Hybride Suche mit mehreren Vektoren
In vielen Anwendungen kann ein Objekt anhand einer Vielzahl von Informationen wie Titel und Beschreibung oder anhand mehrerer Modalitäten wie Text, Bilder und Audio durchsucht werden. So wird beispielsweise ein Tweet mit einem Text und einem Bild durchsucht, wenn entweder der Text oder das Bild mit der Semantik der Suchanfrage übereinstimmt. Die hybride Suche verbessert das Sucherlebnis durch die Kombination von Suchen in diesen verschiedenen Bereichen. Milvus unterstützt dies, indem es die Suche auf mehreren Vektorfeldern ermöglicht und mehrere ANN-Suchen (Approximate Nearest Neighbor) gleichzeitig durchführt. Die hybride Suche mit mehreren Vektoren ist besonders nützlich, wenn Sie sowohl Text als auch Bilder, mehrere Textfelder, die dasselbe Objekt beschreiben, oder dichte und spärliche Vektoren durchsuchen möchten, um die Suchqualität zu verbessern.
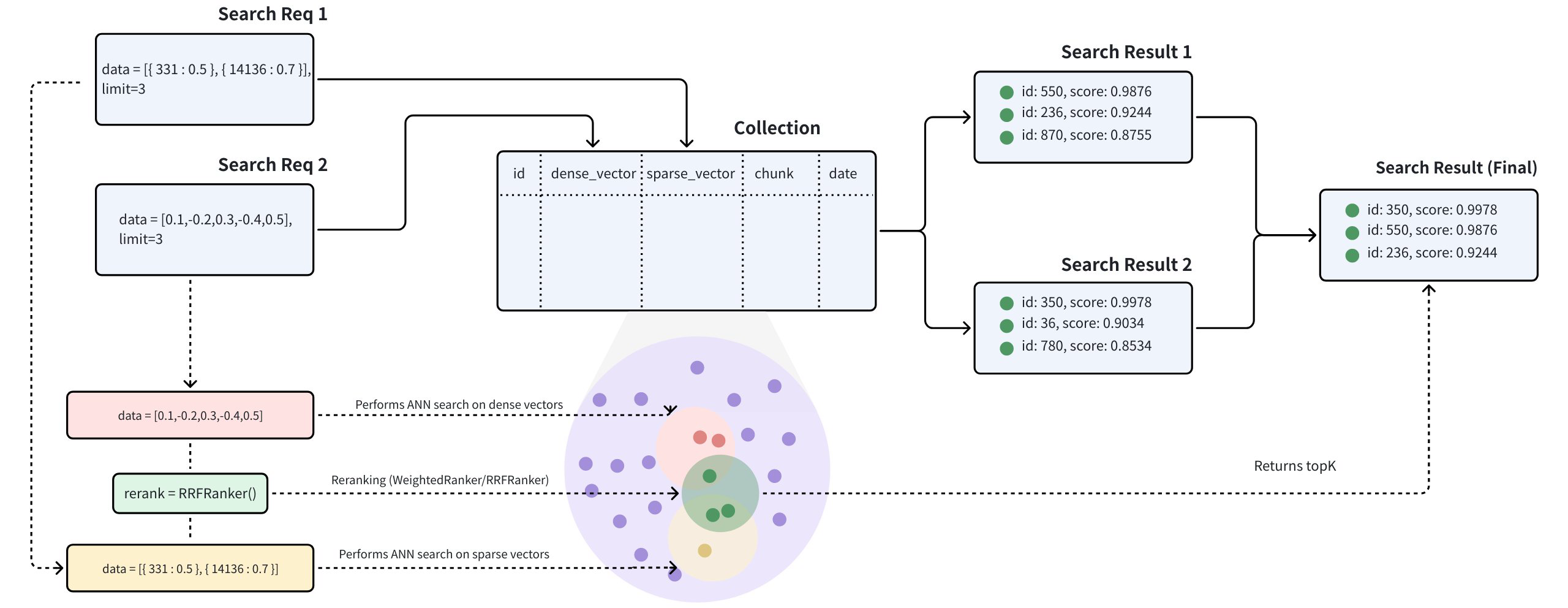 Arbeitsablauf der hybriden Suche
Arbeitsablauf der hybriden Suche
Die Multi-Vektor-Hybridsuche integriert verschiedene Suchmethoden oder überspannt Einbettungen aus verschiedenen Modalitäten:
Sparse-Dense Vector Search: Dense Vectors eignen sich hervorragend für die Erfassung semantischer Beziehungen, während Sparse Vectors sehr effektiv für den präzisen Abgleich von Schlüsselwörtern sind. Die hybride Suche kombiniert diese Ansätze, um sowohl ein breites konzeptionelles Verständnis als auch eine exakte Begriffsrelevanz zu gewährleisten und so die Suchergebnisse zu verbessern. Durch die Nutzung der Stärken der einzelnen Methoden überwindet die hybride Suche die Einschränkungen der einzelnen Ansätze und bietet eine bessere Leistung bei komplexen Suchanfragen. Hier finden Sie einen detaillierten Leitfaden zur hybriden Suche, die die semantische Suche mit der Volltextsuche kombiniert.
Multimodale Vektorsuche: Die multimodale Vektorsuche ist eine leistungsstarke Technik, mit der Sie verschiedene Datentypen durchsuchen können, darunter Text, Bilder, Audio und andere. Der Hauptvorteil dieses Ansatzes ist die Fähigkeit, verschiedene Modalitäten zu einem nahtlosen und zusammenhängenden Sucherlebnis zu vereinen. Bei der Produktsuche kann ein Benutzer beispielsweise eine Textabfrage eingeben, um Produkte zu finden, die sowohl mit Text als auch mit Bildern beschrieben sind. Durch die Kombination dieser Modalitäten mittels einer hybriden Suchmethode können Sie die Suchgenauigkeit verbessern oder die Suchergebnisse anreichern.
Beispiel
Betrachten wir einen realen Anwendungsfall, bei dem jedes Produkt eine Textbeschreibung und ein Bild enthält. Auf der Grundlage der verfügbaren Daten können wir drei Arten von Suchen durchführen:
Semantische Textsuche: Hierbei wird die Textbeschreibung des Produkts mithilfe von dichten Vektoren abgefragt. Die Texteinbettungen können mit Modellen wie BERT und Transformers oder Diensten wie OpenAI generiert werden.
Volltextsuche: Hier wird die Textbeschreibung des Produkts anhand einer Schlüsselwortübereinstimmung mit spärlichen Vektoren abgefragt. Hierfür können Algorithmen wie BM25 oder Sparse Embedding-Modelle wie BGE-M3 oder SPLADE verwendet werden.
Multimodale Bildsuche: Bei dieser Methode wird das Bild anhand einer Textabfrage mit dichten Vektoren abgefragt. Bildeinbettungen können mit Modellen wie CLIP erzeugt werden.
In diesem Leitfaden wird ein Beispiel für eine multimodale hybride Suche vorgestellt, bei der die oben genannten Suchmethoden mit einer Rohtextbeschreibung und Bildeinbettungen von Produkten kombiniert werden. Es wird gezeigt, wie man Multivektordaten speichert und hybride Suchen mit einer Reranking-Strategie durchführt.
Erstellen einer Sammlung mit mehreren Vektorfeldern
Der Prozess der Erstellung einer Sammlung umfasst drei wichtige Schritte: Definition des Sammlungsschemas, Konfiguration der Indexparameter und Erstellung der Sammlung.
Definieren des Schemas
Für die hybride Suche mit mehreren Vektorfeldern sollten Sie mehrere Vektorfelder in einem Sammlungsschema definieren. Details zu den Beschränkungen für die Anzahl der in einer Sammlung zulässigen Vektorfelder finden Sie unter Zilliz Cloud Limits. Falls erforderlich, können Sie jedoch die proxy.maxVectorFieldNum anpassen, um bei Bedarf bis zu 10 Vektorfelder in eine Sammlung aufzunehmen.
In diesem Beispiel werden die folgenden Felder in das Schema aufgenommen:
id: Dient als Primärschlüssel für die Speicherung von Text-IDs. Dieses Feld ist vom DatentypINT64.text: Dient zur Speicherung von Textinhalten. Dieses Feld hat den DatentypVARCHARmit einer maximalen Länge von 1000 Bytes. Die Optionenable_analyzerwird aufTruegesetzt, um die Volltextsuche zu erleichtern.text_dense: Dient zur Speicherung von dichten Vektoren der Texte. Dieses Feld hat den DatentypFLOAT_VECTORmit einer Vektordimension von 768.text_sparse: Dient zur Speicherung von spärlichen Vektoren der Texte. Dieses Feld hat den DatentypSPARSE_FLOAT_VECTOR.image_dense: Zur Speicherung von dichten Vektoren der Produktbilder. Dieses Feld hat den DatentypFLOAT_VETORmit einer Vektordimension von 512.
Da wir den eingebauten Algorithmus BM25 verwenden werden, um eine Volltextsuche im Textfeld durchzuführen, ist es notwendig, das Schema um den Milvus Function zu erweitern. Weitere Einzelheiten finden Sie unter Volltextsuche.
from pymilvus import (
MilvusClient, DataType, Function, FunctionType
)
client = MilvusClient(
uri="http://localhost:19530",
token="root:Milvus"
)
# Init schema with auto_id disabled
schema = client.create_schema(auto_id=False)
# Add fields to schema
schema.add_field(field_name="id", datatype=DataType.INT64, is_primary=True, description="product id")
schema.add_field(field_name="text", datatype=DataType.VARCHAR, max_length=1000, enable_analyzer=True, description="raw text of product description")
schema.add_field(field_name="text_dense", datatype=DataType.FLOAT_VECTOR, dim=768, description="text dense embedding")
schema.add_field(field_name="text_sparse", datatype=DataType.SPARSE_FLOAT_VECTOR, description="text sparse embedding auto-generated by the built-in BM25 function")
schema.add_field(field_name="image_dense", datatype=DataType.FLOAT_VECTOR, dim=512, description="image dense embedding")
# Add function to schema
bm25_function = Function(
name="text_bm25_emb",
input_field_names=["text"],
output_field_names=["text_sparse"],
function_type=FunctionType.BM25,
)
schema.add_function(bm25_function)
import io.milvus.v2.client.ConnectConfig;
import io.milvus.v2.client.MilvusClientV2;
import io.milvus.v2.common.DataType;
import io.milvus.common.clientenum.FunctionType;
import io.milvus.v2.service.collection.request.AddFieldReq;
import io.milvus.v2.service.collection.request.CreateCollectionReq;
import io.milvus.v2.service.collection.request.CreateCollectionReq.Function;
import java.util.*;
MilvusClientV2 client = new MilvusClientV2(ConnectConfig.builder()
.uri("http://localhost:19530")
.token("root:Milvus")
.build());
CreateCollectionReq.CollectionSchema schema = client.createSchema();
schema.addField(AddFieldReq.builder()
.fieldName("id")
.dataType(DataType.Int64)
.isPrimaryKey(true)
.autoID(false)
.build());
schema.addField(AddFieldReq.builder()
.fieldName("text")
.dataType(DataType.VarChar)
.maxLength(1000)
.enableAnalyzer(true)
.build());
schema.addField(AddFieldReq.builder()
.fieldName("text_dense")
.dataType(DataType.FloatVector)
.dimension(768)
.build());
schema.addField(AddFieldReq.builder()
.fieldName("text_sparse")
.dataType(DataType.SparseFloatVector)
.build());
schema.addField(AddFieldReq.builder()
.fieldName("image_dense")
.dataType(DataType.FloatVector)
.dimension(512)
.build());
schema.addFunction(Function.builder()
.functionType(FunctionType.BM25)
.name("text_bm25_emb")
.inputFieldNames(Collections.singletonList("text"))
.outputFieldNames(Collections.singletonList("text_sparse"))
.build());
import (
"context"
"fmt"
"github.com/milvus-io/milvus/client/v2/column"
"github.com/milvus-io/milvus/client/v2/entity"
"github.com/milvus-io/milvus/client/v2/index"
"github.com/milvus-io/milvus/client/v2/milvusclient"
)
ctx, cancel := context.WithCancel(context.Background())
defer cancel()
milvusAddr := "localhost:19530"
client, err := milvusclient.New(ctx, &milvusclient.ClientConfig{
Address: milvusAddr,
})
if err != nil {
fmt.Println(err.Error())
// handle error
}
defer client.Close(ctx)
function := entity.NewFunction().
WithName("text_bm25_emb").
WithInputFields("text").
WithOutputFields("text_sparse").
WithType(entity.FunctionTypeBM25)
schema := entity.NewSchema()
schema.WithField(entity.NewField().
WithName("id").
WithDataType(entity.FieldTypeInt64).
WithIsPrimaryKey(true),
).WithField(entity.NewField().
WithName("text").
WithDataType(entity.FieldTypeVarChar).
WithEnableAnalyzer(true).
WithMaxLength(1000),
).WithField(entity.NewField().
WithName("text_dense").
WithDataType(entity.FieldTypeFloatVector).
WithDim(768),
).WithField(entity.NewField().
WithName("text_sparse").
WithDataType(entity.FieldTypeSparseVector),
).WithField(entity.NewField().
WithName("image_dense").
WithDataType(entity.FieldTypeFloatVector).
WithDim(512),
).WithFunction(function)
import { MilvusClient, DataType } from "@zilliz/milvus2-sdk-node";
const address = "http://localhost:19530";
const token = "root:Milvus";
const client = new MilvusClient({address, token});
// Define fields
const fields = [
{
name: "id",
data_type: DataType.Int64,
is_primary_key: true,
auto_id: false
},
{
name: "text",
data_type: DataType.VarChar,
max_length: 1000,
enable_match: true
},
{
name: "text_dense",
data_type: DataType.FloatVector,
dim: 768
},
{
name: "text_sparse",
data_type: DataType.SPARSE_FLOAT_VECTOR
},
{
name: "image_dense",
data_type: DataType.FloatVector,
dim: 512
}
];
// define function
const functions = [
{
name: "text_bm25_emb",
description: "text bm25 function",
type: FunctionType.BM25,
input_field_names: ["text"],
output_field_names: ["text_sparse"],
params: {},
},
];
export bm25Function='{
"name": "text_bm25_emb",
"type": "BM25",
"inputFieldNames": ["text"],
"outputFieldNames": ["text_sparse"],
"params": {}
}'
export schema='{
"autoId": false,
"functions": [$bm25Function],
"fields": [
{
"fieldName": "id",
"dataType": "Int64",
"isPrimary": true
},
{
"fieldName": "text",
"dataType": "VarChar",
"elementTypeParams": {
"max_length": 1000,
"enable_analyzer": true
}
},
{
"fieldName": "text_dense",
"dataType": "FloatVector",
"elementTypeParams": {
"dim": "768"
}
},
{
"fieldName": "text_sparse",
"dataType": "SparseFloatVector"
},
{
"fieldName": "image_dense",
"dataType": "FloatVector",
"elementTypeParams": {
"dim": "512"
}
}
]
}'
Index erstellen
Nach der Definition des Sammlungsschemas ist der nächste Schritt, die Vektorindizes zu konfigurieren und die Ähnlichkeitsmetriken festzulegen. Im gegebenen Beispiel:
text_dense_index: wird ein Index vom TypAUTOINDEXmit dem Metrik-TypIPfür das Text-Density-Vektorfeld erstellt.text_sparse_indexEin Index des TypsSPARSE_INVERTED_INDEXmit dem Metrik-TypBM25wird für das Text-Sparse-Vektorfeld verwendet.image_dense_indexEin Index vom TypAUTOINDEXmit dem metrischen TypIPwird für das dichte Bildvektorfeld erstellt.
Sie können andere Indextypen wählen, die Ihren Bedürfnissen und Datentypen am besten entsprechen. Weitere Informationen zu den unterstützten Indextypen finden Sie in der Dokumentation zu den verfügbaren Indextypen.
# Prepare index parameters
index_params = client.prepare_index_params()
# Add indexes
index_params.add_index(
field_name="text_dense",
index_name="text_dense_index",
index_type="AUTOINDEX",
metric_type="IP"
)
index_params.add_index(
field_name="text_sparse",
index_name="text_sparse_index",
index_type="SPARSE_INVERTED_INDEX",
metric_type="BM25",
params={"inverted_index_algo": "DAAT_MAXSCORE"}, # or "DAAT_WAND" or "TAAT_NAIVE"
)
index_params.add_index(
field_name="image_dense",
index_name="image_dense_index",
index_type="AUTOINDEX",
metric_type="IP"
)
import io.milvus.v2.common.IndexParam;
import java.util.*;
Map<String, Object> denseParams = new HashMap<>();
IndexParam indexParamForTextDense = IndexParam.builder()
.fieldName("text_dense")
.indexName("text_dense_index")
.indexType(IndexParam.IndexType.AUTOINDEX)
.metricType(IndexParam.MetricType.IP)
.build();
Map<String, Object> sparseParams = new HashMap<>();
sparseParams.put("inverted_index_algo": "DAAT_MAXSCORE");
IndexParam indexParamForTextSparse = IndexParam.builder()
.fieldName("text_sparse")
.indexName("text_sparse_index")
.indexType(IndexParam.IndexType.SPARSE_INVERTED_INDEX)
.metricType(IndexParam.MetricType.BM25)
.extraParams(sparseParams)
.build();
IndexParam indexParamForImageDense = IndexParam.builder()
.fieldName("image_dense")
.indexName("image_dense_index")
.indexType(IndexParam.IndexType.AUTOINDEX)
.metricType(IndexParam.MetricType.IP)
.build();
List<IndexParam> indexParams = new ArrayList<>();
indexParams.add(indexParamForTextDense);
indexParams.add(indexParamForTextSparse);
indexParams.add(indexParamForImageDense);
indexOption1 := milvusclient.NewCreateIndexOption("my_collection", "text_dense",
index.NewAutoIndex(index.MetricType(entity.IP)))
indexOption2 := milvusclient.NewCreateIndexOption("my_collection", "text_sparse",
index.NewSparseInvertedIndex(entity.BM25, 0.2))
indexOption3 := milvusclient.NewCreateIndexOption("my_collection", "image_dense",
index.NewAutoIndex(index.MetricType(entity.IP)))
)
const index_params = [{
field_name: "text_dense",
index_name: "text_dense_index",
index_type: "AUTOINDEX",
metric_type: "IP"
},{
field_name: "text_sparse",
index_name: "text_sparse_index",
index_type: "IndexType.SPARSE_INVERTED_INDEX",
metric_type: "BM25",
params: {
inverted_index_algo: "DAAT_MAXSCORE",
}
},{
field_name: "image_dense",
index_name: "image_dense_index",
index_type: "AUTOINDEX",
metric_type: "IP"
}]
export indexParams='[
{
"fieldName": "text_dense",
"metricType": "IP",
"indexName": "text_dense_index",
"indexType":"AUTOINDEX"
},
{
"fieldName": "text_sparse",
"metricType": "BM25",
"indexName": "text_sparse_index",
"indexType": "SPARSE_INVERTED_INDEX",
"params":{"inverted_index_algo": "DAAT_MAXSCORE"}
},
{
"fieldName": "image_dense",
"metricType": "IP",
"indexName": "image_dense_index",
"indexType":"AUTOINDEX"
}
]'
Sammlung erstellen
Erstellen Sie eine Sammlung mit dem Namen demo mit dem Sammlungsschema und den Indizes, die in den beiden vorherigen Schritten konfiguriert wurden.
client.create_collection(
collection_name="my_collection",
schema=schema,
index_params=index_params
)
CreateCollectionReq createCollectionReq = CreateCollectionReq.builder()
.collectionName("my_collection")
.collectionSchema(schema)
.indexParams(indexParams)
.build();
client.createCollection(createCollectionReq);
err = client.CreateCollection(ctx,
milvusclient.NewCreateCollectionOption("my_collection", schema).
WithIndexOptions(indexOption1, indexOption2))
if err != nil {
fmt.Println(err.Error())
// handle error
}
res = await client.createCollection({
collection_name: "my_collection",
fields: fields,
index_params: index_params,
})
export CLUSTER_ENDPOINT="http://localhost:19530"
export TOKEN="root:Milvus"
curl --request POST \
--url "${CLUSTER_ENDPOINT}/v2/vectordb/collections/create" \
--header "Authorization: Bearer ${TOKEN}" \
--header "Content-Type: application/json" \
--header "Request-Timeout: 10" \
-d "{
\"collectionName\": \"my_collection\",
\"schema\": $schema,
\"indexParams\": $indexParams
}"
Daten einfügen
In diesem Abschnitt werden Daten in die Sammlung my_collection eingefügt, basierend auf dem zuvor definierten Schema. Stellen Sie beim Einfügen sicher, dass alle Felder mit Ausnahme der Felder mit automatisch generierten Werten mit Daten im richtigen Format versehen sind. In diesem Beispiel:
id: eine Ganzzahl, die die Produkt-ID darstellttexteine Zeichenkette, die die Produktbezeichnung enthälttext_denseeine Liste von 768 Gleitkommawerten, die die dichte Einbettung der Textbeschreibung darstellenimage_denseeine Liste von 512 Fließkommawerten, die die dichte Einbettung des Produktbildes darstellen
Sie können die gleichen oder unterschiedliche Modelle verwenden, um die dichte Einbettung für jedes Feld zu erzeugen. In diesem Beispiel haben die beiden dichten Einbettungen unterschiedliche Dimensionen, was darauf hindeutet, dass sie von unterschiedlichen Modellen erzeugt wurden. Achten Sie bei der späteren Definition jeder Suche darauf, dass Sie das entsprechende Modell verwenden, um die passende Abfrageeinbettung zu erzeugen.
Da in diesem Beispiel die eingebaute Funktion BM25 verwendet wird, um Sparse Embeddings aus dem Textfeld zu generieren, müssen Sie Sparse-Vektoren nicht manuell eingeben. Wenn Sie sich jedoch dafür entscheiden, BM25 nicht zu verwenden, müssen Sie die Sparse Embeddings selbst vorberechnen und bereitstellen.
import random
# Generate example vectors
def generate_dense_vector(dim):
return [random.random() for _ in range(dim)]
data=[
{
"id": 0,
"text": "Red cotton t-shirt with round neck",
"text_dense": generate_dense_vector(768),
"image_dense": generate_dense_vector(512)
},
{
"id": 1,
"text": "Wireless noise-cancelling over-ear headphones",
"text_dense": generate_dense_vector(768),
"image_dense": generate_dense_vector(512)
},
{
"id": 2,
"text": "Stainless steel water bottle, 500ml",
"text_dense": generate_dense_vector(768),
"image_dense": generate_dense_vector(512)
}
]
res = client.insert(
collection_name="my_collection",
data=data
)
import com.google.gson.Gson;
import com.google.gson.JsonObject;
import io.milvus.v2.service.vector.request.InsertReq;
Gson gson = new Gson();
JsonObject row1 = new JsonObject();
row1.addProperty("id", 0);
row1.addProperty("text", "Red cotton t-shirt with round neck");
row1.add("text_dense", gson.toJsonTree(text_dense1));
row1.add("image_dense", gson.toJsonTree(image_dense));
JsonObject row2 = new JsonObject();
row2.addProperty("id", 1);
row2.addProperty("text", "Wireless noise-cancelling over-ear headphones");
row2.add("text_dense", gson.toJsonTree(text_dense2));
row2.add("image_dense", gson.toJsonTree(image_dense2));
JsonObject row3 = new JsonObject();
row3.addProperty("id", 2);
row3.addProperty("text", "Stainless steel water bottle, 500ml");
row3.add("text_dense", gson.toJsonTree(dense3));
row3.add("image_dense", gson.toJsonTree(sparse3));
List<JsonObject> data = Arrays.asList(row1, row2, row3);
InsertReq insertReq = InsertReq.builder()
.collectionName("my_collection")
.data(data)
.build();
InsertResp insertResp = client.insert(insertReq);
_, err = client.Insert(ctx, milvusclient.NewColumnBasedInsertOption("my_collection").
WithInt64Column("id", []int64{0, 1, 2}).
WithVarcharColumn("text", []string{
"Red cotton t-shirt with round neck",
"Wireless noise-cancelling over-ear headphones",
"Stainless steel water bottle, 500ml",
}).
WithFloatVectorColumn("text_dense", 768, [][]float32{
{0.3580376395471989, -0.6023495712049978, 0.18414012509913835, ...},
{0.19886812562848388, 0.06023560599112088, 0.6976963061752597, ...},
{0.43742130801983836, -0.5597502546264526, 0.6457887650909682, ...},
}).
WithFloatVectorColumn("image_dense", 512, [][]float32{
{0.6366019600530924, -0.09323198122475052, ...},
{0.6414180010301553, 0.8976979978567611, ...},
{-0.6901259768402174, 0.6100500332193755, ...},
}).
if err != nil {
fmt.Println(err.Error())
// handle err
}
const { MilvusClient, DataType } = require("@zilliz/milvus2-sdk-node")
var data = [
{id: 0, text: "Red cotton t-shirt with round neck" , text_dense: [0.3580376395471989, -0.6023495712049978, 0.18414012509913835, ...], image_dense: [0.6366019600530924, -0.09323198122475052, ...]},
{id: 1, text: "Wireless noise-cancelling over-ear headphones" , text_dense: [0.19886812562848388, 0.06023560599112088, 0.6976963061752597, ...], image_dense: [0.6414180010301553, 0.8976979978567611, ...]},
{id: 2, text: "Stainless steel water bottle, 500ml" , text_dense: [0.43742130801983836, -0.5597502546264526, 0.6457887650909682, ...], image_dense: [-0.6901259768402174, 0.6100500332193755, ...]}
]
var res = await client.insert({
collection_name: "my_collection",
data: data,
})
curl --request POST \
--url "${CLUSTER_ENDPOINT}/v2/vectordb/entities/insert" \
--header "Authorization: Bearer ${TOKEN}" \
--header "Content-Type: application/json" \
--header "Request-Timeout: 10" \
-d '{
"data": [
{"id": 0, "text": "Red cotton t-shirt with round neck" , "text_dense": [0.3580376395471989, -0.6023495712049978, 0.18414012509913835, ...], "image_dense": [0.6366019600530924, -0.09323198122475052, ...]},
{"id": 1, "text": "Wireless noise-cancelling over-ear headphones" , "text_dense": [0.19886812562848388, 0.06023560599112088, 0.6976963061752597, ...], "image_dense": [0.6414180010301553, 0.8976979978567611, ...]},
{"id": 2, "text": "Stainless steel water bottle, 500ml" , "text_dense": [0.43742130801983836, -0.5597502546264526, 0.6457887650909682, ...], "image_dense": [-0.6901259768402174, 0.6100500332193755, ...]}
],
"collectionName": "my_collection"
}'
Hybride Suche durchführen
Schritt 1: Erstellen mehrerer AnnSearchRequest-Instanzen
Die hybride Suche wird durch die Erstellung mehrerer AnnSearchRequest in der Funktion hybrid_search() implementiert, wobei jede AnnSearchRequest eine grundlegende ANN-Suchanfrage für ein bestimmtes Vektorfeld darstellt. Daher muss vor der Durchführung einer Hybrid Search für jedes Vektorfeld eine AnnSearchRequest erstellt werden.
Darüber hinaus können Sie durch die Konfiguration des Parameters expr in einer AnnSearchRequest die Filterbedingungen für Ihre hybride Suche festlegen. Weitere Informationen finden Sie unter Gefilterte Suche und Filterung erklärt.
Bei der hybriden Suche unterstützt jede AnnSearchRequest nur eine Abfrage.
Um die Möglichkeiten der verschiedenen Suchvektorfelder zu demonstrieren, werden wir drei AnnSearchRequest Suchanfragen mit einer Beispielabfrage erstellen. Wir werden auch die vorberechneten dichten Vektoren für diesen Prozess verwenden. Die Suchanfragen werden auf die folgenden Vektorfelder abzielen:
text_densefür die semantische Textsuche, die ein kontextuelles Verständnis und eine Suche auf der Grundlage der Bedeutung statt eines direkten Schlüsselwortabgleichs ermöglicht.text_sparsefür die Volltextsuche oder den Abgleich von Schlüsselwörtern, wobei der Schwerpunkt auf exakten Wort- oder Satzübereinstimmungen innerhalb des Textes liegt.image_densefür die multimodale Text-Bild-Suche, um relevante Produktbilder auf der Grundlage des semantischen Inhalts der Suchanfrage zu finden.
from pymilvus import AnnSearchRequest
query_text = "white headphones, quiet and comfortable"
query_dense_vector = generate_dense_vector(768)
query_multimodal_vector = generate_dense_vector(512)
# text semantic search (dense)
search_param_1 = {
"data": [query_dense_vector],
"anns_field": "text_dense",
"param": {"nprobe": 10},
"limit": 2
}
request_1 = AnnSearchRequest(**search_param_1)
# full-text search (sparse)
search_param_2 = {
"data": [query_text],
"anns_field": "text_sparse",
"limit": 2
}
request_2 = AnnSearchRequest(**search_param_2)
# text-to-image search (multimodal)
search_param_3 = {
"data": [query_multimodal_vector],
"anns_field": "image_dense",
"param": {"nprobe": 10},
"limit": 2
}
request_3 = AnnSearchRequest(**search_param_3)
reqs = [request_1, request_2, request_3]
import io.milvus.v2.service.vector.request.AnnSearchReq;
import io.milvus.v2.service.vector.request.data.BaseVector;
import io.milvus.v2.service.vector.request.data.FloatVec;
import io.milvus.v2.service.vector.request.data.SparseFloatVec;
import io.milvus.v2.service.vector.request.data.EmbeddedText;
float[] queryDense = new float[]{-0.0475336798f, 0.0521207601f, 0.0904406682f, ...};
float[] queryMultimodal = new float[]{0.0158298651f, 0.5264158340f, ...}
List<BaseVector> queryTexts = Collections.singletonList(new EmbeddedText("white headphones, quiet and comfortable");)
List<BaseVector> queryDenseVectors = Collections.singletonList(new FloatVec(queryDense));
List<BaseVector> queryMultimodalVectors = Collections.singletonList(new FloatVec(queryMultimodal));
List<AnnSearchReq> searchRequests = new ArrayList<>();
searchRequests.add(AnnSearchReq.builder()
.vectorFieldName("text_dense")
.vectors(queryDenseVectors)
.params("{\"nprobe\": 10}")
.topK(2)
.build());
searchRequests.add(AnnSearchReq.builder()
.vectorFieldName("text_sparse")
.vectors(queryTexts)
.topK(2)
.build());
searchRequests.add(AnnSearchReq.builder()
.vectorFieldName("image_dense")
.vectors(queryMultimodalVectors)
.params("{\"nprobe\": 10}")
.topK(2)
.build());
queryText := entity.Text({"white headphones, quiet and comfortable"})
queryVector := []float32{0.3580376395471989, -0.6023495712049978, 0.18414012509913835, ...}
queryMultimodalVector := []float32{0.015829865178701663, 0.5264158340734488, ...}
request1 := milvusclient.NewAnnRequest("text_dense", 2, entity.FloatVector(queryVector)).
WithAnnParam(index.NewIvfAnnParam(10))
annParam := index.NewSparseAnnParam()
annParam.WithDropRatio(0.2)
request2 := milvusclient.NewAnnRequest("text_sparse", 2, queryText).
WithAnnParam(annParam)
request3 := milvusclient.NewAnnRequest("image_dense", 2, entity.FloatVector(queryMultimodalVector)).
WithAnnParam(index.NewIvfAnnParam(10))
const query_text = "white headphones, quiet and comfortable"
const query_vector = [0.3580376395471989, -0.6023495712049978, 0.18414012509913835, ...]
const query_multimodal_vector = [0.015829865178701663, 0.5264158340734488, ...]
const search_param_1 = {
"data": query_vector,
"anns_field": "text_dense",
"param": {"nprobe": 10},
"limit": 2
}
const search_param_2 = {
"data": query_text,
"anns_field": "text_sparse",
"limit": 2
}
const search_param_3 = {
"data": query_multimodal_vector,
"anns_field": "image_dense",
"param": {"nprobe": 10},
"limit": 2
}
export req='[
{
"data": [[0.3580376395471989, -0.6023495712049978, 0.18414012509913835, ...]],
"annsField": "text_dense",
"params": {"nprobe": 10},
"limit": 2
},
{
"data": ["white headphones, quiet and comfortable"],
"annsField": "text_sparse",
"limit": 2
},
{
"data": [[0.015829865178701663, 0.5264158340734488, ...]],
"annsField": "image_dense",
"params": {"nprobe": 10},
"limit": 2
}
]'
Da der Parameter limit auf 2 gesetzt ist, liefert jede AnnSearchRequest 2 Suchergebnisse. In diesem Beispiel werden 3 AnnSearchRequest Instanzen erstellt, was zu insgesamt 6 Suchergebnissen führt.
Schritt 2: Konfigurieren Sie eine Ranglistenstrategie
Um die ANN-Suchergebnissätze zusammenzuführen und neu zu ordnen, ist die Auswahl einer geeigneten Rangordnungsstrategie unerlässlich. Milvus bietet mehrere Arten von Ranking-Strategien an. Weitere Einzelheiten zu diesen Ranking-Mechanismen finden Sie unter Weighted Ranker oder RRF Ranker.
Da in diesem Beispiel kein besonderer Schwerpunkt auf bestimmte Suchanfragen gelegt wird, werden wir mit der RRFRanker-Strategie arbeiten.
ranker = Function(
name="rrf",
input_field_names=[], # Must be an empty list
function_type=FunctionType.RERANK,
params={
"reranker": "rrf",
"k": 100 # Optional
}
)
import io.milvus.common.clientenum.FunctionType;
import io.milvus.v2.service.collection.request.CreateCollectionReq.Function;
Function ranker = Function.builder()
.name("rrf")
.functionType(FunctionType.RERANK)
.param("reranker", "rrf")
.param("k", "100")
.build()
const rerank = {
name: 'rrf',
description: 'bm25 function',
type: FunctionType.RERANK,
input_field_names: [],
params: {
"reranker": "rrf",
"k": 100
},
};
import (
"github.com/milvus-io/milvus/client/v2/entity"
)
ranker := entity.NewFunction().
WithName("rrf").
WithType(entity.FunctionTypeRerank).
WithParam("reranker", "rrf").
WithParam("k", "100")
# Restful
export functionScore='{
"functions": [
{
"name": "rrf",
"type": "Rerank",
"inputFieldNames": [],
"params": {
"reranker": "rrf",
"k": 100
}
}
]
}'
Schritt 3: Durchführen einer hybriden Suche
Bevor Sie eine hybride Suche starten, stellen Sie sicher, dass die Sammlung geladen ist. Wenn die Vektorfelder in der Sammlung keinen Index haben oder nicht in den Speicher geladen sind, wird bei der Ausführung der Methode Hybrid Search ein Fehler auftreten.
res = client.hybrid_search(
collection_name="my_collection",
reqs=reqs,
ranker=ranker,
limit=2
)
for hits in res:
print("TopK results:")
for hit in hits:
print(hit)
import io.milvus.v2.common.ConsistencyLevel;
import io.milvus.v2.service.vector.request.HybridSearchReq;
import io.milvus.v2.service.vector.response.SearchResp;
HybridSearchReq hybridSearchReq = HybridSearchReq.builder()
.collectionName("my_collection")
.searchRequests(searchRequests)
.ranker(reranker)
.topK(2)
.build();
SearchResp searchResp = client.hybridSearch(hybridSearchReq);
resultSets, err := client.HybridSearch(ctx, milvusclient.NewHybridSearchOption(
"my_collection",
2,
request1,
request2,
request3,
).WithReranker(reranker))
if err != nil {
fmt.Println(err.Error())
// handle error
}
for _, resultSet := range resultSets {
fmt.Println("IDs: ", resultSet.IDs.FieldData().GetScalars())
fmt.Println("Scores: ", resultSet.Scores)
}
const { MilvusClient, DataType } = require("@zilliz/milvus2-sdk-node")
res = await client.loadCollection({
collection_name: "my_collection"
})
import { MilvusClient, RRFRanker, WeightedRanker } from '@zilliz/milvus2-sdk-node';
const search = await client.search({
collection_name: "my_collection",
data: [search_param_1, search_param_2, search_param_3],
limit: 2,
rerank: rerank
});
curl --request POST \
--url "${CLUSTER_ENDPOINT}/v2/vectordb/entities/hybrid_search" \
--header "Authorization: Bearer ${TOKEN}" \
--header "Content-Type: application/json" \
--header "Request-Timeout: 10" \
-d "{
\"collectionName\": \"my_collection\",
\"search\": ${req},
\"rerank\": {
\"strategy\":\"rrf\",
\"params\": ${rerank}
},
\"limit\": 2
}"
Die Ausgabe sieht folgendermaßen aus:
["['id: 1, distance: 0.006047376897186041, entity: {}', 'id: 2, distance: 0.006422005593776703, entity: {}']"]
Mit dem Parameter limit=2, der für die hybride Suche angegeben wurde, ordnet Milvus die sechs Ergebnisse aus den drei Suchvorgängen neu an. Letztendlich werden nur die beiden ähnlichsten Ergebnisse zurückgegeben.
Erweiterte Verwendung
Vorübergehend eine Zeitzone für eine hybride Suche festlegen
Wenn Ihre Sammlung ein Feld TIMESTAMPTZ hat, können Sie die Standardzeitzone der Datenbank oder Sammlung für einen einzelnen Vorgang vorübergehend außer Kraft setzen, indem Sie den Parameter timezone im Aufruf der Hybridsuche setzen. Dies steuert, wie TIMESTAMPTZ Werte während des Vorgangs angezeigt und verglichen werden.
Der Wert von timezone muss eine gültige IANA-Zeitzonenkennung sein (z. B. Asien/Shanghai, Amerika/Chicago oder UTC). Einzelheiten zur Verwendung des Feldes TIMESTAMPTZ finden Sie unter TIMESTAMPTZ-Feld.
Das folgende Beispiel zeigt, wie eine Zeitzone für einen hybriden Suchvorgang vorübergehend festgelegt wird:
res = client.hybrid_search(
collection_name="my_collection",
reqs=reqs,
ranker=ranker,
limit=2,
timezone="America/Havana",
)