Comparing Vector Databases, Vector Search Libraries, and Vector Search Plugins

Hey there - welcome back to Vector Database 101!
The surge in ChatGPT and other large language models (LLMs) has driven the growth of vector search technologies, featuring specialized vector databases like Milvus and Zilliz Cloud alongside libraries such as FAISS and integrated vector search plugins within conventional databases.
In our previous series post, we delved into the fundamentals of vector databases. In this post, we’ll continue to explore the intricate realm of vector search, comparing vector databases, vector search plugins, and vector search libraries.
What is vector search?
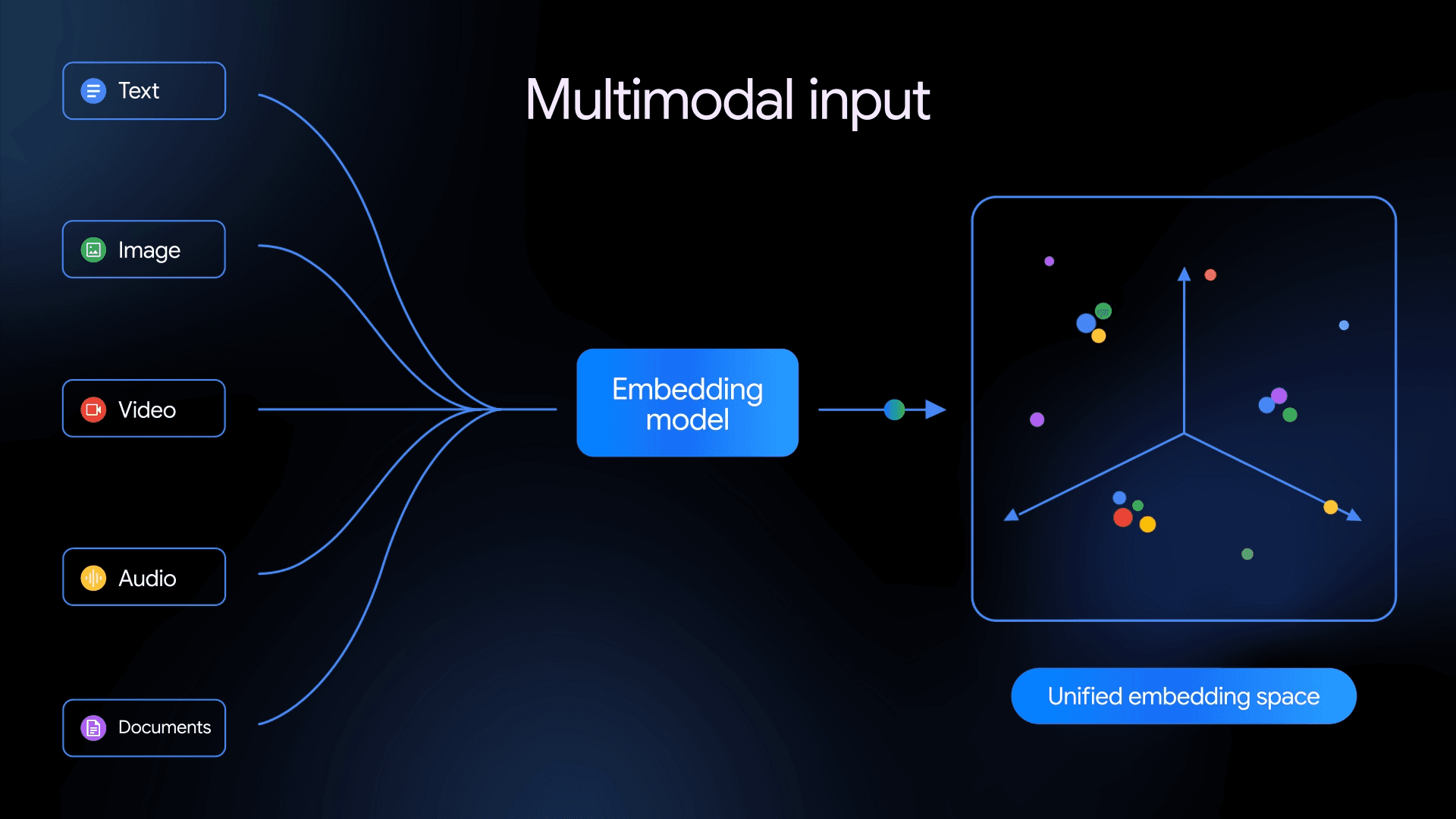
Vector search, also known as vector similarity search, is a technique for retrieving the top-k results that are most similar or semantically related to a given query vector among an extensive collection of dense vector data. Before conducting similarity searches, we leverage neural networks to transform unstructured data, such as text, images, videos, and audio, into high-dimensional numerical vectors called embedding vectors. After generating embedding vectors, vector search engines compare the spatial distance between the input query vector and the vectors in the vector stores. The closer they are in space, the more similar they are.
Multiple vector search technologies are available in the market, including machine learning libraries like Python’s NumPy, vector search libraries like FAISS, vector search plugins built on traditional databases, and specialized vector databases like Milvus and Zilliz Cloud.
Vector databases vs. vector search libraries
Specialized vector databases are not the only stack for similarity searches. Before the advent of vector databases, many vector searching libraries, such as FAISS, ScaNN, and HNSW, were used for vector retrieval.
Vector search libraries can help you quickly build a high-performance prototype vector search system. Taking FAISS as an example, it is open-source and developed by Meta for efficient similarity search and dense vector clustering. FAISS can handle vector collections of any size, even those that cannot be fully loaded into memory. Additionally, FAISS offers tools for evaluation and parameter tuning. Even though written in C++, FAISS provides a Python/NumPy interface.
However, vector search libraries are merely lightweight ANN libraries rather than managed solutions, and they have limited functionality. If your dataset is small and limited, these libraries can be sufficient for unstructured data processing, even for systems running in production. However, as dataset sizes increase and more users are onboarded, the scale problem becomes increasingly difficult to solve. Moreover, they don’t allow any modifications to their index data and cannot be queried during data import.
By contrast, vector databases are a more optimal solution for unstructured data storage and retrieval. They can store and query millions or even billions of vectors while providing real-time responses simultaneously; they’re highly scalable to meet users’ growing business needs.
In addition, vector databases like Milvus have much more user-friendly features for structured/semi-structured data: cloud-nativity, multi-tenancy, scalability, etc. These features will become clear as we dive deeper into this tutorial.
They also operate in a totally different layer of abstraction from vector search libraries - vector databases are full-fledged services, while ANN libraries are meant to be integrated into the application that you’re developing. In this sense, ANN libraries are one of the many components that vector databases are built on top of, similar to how Elasticsearch is built on top of Apache Lucene.
To give an example of why this abstraction is so important, let’s look at inserting a new unstructured data element into a vector database. This is super easy in Milvus:
from pymilvus import Collectioncollection = Collection('book')mr = collection.insert(data)
It’s really as easy as that - 3 lines of code. With a library such as FAISS or ScaNN, there is, unfortunately, no easy way of doing this without manually re-creating the entire index at certain checkpoints. Even if you could, vector search libraries still lack scalability and multi-tenancy, two of the most important vector database features.
Vector databases vs. vector search plugins for traditional databases
Great, now that we’ve established the difference between vector search libraries and vector databases, let’s take a look at how vector databases differ from vector search plugins.
An increasing number of traditional relational databases, and search systems such as Clickhouse and Elasticsearch are including built-in vector search plugins. Elasticsearch 8.0, for example, includes vector insertion and ANN search functionality that can be called via restful API endpoints. The problem with vector search plugins should be clear as night and day - these solutions do not take a full-stack approach to embedding management and vector search. Instead, these plugins are meant to be enhancements on top of existing architectures, thereby making them limited and unoptimized. Developing an unstructured data application atop a traditional database would be like trying to fit lithium batteries and electric motors inside the frame of a gas-powered car - not a great idea!
To illustrate why this is, let’s go back to the list of features that a vector database should implement (from the first section). Vector search plugins are missing two of these features - tunability and user-friendly APIs/SDKs. I’ll continue to use Elasticsearch’s ANN engine as an example; other vector search plugins operate very similarly so I won’t go too much further into detail. Elasticsearch supports vector storage via the dense_vector data field type and allows for querying via the knnsearch endpoint:
PUT index
{
"mappings": {
"properties": {
"image-vector": {
"type": "dense_vector",
"dims": 128,
"index": true,
"similarity": "l2_norm"
}
}
}
}
PUT index/_doc
{
"image-vector": [0.12, 1.34, ...]
}
GET index/_knn_search
{
"knn": {
"field": "image-vector",
"query_vector": [-0.5, 9.4, ...],
"k": 10,
"num_candidates": 100
}
}
Elasticsearch’s ANN plugin supports only one indexing algorithm: Hierarchical Navigable Small Worlds, also known as HNSW (I like to think that the creator was ahead of Marvel when it came to popularizing the multiverse). On top of that, only L2/Euclidean distance is supported as a distance metric. This is an okay start, but let’s compare it to Milvus, a full-fledged vector database. Using pymilvus:
>>> field1 = FieldSchema(name='id', dtype=DataType.INT64, description='int64', is_primary=True)
>>> field2 = FieldSchema(name='embedding', dtype=DataType.FLOAT_VECTOR, description='embedding', dim=128, is_primary=False)
>>> schema = CollectionSchema(fields=[field1, field2], description='hello world collection')
>>> collection = Collection(name='my_collection', data=None, schema=schema)
>>> index_params = {
'index_type': 'IVF_FLAT',
'params': {'nlist': 1024},
"metric_type": 'L2'}
>>> collection.create_index('embedding', index_params)
>>> search_param = {
'data': vector,
'anns_field': 'embedding',
'param': {'metric_type': 'L2', 'params': {'nprobe': 16}},
'limit': 10,
'expr': 'id_field > 0'
}
>>> results = collection.search(**search_param)
While both Elasticsearch and Milvus have methods for creating indexes, inserting embedding vectors, and performing nearest neighbor search, it’s clear from these examples that Milvus has a more intuitive vector search API (better user-facing API) and broader vector index + distance metric support (better tunability). Milvus also plans to support more vector indices and allow for querying via SQL-like statements in the future, further improving both tunability and usability.
We just blew through quite a bit of content. This section was admittedly fairly long, so for those of you who skimmed it, here’s a quick tl;dr: Milvus is better than vector search plugins because Milvus was built from the ground-up as a vector database, allowing for a richer set of features and an architecture more suited towards unstructured data.
How to choose from different vector search technologies?
Not all vector databases are created equal; each possesses unique traits that cater to specific applications. Vector search libraries and plugins are user-friendly and ideal for handling small-scale production environments with millions of vectors. If your data size is small and you just require basic vector search functionality, these technologies are sufficient for your business.
However, a specialized vector database should be your top choice for data-intensive businesses dealing with hundreds of millions of vectors and demanding real-time responses. Milvus, for instance, effortlessly manages billions of vectors, offering lightning-fast query speeds and rich functionality. Moreover, fully managed solutions like Zilliz prove even more advantageous, liberating you from operational challenges and enabling an exclusive focus on your core business activities.
Take another look at the Vector Database 101 courses
- Introduction to Unstructured Data
- What is a Vector Database?
- Comparing Vector Databases, Vector Search Libraries, and Vector Search Plugins
- Introduction to Milvus
- Milvus Quickstart
- Introduction to Vector Similarity Search
- Vector Index Basics and the Inverted File Index
- Scalar Quantization and Product Quantization
- Hierarchical Navigable Small Worlds (HNSW)
- Approximate Nearest Neighbors Oh Yeah (ANNOY)
- Choosing the Right Vector Index for Your Project
- DiskANN and the Vamana Algorithm
- What is vector search?
- Vector databases vs. vector search libraries
- Vector databases vs. vector search plugins for traditional databases
- How to choose from different vector search technologies?
- Take another look at the Vector Database 101 courses
On This Page
Try Managed Milvus for Free
Zilliz Cloud is hassle-free, powered by Milvus and 10x faster.
Get StartedLike the article? Spread the word