Designing Multi-Tenancy RAG with Milvus: Best Practices for Scalable Enterprise Knowledge Bases
Introduction
Over the past couple of years, Retrieval-Augmented Generation (RAG) has emerged as a trusted solution for large organizations to enhance their LLM-powered applications, especially those with diverse users. As such applications grow, implementing a multi-tenancy framework becomes essential. Multi-tenancy provides secure, isolated access to data for different user groups, ensuring user trust, meeting regulatory standards, and improving operational efficiency.
Milvus is an open-source vector database built to handle high-dimensional vector data. It is an indispensable infrastructure component of RAG, storing and retrieving contextual information for LLMs from external sources. Milvus offers flexible multi-tenancy strategies for various needs, including database-level, collection-level, and partition-level multi-tenancy.
In this post, we’ll cover:
What is Multi-Tenancy and Why It Matters
Multi-Tenancy Strategies in Milvus
Example: Multi-Tenancy Strategy for a RAG-Powered Enterprise Knowledge Base
What is Multi-Tenancy and Why It Matters
Multi-tenancy is an architecture where multiple customers or teams, known as "tenants," share a single instance of an application or system. Each tenant’s data and configurations are logically isolated, ensuring privacy and security, while all tenants share the same underlying infrastructure.
Imagine a SaaS platform that provides knowledge-based solutions to multiple companies. Each company is a tenant.
Tenant A is a healthcare organization storing patient-facing FAQs and compliance documents.
Tenant B is a tech company managing internal IT troubleshooting workflows.
Tenant C is a retail business with customer service FAQs for product returns.
Each tenant operates in a completely isolated environment, ensuring that no data from Tenant A leaks into Tenant B’s system or vice versa. Furthermore, resource allocation, query performance, and scaling decisions are tenant-specific, ensuring high performance regardless of workload spikes in one tenant.
Multi-tenancy also works for systems serving different teams within the same organization. Imagine a large company using a RAG-powered knowledge base to serve its internal departments, such as HR, Legal, and Marketing. Each department is a tenant with isolated data and resources in this setup.
Multi-tenancy offers significant benefits, including cost efficiency, scalability, and robust data security. By sharing a single infrastructure, service providers can reduce overhead costs and ensure more effective resource consumption. This approach also scales effortlessly—onboarding new tenants requires far fewer resources than creating separate instances for each one, as with single-tenancy models. Importantly, multi-tenancy maintains robust data security by ensuring strict data isolation for each tenant, with access controls and encryption protecting sensitive information from unauthorized access. Additionally, updates, patches, and new features can be deployed across all tenants simultaneously, simplifying system maintenance and reducing the burden on administrators while ensuring that security and compliance standards are consistently upheld.
Multi-Tenancy Strategies in Milvus
To understand how Milvus supports multi-tenancy, it’s important to first look at how it organizes user data.
How Milvus Organizes User Data
Milvus structures data across three layers, moving from broad to granular: Database, Collection, and Partition/Partition Key.
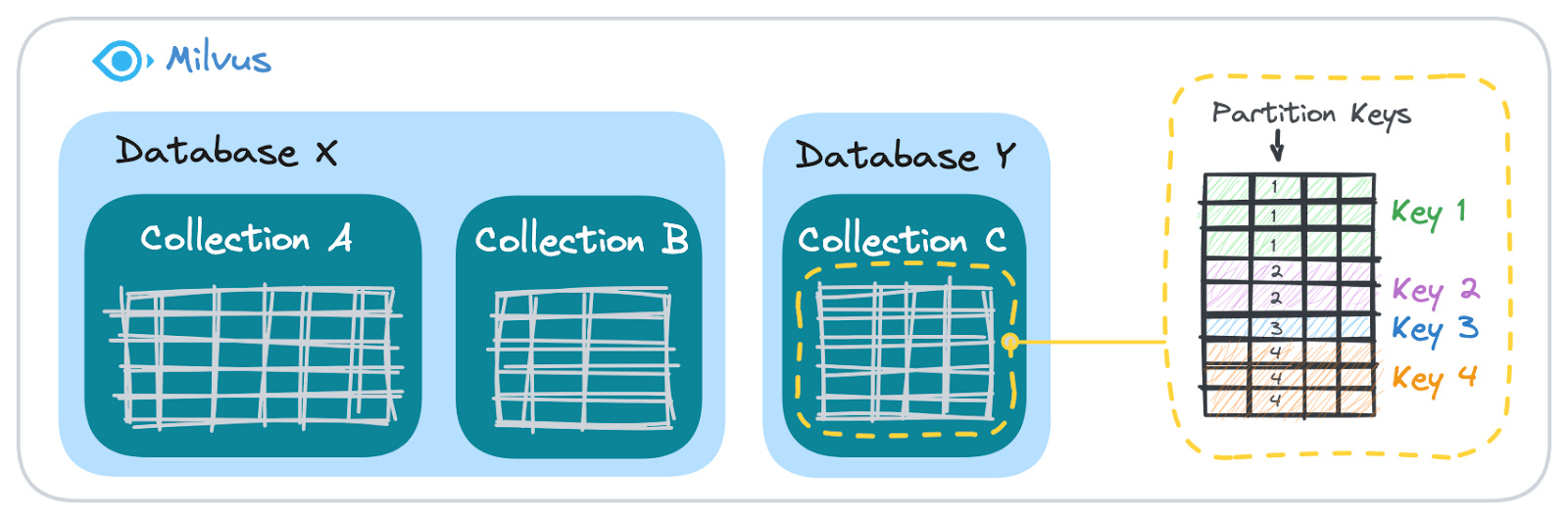 Figure- How Milvus organizes user data .png
Figure- How Milvus organizes user data .png
Figure: How Milvus organizes user data
Database: This acts as a logical container, similar to a database in traditional relational systems.
Collection: Comparable to a table within a database, a collection organizes data into manageable groups.
Partition/Partition Key: Within a collection, data can be further segmented by Partitions. Using a Partition Key, data with the same key is grouped together. For example, if you use a user ID as the Partition Key, all data for a specific user will be stored in the same logical segment. This makes it straightforward to retrieve data tied to individual users.
As you move from Database to Collection to Partition Key, the granularity of data organization becomes progressively finer.
To ensure stronger data security and proper access control, Milvus also provides robust Role-Based Access Control (RBAC), allowing administrators to define specific permissions for each user. Only authorized users can access certain data.
Milvus supports multiple strategies for implementing multi-tenancy, offering flexibility based on the needs of your application: database-level, collection-level, and partition-level multi-tenancy.
Database-Level Multi-Tenancy
With the database-level multi-tenancy approach, each tenant is assigned their own database within the same Milvus cluster. This strategy provides strong data isolation and ensures optimal search performance. However, it can lead to inefficient resource utilization if certain tenants remain inactive.
Collection-Level Multi-Tenancy
Here, in collection-level multi-tenancy, we can organize data for tenants in two ways.
One Collection for All Tenants: All tenants share a single collection, with tenant-specific fields used for filtering. While simple to implement, this approach can encounter performance bottlenecks as the number of tenants increases.
One Collection per Tenant: Each tenant can have a dedicated collection, improving isolation and performance but requiring more resources. This setup may face scalability limitations if the number of tenants exceeds Milvus’s collection capacity.
Partition-Level Multi-Tenancy
Partition-Level Multi-Tenancy focuses on organizing tenants within a single collection. Here, we also have two ways to organize tenant data.
One Partition per Tenant: Tenants share a collection, but their data is stored in separate partitions. We can isolate data by assigning each tenant a dedicated partition, balancing isolation and search performance. However, this approach is constrained by Milvus’s maximum partition limit.
Partition-Key-Based Multi-Tenancy: This is a more scalable option in which a single collection uses partition keys to distinguish tenants. This method simplifies resource management and supports higher scalability but does not support bulk data inserts.
The table below summarizes the key differences between key multi-tenancy approaches.
| Granularity | Database-level | Collection-level | Partition Key-level |
|---|---|---|---|
| Max Tenants Supported | ~1,000 | ~10,000 | ~10,000,000 |
| Data Organization Flexibility | High: Users can define multiple collections with custom schemas. | Medium: Users are limited to one collection with a custom schema. | Low: All users share a collection, requiring a consistent schema. |
| Cost per User | High | Medium | Low |
| Physical Resource Isolation | Yes | Yes | No |
| RBAC | Yes | Yes | No |
| Search Performance | Strong | Medium | Strong |
Example: Multi-Tenancy Strategy for a RAG-Powered Enterprise Knowledge Base
When designing the multi-tenancy strategy for a RAG system, it’s essential to align your approach with the specific needs of your business and your tenants. Milvus offers various multi-tenancy strategies, and choosing the right one depends on the number of tenants, their requirements, and the level of data isolation needed. Here’s a practical guide for making these decisions, taking a RAG-powered enterprise knowledge base as an example.
Understanding Tenant Structure Before Choosing a Multi-Tenancy Strategy
A RAG-powered enterprise knowledge base often serves a small number of tenants. These tenants are usually independent business units like IT, Sales, Legal, and Marketing, each requiring distinct knowledge base services. For example, the HR Department manages sensitive employee information like onboarding guides and benefits policies, which should be confidential and accessible only to HR personnel.
In this case, each business unit should be treated as a separate tenant and a Database-level multi-tenancy strategy is often the most suitable. By assigning dedicated databases to each tenant, organizations can achieve strong logical isolation, simplifying management and enhancing security. This setup provides tenants with significant flexibility—they can define custom data models within collections, create as many collections as needed, and independently manage access control for their collections.
Enhancing Security with Physical Resource Isolation
In situations where data security is highly prioritized, logical isolation at the database level may not be enough. For example, some business units might handle critical or highly sensitive data, requiring stronger guarantees against interference from other tenants. In such cases, we can implement a physical isolation approach on top of a database-level multi-tenancy structure.
Milvus enables us to map logical components, such as databases and collections, to physical resources. This method ensures that the activities of other tenants do not impact critical operations. Let’s explore how this approach works in practice.
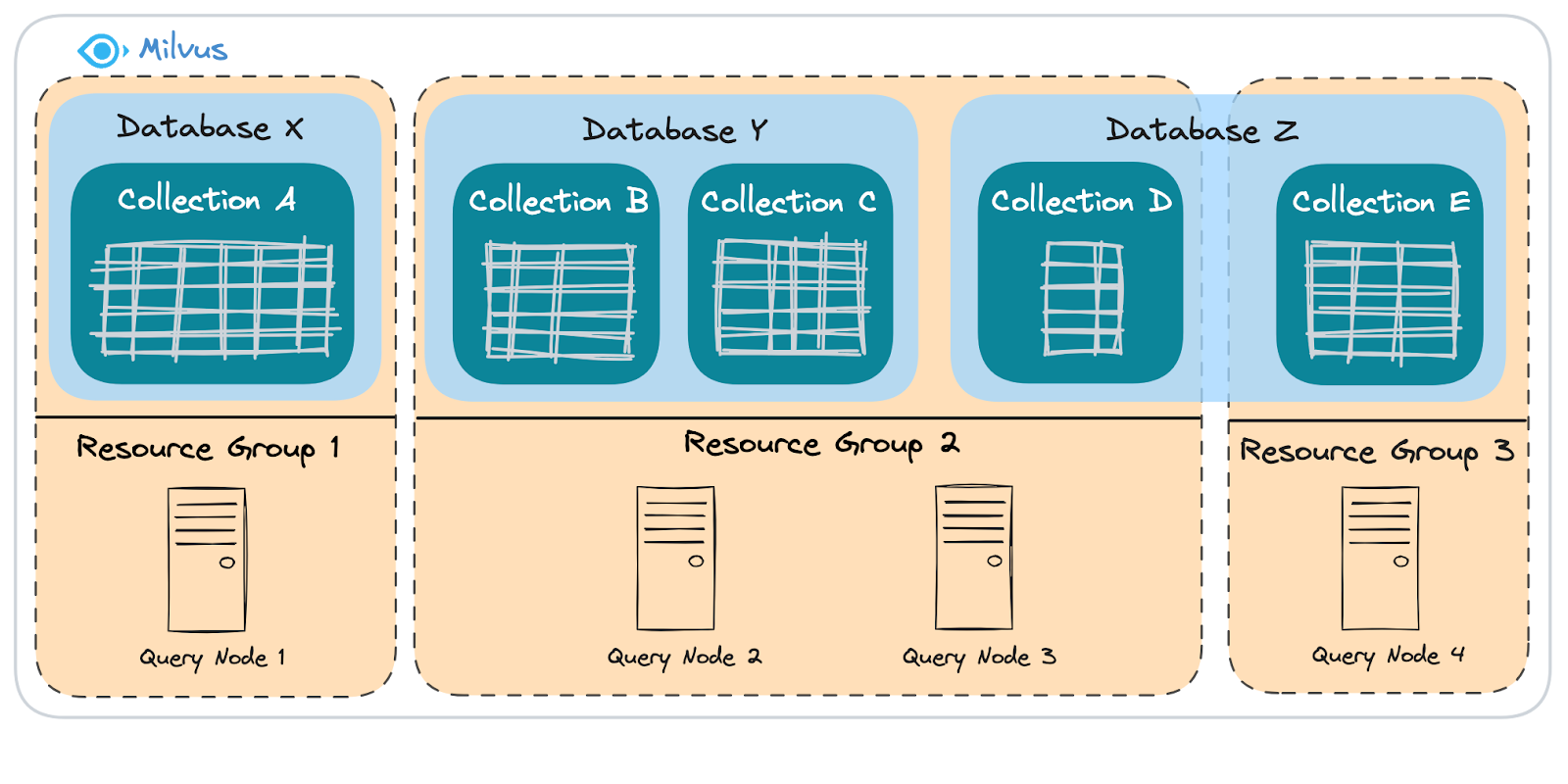 Figure- How Milvus manages physical resources.png
Figure- How Milvus manages physical resources.png
Figure: How Milvus manages physical resources
As shown in the diagram above, there are three layers of resource management in Milvus: Query Node, Resource Group, and Database.
Query Node: The component that processes query tasks. It runs on a physical machine or container (e.g., a pod in Kubernetes).
Resource Group: A collection of Query Nodes that acts as a bridge between logical components (databases and collections) and physical resources. You can allocate one or more databases or collections to a single Resource Group.
In the example shown in the diagram above, there are three logical Databases: X, Y, and Z.
Database X: Contains Collection A.
Database Y: Contains Collections B and C.
Database Z: Contains Collections D and E.
Let’s say Database X holds a critical knowledge base that we don’t want to be affected by the load from Database Y or Database Z. To ensure data isolation:
Database X is assigned its own Resource Group to guarantee that its critical knowledge base is unaffected by workloads from other databases.
Collection E is also allocated to a separate Resource Group within its parent database (Z). This provides isolation at the collection level for specific critical data within a shared database.
Meanwhile, the remaining collections in Databases Y and Z share the physical resources of Resource Group 2.
By carefully mapping logical components to physical resources, organizations can achieve a flexible, scalable, and secure multi-tenancy architecture tailored to their specific business needs.
Designing End User-Level Access
Now that we’ve learned the best practices for choosing a multi-tenancy strategy for an enterprise RAG, let’s explore how to design user-level access in such systems.
In these systems, end users usually interact with the knowledge base in a read-only mode through LLMs. However, organizations still need to track such Q&A data generated by users and link it to specific users for various purposes, such as improving the knowledge base’s accuracy or offering personalized services.
Take a hospital’s smart consultation service desk as an example. Patients might ask questions like, “Are there any available appointments with the specialist today?” or “Is there any specific preparation needed for my upcoming surgery?” While these questions don’t directly impact the knowledge base, it’s important for the hospital to track such interactions to improve services. These Q&A pairs are usually stored in a separate database (it doesn’t necessarily have to be a vector database) dedicated to logging interactions.
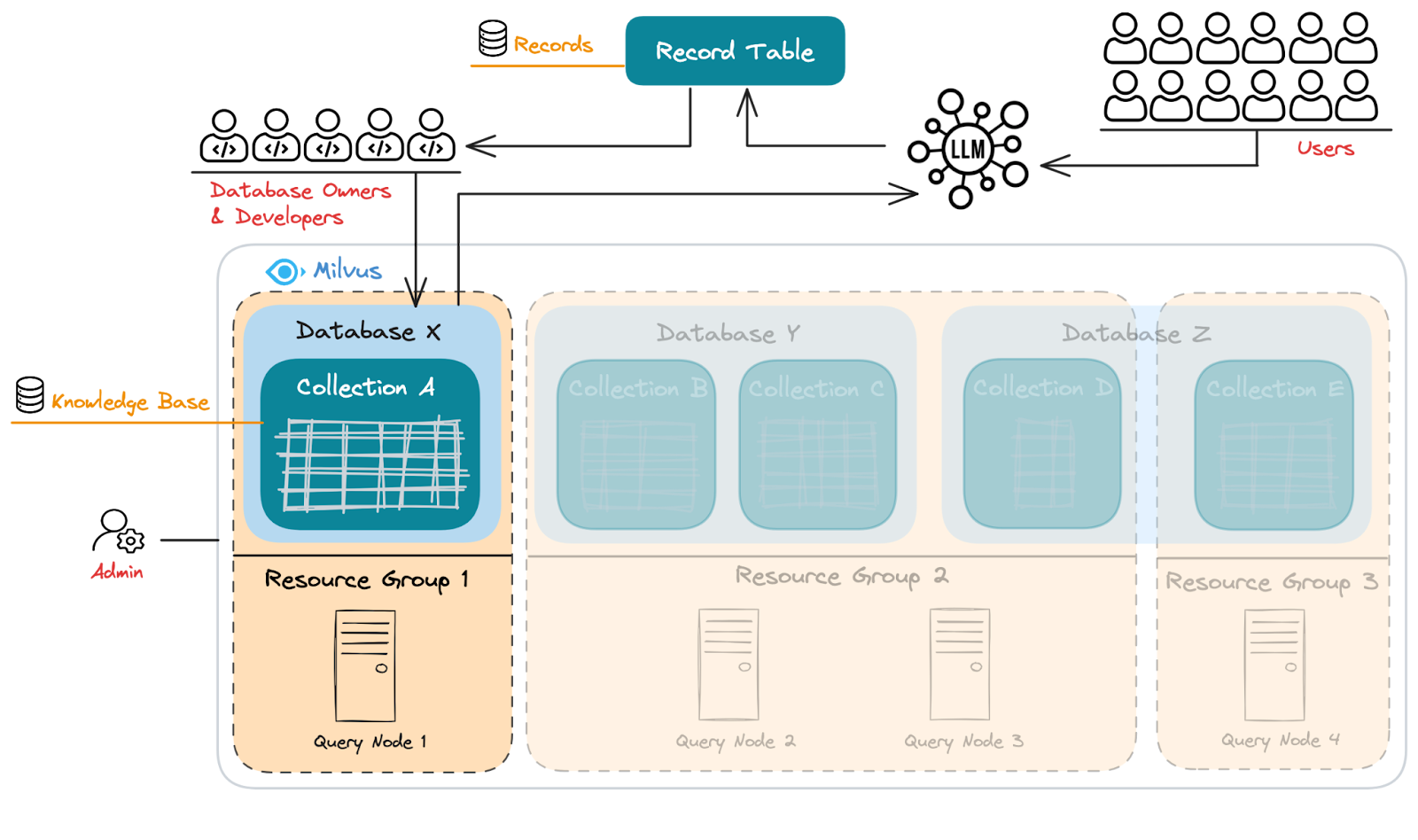 Figure- The multi-tenancy architecture for an enterprise RAG knowledge base .png
Figure- The multi-tenancy architecture for an enterprise RAG knowledge base .png
Figure: The multi-tenancy architecture for an enterprise RAG knowledge base
The diagram above shows the multi-tenancy architecture of an enterprise RAG system.
System Administrators oversee the RAG system, manage resource allocation, assign databases, map them to resource groups, and ensure scalability. They handle the physical infrastructure, as shown in the diagram, where each resource group (e.g., Resource Group 1, 2, and 3) is mapped to physical servers (query nodes).
Tenants (Database owners and developers) manage the knowledge base, iterating on it based on the user-generated Q&A data, as shown in the diagram. Different databases (Database X, Y, Z) contain collections with different knowledge base content (Collection A, B, etc.).
End Users interact with the system in a read-only manner through the LLM. As they query the system, their questions are logged in the separate Q&A record table (a separate database), continuously feeding valuable data back into the system.
This design ensures that each process layer—from user interaction to system administration—works seamlessly, helping the organization build a robust and continuously improving knowledge base.
Summary
In this blog, we’ve explored how multi-tenancy frameworks play a critical role in the scalability, security, and performance of RAG-powered knowledge bases. By isolating data and resources for different tenants, businesses can ensure privacy, regulatory compliance, and optimized resource allocation across a shared infrastructure. Milvus, with its flexible multi-tenancy strategies, allows businesses to choose the right level of data isolation—from database level to partition level—depending on their specific needs. Choosing the right multi-tenancy approach ensures companies can provide tailored services to tenants, even when dealing with diverse data and workloads.
By following the best practices outlined here, organizations can effectively design and manage multi-tenancy RAG systems that not only deliver superior user experiences but also scale effortlessly as business needs grow. Milvus’ architecture ensures that enterprises can maintain high levels of isolation, security, and performance, making it a crucial component in building enterprise-grade, RAG-powered knowledge bases.
Stay Tuned for More Insights into Multi-Tenancy RAG
In this blog, we’ve discussed how Milvus’ multi-tenancy strategies are designed to manage tenants, but not end users within those tenants. End-user interactions usually happen at the application layer, while the vector database itself remains unaware of those users.
You might be wondering: If I want to provide more precise answers based on each end user’s query history, doesn’t Milvus need to maintain a personalized Q&A context for each user?
That’s a great question, and the answer really depends on the use case. For example, in an on-demand consultation service, queries are random, and the main focus is on the quality of the knowledge base rather than on keeping track of a user’s historical context.
However, in other cases, RAG systems must be context-aware. When this is required, Milvus needs to collaborate with the application layer to maintain a personalized memory of each user’s context. This design is especially important for applications with massive end users, which we’ll explore in greater detail in my next post. Stay tuned for more insights!
- Introduction
- What is Multi-Tenancy and Why It Matters
- Multi-Tenancy Strategies in Milvus
- How Milvus Organizes User Data
- Database-Level Multi-Tenancy
- Collection-Level Multi-Tenancy
- Partition-Level Multi-Tenancy
- Example: Multi-Tenancy Strategy for a RAG-Powered Enterprise Knowledge Base
- Understanding Tenant Structure Before Choosing a Multi-Tenancy Strategy
- Enhancing Security with Physical Resource Isolation
- Designing End User-Level Access
- Summary
- Stay Tuned for More Insights into Multi-Tenancy RAG
On This Page
Try Managed Milvus for Free
Zilliz Cloud is hassle-free, powered by Milvus and 10x faster.
Get StartedLike the article? Spread the word



