What Milvus Users Taught Us in 2024
Overview
As Milvus flourished in 2024 with major releases and a thriving open-source ecosystem, a hidden treasure trove of user insights was quietly forming in our community on Discord. This compilation of community discussions presented a unique opportunity to understand our users’ challenges firsthand. Intrigued by this untapped resource, I embarked on a comprehensive analysis of every discussion thread from the year, searching for patterns that could help us compile a frequently asked questions resource for Milvus users.
My analysis revealed three primary areas where users consistently sought guidance: Performance Optimization, Deployment Strategies, and Data Management. Users frequently discussed how to fine-tune Milvus for production environments and track performance metrics effectively. When it came to deployment, the community grappled with selecting appropriate deployments, choosing optimal search indices, and resolving issues in distributed setups. The data management conversations centered around service-to-service data migration strategies and the selection of embedding models.
Let’s examine each of these areas in more detail.
Deployment

Milvus provides flexible deployment modes to fit various use cases. However, some users do find it challenging to find the right choice, and want to feel comfortable that they are doing so “correctly.”
Which deployment type should I choose?
A very frequent question is which deployment to choose out of Milvus Lite, Standalone, and Distributed. The answer primarily depends on how large your vector database needs to be and how much traffic it will serve:
Milvus Lite
When prototyping on your local system with up to a few million vectors, or looking for an embedded vector db for unit testing and CI/CD, you can use Milvus Lite. Note that some more advanced features like full-text search are not yet available within Milvus Lite but coming soon.
Milvus Standalone
If your system needs to serve production traffic and / or you need to store between a few million and a hundred-million vectors, you should use Milvus Standalone, which packs all components of Milvus into a single Docker image. There is a variation which just takes its persistent storage (minio) and metadata store (etcd) dependencies out as separate images.
Milvus Distributed
For any larger scale deployments serving production traffic, like serving billions of vectors at thousands of QPS, you should use Milvus Distributed. Some users may want to perform offline batch processing at scale, for example, for data deduplication or record linkage, and the future version of Milvus 3.0 will provide a more efficient way of doing this by what we term a vector lake.
Fully Managed Service
For developers who want to focus on the application development without worrying about DevOps, Zilliz Cloud is the fully managed Milvus that offers a free tier.
See “Overview of Milvus Deployments” for more information.
How much memory, storage, and compute will I require?
This question comes up a lot, not only for existing Milvus users but also those who are considering whether Milvus is appropriate for their application. The exact combination of how much memory, storage, and compute a deployment will require depends on complex interaction of factors.
Vector embeddings differ in dimensionality due to the model that is used. And some vector search indexes are stored entirely in memory, whereas others store data to disk. Also, many search indexes are able to store a compressed (quantized) copy of the embeddings and require additional memory for graph data structures. These are just a few factors that affect the memory and storage.
Milvus Resource Sizing Tool
Luckily, Zilliz (the team that maintains Milvus) has built a resource sizing tool that does a fantastic job of answering this question. Input your vector dimensionality, index type, deployment options, and so on and the tool estimates CPU, memory, and storage needed across the various types of Milvus nodes and its dependencies. Your mileage may vary so a real load testing with your data and sample traffic is always a good idea.
Which vector index or distance metric should I choose?
Many users are uncertain which index they should choose and how to set the hyperparameters. First, it is always possible to defer the choice of index type to Milvus by selecting AUTOINDEX. If you wish to select a specific index type, however, a few rules of thumb provide a starting point.
In-Memory Indexes
Would you like to pay the cost to fit your index entirely into memory? An in-memory index is typically the fastest but also expensive. See “In-memory indexes” for a list of the ones supported by Milvus and the tradeoffs they make in terms of latency, memory, and recall.
Keep in mind that your index size is not simply the number of vectors times their dimensionality and floating point size. Most indexes quantize the vectors to reduce memory usage, but require memory for additional data structures. Other non-vector data (scalar) and their index also takes up memory space.
On-Disk Indexes
When your index does not fit in memory, you can use one of the “On-disk indexes” provided by Milvus. Two choices with very different latency/resource tradeoffs are DiskANN and MMap.
DiskANN stores a highly compressed copy of the vectors in memory, and the uncompressed vectors and graph search structures on disk. It uses some clever ideas to search the vector space while minimizing disk reads and takes advantage of the fast random access speed of SSDs. For minimum latency, the SSD must be connected via NVMe rather than SATA for best I/O performance.
Technically speaking, MMap is not an index type, but refers to the use of virtual memory with an in-memory index. With virtual memory, pages can be swapped between disk and RAM as required, which allows a much larger index to be used efficiently if the access patterns are such that only a small portion of the data is used at a time.
DiskANN has excellent and consistent latency. MMap has even better latency when it is accessing a page in-memory, but frequent page-swapping will cause latency spikes. Thus MMap can have a higher variability in latency, depending on the memory access patterns.
GPU Indexes
A third option is to construct an index using GPU memory and compute. Milvus’ GPU support is contributed by the Nvidia RAPIDS team. GPU vector search may have lower latency than a corresponding CPU search, although it usually takes hundreds or thousands of search QPS to fully exploit the parallelism of GPU. Also, GPUs typically have less memory than the CPU RAM and are more costly to run.
Distance Metrics
An easier question to answer is which distance metric should you choose to measure similarity between vectors. It is recommended to choose the same distance metric that your embedding model was trained with, which is typically COSINE (or IP when inputs are normalized). The source of your model (e.g. the model page on HuggingFace) will provide clarification on which distance metric was used. Zilliz also put together a convenient table to look that up.
To summarize, I think a lot of the uncertainty around index choice revolves around uncertainty about how these choices affect the latency/resource usage/recall tradeoff of your deployment. I recommend using the rules of thumb above to decide between in-memory, on-disk, or GPU indexes, and then using the tradeoff guidelines given in the Milvus documentation to pick a particular one.
Can you fix my broken Milvus Distributed deployment?
Many questions revolve around issues getting a Milvus Distributed deployment up and running, with questions relating to configuration, tooling, and debugging logs. It’s hard to give a single fix as each question seems different from the last, although luckily Milvus has a vibrant Discord where you can seek help, and we also offer 1-on-1 office hours with an expert.
How do I deploy Milvus on Windows?
A question that has come up several times is how to deploy Milvus on Windows machines. Based on your feedback, we have rewritten the documentation for this: see Run Milvus in Docker (Windows) for how to do this, using Windows Subsystem for Linux 2 (WSL2).
Performance and Profiling

Having chosen a deployment type and got it running, users want to feel comfortable that they have made optimal decisions and would like to profile their deployment’s performance and state. Many questions related to how to profile performance, observe state, and get an insight into what and why.
How do I measure performance?
Users want to check metrics related to the performance of their deployment so they can understand and remedy bottlenecks. Metrics mentioned include average query latency, distribution of latencies, query volume, memory usage, disk storage, and so on. These metrics can be observed from the monitoring system. In addition, Milvus 2.5 introduces a new tool called WebUI (feedback welcome!), which allows you to access more system internal information like segment compaction status, from a user-friendly web interface.
What’s happening inside Milvus right now (i.e. observe state)?
Relatedly, users want to observe the internal state of their deployment. Issues raised include understanding why a search index is taking so long to build, how to determine if the cluster is healthy, and understanding how a query is executed across nodes. Many of these questions can be answered with the new WebUI that gives transparency to what the system is doing internally.
How does some (complex) aspect of the internals work?
Advanced users often want some understanding of Milvus internals, for example, having an understanding of the sealing of segments or memory management. The underlying goal is typically to improve performance and sometimes to debug issues. The documentation, particularly under the sections “Concepts” and “Administration Guide" is helpful here, for instance see the pages “Milvus Architecture Overview” and “Clustering Compaction”. We will continue to improve the documentation on Milvus internals, make it easier to understand, and welcome any feedback or requests via Discord.
Which embedding model should I choose?
A question related to performance that has come up multiple times in meetups, office hours, and on Discord is how to choose an embedding model. This is a difficult question to give a definitive answer although we recommend starting with default models like all-MiniLM-L6-v2.
Similar to the choice of search index, there are tradeoffs between compute, storage, and recall. An embedding model with larger output dimension will require more storage, all else held equal, although probably result in higher recall of relevant items. Larger embedding models, for a fixed dimension, typically outperform smaller ones in terms of recall, although at the cost of increased compute and time. Leaderboards that rank embedding model performance such as MTEB are based on benchmarks that may not align with your specific data and task.
So, it does not make sense to think of a “best” embedding model. Start with one that has acceptable recall and meets your compute and time budget for calculating embeddings. Further optimizations like fine-tuning on your data or exploring the compute/recall tradeoff empirically can be deferred to after you have a working system in production.
Data Management
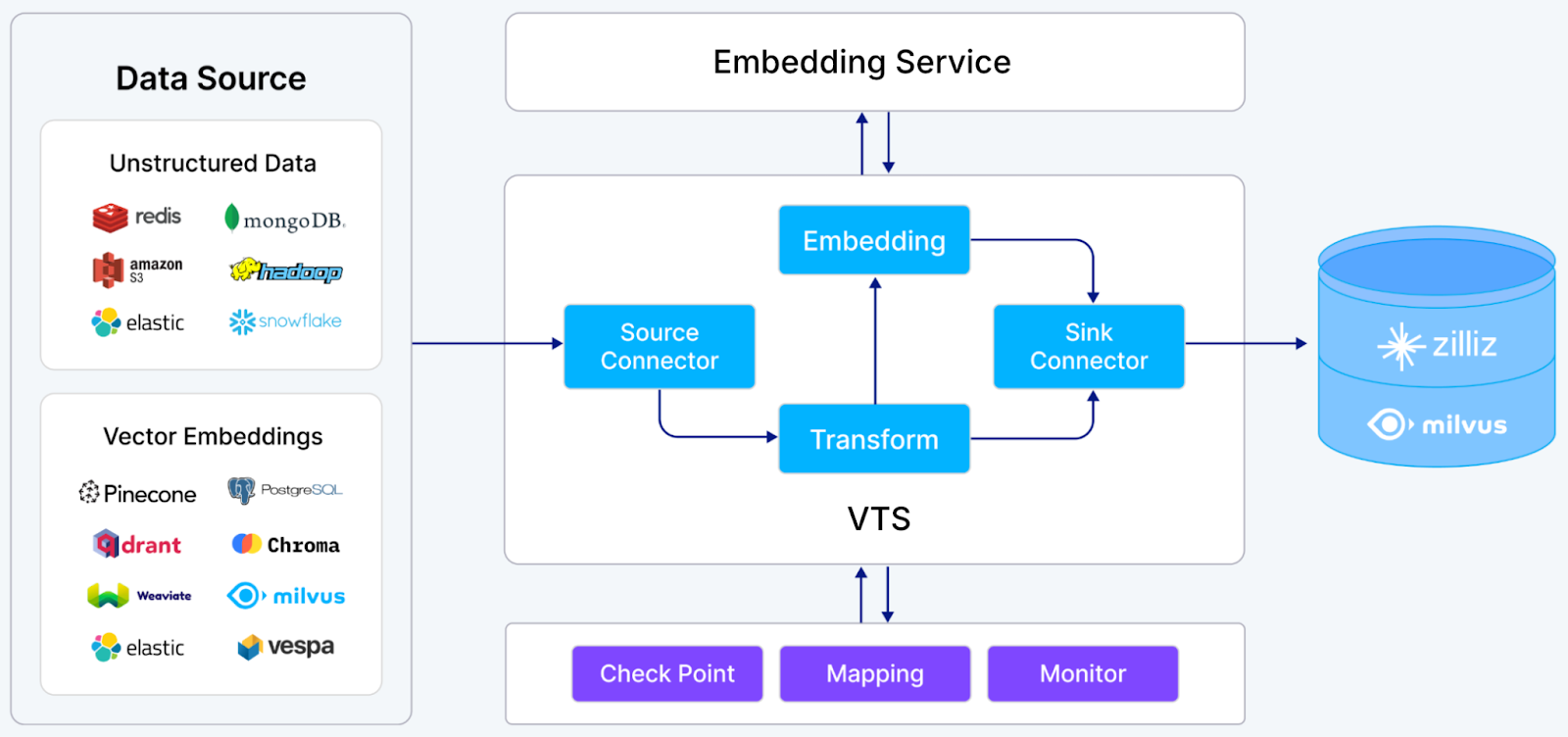
How to move data into and out of a Milvus deployment is another main theme in the Discord discussions, which is no surprise given how central this task is to putting an application into production.
How do I migrate data from X to Milvus? How do I migrate data from Standalone to Distributed? How do I migrate from 2.4.x to 2.5.x?
A new user commonly wants to get existing data into Milvus from another platform, including traditional search engines like Elasticsearch and other vector databases like Pinecone or Qdrant. Existing users may also want to migrate their data from one Milvus deployment to another, or from self-hosted Milvus to fully managed Zilliz Cloud.
The Vector Transport Service (VTS) and the managed Migration service on Zilliz Cloud are designed for this purpose.
How do I save and load data backups? How do I export data from Milvus?
Milvus has a dedicated tool, milvus-backup, to take snapshots on permanent storage and restore them.
Next Steps
I hope this has given you some pointers on how to tackle common challenges faced when building with a vector database. This definitely helped us to take another look at our documentation and feature roadmap to keep working on things that can help our community best succeed with Milvus. A key takeaway that I would like to emphasize, is that your choices put you within different points of a tradeoff space between compute, storage, latency, and recall. You cannot maximize all of these performance criteria simultaneously - there is no “optimal” deployment. Yet, by understanding more about how vector search and distributed database systems work you can make an informed decision.
After trawling through the large number of posts from 2024, it got me thinking: why should a human do this? Has not Generative AI promised to solve such a task of crunching large amounts of text and extracting insight? Join me in the second part of this blog post (coming soon), where I investigate the design and implementation of a multi-agent system for extracting insight from discussion forums.
Thanks again and hope to see you in the community Discord and our next Unstructured Data meetups. For more hands-on assistance, we welcome you to book a 1-on-1 office hour. Your feedback is essential to improving Milvus!
- Overview
- Deployment
- Which deployment type should I choose?
- How much memory, storage, and compute will I require?
- Which vector index or distance metric should I choose?
- Can you fix my broken Milvus Distributed deployment?
- How do I deploy Milvus on Windows?
- Performance and Profiling
- How do I measure performance?
- What’s happening inside Milvus right now (i.e. observe state)?
- How does some (complex) aspect of the internals work?
- Which embedding model should I choose?
- Data Management
- How do I migrate data from X to Milvus? How do I migrate data from Standalone to Distributed? How do I migrate from 2.4.x to 2.5.x?
- How do I save and load data backups? How do I export data from Milvus?
- Next Steps
On This Page
Try Managed Milvus for Free
Zilliz Cloud is hassle-free, powered by Milvus and 10x faster.
Get StartedLike the article? Spread the word



