7 Years, 2 Major Rebuilds, 40K+ GitHub Stars: The Rise of Milvus as the Leading Open-Source Vector Database
In June 2025, Milvus reached 35,000 GitHub stars. Fast-forward just a few months, and we’ve now crossed 40,000—proof not only of momentum but of a global community that keeps pushing the future of vector and multimodal search forward.
We’re profoundly grateful. To everyone who starred, forked, filed issues, argued over an API, shared a benchmark, or built something incredible with Milvus: Thank you, and you’re the reason this project moves as fast as it does. Every star represents more than a button pressed — it reflects someone choosing Milvus to power their work, someone who believes in what we’re building, someone who shares our vision for open, accessible, high-performance AI infrastructure.
So as we celebrate, we’re also looking ahead—to the features you’re asking for, to the architectures AI now demands, and to a world where multimodal, semantic understanding is the default in every application.
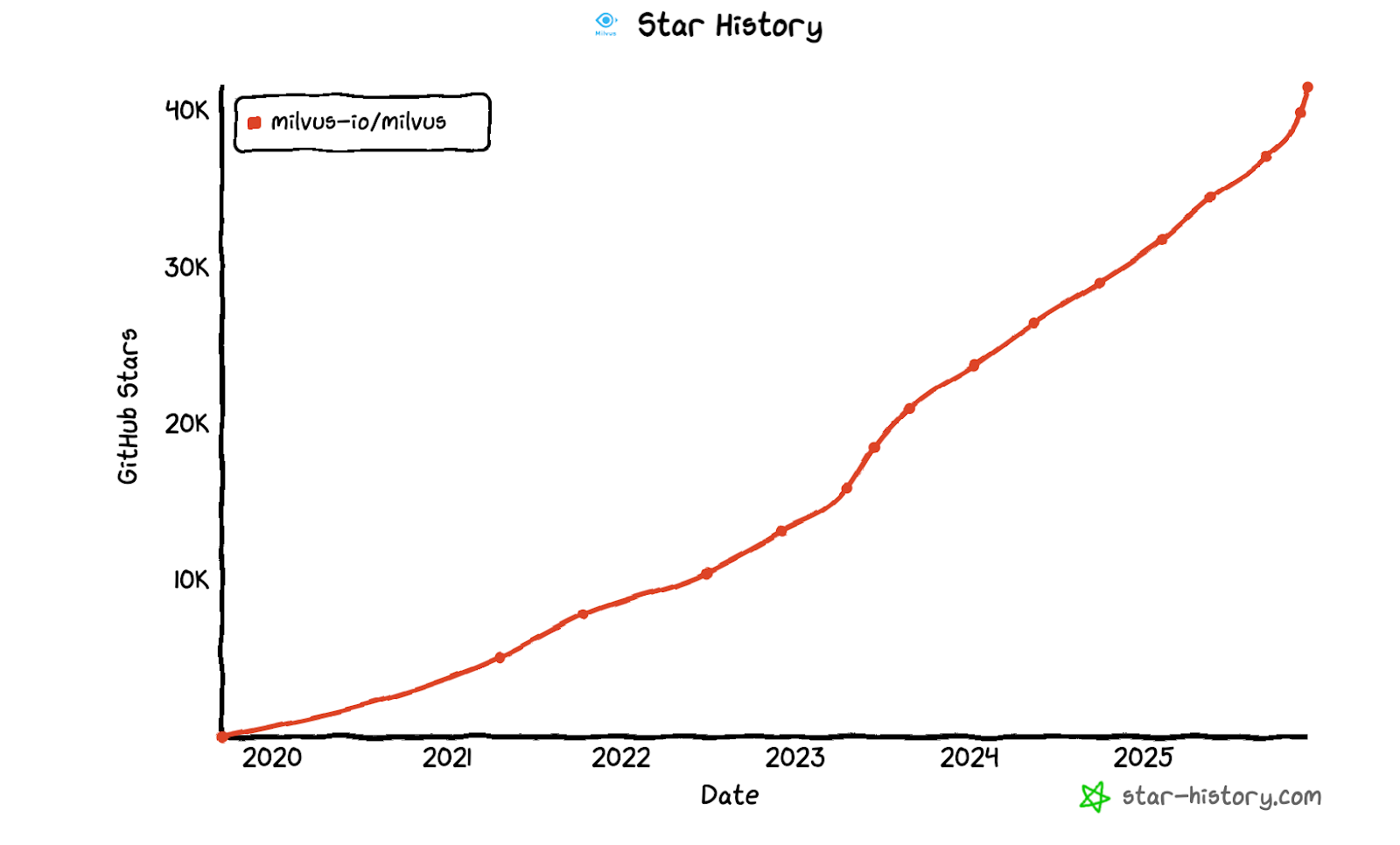
The Journey: From Zero to 40,000+ Stars
When we started building Milvus in 2017, the term vector database didn’t even exist. We were just a small team of engineers convinced that AI applications would soon need a new kind of data infrastructure—one built not for rows and columns, but for high-dimensional, unstructured, multimodal data. Traditional databases weren’t built for that world, and we knew someone had to reimagine what storage and retrieval could look like.
The early days were far from glamorous. Building enterprise-grade infrastructure is slow, stubborn work—weeks spent profiling code paths, rewriting components, and questioning design choices at 2 a.m. But we held onto a simple mission: make vector search accessible, scalable, and reliable for every developer building AI applications. That mission carried us through the first breakthroughs and through the inevitable setbacks.
And along the way, a few turning points changed everything:
2019: We open-sourced Milvus 0.10. It meant exposing all our rough edges—the hacks, the TODOs, the pieces we weren’t yet proud of. But the community showed up. Developers filed issues we never would’ve found, proposed features we hadn’t imagined, and challenged assumptions that ultimately made Milvus stronger.
2020–2021: We joined the LF AI & Data Foundation, shipped Milvus 1.0, graduated from LF AI & Data, and won the BigANN billion-scale vector search challenge—early proof that our architecture could handle real-world scale.
2022: Enterprise users needed Kubernetes-native scaling, elasticity, and real separation of storage and compute. We faced a hard decision: patch the old system or rebuild everything. We chose the harder path. Milvus 2.0 was a ground-up reinvention, introducing a fully decoupled cloud-native architecture that transformed Milvus into a production-grade platform for mission-critical AI workloads.
2024–2025: Zilliz (the team behind Milvus) was named a leader by Forrester, surged past 30,000 stars, and is now beyond 40,000. It became the backbone for multimodal search, RAG systems, agentic workflows, and billion-scale retrieval across industries—education, finance, creative production, scientific research, and more.
This milestone was earned not through hype, but through developers choosing Milvus for real production workloads and pushing us to improve every step of the way.
2025: Two Major Releases, Massive Performance Gains
2025 was the year Milvus stepped into a new league. While vector search excels at semantic understanding, the reality in production is simple: developers still need precise keyword matching for product IDs, serial numbers, exact phrases, legal terms, and more. Without native full-text search, teams were forced to maintain Elasticsearch/OpenSearch clusters or glue together their own custom solutions—doubling operational overhead and fragmentation.
Milvus 2.5 changed that. It introduced truly native hybrid search, combining full-text retrieval and vector search into a single engine. For the first time, developers could run lexical queries, semantic queries, and metadata filters together without juggling extra systems or syncing pipelines. We also upgraded metadata filtering, expression parsing, and execution efficiency so that hybrid queries felt natural—and fast—under real production loads.
Milvus 2.6 pushed this momentum further, targeting the two challenges we hear most often from users running at scale: cost and performance. This release delivered deep architectural improvements—more predictable query paths, faster indexing, dramatically lower memory usage, and significantly more efficient storage. Many teams reported immediate gains without changing a single line of application code.
Here are just a few highlights from Milvus 2.6:
Tiered storage that lets teams balance cost and performance more intelligently, cutting storage costs by as much as 50%.
Huge memory savings through RaBitQ 1-bit quantization — reducing memory usage by up to 72% while still delivering faster queries.
A redesigned full-text engine with a significantly faster BM25 implementation — up to 4× faster than Elasticsearch in our benchmarks.
A new Path Index for JSON-structured metadata, unlocking up to 100× faster filtering on complex documents.
AiSAQ: billion-scale compression with 3200× storage reduction and strong recall
Semantic + Geospatial Search with R-Tree: Combining where things are with what they mean for more relevant results
CAGRA+ Vamana: Cuts deployment cost with a hybrid CAGRA mode that builds on GPU but queries on CPU
A “data in, data out” workflow that simplifies embedding ingestion and retrieval, especially for multimodal pipelines.
Support for up to 100K collections in a single cluster — a major step toward true multi-tenancy at scale.
For a deeper look at Milvus 2.6, check out the full release notes.

Beyond Milvus: Open-Source Tools for AI Developers
In 2025, we didn’t just improve Milvus—we built tools that strengthen the entire AI developer ecosystem. Our goal wasn’t to chase trends, but to give builders the kind of open, powerful, transparent tools we’ve always wished existed.
DeepSearcher: Research Without Cloud Lock-In
OpenAI’s Deep Researcher proved what deep reasoning agents can do. But it’s closed, expensive, and locked behind cloud APIs. DeepSearcher is our answer. It’s a local, open-source deep research engine designed for anyone who wants structured investigations without sacrificing control or privacy.
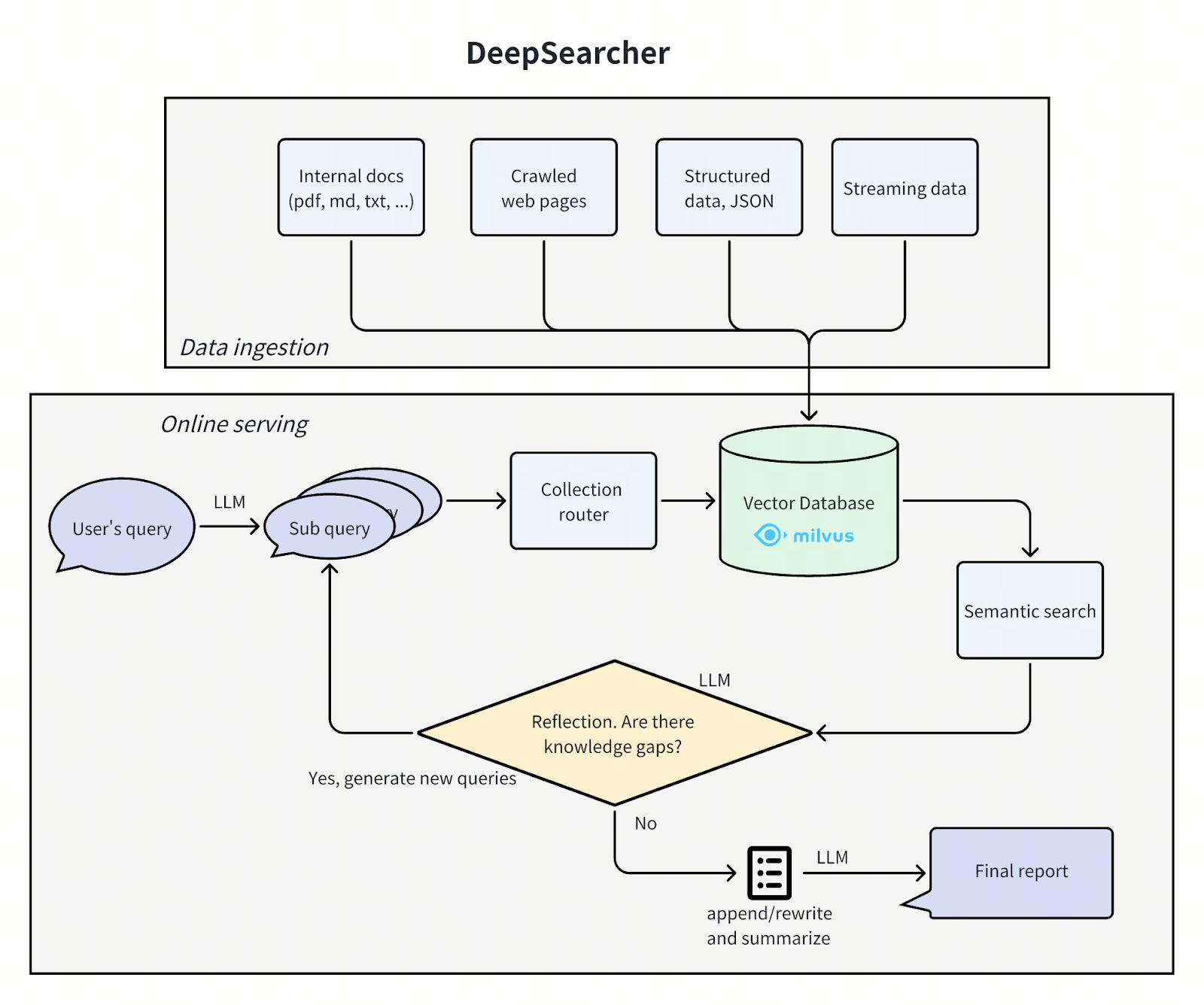
DeepSearcher runs entirely on your machine, gathering information across sources, synthesizing insights, and providing citations, reasoning steps, and traceability—features essential for real research, not just surface-level summaries. No black boxes. No vendor lock-in. Just transparent, reproducible analysis that developers and researchers can trust.
Claude Context: Coding Assistants That Actually Understand Your Code
Most AI coding tools still behave like fancy grep pipelines—fast, shallow, token-burning, and oblivious to real project structure. Claude Context changes that. Built as an MCP plugin, it finally gives coding assistants what they’ve been missing: genuine semantic understanding of your codebase.

Claude Context builds a vector-powered semantic index across your project, letting agents find the right modules, follow relationships across files, understand architecture-level intent, and answer questions with relevance rather than guesswork. It reduces token waste, boosts precision, and—most importantly—lets coding assistants behave as if they truly understand your software rather than pretending to.
Both tools are fully open source. Because AI infrastructure should belong to everyone—and because the future of AI should not be locked behind proprietary walls.
Trusted by 10,000+ Teams in Production
Today, more than 10,000 enterprise teams run Milvus in production—from fast-growing startups to some of the world’s most established technology and Fortune 500 companies. Teams at NVIDIA, Salesforce, eBay, Airbnb, IBM, AT&T, LINE, Shopee, Roblox, Bosch, and inside Microsoft rely on Milvus to power AI systems that operate every minute of every day. Their workloads span search, recommendations, agentic pipelines, multimodal retrieval, and other applications that push vector infrastructure to its limits.

But what matters most isn’t just who uses Milvus—it’s what they’re building with it. Across industries, Milvus sits behind systems that shape how businesses operate, innovate, and compete:
AI copilots and enterprise assistants that improve customer support, sales workflows, and internal decision-making with instant access to billions of embeddings.
Semantic and visual search in e-commerce, media, and advertising, driving higher conversion, better discovery, and faster creative production.
Legal, financial, and scientific intelligence platforms where precision, auditability, and compliance translate into real operational gains.
Fraud detection and risk engines in fintech and banking that depend on fast semantic matching to prevent losses in real time.
Large-scale RAG and agentic systems that give teams deeply contextual, domain-aware AI behavior.
Enterprise knowledge layers that unify text, code, images, and metadata into one coherent semantic fabric.
And these aren’t lab benchmarks—they’re some of the world’s most demanding production deployments. Milvus routinely delivers:
Sub-50ms retrieval across billions of vectors
Billions of documents and events managed in a single system
5–10× faster workflows than alternative solutions
Multi-tenant architectures supporting hundreds of thousands of collections
Teams choose Milvus for a simple reason: it delivers where it matters—speed, reliability, cost efficiency, and the ability to scale to billions without tearing apart their architecture every few months. The trust these teams place in us is the reason we keep strengthening Milvus for the decade of AI ahead.

When You Need Milvus Without the Ops: Zilliz Cloud
Milvus is free, powerful, and battle-tested. But it’s also a distributed system—and running distributed systems well is real engineering work. Index tuning, memory management, cluster stability, scaling, observability… these tasks take time and expertise that many teams simply don’t have to spare. Developers wanted the power of Milvus, just without the operational weight that inevitably comes with managing it at scale.
This reality led us to a simple conclusion: if Milvus was going to become core infrastructure for AI applications, we needed to make it effortless to operate. That’s why we built Zilliz Cloud, the fully managed Milvus service created and maintained by the same team behind the open-source project.
Zilliz Cloud gives developers the Milvus they already know and trust—but without provisioning clusters, firefighting performance issues, planning upgrades, or worrying about storage and compute tuning. And because it includes optimizations impossible to run in self-managed environments, it’s even faster and more reliable. Cardinal, our commercial-grade, self-optimizing vector engine, delivers 10× the performance of open-source Milvus.
What Sets Zilliz Cloud Apart
- Self-optimizing performance: AutoIndex automatically tunes HNSW, IVF, and DiskANN, delivering 96%+ recall with zero manual configuration.
Elastic & cost-efficient: Pay-as-you-go pricing, serverless autoscaling, and intelligent resource management often reduce costs by 50% or more compared to self-managed deployments.
Enterprise-grade reliability: 99.95% uptime SLA, multi-AZ redundancy, SOC 2 Type II, ISO 27001, and GDPR compliance. Full support for RBAC, BYOC, audit logs, and encryption.
Cloud-agnostic deployment: Run on AWS, Azure, GCP, Alibaba Cloud, or Tencent Cloud—no vendor lock-in, consistent performance everywhere.
Natural language queries: Built-in MCP server support lets you query data conversationally instead of manually crafting API calls.
Effortless Migration: Move from Milvus, Pinecone, Qdrant, Weaviate, Elasticsearch, or PostgreSQL using built-in migration tools — no schema rewrites or downtime required.
100% compatible with open-source Milvus. No proprietary forks. No lock-in. Just Milvus, made easier.
Milvus will always remain open source and free to use. But running and operating it reliably at enterprise scale requires significant expertise and resources. Zilliz Cloud is our answer to that gap. Deployed across 29 regions and five major clouds, Zilliz Cloud provides enterprise-grade performance, security, and cost efficiency while keeping you completely aligned with the Milvus you already know.
What’s Next: Milvus Lake
As the team that introduced the vector database, we’ve had a front-row seat to how enterprise data is changing. What once fit neatly into terabytes of structured tables is rapidly turning into petabytes—and soon trillions—of multimodal objects. Text, images, audio, video, time-series streams, multi-sensor logs… these now define the datasets that modern AI systems rely on.
Vector databases are purpose-built for unstructured and multimodal data, but they aren’t always the most economical or architecturally sound choice—especially when the vast majority of data is cold. Training corpora for large models, autonomous-driving perception logs, and robotics datasets usually don’t require millisecond-level latency or high concurrency. Running this volume of data through a real-time vector database becomes expensive, operationally heavy, and overly complex for pipelines that don’t require that level of performance.
That reality led us to our next major initiative: Milvus Lake—a semantic-driven, index-first multimodal lakehouse designed for AI-scale data. Milvus Lake unifies semantic signals across every modality—vectors, metadata, labels, LLM-generated descriptions, and structured fields—and organizes them into Semantic Wide Tables anchored around real business entities. Data that previously lived as raw, scattered files in object storage, lakehouses, and model pipelines becomes a unified, queryable semantic layer. Massive multimodal corpora turn into manageable, retrievable, reusable assets with consistent meaning across the enterprise.
Under the hood, Milvus Lake is built on a clean manifest + data + index architecture that treats indexing as foundational rather than an afterthought. This unlocks a “retrieve first, process later” workflow optimized for trillion-scale cold data—offering predictable latency, dramatically lower storage costs, and far greater operational stability. A tiered-storage approach—NVMe/SSD for hot paths and object storage for deep archives—paired with efficient compression and lazy-loaded indexes preserves semantic fidelity while keeping infrastructure overhead firmly in control.
Milvus Lake also plugs seamlessly into the modern data ecosystem, integrating with Paimon, Iceberg, Hudi, Spark, Ray, and other big-data engines and formats. Teams can run batch processing, near-real-time pipelines, semantic retrieval, feature engineering, and training-data preparation all in one place—without replatforming their existing workflows. Whether you’re building foundation-model corpora, managing autonomous-driving simulation libraries, training robotics agents, or powering large-scale retrieval systems, Milvus Lake provides an extensible and cost-efficient semantic lakehouse for the AI era.
Milvus Lake is in active development. Interested in early access or want to learn more?
Built by the Community, For the Community
What makes Milvus special isn’t just the technology—it’s the people behind it. Our contributor base spans the globe, bringing together specialists from high-performance computing, distributed systems, and AI infrastructure. Engineers and researchers from ARM, NVIDIA, AMD, Intel, Meta, IBM, Salesforce, Alibaba, Microsoft, and many more have contributed their expertise to shape Milvus into what it is today.
Every pull request, every bug report, every question answered in our forums, every tutorial created—these contributions make Milvus better for everyone.
This milestone belongs to all of you:
To our contributors: Thank you for your code, your ideas, and your time. You make Milvus better every single day.
To our users: Thank you for trusting Milvus with your production workloads and for sharing your experiences, both good and challenging. Your feedback drives our roadmap.
To our community supporters: Thank you for answering questions, writing tutorials, creating content, and helping newcomers get started. You make our community welcoming and inclusive.
To our partners and integrators: Thank you for building with us and making Milvus a first-class citizen in the AI development ecosystem.
To the Zilliz team: Thank you for your unwavering commitment to both the open-source project and our users’ success.
Milvus has grown because thousands of people decided to build something together—openly, generously, and with the belief that foundational AI infrastructure should be accessible to everyone.
Join Us on This Journey
Whether you’re building your first vector search application or scaling to billions of vectors, we’d love to have you as part of the Milvus community.
Get Started:
⭐ Star us on GitHub: github.com/milvus-io/milvus
☁️ Try Zilliz Cloud Free: zilliz.com/cloud
💬 Join our Discord to connect with developers worldwide
📚 Explore our docs: Milvus documentation
💬 Book a 20-minute one-on-one session to get insights, guidance, and answers to your questions.
The road ahead is exciting. As AI reshapes industries and unlocks new possibilities, vector databases will sit at the core of this transformation. Together, we’re building the semantic foundation that modern AI applications rely on—and we’re only getting started.
Here’s to the next 40,000 stars, and to building the future of AI infrastructure together. 🎉
- The Journey: From Zero to 40,000+ Stars
- 2025: Two Major Releases, Massive Performance Gains
- Beyond Milvus: Open-Source Tools for AI Developers
- DeepSearcher: Research Without Cloud Lock-In
- Claude Context: Coding Assistants That Actually Understand Your Code
- Trusted by 10,000+ Teams in Production
- When You Need Milvus Without the Ops: Zilliz Cloud
- What's Next: Milvus Lake
- Built by the Community, For the Community
- Join Us on This Journey
On This Page
Try Managed Milvus for Free
Zilliz Cloud is hassle-free, powered by Milvus and 10x faster.
Get StartedLike the article? Spread the word



