Data processing
This article provides a detailed description of the implementation of data insertion, index building, and data querying in Milvus.
Data insertion
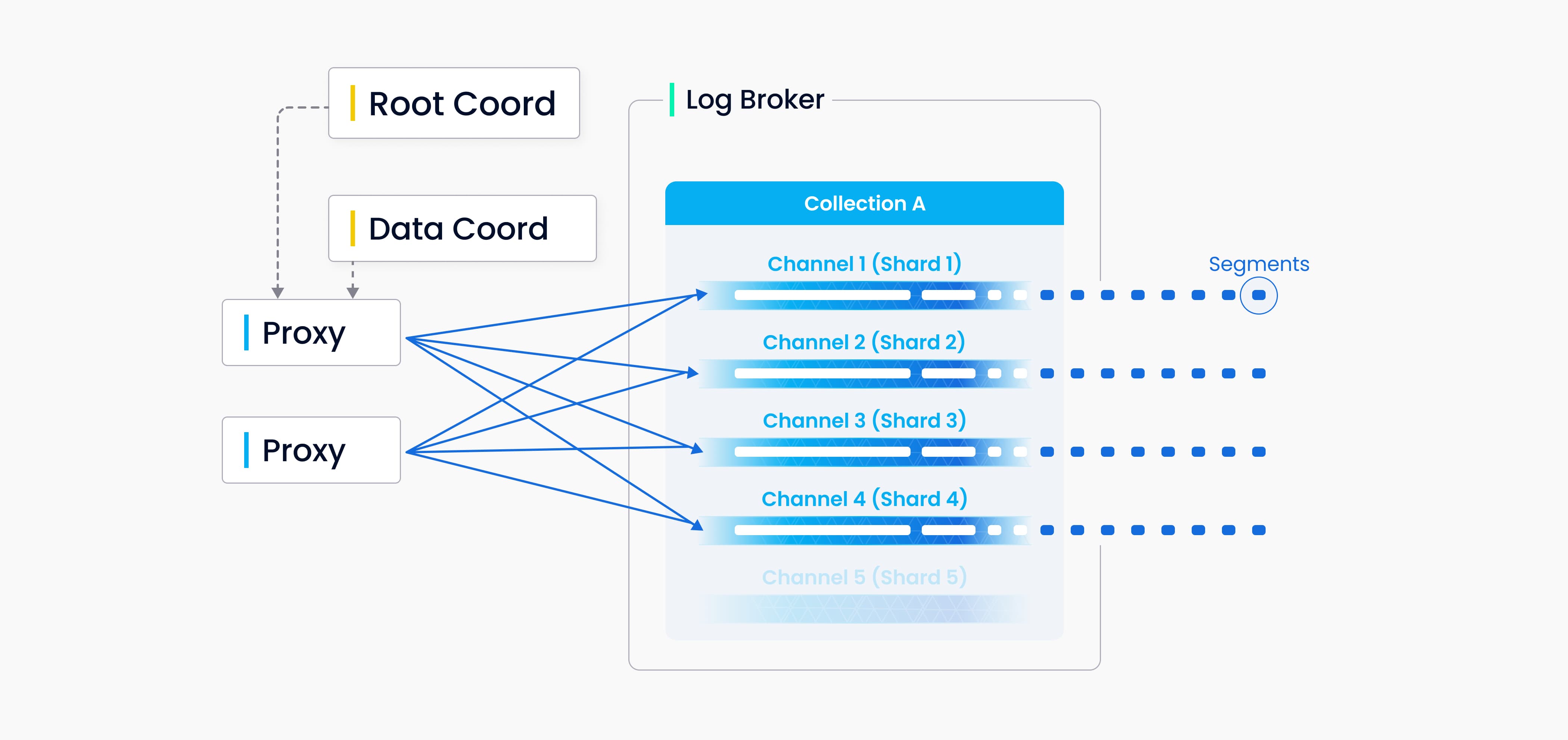
You can specify a number of shards for each collection in Milvus, each shard corresponding to a virtual channel (vchannel). As the following figure shows, Milvus assigns each vchannel in the log broker a physical channel (pchannel). Any incoming insert/delete request is routed to shards based on the hash value of primary key.
Validation of DML requests is moved forward to the proxy because Milvus does not have complicated transactions. The proxy requests a timestamp for each insert/delete request from the TSO (Timestamp Oracle), which is the timing module that colocates with the root coordinator. With the older timestamp being overwritten by the newer one, timestamps are used to determine the sequence of data requests being processed. The proxy retrieves information in batches from data coord including entities’ segments and primary keys to increase overall throughput and avoid overburdening the central node.
 Channels 1
Channels 1
Both DML (data manipulation language) operations and DDL (data definition language) operations are written to the log sequence, but DDL operations are only assigned one channel because of their low frequency of occurrence.
 Channels 2
Channels 2
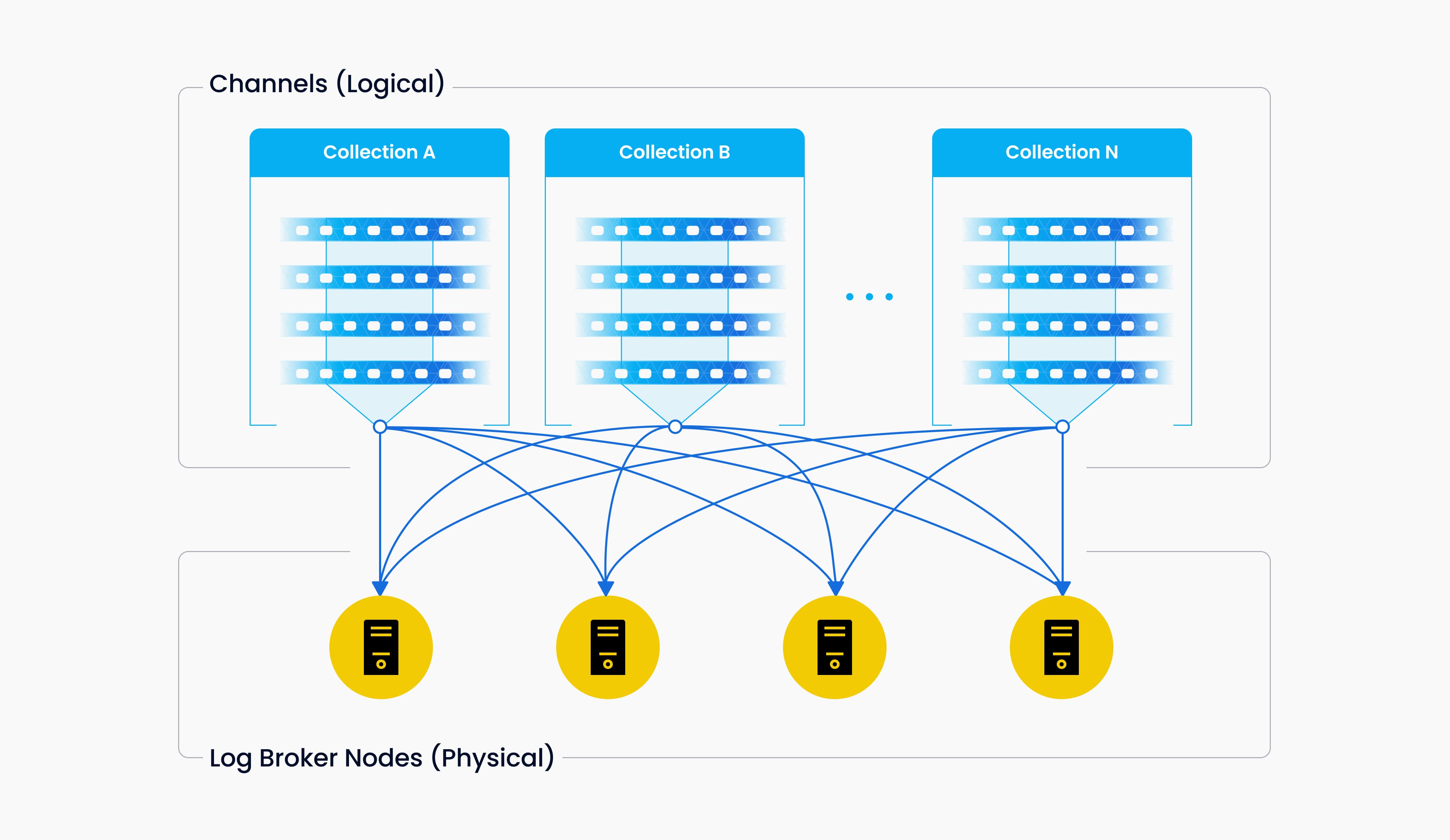
Vchannels are maintained in the underlying log broker nodes. Each channel is physically indivisible and available for any but only one node. When data ingestion rate reaches a bottleneck, consider two things: whether the log broker node is overloaded and needs to be scaled; and, whether there are sufficient shards to ensure load balancing for each node.
 Write log sequence
Write log sequence
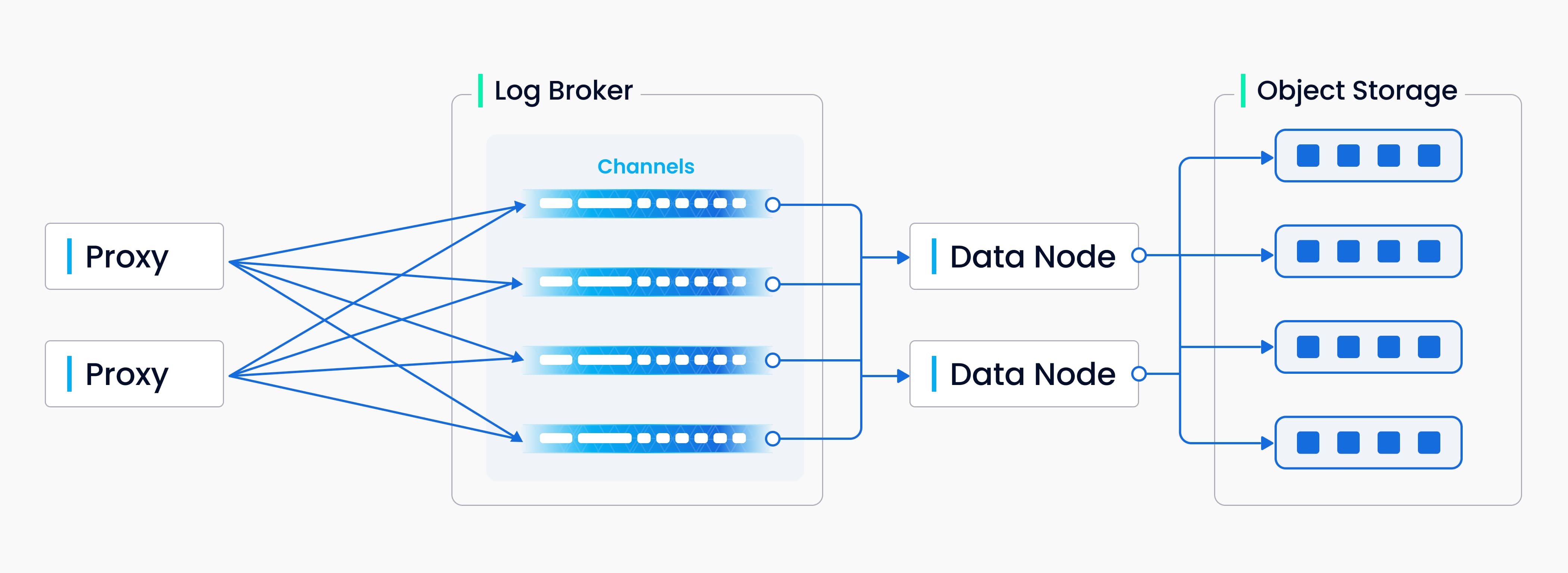
The above diagram encapsulates four components involved in the process of writing log sequence: the proxy, log broker, data node, and object storage. The process involves four tasks: validation of DML requests, publication-subscription of the log sequence, conversion from a streaming log to log snapshots, and persistence of log snapshots. The four tasks are decoupled from each other to make sure each task is handled by its corresponding node type. Nodes of the same type are made equal and can be scaled elastically and independently to accommodate various data loads, massive and highly fluctuating streaming data in particular.
Index building
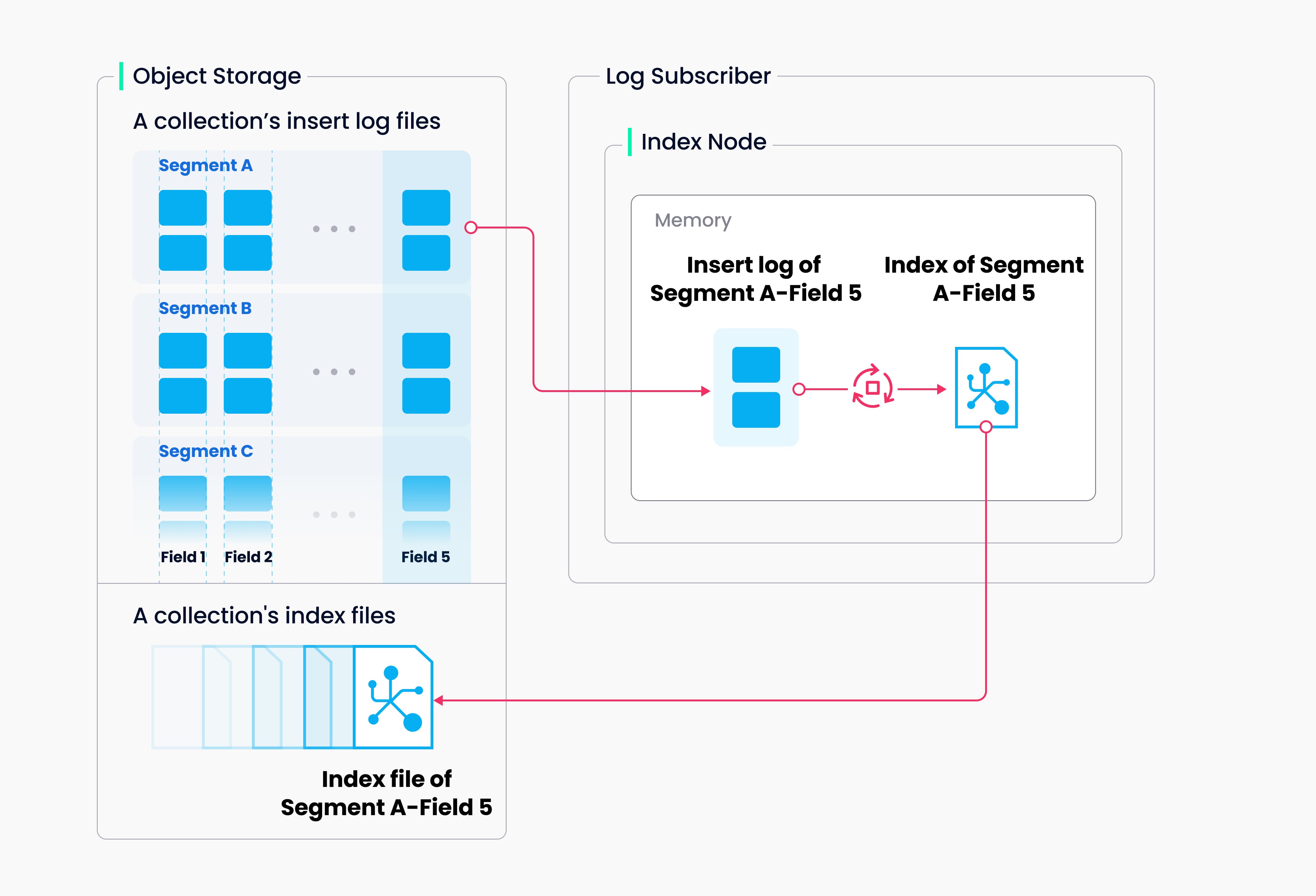
Index building is performed by index nodes. To avoid frequent index building for data updates, a collection in Milvus is divided further into segments, each with its own index.
 Index building
Index building
Milvus supports building indices for each vector field, scalar field and primary field. Both the input and output of index building engage with object storage: The index node loads the log snapshots to index from a segment (which is in object storage) to memory, deserializes the corresponding data and metadata to build index, serializes the index when index building completes, and writes it back to object storage.
Index building mainly involves vector and matrix operations and hence is compute- and memory-intensive. Vectors cannot be efficiently indexed with traditional tree-based indexes due to their high-dimensional nature, but can be indexed with techniques especially designed for this task, such as cluster- or graph-based indices. Regardless its type, building an index involves massive iterative calculations for large-scale vectors, such as K-means or graph traversal.
Unlike indexing for scalar data, building a vector index benefits greatly from SIMD (single instruction, multiple data) acceleration. Milvus has innate support for SIMD instruction sets, e.g., SSE, AVX2, and AVX512. Given the “hiccup” and resource-intensive nature of vector index building, elasticity becomes crucially important to Milvus in economical terms. Future Milvus releases will further explorations in heterogeneous computing and serverless computation to bring down the related costs.
Milvus also supports scalar filtering and primary field query. It has inbuilt indices to improve query efficiency, e.g., Bloom filter indices, hash indices, tree-based indices, and inverted indices, and plans to introduce more external indexes, e.g., bitmap indexes and rough indexes.
Data query
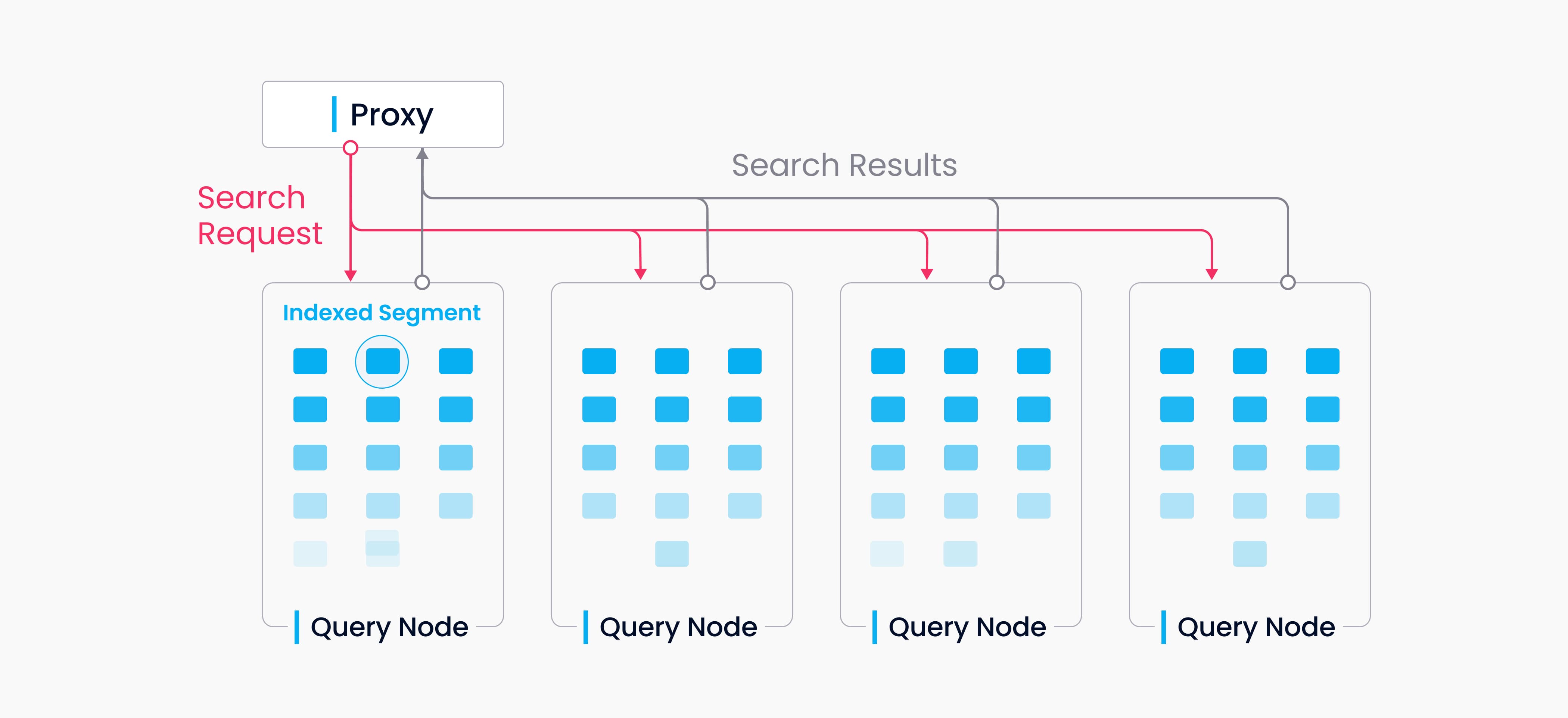
The term “data query” refers to the process of searching a specified collection for k number of vectors nearest to a target vector or for all vectors within a specified distance range to the vector. Vectors are returned together with their corresponding primary key and fields.
 Data query
Data query
A collection in Milvus is split into multiple segments, and the query nodes load indices by segment. When a search request arrives, it is broadcast to all query nodes for a concurrent search. Each node then prunes the local segments, searches for vectors meeting the criteria, and reduces and returns the search results.
Query nodes are independent from each other in a data query. Each node is responsible only for two tasks: Loading or releasing segments following the instructions from query coord; conducting a search within the local segments. And the proxy is responsible for reducing search results from each query node and returning the final results to the client.
 Handoff
Handoff
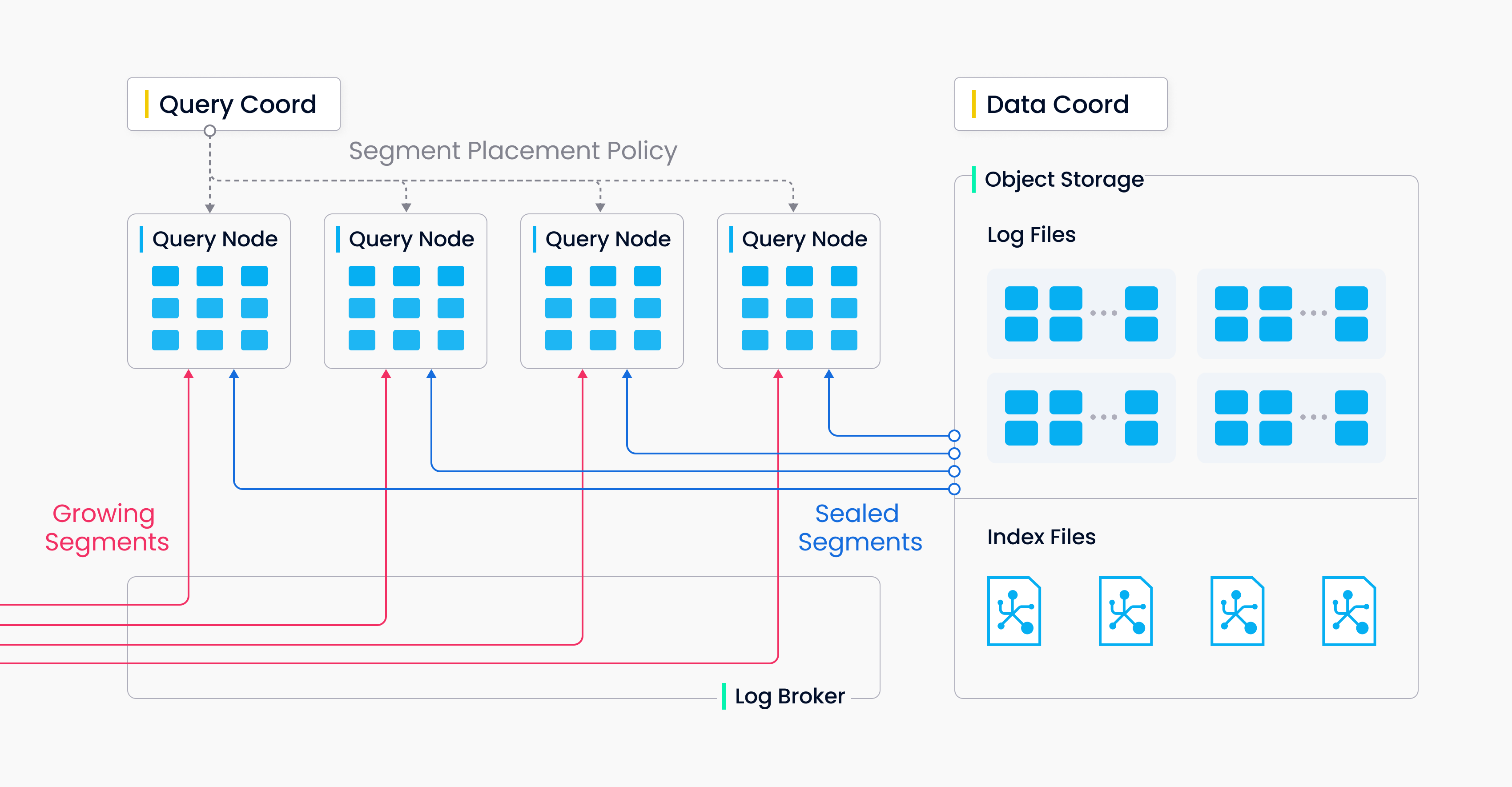
There are two types of segments, growing segments (for incremental data), and sealed segments (for historical data). Query nodes subscribe to vchannel to receive recent updates (incremental data) as growing segments. When a growing segment reaches a predefined threshold, data coord seals it and index building begins. Then a handoff operation initiated by query coord turns incremental data to historical data. Query coord will distribute sealed segments evenly among all query nodes according to memory usage, CPU overhead, and segment number.
What’s next
- Learn about how to use the Milvus vector database for real-time query.
- Learn about data insertion and data persistence in Milvus.
- Learn how data is processed in Milvus.