In-Memory Replica
This topic introduces the in-memory replica (replication) mechanism in Milvus that enables multiple segment replications in the working memory to improve performance and availability.
For information on how to configure in-memory replicas, refer to Query Node-related Configurations.
Overview
 Replica_Availiability
Replica_Availiability
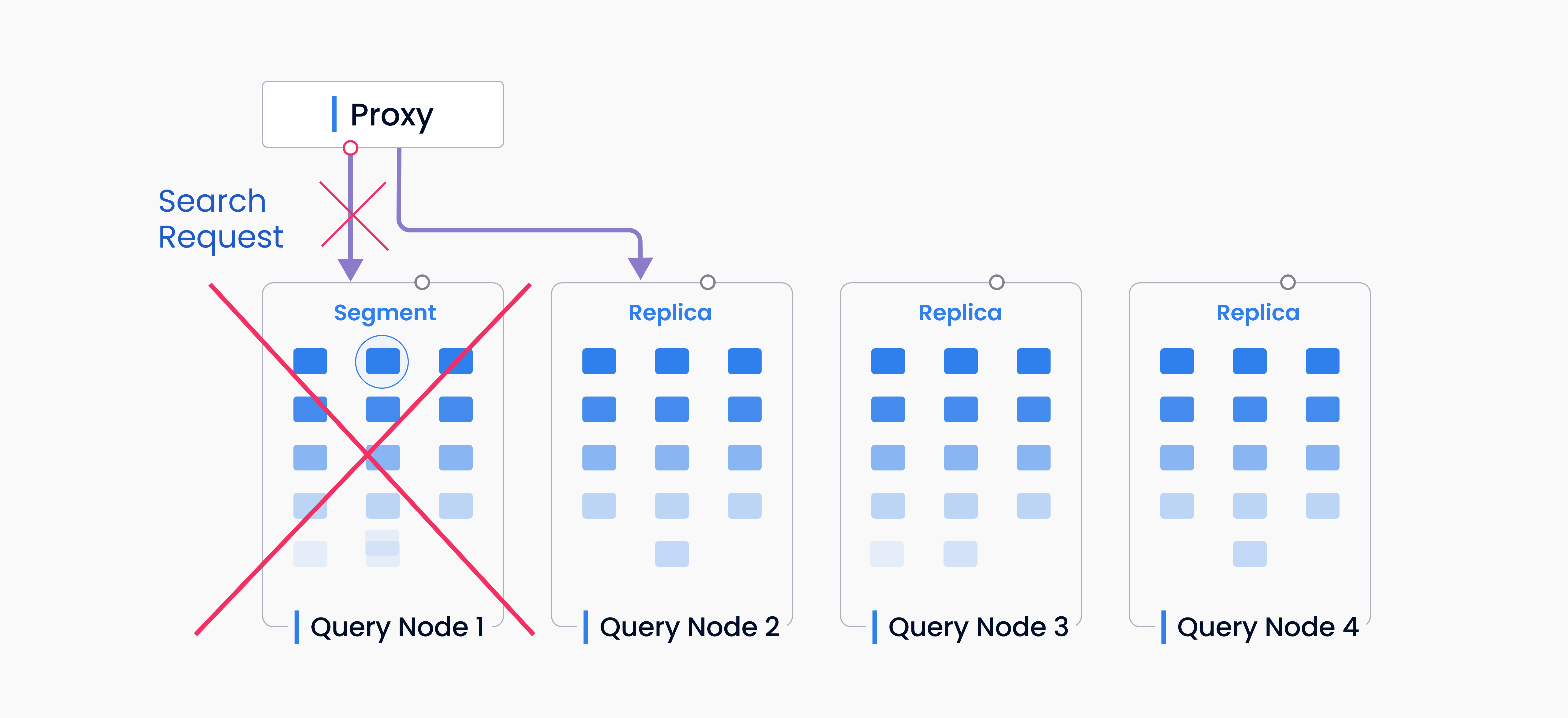
With in-memory replicas, Milvus can load the same segment on multiple query nodes. If one query node has failed or is busy with a current search request when another arrives, the system can send new requests to an idle query node that has a replication of the same segment.
Performance
In-memory replicas allow you to leverage extra CPU and memory resources. It is very useful if you have a relatively small dataset but want to increase read throughput with extra hardware resources. Overall QPS (query per second) and throughput can be significantly improved.
Availability
In-memory replicas help Milvus recover faster if a query node crashes. When a query node fails, the segment does not have to be reloaded on another query node. Instead, the search request can be resent to a new query node immediately without having to reload the data again. With multiple segment replicas maintained simultaneously, the system is more resilient in the face of a failover.
Key Concepts
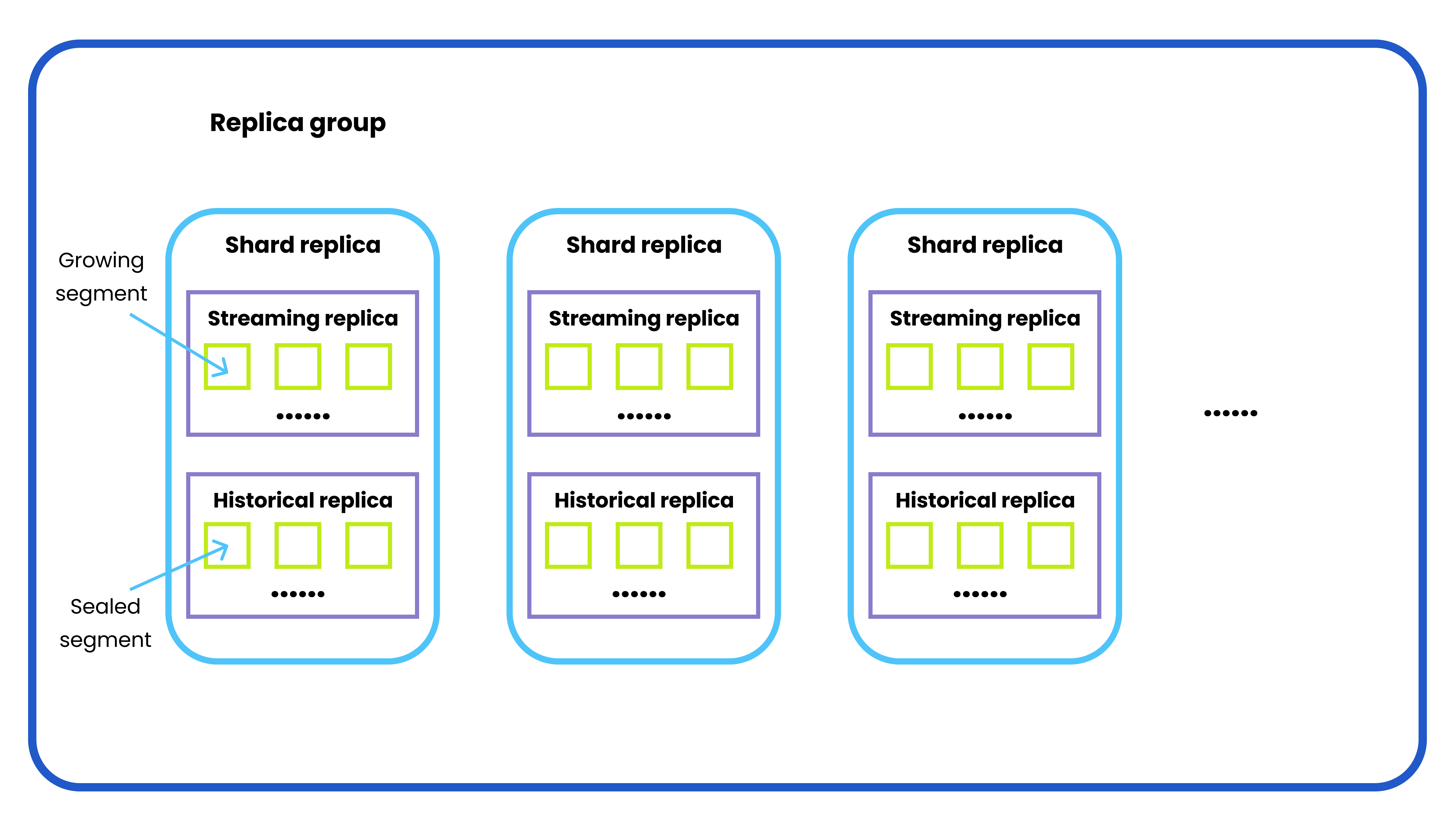
In-memory replicas are organized as replica groups. Each replica group contains shard replicas. Each shard replica has a streaming replica and a historical replica that correspond to the growing and sealed segments in the shard (i.e. DML channel).
 An illustration of how in-memory replica works
An illustration of how in-memory replica works
Replica group
A replica group consists of multiple query nodes that are responsible for handling historical data and replicas.
Shard replica
A shard replica consists of a streaming replica and a historical replica, both belonging to the same shard. The number of shard replicas in a replica group is determined by the number of shards in a specified collection.
Streaming replica
A streaming replica contains all the growing segments from the same DML channel. Technically speaking, a streaming replica should be served by only one query node in one replica.
Historical replica
A historical replica contains all the sealed segments from the same DML channel. The sealed segments of one historical replica can be distributed on several query nodes within the same replica group.
Shard leader
A shard leader is the query node serving the streaming replica in a shard replica.
Design Details
Balance
A new segment that needs to be loaded will be allocated to multiple different query nodes. A search request can be processed once at least one replica is loaded successfully.
Search
Cache
The proxy maintains a cache that maps segments to query nodes and updates it periodically. When the proxy receives a request, Milvus gets all sealed segments that need to be searched from the cache and try to assign them to the query nodes evenly.
For growing segments, the proxy also maintains a channel-to-query-node cache and sends requests to corresponding query nodes.
Failover
The caches on the proxy are not always up-to-date. Some segments or channels may have been moved to other query nodes when a request comes in. In this case, the proxy will receive an error response, update the cache and try to assign it to another query node.
A segment will be ignored if the proxy still cannot find it after updating the cache. This could happen if the segment has been compacted.
If the cache is not accurate, the proxy may miss some segments. Query nodes with DML channels (growing segments) return search responses along with a list of reliable segments that the proxy can compare and update the cache with.
Enhancement
The proxy cannot allocate search requests to query nodes completely equally and query nodes may have different resources to serve search requests. To avoid a long-tailed distribution of resources, the proxy will assign active segments on other query nodes to an idle query node that also has these segments.