مسترجع البحث الهجين ميلفوس الهجين
يجمع البحث الهجين بين نقاط القوة في نماذج البحث المختلفة لتعزيز دقة الاسترجاع وقوته. فهو يستفيد من إمكانيات كل من البحث المتجه الكثيف المتجه والبحث المتجه المتناثر، بالإضافة إلى مجموعات من استراتيجيات البحث المتجه الكثيف المتعددة، مما يضمن استرجاعًا شاملاً ودقيقًا لاستعلامات متنوعة.
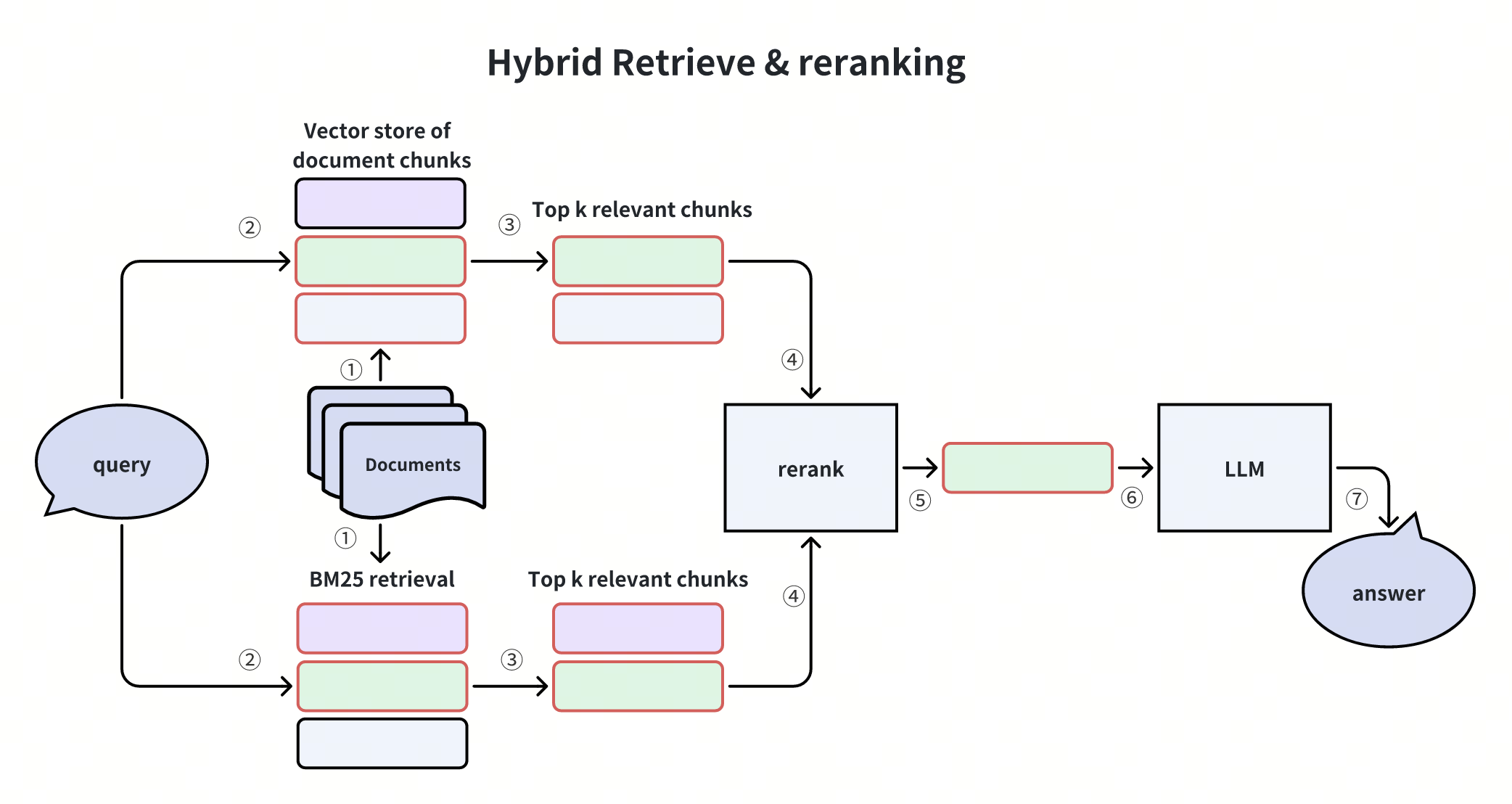
يوضح هذا الرسم البياني سيناريو البحث الهجين الأكثر شيوعًا، وهو البحث الهجين الكثيف + البحث الهجين المتناثر. في هذه الحالة، يتم استرداد المرشحين باستخدام كل من تشابه المتجهات الدلالية ومطابقة الكلمات الرئيسية الدقيقة. يتم دمج النتائج من هاتين الطريقتين وإعادة ترتيبها وتمريرها إلى جهاز البحث الدلالي لتوليد الإجابة النهائية. يوازن هذا النهج بين الدقة والفهم الدلالي، مما يجعله فعالاً للغاية في سيناريوهات الاستعلام المتنوعة.
بالإضافة إلى البحث الهجين الكثيف + المتناثر، يمكن للاستراتيجيات الهجينة أيضًا الجمع بين نماذج متجهات كثيفة متعددة. على سبيل المثال، قد يتخصص أحد نماذج المتجهات الكثيفة في التقاط الفروق الدلالية الدقيقة، بينما يركز نموذج آخر على التضمينات السياقية أو التمثيلات الخاصة بالمجال. من خلال دمج النتائج من هذه النماذج وإعادة ترتيبها، يضمن هذا النوع من البحث الهجين عملية استرجاع أكثر دقة وإدراكًا للسياق.
يوفر تكامل LangChain Milvus طريقة مرنة لتنفيذ البحث الهجين، فهو يدعم أي عدد من حقول المتجهات، وأي نماذج تضمين كثيفة أو متفرقة مخصصة، مما يسمح لـ LangChain Milvus بالتكيف بمرونة مع سيناريوهات استخدام البحث الهجين المختلفة، وفي نفس الوقت متوافق مع القدرات الأخرى لـ LangChain.
في هذا البرنامج التعليمي، سنبدأ بالحالة الأكثر شيوعًا كثيفة + متناثرة، ثم نقدم أي عدد من أساليب استخدام البحث الهجين العامة.
سيتم إهمال MilvusCollectionHybridSearchRetriever، وهو تطبيق آخر للبحث الهجين مع Milvus وLangChain، وهو على وشك الإهمال. يُرجى استخدام النهج الوارد في هذا المستند لتنفيذ البحث الهجين لأنه أكثر مرونة وتوافقًا مع LangChain.
المتطلبات الأساسية
قبل تشغيل هذا الدفتر، تأكد من تثبيت التبعيات التالية:
$ pip install --upgrade --quiet langchain langchain-core langchain-community langchain-text-splitters langchain-milvus langchain-openai bs4 pymilvus[model] #langchain-voyageai
إذا كنت تستخدم Google Colab، لتمكين التبعيات المثبتة للتو، قد تحتاج إلى إعادة تشغيل وقت التشغيل (انقر على قائمة "وقت التشغيل" في أعلى الشاشة، وحدد "إعادة تشغيل الجلسة" من القائمة المنسدلة).
سنستخدم النماذج من OpenAI. يجب عليك إعداد متغيرات البيئة OPENAI_API_KEY من OpenAI.
import os
os.environ["OPENAI_API_KEY"] = "sk-***********"
حدد خادم Milvus URI (واختيارياً TOKEN). لمعرفة كيفية تثبيت خادم ميلفوس وبدء تشغيله باتباع هذا الدليل.
URI = "http://localhost:19530"
# TOKEN = ...
قم بإعداد بعض الأمثلة على المستندات، وهي عبارة عن ملخصات قصص خيالية مصنفة حسب الموضوع أو النوع.
from langchain_core.documents import Document
docs = [
Document(
page_content="In 'The Whispering Walls' by Ava Moreno, a young journalist named Sophia uncovers a decades-old conspiracy hidden within the crumbling walls of an ancient mansion, where the whispers of the past threaten to destroy her own sanity.",
metadata={"category": "Mystery"},
),
Document(
page_content="In 'The Last Refuge' by Ethan Blackwood, a group of survivors must band together to escape a post-apocalyptic wasteland, where the last remnants of humanity cling to life in a desperate bid for survival.",
metadata={"category": "Post-Apocalyptic"},
),
Document(
page_content="In 'The Memory Thief' by Lila Rose, a charismatic thief with the ability to steal and manipulate memories is hired by a mysterious client to pull off a daring heist, but soon finds themselves trapped in a web of deceit and betrayal.",
metadata={"category": "Heist/Thriller"},
),
Document(
page_content="In 'The City of Echoes' by Julian Saint Clair, a brilliant detective must navigate a labyrinthine metropolis where time is currency, and the rich can live forever, but at a terrible cost to the poor.",
metadata={"category": "Science Fiction"},
),
Document(
page_content="In 'The Starlight Serenade' by Ruby Flynn, a shy astronomer discovers a mysterious melody emanating from a distant star, which leads her on a journey to uncover the secrets of the universe and her own heart.",
metadata={"category": "Science Fiction/Romance"},
),
Document(
page_content="In 'The Shadow Weaver' by Piper Redding, a young orphan discovers she has the ability to weave powerful illusions, but soon finds herself at the center of a deadly game of cat and mouse between rival factions vying for control of the mystical arts.",
metadata={"category": "Fantasy"},
),
Document(
page_content="In 'The Lost Expedition' by Caspian Grey, a team of explorers ventures into the heart of the Amazon rainforest in search of a lost city, but soon finds themselves hunted by a ruthless treasure hunter and the treacherous jungle itself.",
metadata={"category": "Adventure"},
),
Document(
page_content="In 'The Clockwork Kingdom' by Augusta Wynter, a brilliant inventor discovers a hidden world of clockwork machines and ancient magic, where a rebellion is brewing against the tyrannical ruler of the land.",
metadata={"category": "Steampunk/Fantasy"},
),
Document(
page_content="In 'The Phantom Pilgrim' by Rowan Welles, a charismatic smuggler is hired by a mysterious organization to transport a valuable artifact across a war-torn continent, but soon finds themselves pursued by deadly assassins and rival factions.",
metadata={"category": "Adventure/Thriller"},
),
Document(
page_content="In 'The Dreamwalker's Journey' by Lyra Snow, a young dreamwalker discovers she has the ability to enter people's dreams, but soon finds herself trapped in a surreal world of nightmares and illusions, where the boundaries between reality and fantasy blur.",
metadata={"category": "Fantasy"},
),
]
التضمين الكثيف + التضمين المتناثر
الخيار 1 (موصى به): التضمين الكثيف + الدالة المدمجة ميلفوس BM25
استخدم التضمين الكثيف + الدالة المدمجة Milvus BM25 لتجميع مثيل مخزن متجه الاسترجاع الهجين.
from langchain_milvus import Milvus, BM25BuiltInFunction
from langchain_openai import OpenAIEmbeddings
vectorstore = Milvus.from_documents(
documents=docs,
embedding=OpenAIEmbeddings(),
builtin_function=BM25BuiltInFunction(), # output_field_names="sparse"),
vector_field=["dense", "sparse"],
connection_args={
"uri": URI,
},
consistency_level="Bounded", # Supported values are (`"Strong"`, `"Session"`, `"Bounded"`, `"Eventually"`). See https://milvus.io/docs/tune_consistency.md#Consistency-Level for more details.
drop_old=False,
)
- عند استخدام
BM25BuiltInFunction، يُرجى ملاحظة أن البحث في النص الكامل متاح في Milvus Standalone وMilvus Distributed، ولكن ليس في Milvus Lite، على الرغم من أنه على خارطة الطريق لإدراجه في المستقبل. سيكون متاحًا أيضًا في Zilliz Cloud (ميلفوس المدارة بالكامل) قريبًا. يرجى التواصل مع support@zilliz.com لمزيد من المعلومات.
في الكود أعلاه، نحدد مثيلًا لـ BM25BuiltInFunction ونمرره إلى الكائن Milvus. BM25BuiltInFunction هي فئة غلاف خفيفة الوزن لـ Function في ميلفوس. يمكننا استخدامه مع OpenAIEmbeddings لتهيئة مثيل مخزن متجه البحث الهجين الكثيف + المتناثر Milvus للبحث الهجين Milvus.
BM25BuiltInFunction لا يتطلب من العميل تمرير مجموعة من المفردات أو التدريب، فكلها تتم معالجتها تلقائيًا في نهاية خادم Milvus، لذلك لا يحتاج المستخدمون إلى الاهتمام بأي مفردات أو مجموعة مفردات. بالإضافة إلى ذلك، يمكن للمستخدمين أيضًا تخصيص المحلل لتنفيذ معالجة النص المخصص في BM25.
لمزيد من المعلومات حول BM25BuiltInFunction ، يُرجى الرجوع إلى البحث عن النص الكامل واستخدام البحث عن النص الكامل مع LangChain وMilvus.
الخيار 2: استخدام التضمين المتناثر الكثيف والمخصص في LangChain
يمكنك أن ترث الفئة BaseSparseEmbedding من langchain_milvus.utils.sparse ، وتنفيذ الطريقتين embed_query و embed_documents لتخصيص عملية التضمين المتناثر. يسمح لك ذلك بتخصيص أي طريقة تضمين متناثرة بناءً على إحصائيات تردد المصطلح (مثل BM25) أو الشبكات العصبية (مثل SPADE).
إليك مثال على ذلك:
from typing import Dict, List
from langchain_milvus.utils.sparse import BaseSparseEmbedding
class MyCustomEmbedding(BaseSparseEmbedding): # inherit from BaseSparseEmbedding
def __init__(self, model_path): ... # code to init or load model
def embed_query(self, query: str) -> Dict[int, float]:
... # code to embed query
return { # fake embedding result
1: 0.1,
2: 0.2,
3: 0.3,
# ...
}
def embed_documents(self, texts: List[str]) -> List[Dict[int, float]]:
... # code to embed documents
return [ # fake embedding results
{
1: 0.1,
2: 0.2,
3: 0.3,
# ...
}
] * len(texts)
لدينا فئة تجريبية BM25SparseEmbedding موروثة من BaseSparseEmbedding في langchain_milvus.utils.sparse. يمكنك تمريرها في قائمة تضمين التهيئة لمثيل مخزن متجه ميلفوس المتجه تمامًا مثل فئات التضمين الكثيفة الأخرى في لانجشين.
# BM25SparseEmbedding is inherited from BaseSparseEmbedding
from langchain_milvus.utils.sparse import BM25SparseEmbedding
embedding1 = OpenAIEmbeddings()
corpus = [doc.page_content for doc in docs]
embedding2 = BM25SparseEmbedding(
corpus=corpus
) # pass in corpus to initialize the statistics
vectorstore = Milvus.from_documents(
documents=docs,
embedding=[embedding1, embedding2],
vector_field=["dense", "sparse"],
connection_args={
"uri": URI,
},
consistency_level="Bounded", # Supported values are (`"Strong"`, `"Session"`, `"Bounded"`, `"Eventually"`). See https://milvus.io/docs/tune_consistency.md#Consistency-Level for more details.
drop_old=False,
)
على الرغم من أن هذه طريقة لاستخدام BM25، إلا أنها تتطلب من المستخدمين إدارة مجموعة إحصائيات تكرار المصطلحات. نوصي باستخدام الدالة المدمجة BM25 (الخيار 1) بدلاً من ذلك، لأنها تتعامل مع كل شيء من جانب خادم Milvus. وهذا يلغي حاجة المستخدمين إلى القلق بشأن إدارة المجموعة أو تدريب المفردات. لمزيد من المعلومات، يرجى الرجوع إلى استخدام البحث عن النص الكامل مع LangChain و Milvus.
تحديد حقول متجهات عشوائية متعددة
عند تهيئة مخزن متجهات Milvus، يمكنك تمرير قائمة التضمينات (وستقوم أيضًا بتمرير قائمة الدوال المدمجة في المستقبل) لتنفيذ عملية استرجاع متعددة الطرق، ومن ثم إعادة ترتيب هذه الحقول المرشحة. إليك مثال على ذلك:
# from langchain_voyageai import VoyageAIEmbeddings
embedding1 = OpenAIEmbeddings(model="text-embedding-ada-002")
embedding2 = OpenAIEmbeddings(model="text-embedding-3-large")
# embedding3 = VoyageAIEmbeddings(model="voyage-3") # You can also use embedding from other embedding model providers, e.g VoyageAIEmbeddings
vectorstore = Milvus.from_documents(
documents=docs,
embedding=[embedding1, embedding2], # embedding3],
builtin_function=BM25BuiltInFunction(output_field_names="sparse"),
# `sparse` is the output field name of BM25BuiltInFunction, and `dense1` and `dense2` are the output field names of embedding1 and embedding2
vector_field=["dense1", "dense2", "sparse"],
connection_args={
"uri": URI,
},
consistency_level="Bounded", # Supported values are (`"Strong"`, `"Session"`, `"Bounded"`, `"Eventually"`). See https://milvus.io/docs/tune_consistency.md#Consistency-Level for more details.
drop_old=False,
)
vectorstore.vector_fields
['dense1', 'dense2', 'sparse']
في هذا المثال، لدينا ثلاثة حقول متجهة. من بينها، يتم استخدام sparse كحقل مخرجات BM25BuiltInFunction ، بينما يتم تعيين الحقلين الآخرين، dense1 و dense2 ، تلقائيًا كحقول مخرجات للنموذجين OpenAIEmbeddings (بناءً على الترتيب).
تحديد بارامترات الفهرس للحقول متعددة المتجهات
بشكل افتراضي، سيتم تحديد أنواع الفهرس لكل حقل متجه تلقائيًا حسب نوع التضمين أو الدالة المضمنة. ومع ذلك، يمكنك أيضًا تحديد نوع الفهرس لكل حقل متجه لتحسين أداء البحث.
dense_index_param_1 = {
"metric_type": "COSINE",
"index_type": "HNSW",
}
dense_index_param_2 = {
"metric_type": "IP",
"index_type": "HNSW",
}
sparse_index_param = {
"metric_type": "BM25",
"index_type": "AUTOINDEX",
}
vectorstore = Milvus.from_documents(
documents=docs,
embedding=[embedding1, embedding2],
builtin_function=BM25BuiltInFunction(output_field_names="sparse"),
index_params=[dense_index_param_1, dense_index_param_2, sparse_index_param],
vector_field=["dense1", "dense2", "sparse"],
connection_args={
"uri": URI,
},
consistency_level="Bounded", # Supported values are (`"Strong"`, `"Session"`, `"Bounded"`, `"Eventually"`). See https://milvus.io/docs/tune_consistency.md#Consistency-Level for more details.
drop_old=False,
)
vectorstore.vector_fields
['dense1', 'dense2', 'sparse']
يُرجى الحفاظ على ترتيب قائمة بارامترات الفهرس متسقًا مع ترتيب vectorstore.vector_fields لتجنب الالتباس.
إعادة ترتيب المرشحين
بعد المرحلة الأولى من الاسترجاع، نحتاج إلى إعادة ترتيب المرشحين للحصول على نتيجة أفضل. يمكنك اختيار WeightedRanker أو RRFRanker حسب متطلباتك. يمكنك الرجوع إلى إعادة التصنيف لمزيد من المعلومات.
فيما يلي مثال على إعادة الترتيب الموزون:
vectorstore = Milvus.from_documents(
documents=docs,
embedding=OpenAIEmbeddings(),
builtin_function=BM25BuiltInFunction(),
vector_field=["dense", "sparse"],
connection_args={
"uri": URI,
},
consistency_level="Bounded", # Supported values are (`"Strong"`, `"Session"`, `"Bounded"`, `"Eventually"`). See https://milvus.io/docs/tune_consistency.md#Consistency-Level for more details.
drop_old=False,
)
query = "What are the novels Lila has written and what are their contents?"
vectorstore.similarity_search(
query, k=1, ranker_type="weighted", ranker_params={"weights": [0.6, 0.4]}
)
[Document(metadata={'pk': 454646931479252186, 'category': 'Heist/Thriller'}, page_content="In 'The Memory Thief' by Lila Rose, a charismatic thief with the ability to steal and manipulate memories is hired by a mysterious client to pull off a daring heist, but soon finds themselves trapped in a web of deceit and betrayal.")]
فيما يلي مثال على إعادة ترتيب RRRF:
vectorstore.similarity_search(query, k=1, ranker_type="rrf", ranker_params={"k": 100})
[Document(metadata={'category': 'Heist/Thriller', 'pk': 454646931479252186}, page_content="In 'The Memory Thief' by Lila Rose, a charismatic thief with the ability to steal and manipulate memories is hired by a mysterious client to pull off a daring heist, but soon finds themselves trapped in a web of deceit and betrayal.")]
إذا لم تقم بتمرير أي معلمات حول إعادة الترتيب، فسيتم استخدام استراتيجية إعادة الترتيب الموزونة المتوسطة بشكل افتراضي.
استخدام البحث المختلط وإعادة الترتيب في RAG
في سيناريو RAG، النهج الأكثر شيوعًا للبحث الهجين هو الاسترجاع الكثيف + المتناثر، متبوعًا بإعادة الترتيب. يوضح المثال التالي رمزًا مباشرًا من البداية إلى النهاية.
إعداد البيانات
نستخدم لانغشين WebBaseLoader لتحميل المستندات من مصادر الويب وتقسيمها إلى أجزاء باستخدام RecursiveCharacterTextSplitter.
import bs4
from langchain_community.document_loaders import WebBaseLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
# Create a WebBaseLoader instance to load documents from web sources
loader = WebBaseLoader(
web_paths=(
"https://lilianweng.github.io/posts/2023-06-23-agent/",
"https://lilianweng.github.io/posts/2023-03-15-prompt-engineering/",
),
bs_kwargs=dict(
parse_only=bs4.SoupStrainer(
class_=("post-content", "post-title", "post-header")
)
),
)
# Load documents from web sources using the loader
documents = loader.load()
# Initialize a RecursiveCharacterTextSplitter for splitting text into chunks
text_splitter = RecursiveCharacterTextSplitter(chunk_size=2000, chunk_overlap=200)
# Split the documents into chunks using the text_splitter
docs = text_splitter.split_documents(documents)
# Let's take a look at the first document
docs[1]
Document(metadata={'source': 'https://lilianweng.github.io/posts/2023-06-23-agent/'}, page_content='Fig. 1. Overview of a LLM-powered autonomous agent system.\nComponent One: Planning#\nA complicated task usually involves many steps. An agent needs to know what they are and plan ahead.\nTask Decomposition#\nChain of thought (CoT; Wei et al. 2022) has become a standard prompting technique for enhancing model performance on complex tasks. The model is instructed to “think step by step” to utilize more test-time computation to decompose hard tasks into smaller and simpler steps. CoT transforms big tasks into multiple manageable tasks and shed lights into an interpretation of the model’s thinking process.\nTree of Thoughts (Yao et al. 2023) extends CoT by exploring multiple reasoning possibilities at each step. It first decomposes the problem into multiple thought steps and generates multiple thoughts per step, creating a tree structure. The search process can be BFS (breadth-first search) or DFS (depth-first search) with each state evaluated by a classifier (via a prompt) or majority vote.\nTask decomposition can be done (1) by LLM with simple prompting like "Steps for XYZ.\\n1.", "What are the subgoals for achieving XYZ?", (2) by using task-specific instructions; e.g. "Write a story outline." for writing a novel, or (3) with human inputs.\nAnother quite distinct approach, LLM+P (Liu et al. 2023), involves relying on an external classical planner to do long-horizon planning. This approach utilizes the Planning Domain Definition Language (PDDL) as an intermediate interface to describe the planning problem. In this process, LLM (1) translates the problem into “Problem PDDL”, then (2) requests a classical planner to generate a PDDL plan based on an existing “Domain PDDL”, and finally (3) translates the PDDL plan back into natural language. Essentially, the planning step is outsourced to an external tool, assuming the availability of domain-specific PDDL and a suitable planner which is common in certain robotic setups but not in many other domains.\nSelf-Reflection#')
تحميل المستند إلى مخزن ميلفوس المتجه
كما في المقدمة أعلاه، نقوم بتهيئة وتحميل المستندات المعدة في مخزن Milvus vector، والذي يحتوي على حقلي متجهين: dense لتضمين OpenAI و sparse لدالة BM25.
vectorstore = Milvus.from_documents(
documents=docs,
embedding=OpenAIEmbeddings(),
builtin_function=BM25BuiltInFunction(),
vector_field=["dense", "sparse"],
connection_args={
"uri": URI,
},
consistency_level="Bounded", # Supported values are (`"Strong"`, `"Session"`, `"Bounded"`, `"Eventually"`). See https://milvus.io/docs/tune_consistency.md#Consistency-Level for more details.
drop_old=False,
)
بناء سلسلة RAG
نقوم بإعداد مثيل LLM والموجه، ثم ندمجهما في سلسلة RAG باستخدام لغة تعبير LangChain Expression Language.
from langchain_core.runnables import RunnablePassthrough
from langchain_core.prompts import PromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langchain_openai import ChatOpenAI
# Initialize the OpenAI language model for response generation
llm = ChatOpenAI(model_name="gpt-4o", temperature=0)
# Define the prompt template for generating AI responses
PROMPT_TEMPLATE = """
Human: You are an AI assistant, and provides answers to questions by using fact based and statistical information when possible.
Use the following pieces of information to provide a concise answer to the question enclosed in <question> tags.
If you don't know the answer, just say that you don't know, don't try to make up an answer.
<context>
{context}
</context>
<question>
{question}
</question>
The response should be specific and use statistics or numbers when possible.
Assistant:"""
# Create a PromptTemplate instance with the defined template and input variables
prompt = PromptTemplate(
template=PROMPT_TEMPLATE, input_variables=["context", "question"]
)
# Convert the vector store to a retriever
retriever = vectorstore.as_retriever()
# Define a function to format the retrieved documents
def format_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)
استخدم LCEL (لغة تعبير سلسلة اللغات) لبناء سلسلة RAG.
# Define the RAG (Retrieval-Augmented Generation) chain for AI response generation
rag_chain = (
{"context": retriever | format_docs, "question": RunnablePassthrough()}
| prompt
| llm
| StrOutputParser()
)
# rag_chain.get_graph().print_ascii()
قم باستدعاء سلسلة RAG مع سؤال محدد واسترداد الإجابة
query = "What is PAL and PoT?"
res = rag_chain.invoke(query)
res
'PAL (Program-aided Language models) and PoT (Program of Thoughts prompting) are approaches that involve using language models to generate programming language statements to solve natural language reasoning problems. This method offloads the solution step to a runtime, such as a Python interpreter, allowing for complex computation and reasoning to be handled externally. PAL and PoT rely on language models with strong coding skills to effectively perform these tasks.'
تهانينا! لقد قمتَ ببناء سلسلة RAG بحث هجينة (متجه كثيف + دالة bm25 متناثرة) مدعومة من Milvus وLangChain.