Hands-on with Qwen 3 and Milvus: Building RAG with the Latest Hybrid Inference Models

As a developer constantly seeking practical AI tools, I couldn’t ignore the buzz surrounding Alibaba Cloud’s latest release: the Qwen 3 model family, a robust lineup of eight hybrid inference models designed to redefine the balance between intelligence and efficiency. In just 12 hours, the project garnered over 17,000 GitHub stars and reached a peak of 23,000 downloads per hour on Hugging Face.
So what’s different this time? In short, Qwen 3 models combine both reasoning (slow, thoughtful responses) and non-reasoning (fast, efficient answers) in a single architecture, include diverse model options, enhanced training and performance, and deliver more enterprise-ready features.
In this post, I’ll summarize the key capabilities of Qwen 3 models you should pay attention to and guide you through a process of pairing Qwen 3 with Milvus to build a local, cost-aware retrieval-augmented generation (RAG) system—complete with hands-on code and tips for optimizing performance versus latency.
Let’s dive in.
What’s Exciting About Qwen 3?
After testing and digging into Qwen 3, it’s clear that it’s not just about bigger numbers on a spec sheet. It’s about how the model’s design choices actually help developers build better GenAI applications — faster, smarter, and with more control. Here’s what stands out.
1. Hybrid Thinking Modes: Smart When You Need Them, Speed When You Don’t
One of the most innovative features in Qwen 3 is its hybrid inference architecture. It gives you fine-grained control over how much “thinking” the model does on a task-by-task basis. Not all tasks need complicated reasoning, after all.
For complex problems that require deep analysis, you can tap into full reasoning power — even if it’s slower.
For everyday simple queries, you can switch into a faster, lighter mode.
You can even set a “thinking budget” — capping how much compute or tokens a session burns.
This isn’t just a lab feature either. It directly addresses the daily trade-off developers juggle: delivering high-quality responses without blowing up infrastructure costs or user latency.
2. A Versatile Lineup: MoE and Dense Models for Different Needs
Qwen 3 provides a wide range of models designed to match different operational needs:
Two MoE (Mixture of Experts) models:
Qwen3-235B-A22B: 235 billion total parameters, 22 billion active per query
Qwen3-30B-A3B: 30 billion total, 3 billion active
Six Dense models: ranging from a nimble 0.6B to a hefty 32B parameters
Quick tech background: Dense models (like GPT-3 or BERT) always activate all parameters, making them heavier but sometimes more predictable. MoE models activate only a fraction of the network at a time, making them much more efficient at scale.
In practice, this versatile lineup of models means you can:
Use dense models for tight, predictable workloads (like embedded devices)
Use MoE models when you need heavyweight capabilities without melting your cloud bill
With this range, you can tailor your deployment — from lightweight, edge-ready setups to powerful cloud-scale deployments — without being locked into a single model type.
3. Focused on Efficiency and Real-World Deployment
Instead of focusing solely on scaling model size, Qwen 3 focuses on training efficiency and deployment practicality:
Trained on 36 trillion tokens — double what Qwen 2.5 used
Expanded to 235B parameters — but smartly managed through MoE techniques, balancing capability with resource demands.
Optimized for deployment — dynamic quantization (down from FP4 to INT8) lets you run even the biggest Qwen 3 model on modest infrastructure — for example, deployment on four H20 GPUs.
The goal here is clear: deliver stronger performance without requiring disproportionate infrastructure investment.
4. Built for Real Integration: MCP Support and Multilingual Capabilities
Qwen 3 is designed with integration in mind, not just isolated model performance:
MCP (Model Context Protocol) compatibility enables seamless integration with external databases, APIs, and tools, reducing engineering overhead for complex applications.
Qwen-Agent enhances tool calling and workflow orchestration, supporting the building of more dynamic, actionable AI systems.
Multilingual support across 119 languages and dialects makes Qwen 3 a strong choice for applications targeting global and multilingual markets.
These features collectively make it easier for developers to build production-grade systems without needing extensive custom engineering around the model.
Qwen 3 Now Supported in DeepSearcher
DeepSearcher is an open-source project for deep retrieval and report generation, designed as a local-first alternative to OpenAI’s Deep Research. It helps developers build systems that surface high-quality, context-aware information from private or domain-specific data sources.
DeepSearcher now supports Qwen 3’s hybrid inference architecture, allowing developers to toggle reasoning dynamically — applying deeper inference only when it adds value, and skipping it when speed is more important.
Under the hood, DeepSearcher integrates with Milvus, a high-performance vector database developed by Zilliz engineers, to provide fast and accurate semantic search over local data. Combined with model flexibility, it gives developers greater control over system behavior, cost, and user experience.
Hands-on Tutorial: Building a RAG System with Qwen 3 and Milvus
Let’s put these Qwen 3 models to work by building a RAG system using the Milvus vector database.
Set up the environment.
# Install required packages
pip install --upgrade pymilvus openai requests tqdm
# Set up API key
import os
os.environ["DASHSCOPE_API_KEY"] = "YOUR_DASHSCOPE_API_KEY" # Get this from Alibaba Cloud DashScope
Note: You will need to obtain the API Key from Alibaba Cloud.
Data Preparation
We will use the Milvus documentation pages as our primary knowledge base.
# Download and extract Milvus documentation
!wget https://github.com/milvus-io/milvus-docs/releases/download/v2.4.6-preview/milvus_docs_2.4.x_en.zip
!unzip -q milvus_docs_2.4.x_en.zip -d milvus_docs
# Load and parse the markdown files
from glob import glob
text_lines = []
for file_path in glob("milvus_docs/en/faq/*.md", recursive=True):
with open(file_path, "r") as file:
file_text = file.read()
text_lines += file_text.split("# ")
Setting Up Models
We’ll use DashScope’s OpenAI-compatible API to access Qwen 3:
# Set up OpenAI client to access Qwen 3
from openai import OpenAI
openai_client = OpenAI(
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
api_key=os.getenv("DASHSCOPE_API_KEY")
)
# Set up embedding model
from pymilvus import model as milvus_model
embedding_model = milvus_model.DefaultEmbeddingFunction()
Let’s generate a test embedding and print its dimensions and first few elements:
test_embedding = embedding_model.encode_queries(["This is a test"])[0]
embedding_dim = len(test_embedding)
print(embedding_dim)
print(test_embedding[:10])
Output:
768
[-0.04836066 0.07163023 -0.01130064 -0.03789345 -0.03320649 -0.01318448
-0.03041712 -0.02269499 -0.02317863 -0.00426028]
Creating a Milvus Collection
Let’s set up our Milvus vector database:
from pymilvus import MilvusClient
# Initialize Milvus client (using local storage for simplicity)
milvus_client = MilvusClient(uri="./milvus_demo.db")
collection_name = "my_rag_collection"
# Create a fresh collection
if milvus_client.has_collection(collection_name):
milvus_client.drop_collection(collection_name)
# Create a new collection
test_embedding = embedding_model.encode_queries(["This is a test"])[0]
embedding_dim = len(test_embedding)
milvus_client.create_collection(
collection_name=collection_name,
dimension=embedding_dim,
metric_type="IP", # Inner product distance
consistency_level="Strong", # Strong consistency level
)
About MilvusClient parameter settings:
Setting the URI to a local file (e.g.,
./milvus.db) is the most convenient method as it automatically uses Milvus Lite to store all data in that file.For large-scale data, you can set up a more powerful Milvus server on Docker or Kubernetes. In this case, use the server’s URI (e.g.,
http://localhost:19530) as your URI.If you want to use Zilliz Cloud (the managed service of Milvus), adjust the URI and token, which correspond to the Public Endpoint and API key in Zilliz Cloud.
Adding Documents to the Collection
Now we’ll create embeddings for our text chunks and add them to Milvus:
from tqdm import tqdm
data = []
doc_embeddings = embedding_model.encode_documents(text_lines)
for i, line in enumerate(tqdm(text_lines, desc="Creating embeddings")):
data.append({"id": i, "vector": doc_embeddings[i], "text": line})
milvus_client.insert(collection_name=collection_name, data=data)
Output:
Creating embeddings: 100%|██████████████████████████████████████████████████| 72/72 [00:00<00:00, 381300.36it/s]
{'insert_count': 72, 'ids': [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 62, 63, 64, 65, 66, 67, 68, 69, 70, 71], 'cost': 0}
Building the RAG Query System
Now for the exciting part - let’s set up our RAG system to answer questions.
Let’s specify a common question about Milvus:
question = "How is data stored in milvus?"
Search for this question in the collection and retrieve the top 3 semantically matching results:
search_res = milvus_client.search(
collection_name=collection_name,
data=embedding_model.encode_queries([question]), # Convert the question to an embedding vector
limit=3, # Return top 3 results
search_params={"metric_type": "IP", "params": {}}, # Inner product distance
output_fields=["text"], # Return the text field
)
Let’s look at the search results for this query:
import json
retrieved_lines_with_distances = [
(res["entity"]["text"], res["distance"]) for res in search_res[0]
]
print(json.dumps(retrieved_lines_with_distances, indent=4))
Output:
[
[
" Where does Milvus store data?\n\nMilvus deals with two types of data, inserted data and metadata. \n\nInserted data, including vector data, scalar data, and collection-specific schema, are stored in persistent storage as incremental log. Milvus supports multiple object storage backends, including [MinIO](https://min.io/), [AWS S3](https://aws.amazon.com/s3/?nc1=h_ls), [Google Cloud Storage](https://cloud.google.com/storage?hl=en#object-storage-for-companies-of-all-sizes) (GCS), [Azure Blob Storage](https://azure.microsoft.com/en-us/products/storage/blobs), [Alibaba Cloud OSS](https://www.alibabacloud.com/product/object-storage-service), and [Tencent Cloud Object Storage](https://www.tencentcloud.com/products/cos) (COS).\n\nMetadata are generated within Milvus. Each Milvus module has its own metadata that are stored in etcd.\n\n###",
0.6572665572166443
],
[
"How does Milvus flush data?\n\nMilvus returns success when inserted data are loaded to the message queue. However, the data are not yet flushed to the disk. Then Milvus' data node writes the data in the message queue to persistent storage as incremental logs. If `flush()` is called, the data node is forced to write all data in the message queue to persistent storage immediately.\n\n###",
0.6312146186828613
],
[
"How does Milvus handle vector data types and precision?\n\nMilvus supports Binary, Float32, Float16, and BFloat16 vector types.\n\n- Binary vectors: Store binary data as sequences of 0s and 1s, used in image processing and information retrieval.\n- Float32 vectors: Default storage with a precision of about 7 decimal digits. Even Float64 values are stored with Float32 precision, leading to potential precision loss upon retrieval.\n- Float16 and BFloat16 vectors: Offer reduced precision and memory usage. Float16 is suitable for applications with limited bandwidth and storage, while BFloat16 balances range and efficiency, commonly used in deep learning to reduce computational requirements without significantly impacting accuracy.\n\n###",
0.6115777492523193
]
]
Using the LLM to Build a RAG Response
Convert the retrieved documents to string format:
context = "\n".join(
[line_with_distance[0] for line_with_distance in retrieved_lines_with_distances]
)
Provide system prompt and user prompt for the large language model:
SYSTEM_PROMPT = """
You are an AI assistant. You are able to find answers to the questions from the contextual passage snippets provided.
"""
USER_PROMPT = f"""
Use the following pieces of information enclosed in <context> tags to provide an answer to the question enclosed in <question> tags.
<context>
{context}
</context>
<question>
{question}
</question>
"""
Use the latest Qwen model to generate a response based on the prompt:
completion = openai_client.chat.completions.create(
# Model list: https://help.aliyun.com/zh/model-studio/getting-started/models
model="qwen-plus-2025-04-28",
messages=[
{"role": "system", "content": SYSTEM_PROMPT},
{"role": "user", "content": USER_PROMPT},
],
# Control thinking process with enable_thinking parameter (default True for open-source, False for commercial)
extra_body={"enable_thinking": False},
)
print(completion.choices[0].message.content)
Output:
In Milvus, data is stored in two main categories: **inserted data** and **metadata**.
- **Inserted Data**: This includes vector data (like Binary, Float32, Float16, and BFloat16 types), scalar data, and collection-specific schema. These are stored in persistent storage as **incremental logs**. Milvus supports various object storage backends for this purpose, including:
- [MinIO](https://min.io/)
- [AWS S3](https://aws.amazon.com/s3/?nc1=h_ls)
- [Google Cloud Storage (GCS)](https://cloud.google.com/storage?hl=en#object-storage-for-companies-of-all-sizes)
- [Azure Blob Storage](https://azure.microsoft.com/en-us/products/storage/blobs)
- [Alibaba Cloud OSS](https://www.alibabacloud.com/product/object-storage-service)
- [Tencent Cloud Object Storage (COS)](https://www.tencentcloud.com/products/cos)
- **Metadata**: Metadata generated within Milvus is stored separately. Each Milvus module maintains its own metadata, which is stored in [etcd](https://etcd.io/), a distributed key-value store.
When data is inserted into Milvus, it is first loaded into a message queue. It is not immediately written to disk. A `flush()` operation ensures that all data in the queue is written to persistent storage immediately.
Comparing Reasoning vs. Non-Reasoning Modes: A Practical Test
I ran a test comparing the two inference modes on a math problem:
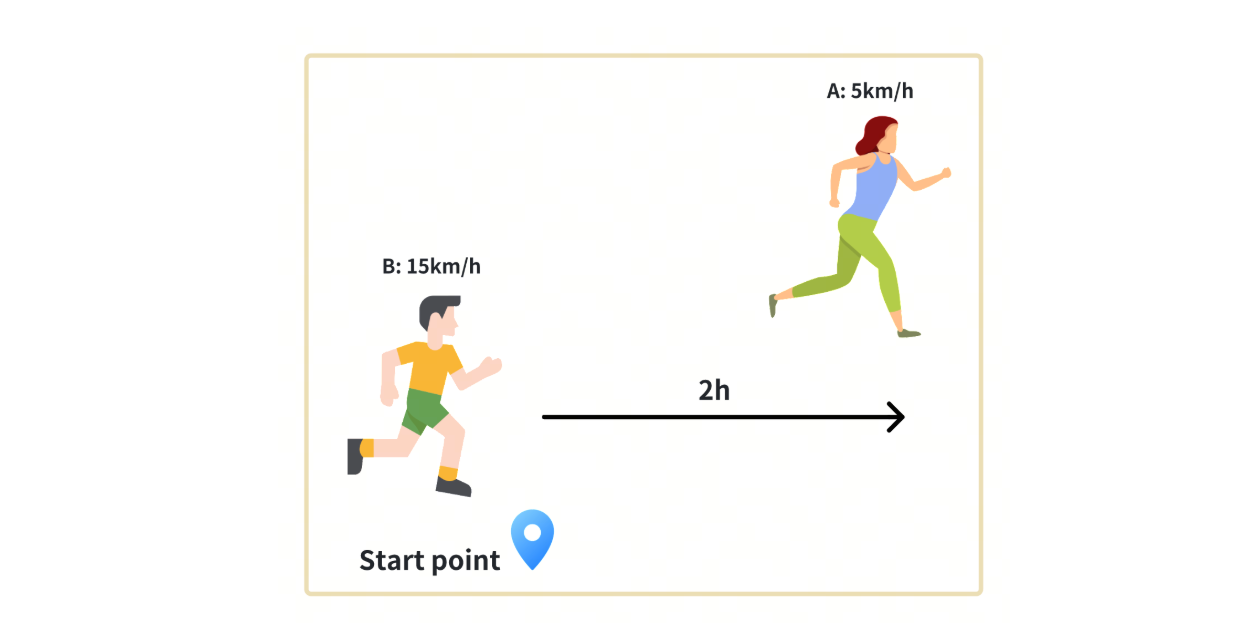
Problem: Person A and Person B start running from the same location. A leaves first and runs for 2 hours at 5km/h. B follows at 15km/h. How long will it take B to catch up?
import os
import time
from openai import OpenAI
os.environ["DASHSCOPE_API_KEY"] = "sk-****************"
client = OpenAI(
api_key=os.getenv("DASHSCOPE_API_KEY"),
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
)
############################################
# Think
# Record the start time
start_time = time.time()
stream = client.chat.completions.create(
# model lists:https://help.aliyun.com/zh/model-studio/getting-started/models
model="qwen3-235b-a22b",
# model="qwen-plus-2025-04-28",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "A and B depart from the same location. A leaves 2 hours earlier at 5 km/h. B follows at 15 km/h. When will B catch up?"},
],
# You can control the thinking mode through the enable_thinking parameter
extra_body={"enable_thinking": True},
stream=True,
)
answer_content = ""
for chunk in stream:
delta = chunk.choices[0].delta
if delta.content is not None:
answer_content += delta.content
print(answer_content)
# Record the end time and calculate the total runtime
end_time = time.time()
print(f"\n\nTotal runtime:{end_time - start_time:.2f}seconds")
With reasoning mode enabled:
Processing time: ~74.83 seconds
Deep analysis, problem parsing, multiple solution paths
High-quality markdown output with formulas
(The image below is a screenshot of the visualization of the model’s markdown response, for the reader’s convenience)

Non-Reasoning Mode:
In the code, you only need to set "enable_thinking": False
Results of non-reasoning mode on this problem:
- Processing time: ~74.83 seconds
- Deep analysis, problem parsing, multiple solution paths
- High-quality markdown output with formulas
(The image below is a screenshot of the visualization of the model’s markdown response, for the reader’s convenience)

Conclusion
Qwen 3 introduces a flexible model architecture that aligns well with the real-world needs of GenAI development. With a range of model sizes (including both dense and MoE variants), hybrid inference modes, MCP integration, and multilingual support, it gives developers more options to tune for performance, latency, and cost, depending on the use case.
Rather than emphasizing scale alone, Qwen 3 focuses on adaptability. This makes it a practical choice for building RAG pipelines, AI agents, and production applications that require both reasoning capabilities and cost-efficient operation.
When paired with infrastructure like Milvus — a high-performance open-source vector database — Qwen 3’s capabilities become even more useful, enabling fast, semantic search and smooth integration with local data systems. Together, they offer a strong foundation for intelligent, responsive GenAI applications at scale.
- What's Exciting About Qwen 3?
- 1. Hybrid Thinking Modes: Smart When You Need Them, Speed When You Don’t
- 2. A Versatile Lineup: MoE and Dense Models for Different Needs
- 3. Focused on Efficiency and Real-World Deployment
- 4. Built for Real Integration: MCP Support and Multilingual Capabilities
- Qwen 3 Now Supported in DeepSearcher
- Hands-on Tutorial: Building a RAG System with Qwen 3 and Milvus
- Set up the environment.
- Data Preparation
- Setting Up Models
- Creating a Milvus Collection
- Adding Documents to the Collection
- Building the RAG Query System
- Using the LLM to Build a RAG Response
- Comparing Reasoning vs. Non-Reasoning Modes: A Practical Test
- Conclusion
On This Page
Try Managed Milvus for Free
Zilliz Cloud is hassle-free, powered by Milvus and 10x faster.
Get StartedLike the article? Spread the word



