Understanding Consistency Level in the Milvus Vector Database
 Cover_image
Cover_image
This article is written by Chenglong Li and transcreated by Angela Ni.
Have you ever wondered why sometimes the data you have deleted from the Mlivus vector database still appear in the search results?
A very likely reason is that you have not set the appropriate consistency level for your application. Consistency level in a distributed vector database is critical as it determines at which point a particular data write can be read by the system.
Therefore, this article aims to demystify the concept of consistency and delve into the levels of consistency supported by the Milvus vector database.
Jump to:
What is consistency
Before getting started, we need to first clarify the connotation of consistency in this article as the word “consistency” is an overloaded term in the computing industry. Consistency in a distributed database specifically refers to the property that ensures every node or replica has the same view of data when writing or reading data at a given time. Therefore, here we are talking about consistency as in the CAP theorem.
For serving massive online businesses in the modern world, multiple replicas are commonly adopted. For instance, online e-commerce giant Amazon replicates its orders or SKU data across multiple data centers, zones, or even countries to ensure high system availability in the event of a system crash or failure. This poses a challenge to the system - data consistency across multiple replicas. Without consistency, it is very likely that the deleted item in your Amazon cart reappears, causing very bad user experience.
Hence, we need different data consistency levels for different applications. And luckily, Milvus, a database for AI, offers flexibility in consistency level and you can set the consistency level that best suits your application.
Consistency in the Milvus vector database
The concept of consistency level was first introduced with the release of Milvus 2.0. The 1.0 version of Milvus was not a distributed vector database so we did not involve tunable levels of consistency then. Milvus 1.0 flushes data every second, meaning that new data are almost immediately visible upon their insertion and Milvus reads the most updated data view at the exact time point when a vector similarity search or query request comes.
However, Milvus was refactored in its 2.0 version and Milvus 2.0 is a distributed vector database based on a pub-sub mechanism. The PACELC theorem points out that a distributed system must trade off among consistency, availability, and latency. Furthermore, different levels of consistency serve for different scenarios. Therefore, the concept of consistency was introduced in Milvus 2.0 and it supports tuning levels of consistency.
Four levels of consistency in the Milvus vector database
Milvus supports four levels of consistency: strong, bounded staleness, session, and eventual. And a Milvus user can specify the consistency level when creating a collection or conducting a vector similarity search or query. This section will continue to explain how these four levels of consistency are different and which scenario are they best suited for.
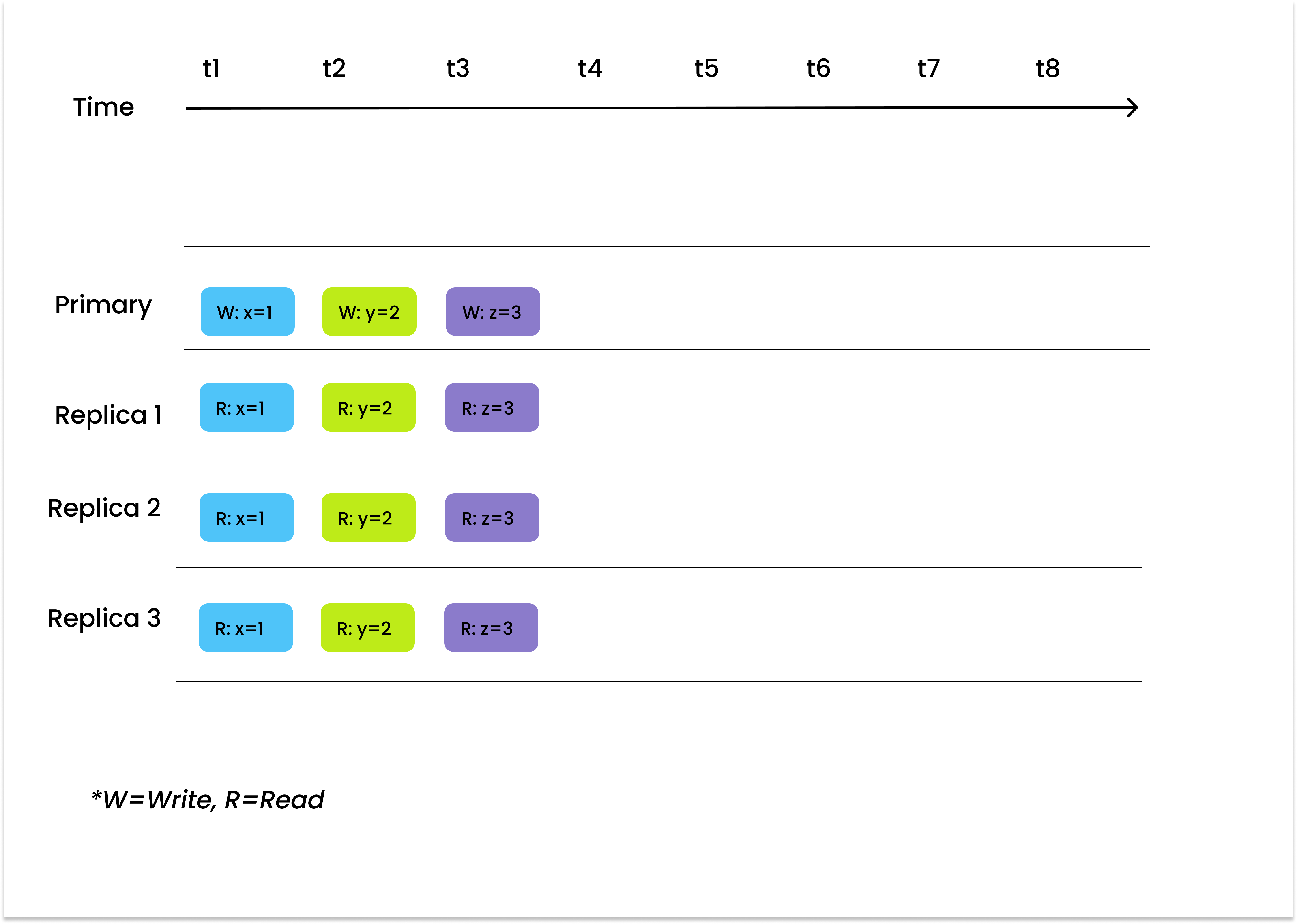
Strong
Strong is the highest and the most strict level of consistency. It ensures that users can read the latest version of data.
 Strong
Strong
According to the PACELC theorem, if the consistency level is set to strong, the latency will increase. Therefore, we recommend choosing strong consistency during functional testings to ensure the accuracy of the test results. And strong consistency is also best suited for applications that have strict demand for data consistency at the cost of search speed. An example can be an online financial system dealing with order payments and billing.
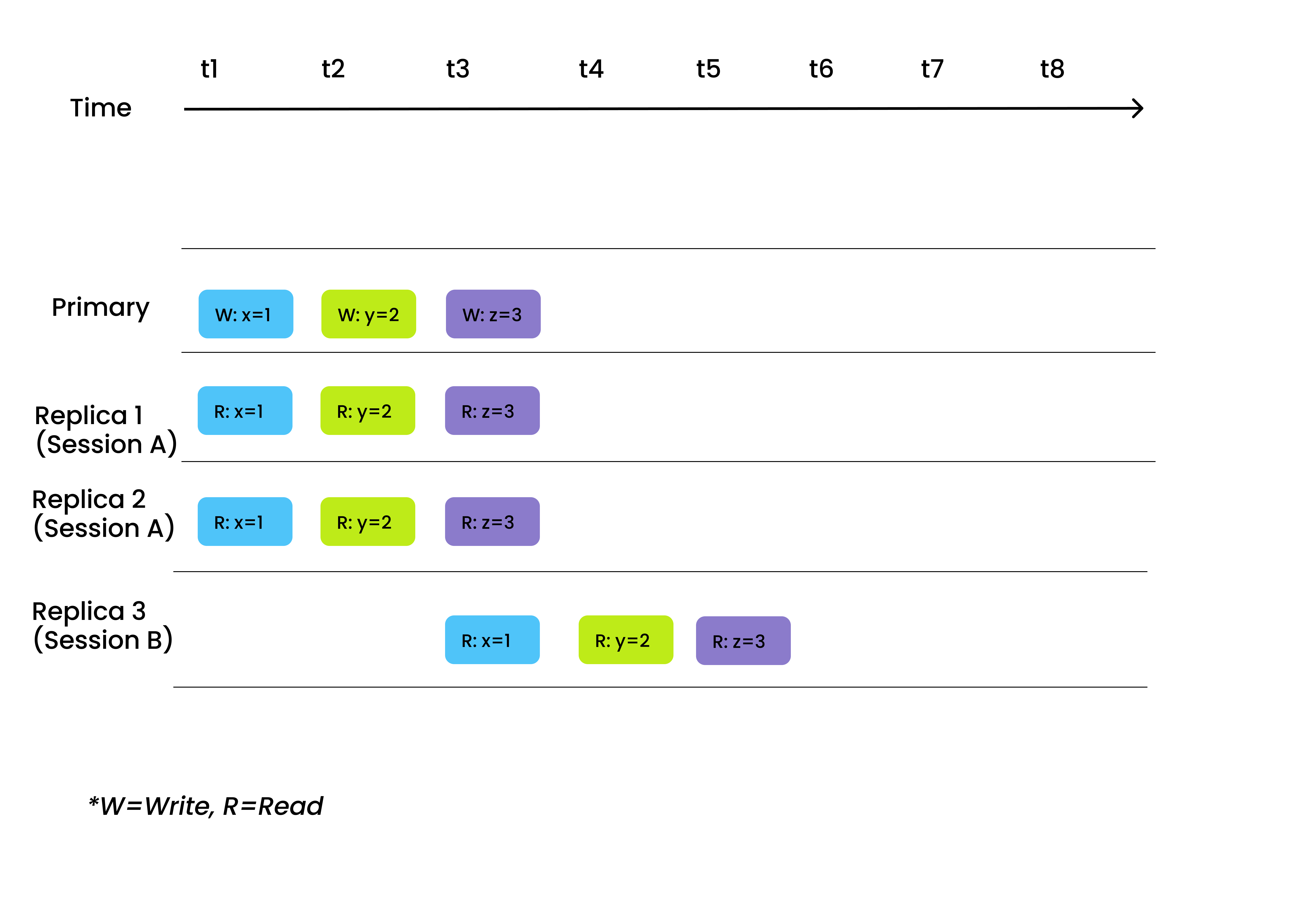
Bounded staleness
Bounded staleness, as its name suggests, allows data inconsistency during a certain period of time. However, generally, the data are always globally consistent out of that period of time.
 Bounded_staleness
Bounded_staleness
Bounded staleness is suitable for scenarios that needs to control search latency and can accept sporadic data invisibility. For instance, in recommender systems like video recommendation engines, data invisibility once in a while has really small impact on the overall recall rate, but can significantly boost the performance of the recommender system. An example can be an app for tracking the status of your online orders.
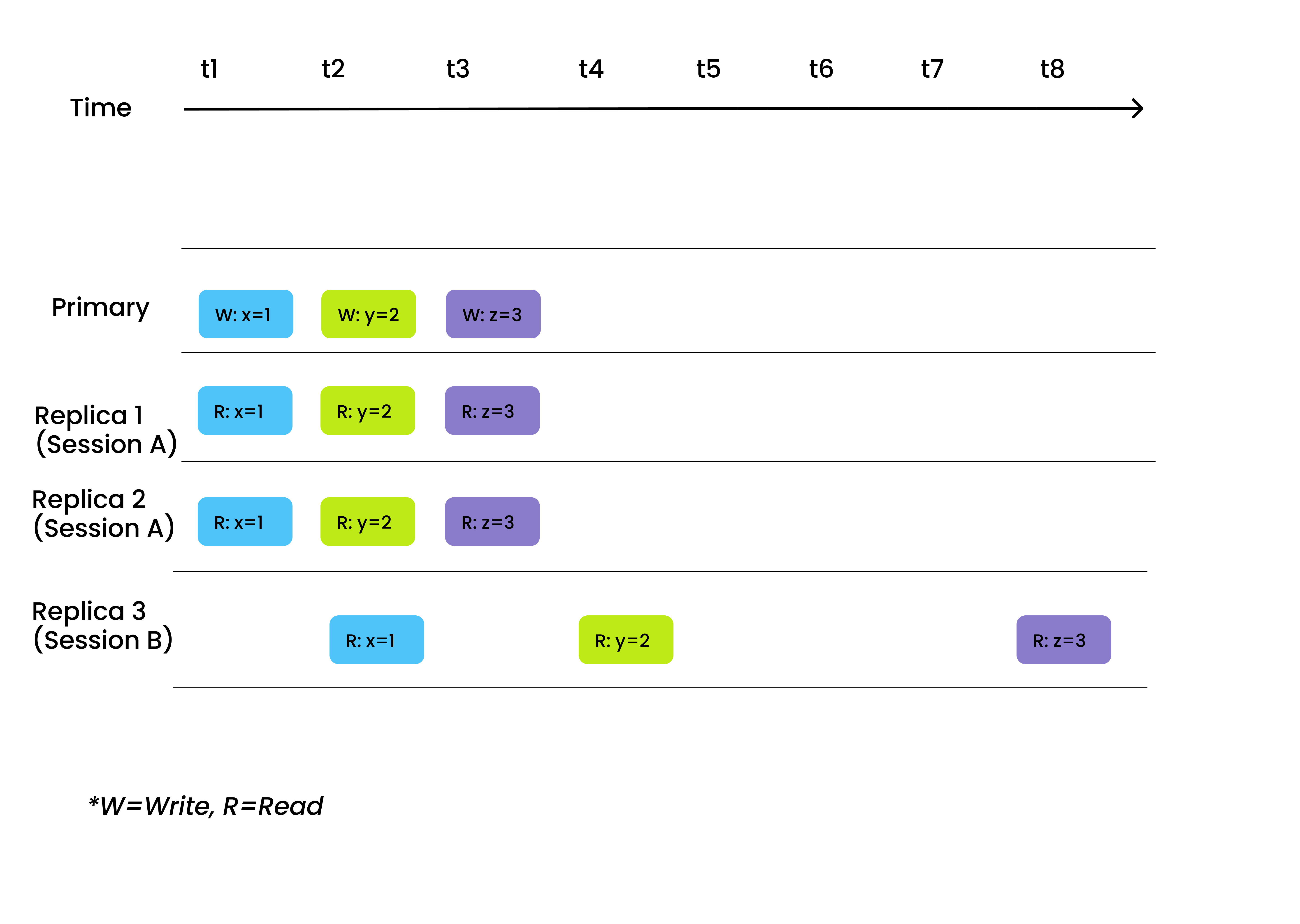
Session
Session ensures that all data writes can be immediately perceived in reads during the same session. In other words, when you write data via one client, the newly inserted data instantaneously become searchable.
 Session
Session
We recommend choosing session as the consistency level for those scenarios where the demand of data consistency in the same session is high. An example can be deleting the data of a book entry from the library system, and after confirmation of the deletion and refreshing the page (a different session), the book should no longer be visible in search results.
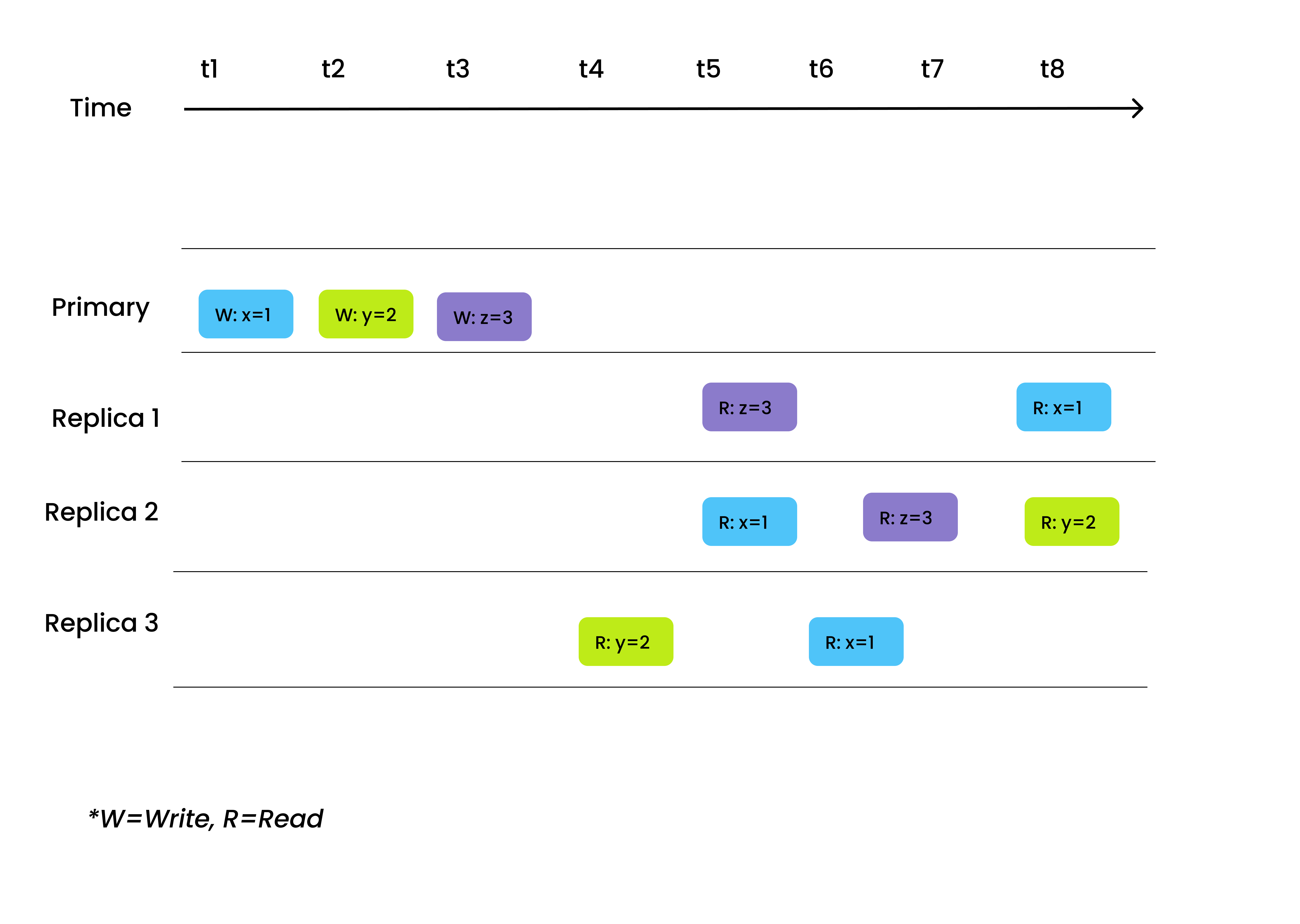
Eventual
There is no guaranteed order of reads and writes, and replicas eventually converge to the same state given that no further write operations are done. Under eventual consistency, replicas start working on read requests with the latest updated values. Eventual consistency is the weakest level among the four.
 Eventual
Eventual
However, according to the PACELC theorem, search latency can be tremendously shortened upon sacrificing consistency. Therefore, eventual consistency is best suited for scenarios that do not have high demand for data consistency but requires blazing-fast search performance. An example can be retrieving reviews and ratings of Amazon products with eventual consistency.
Endnote
So going back to the question raised at the beginning of this article, deleted data are still returned as search results because the user has not chosen the proper level of consistency. The default value for consistency level is bounded staleness (Bounded) in the Milvus vector database. Therefore, the data read might lag behind and Milvus might happen to read the data view before you conducted delete operations during a similarity search or query. However, this issue is simple to solve. All you need to do is tune the consistency level when creating a collection or conducting vector similarity search or query. Simple!
In the next post, we will unveil the mechanism behind and explain how the Milvus vector database achieves different levels of consistency. Stay tuned!
What’s next
With the official release of Milvus 2.1, we have prepared a series of blogs introducing the new features. Read more in this blog series:
- How to Use String Data to Empower Your Similarity Search Applications
- Using Embedded Milvus to Instantly Install and Run Milvus with Python
- Increase Your Vector Database Read Throughput with In-Memory Replicas
- Understanding Consistency Level in the Milvus Vector Database
- Understanding Consistency Level in the Milvus Vector Database (Part II)
- How Does the Milvus Vector Database Ensure Data Security?
- What is consistency
- Consistency in the Milvus vector database
- Four levels of consistency in the Milvus vector database
- Strong
- Bounded staleness
- Session
- Eventual
- Endnote
- What's next
On This Page
Try Managed Milvus for Free
Zilliz Cloud is hassle-free, powered by Milvus and 10x faster.
Get StartedLike the article? Spread the word



