: "AUTOINDEX",
metric_type: "IP"
},{
field_name: "text_sparse",
index_name: "text_sparse_index",
index_type: "IndexType.SPARSE_INVERTED_INDEX",
metric_type: "BM25",
params: {
inverted_index_algo: "DAAT_MAXSCORE",
}
},{
field_name: "image_dense",
index_name: "image_dense_index",
index_type: "AUTOINDEX",
metric_type: "IP"
}]
export indexParams='[
{
"fieldName": "text_dense",
"metricType": "IP",
"indexName": "text_dense_index",
"indexType":"AUTOINDEX"
},
{
"fieldName": "text_sparse",
"metricType": "BM25",
"indexName": "text_sparse_index",
"indexType": "SPARSE_INVERTED_INDEX",
"params":{"inverted_index_algo": "DAAT_MAXSCORE"}
},
{
"fieldName": "image_dense",
"metricType": "IP",
"indexName": "image_dense_index",
"indexType":"AUTOINDEX"
}
]'
Criar coleção
Crie uma coleção chamada demo com o esquema de coleção e os índices configurados nas duas etapas anteriores.
client.create_collection(
collection_name="my_collection",
schema=schema,
index_params=index_params
)
CreateCollectionReq createCollectionReq = CreateCollectionReq.builder()
.collectionName("my_collection")
.collectionSchema(schema)
.indexParams(indexParams)
.build();
client.createCollection(createCollectionReq);
err = client.CreateCollection(ctx,
milvusclient.NewCreateCollectionOption("my_collection", schema).
WithIndexOptions(indexOption1, indexOption2))
if err != nil {
fmt.Println(err.Error())
// handle error
}
res = await client.createCollection({
collection_name: "my_collection",
fields: fields,
index_params: index_params,
})
export CLUSTER_ENDPOINT="http://localhost:19530"
export TOKEN="root:Milvus"
curl --request POST \
--url "${CLUSTER_ENDPOINT}/v2/vectordb/collections/create" \
--header "Authorization: Bearer ${TOKEN}" \
--header "Content-Type: application/json" \
--header "Request-Timeout: 10" \
-d "{
\"collectionName\": \"my_collection\",
\"schema\": $schema,
\"indexParams\": $indexParams
}"
Inserir dados
Esta secção insere dados na coleção my_collection com base no esquema definido anteriormente. Durante a inserção, certifique-se de que todos os campos, exceto aqueles com valores gerados automaticamente, sejam fornecidos com dados no formato correto. Neste exemplo:
idum número inteiro que representa o ID do produtotextuma cadeia de caracteres que contém a descrição do produtotext_denseuma lista de 768 valores de vírgula flutuante que representam a incorporação densa da descrição do textoimage_denseuma lista de 512 valores de vírgula flutuante que representam a incorporação densa da imagem do produto
Pode utilizar os mesmos modelos ou modelos diferentes para gerar incorporações densas para cada campo. Neste exemplo, as duas incorporações densas têm dimensões diferentes, o que sugere que foram geradas por modelos diferentes. Ao definir cada pesquisa posteriormente, certifique-se de usar o modelo correspondente para gerar a incorporação de consulta apropriada.
Como este exemplo usa a função integrada BM25 para gerar embeddings esparsos a partir do campo de texto, não é necessário fornecer vetores esparsos manualmente. No entanto, se você optar por não usar o BM25, deverá pré-computar e fornecer os embeddings esparsos por conta própria.
import random
# Generate example vectors
def generate_dense_vector(dim):
return [random.random() for _ in range(dim)]
data=[
{
"id": 0,
"text": "Red cotton t-shirt with round neck",
"text_dense": generate_dense_vector(768),
"image_dense": generate_dense_vector(512)
},
{
"id": 1,
"text": "Wireless noise-cancelling over-ear headphones",
"text_dense": generate_dense_vector(768),
"image_dense": generate_dense_vector(512)
},
{
"id": 2,
"text": "Stainless steel water bottle, 500ml",
"text_dense": generate_dense_vector(768),
"image_dense": generate_dense_vector(512)
}
]
res = client.insert(
collection_name="my_collection",
data=data
)
import com.google.gson.Gson;
import com.google.gson.JsonObject;
import io.milvus.v2.service.vector.request.InsertReq;
Gson gson = new Gson();
JsonObject row1 = new JsonObject();
row1.addProperty("id", 0);
row1.addProperty("text", "Red cotton t-shirt with round neck");
row1.add("text_dense", gson.toJsonTree(text_dense1));
row1.add("image_dense", gson.toJsonTree(image_dense));
JsonObject row2 = new JsonObject();
row2.addProperty("id", 1);
row2.addProperty("text", "Wireless noise-cancelling over-ear headphones");
row2.add("text_dense", gson.toJsonTree(text_dense2));
row2.add("image_dense", gson.toJsonTree(image_dense2));
JsonObject row3 = new JsonObject();
row3.addProperty("id", 2);
row3.addProperty("text", "Stainless steel water bottle, 500ml");
row3.add("text_dense", gson.toJsonTree(dense3));
row3.add("image_dense", gson.toJsonTree(sparse3));
List<JsonObject> data = Arrays.asList(row1, row2, row3);
InsertReq insertReq = InsertReq.builder()
.collectionName("my_collection")
.data(data)
.build();
InsertResp insertResp = client.insert(insertReq);
_, err = client.Insert(ctx, milvusclient.NewColumnBasedInsertOption("my_collection").
WithInt64Column("id", []int64{0, 1, 2}).
WithVarcharColumn("text", []string{
"Red cotton t-shirt with round neck",
"Wireless noise-cancelling over-ear headphones",
"Stainless steel water bottle, 500ml",
}).
WithFloatVectorColumn("text_dense", 768, [][]float32{
{0.3580376395471989, -0.6023495712049978, 0.18414012509913835, ...},
{0.19886812562848388, 0.06023560599112088, 0.6976963061752597, ...},
{0.43742130801983836, -0.5597502546264526, 0.6457887650909682, ...},
}).
WithFloatVectorColumn("image_dense", 512, [][]float32{
{0.6366019600530924, -0.09323198122475052, ...},
{0.6414180010301553, 0.8976979978567611, ...},
{-0.6901259768402174, 0.6100500332193755, ...},
}).
if err != nil {
fmt.Println(err.Error())
// handle err
}
const { MilvusClient, DataType } = require("@zilliz/milvus2-sdk-node")
var data = [
{id: 0, text: "Red cotton t-shirt with round neck" , text_dense: [0.3580376395471989, -0.6023495712049978, 0.18414012509913835, ...], image_dense: [0.6366019600530924, -0.09323198122475052, ...]},
{id: 1, text: "Wireless noise-cancelling over-ear headphones" , text_dense: [0.19886812562848388, 0.06023560599112088, 0.6976963061752597, ...], image_dense: [0.6414180010301553, 0.8976979978567611, ...]},
{id: 2, text: "Stainless steel water bottle, 500ml" , text_dense: [0.43742130801983836, -0.5597502546264526, 0.6457887650909682, ...], image_dense: [-0.6901259768402174, 0.6100500332193755, ...]}
]
var res = await client.insert({
collection_name: "my_collection",
data: data,
})
curl --request POST \
--url "${CLUSTER_ENDPOINT}/v2/vectordb/entities/insert" \
--header "Authorization: Bearer ${TOKEN}" \
--header "Content-Type: application/json" \
--header "Request-Timeout: 10" \
-d '{
"data": [
{"id": 0, "text": "Red cotton t-shirt with round neck" , "text_dense": [0.3580376395471989, -0.6023495712049978, 0.18414012509913835, ...], "image_dense": [0.6366019600530924, -0.09323198122475052, ...]},
{"id": 1, "text": "Wireless noise-cancelling over-ear headphones" , "text_dense": [0.19886812562848388, 0.06023560599112088, 0.6976963061752597, ...], "image_dense": [0.6414180010301553, 0.8976979978567611, ...]},
{"id": 2, "text": "Stainless steel water bottle, 500ml" , "text_dense": [0.43742130801983836, -0.5597502546264526, 0.6457887650909682, ...], "image_dense": [-0.6901259768402174, 0.6100500332193755, ...]}
],
"collectionName": "my_collection"
}'
Executar a pesquisa híbrida
Etapa 1: Criar várias instâncias de AnnSearchRequest
O Hybrid Search é implementado criando vários AnnSearchRequest na função hybrid_search(), onde cada AnnSearchRequest representa um pedido de pesquisa ANN básico para um campo vetorial específico. Por conseguinte, antes de efetuar uma Pesquisa Híbrida, é necessário criar um AnnSearchRequest para cada campo vetorial.
Além disso, configurando o parâmetro expr num AnnSearchRequest, pode definir as condições de filtragem para a sua pesquisa híbrida. Consulte Filtered Search e Filtering Explained.
Na Pesquisa híbrida, cada AnnSearchRequest suporta apenas um dado de consulta.
Para demonstrar as capacidades de vários campos de vetor de pesquisa, vamos construir três pedidos de pesquisa AnnSearchRequest utilizando uma consulta de amostra. Também utilizaremos os seus vectores densos pré-computados para este processo. Os pedidos de pesquisa visam os seguintes campos vectoriais:
text_densepara pesquisa de texto semântico, permitindo a compreensão contextual e a recuperação com base no significado e não na correspondência direta de palavras-chave.text_sparsepara pesquisa de texto completo ou correspondência de palavras-chave, centrando-se em correspondências exactas de palavras ou frases no texto.image_densepara pesquisa multimodal de texto para imagem, para recuperar imagens de produtos relevantes com base no conteúdo semântico da consulta.
from pymilvus import AnnSearchRequest
query_text = "white headphones, quiet and comfortable"
query_dense_vector = generate_dense_vector(768)
query_multimodal_vector = generate_dense_vector(512)
# text semantic search (dense)
search_param_1 = {
"data": [query_dense_vector],
"anns_field": "text_dense",
"param": {"nprobe": 10},
"limit": 2
}
request_1 = AnnSearchRequest(**search_param_1)
# full-text search (sparse)
search_param_2 = {
"data": [query_text],
"anns_field": "text_sparse",
"limit": 2
}
request_2 = AnnSearchRequest(**search_param_2)
# text-to-image search (multimodal)
search_param_3 = {
"data": [query_multimodal_vector],
"anns_field": "image_dense",
"param": {"nprobe": 10},
"limit": 2
}
request_3 = AnnSearchRequest(**search_param_3)
reqs = [request_1, request_2, request_3]
import io.milvus.v2.service.vector.request.AnnSearchReq;
import io.milvus.v2.service.vector.request.data.BaseVector;
import io.milvus.v2.service.vector.request.data.FloatVec;
import io.milvus.v2.service.vector.request.data.SparseFloatVec;
import io.milvus.v2.service.vector.request.data.EmbeddedText;
float[] queryDense = new float[]{-0.0475336798f, 0.0521207601f, 0.0904406682f, ...};
float[] queryMultimodal = new float[]{0.0158298651f, 0.5264158340f, ...}
List<BaseVector> queryTexts = Collections.singletonList(new EmbeddedText("white headphones, quiet and comfortable");)
List<BaseVector> queryDenseVectors = Collections.singletonList(new FloatVec(queryDense));
List<BaseVector> queryMultimodalVectors = Collections.singletonList(new FloatVec(queryMultimodal));
List<AnnSearchReq> searchRequests = new ArrayList<>();
searchRequests.add(AnnSearchReq.builder()
.vectorFieldName("text_dense")
.vectors(queryDenseVectors)
.params("{\"nprobe\": 10}")
.topK(2)
.build());
searchRequests.add(AnnSearchReq.builder()
.vectorFieldName("text_sparse")
.vectors(queryTexts)
.topK(2)
.build());
searchRequests.add(AnnSearchReq.builder()
.vectorFieldName("image_dense")
.vectors(queryMultimodalVectors)
.params("{\"nprobe\": 10}")
.topK(2)
.build());
queryText := entity.Text({"white headphones, quiet and comfortable"})
queryVector := []float32{0.3580376395471989, -0.6023495712049978, 0.18414012509913835, ...}
queryMultimodalVector := []float32{0.015829865178701663, 0.5264158340734488, ...}
request1 := milvusclient.NewAnnRequest("text_dense", 2, entity.FloatVector(queryVector)).
WithAnnParam(index.NewIvfAnnParam(10))
annParam := index.NewSparseAnnParam()
annParam.WithDropRatio(0.2)
request2 := milvusclient.NewAnnRequest("text_sparse", 2, queryText).
WithAnnParam(annParam)
request3 := milvusclient.NewAnnRequest("image_dense", 2, entity.FloatVector(queryMultimodalVector)).
WithAnnParam(index.NewIvfAnnParam(10))
const query_text = "white headphones, quiet and comfortable"
const query_vector = [0.3580376395471989, -0.6023495712049978, 0.18414012509913835, ...]
const query_multimodal_vector = [0.015829865178701663, 0.5264158340734488, ...]
const search_param_1 = {
"data": query_vector,
"anns_field": "text_dense",
"param": {"nprobe": 10},
"limit": 2
}
const search_param_2 = {
"data": query_text,
"anns_field": "text_sparse",
"limit": 2
}
const search_param_3 = {
"data": query_multimodal_vector,
"anns_field": "image_dense",
"param": {"nprobe": 10},
"limit": 2
}
export req='[
{
"data": [[0.3580376395471989, -0.6023495712049978, 0.18414012509913835, ...]],
"annsField": "text_dense",
"params": {"nprobe": 10},
"limit": 2
},
{
"data": ["white headphones, quiet and comfortable"],
"annsField": "text_sparse",
"limit": 2
},
{
"data": [[0.015829865178701663, 0.5264158340734488, ...]],
"annsField": "image_dense",
"params": {"nprobe": 10},
"limit": 2
}
]'
Dado que o parâmetro limit está definido para 2, cada AnnSearchRequest devolve 2 resultados de pesquisa. Neste exemplo, 3 instâncias AnnSearchRequest são criadas, resultando em um total de 6 resultados de pesquisa.
Etapa 2: Configurar uma estratégia de ranqueamento
Para fundir e classificar novamente os conjuntos de resultados de pesquisa ANN, é essencial selecionar uma estratégia de classificação adequada. Milvus oferece vários tipos de estratégias de reranking. Para mais pormenores sobre estes mecanismos de reranking, consulte Weighted Ranker ou RRF Ranker.
Neste exemplo, uma vez que não existe uma ênfase particular em consultas de pesquisa específicas, iremos proceder com a estratégia RRFRanker.
ranker = Function(
name="rrf",
input_field_names=[], # Must be an empty list
function_type=FunctionType.RERANK,
params={
"reranker": "rrf",
"k": 100 # Optional
}
)
import io.milvus.common.clientenum.FunctionType;
import io.milvus.v2.service.collection.request.CreateCollectionReq.Function;
Function ranker = Function.builder()
.name("rrf")
.functionType(FunctionType.RERANK)
.param("reranker", "rrf")
.param("k", "100")
.build()
const rerank = {
name: 'rrf',
description: 'bm25 function',
type: FunctionType.RERANK,
input_field_names: [],
params: {
"reranker": "rrf",
"k": 100
},
};
import (
"github.com/milvus-io/milvus/client/v2/entity"
)
ranker := entity.NewFunction().
WithName("rrf").
WithType(entity.FunctionTypeRerank).
WithParam("reranker", "rrf").
WithParam("k", "100")
# Restful
export functionScore='{
"functions": [
{
"name": "rrf",
"type": "Rerank",
"inputFieldNames": [],
"params": {
"reranker": "rrf",
"k": 100
}
}
]
}'
Etapa 3: executar uma pesquisa híbrida
Antes de iniciar uma Hybrid Search, certifique-se de que a coleção esteja carregada. Se qualquer campo de vetor dentro da coleção não tiver um índice ou não estiver carregado na memória, ocorrerá um erro ao executar o método Hybrid Search.
res = client.hybrid_search(
collection_name="my_collection",
reqs=reqs,
ranker=ranker,
limit=2
)
for hits in res:
print("TopK results:")
for hit in hits:
print(hit)
import io.milvus.v2.common.ConsistencyLevel;
import io.milvus.v2.service.vector.request.HybridSearchReq;
import io.milvus.v2.service.vector.response.SearchResp;
HybridSearchReq hybridSearchReq = HybridSearchReq.builder()
.collectionName("my_collection")
.searchRequests(searchRequests)
.ranker(reranker)
.topK(2)
.build();
SearchResp searchResp = client.hybridSearch(hybridSearchReq);
resultSets, err := client.HybridSearch(ctx, milvusclient.NewHybridSearchOption(
"my_collection",
2,
request1,
request2,
request3,
).WithReranker(reranker))
if err != nil {
fmt.Println(err.Error())
// handle error
}
for _, resultSet := range resultSets {
fmt.Println("IDs: ", resultSet.IDs.FieldData().GetScalars())
fmt.Println("Scores: ", resultSet.Scores)
}
const { MilvusClient, DataType } = require("@zilliz/milvus2-sdk-node")
res = await client.loadCollection({
collection_name: "my_collection"
})
import { MilvusClient, RRFRanker, WeightedRanker } from '@zilliz/milvus2-sdk-node';
const search = await client.search({
collection_name: "my_collection",
data: [search_param_1, search_param_2, search_param_3],
limit: 2,
rerank: rerank
});
curl --request POST \
--url "${CLUSTER_ENDPOINT}/v2/vectordb/entities/hybrid_search" \
--header "Authorization: Bearer ${TOKEN}" \
--header "Content-Type: application/json" \
--header "Request-Timeout: 10" \
-d "{
\"collectionName\": \"my_collection\",
\"search\": ${req},
\"rerank\": {
\"strategy\":\"rrf\",
\"params\": ${rerank}
},
\"limit\": 2
}"
O resultado é o seguinte:
["['id: 1, distance: 0.006047376897186041, entity: {}', 'id: 2, distance: 0.006422005593776703, entity: {}']"]
Com o parâmetro limit=2 especificado para a Pesquisa híbrida, o Milvus ranqueará os seis resultados obtidos nas três pesquisas. Por fim, eles retornarão apenas os dois primeiros resultados mais semelhantes.
Utilização avançada
Definir temporariamente um fuso horário para uma pesquisa híbrida
Se a sua coleção tiver um campo TIMESTAMPTZ, pode substituir temporariamente o fuso horário predefinido da base de dados ou da coleção para uma única operação, definindo o parâmetro timezone na chamada de pesquisa híbrida. Este parâmetro controla a forma como os valores de TIMESTAMPTZ são apresentados e comparados durante a operação.
O valor de timezone deve ser um identificador de fuso horário IANA válido (por exemplo, Ásia/Shanghai, América/Chicago ou UTC). Para mais informações sobre como utilizar um campo TIMESTAMPTZ, consulte Campo TIMESTAMPTZ.
O exemplo abaixo mostra como definir temporariamente um fuso horário para uma operação de pesquisa híbrida:
res = client.hybrid_search(
collection_name="my_collection",
reqs=reqs,
ranker=ranker,
limit=2,
timezone="America/Havana",
)