Spiegazione delle raccolte
In Milvus è possibile creare più raccolte per gestire i dati e inserirli come entità nelle raccolte. Le collezioni e le entità sono simili alle tabelle e ai record dei database relazionali. Questa pagina aiuta a conoscere le raccolte e i concetti correlati.
Raccolta
Una collezione è una tabella bidimensionale con colonne fisse e righe variabili. Ogni colonna rappresenta un campo e ogni riga rappresenta un'entità.
La tabella seguente mostra una collezione con otto colonne e sei entità.
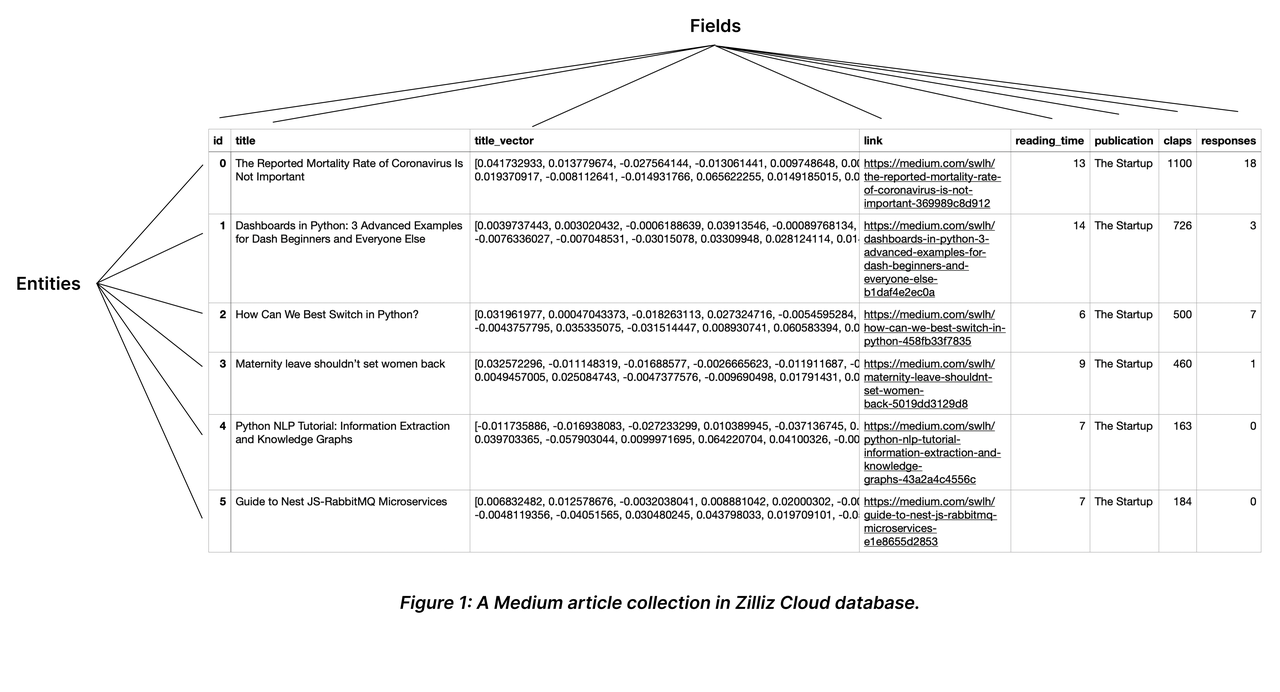 Spiegazione delle raccolte
Spiegazione delle raccolte
Schema e campi
Quando si descrive un oggetto, di solito si citano i suoi attributi, come la dimensione, il peso e la posizione. È possibile utilizzare questi attributi come campi di una collezione. Ogni campo ha diverse proprietà vincolanti, come il tipo di dati e la dimensionalità di un campo vettoriale. È possibile creare uno schema di raccolta creando i campi e definendone l'ordine. Per i possibili tipi di dati applicabili, consultare Schema spiegato.
È necessario includere tutti i campi definiti dallo schema nelle entità da inserire. Per rendere alcuni di essi facoltativi, si può pensare di attivare il campo dinamico. Per maggiori dettagli, consultare Campo dinamico.
Rendere i campi annullabili o impostare valori predefiniti
Per i dettagli su come rendere un campo annullabile o impostare il valore predefinito, consultare Nullable & Default.
Abilitazione del campo dinamico
Per i dettagli su come abilitare e utilizzare il campo dinamico, fare riferimento a Campo dinamico.
Chiave primaria e AutoId
Analogamente al campo primario in un database relazionale, una collezione ha un campo primario per distinguere un'entità dalle altre. Ogni valore del campo primario è globalmente unico e corrisponde a un'entità specifica.
Come mostrato nel grafico precedente, il campo id funge da campo primario e il primo ID 0 corrisponde a un'entità intitolata Il tasso di mortalità del Coronavirus non è importante. Non ci sarà nessun'altra entità che abbia il campo primario 0.
Un campo primario accetta solo numeri interi o stringhe. Quando si inseriscono le entità, i valori del campo primario devono essere inclusi per impostazione predefinita. Tuttavia, se si è abilitato l'AutoId alla creazione della collezione, Milvus genererà questi valori al momento dell'inserimento dei dati. In tal caso, escludere i valori del campo primario dalle entità da inserire.
Per ulteriori informazioni, consultare Campo primario e AutoId.
Indice
La creazione di indici su campi specifici migliora l'efficienza della ricerca. Si consiglia di creare indici per tutti i campi su cui si basa il servizio, tra cui gli indici sui campi vettoriali sono obbligatori.
Entità
Le entità sono record di dati che condividono lo stesso insieme di campi in una raccolta. I valori di tutti i campi di una stessa riga costituiscono un'entità.
È possibile inserire tutte le entità necessarie in una collezione. Tuttavia, con l'aumentare del numero di entità, aumenta anche la dimensione della memoria necessaria, con ripercussioni sulle prestazioni della ricerca.
Per ulteriori informazioni, consultare Schema spiegato.
Caricare e rilasciare
Il caricamento di una collezione è il prerequisito per effettuare ricerche di similarità e query nelle collezioni. Quando si carica una collezione, Milvus carica in memoria tutti i file di indice e i dati grezzi di ogni campo per rispondere rapidamente alle ricerche e alle query.
Le ricerche e le query sono operazioni che richiedono molta memoria. Per risparmiare sui costi, si consiglia di rilasciare le raccolte che non sono attualmente in uso.
Per maggiori dettagli, consultare Carica e rilascia.
Ricerca e query
Una volta creati gli indici e caricata la collezione, è possibile avviare una ricerca di similarità alimentando uno o più vettori di query. Ad esempio, quando si riceve la rappresentazione vettoriale della query in una richiesta di ricerca, Milvus utilizza il tipo di metrica specificato per misurare la somiglianza tra il vettore della query e quelli della collezione di destinazione prima di restituire quelli che sono semanticamente simili alla query.
È anche possibile includere il filtraggio dei metadati nelle ricerche e nelle query per migliorare la pertinenza dei risultati. Le condizioni di filtraggio dei metadati sono obbligatorie nelle query, ma facoltative nelle ricerche.
Per informazioni dettagliate sui tipi di metrica applicabili, consultare Tipi di metrica.
Per ulteriori informazioni su ricerche e query, consultare gli articoli del capitolo Ricerca e Rerank, tra cui le caratteristiche di base:
Inoltre, Milvus offre anche miglioramenti per migliorare le prestazioni e l'efficienza della ricerca. Questi miglioramenti sono disattivati per impostazione predefinita e possono essere attivati e utilizzati in base alle esigenze del servizio. Essi sono
Partizione
Le partizioni sono sottoinsiemi di una collezione, che condividono lo stesso insieme di campi con la collezione madre, e che contengono ciascuna un sottoinsieme di entità.
Allocando le entità in partizioni diverse, è possibile creare gruppi di entità. È possibile effettuare ricerche e interrogazioni in partizioni specifiche per far sì che Milvus ignori le entità in altre partizioni e migliorare l'efficienza della ricerca.
Per ulteriori informazioni, consultare Gestione delle partizioni.
Frammenti
I frammenti sono fette orizzontali di una raccolta. Ogni frammento corrisponde a un canale di ingresso dei dati. Ogni raccolta ha un frammento per impostazione predefinita. È possibile impostare il numero appropriato di shard quando si crea una raccolta, in base al throughput previsto e al volume dei dati da inserire nella raccolta.
Per informazioni dettagliate su come impostare il numero di shard, consultare la sezione Crea raccolta.
Alias
È possibile creare alias per le raccolte. Una raccolta può avere diversi alias, ma le raccolte non possono condividere un alias. Quando si riceve una richiesta per una raccolta, Milvus individua la raccolta in base al nome fornito. Se la collezione con il nome fornito non esiste, Milvus continua a localizzare il nome fornito come alias. È possibile utilizzare gli alias delle collezioni per adattare il codice a diversi scenari.
Per maggiori dettagli, consultare Gestione degli alias.
Funzione
È possibile impostare funzioni che Milvus ricava dai campi al momento della creazione della raccolta. Ad esempio, la funzione di ricerca full-text utilizza la funzione definita dall'utente per derivare un campo vettoriale sparse da un campo varchar specifico. Per ulteriori informazioni sulla ricerca full-text, consultare la sezione Ricerca full-text.
Livello di consistenza
I sistemi di database distribuiti di solito usano il livello di coerenza per definire l'uniformità dei dati tra i nodi di dati e le repliche. È possibile impostare livelli di consistenza separati quando si crea una raccolta o si effettuano ricerche di somiglianza all'interno della raccolta. I livelli di coerenza applicabili sono Strong, Bounded Staleness, Session e Eventually.
Per informazioni dettagliate su questi livelli di consistenza, consultare Livello di consistenza.