Полнотекстовый поиск
Полнотекстовый поиск - это функция поиска документов, содержащих определенные термины или фразы в текстовых массивах данных, с последующим ранжированием результатов по релевантности. Эта функция позволяет преодолеть ограничения семантического поиска, который может упускать из виду точные термины, обеспечивая получение наиболее точных и контекстуально релевантных результатов. Кроме того, она упрощает векторный поиск, принимая исходный текст, автоматически преобразуя текстовые данные в разреженные вкрапления без необходимости вручную генерировать векторные вкрапления.
Эта функция, использующая алгоритм BM25 для оценки релевантности, особенно ценна в сценариях поиска с расширенной генерацией (RAG), где приоритет отдается документам, которые точно соответствуют определенным поисковым терминам.
Интегрируя полнотекстовый поиск с плотным векторным поиском на основе семантики, вы можете повысить точность и релевантность результатов поиска. Дополнительную информацию см. в разделе Гибридный поиск.
Реализация BM25
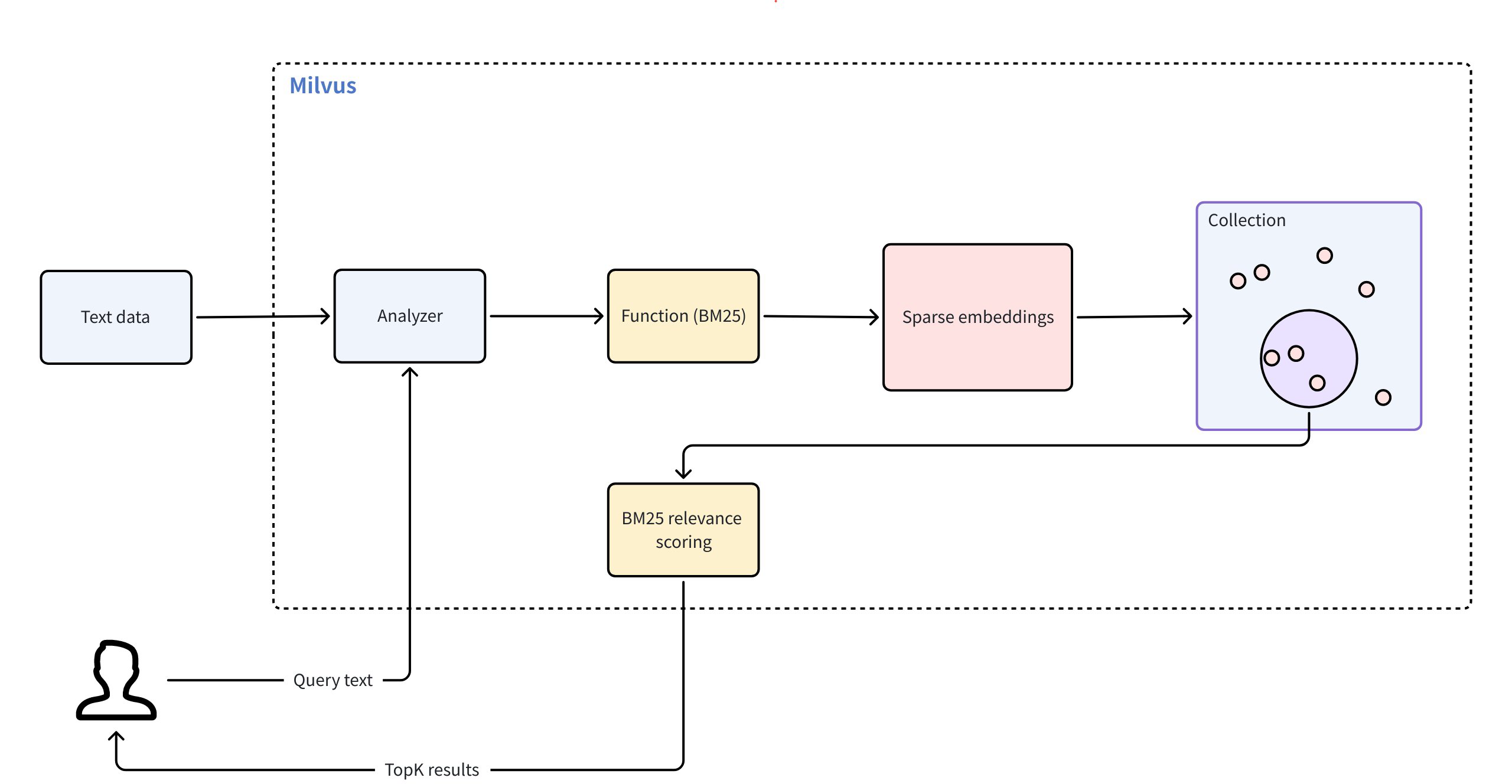
Milvus обеспечивает полнотекстовый поиск на основе алгоритма релевантности BM25 - широко распространенной функции оценки в информационно-поисковых системах. Milvus интегрирует его в рабочий процесс поиска, чтобы предоставлять точные текстовые результаты, ранжированные по релевантности.
Полнотекстовый поиск в Milvus осуществляется по следующей схеме:
Ввод исходного текста: Вы вставляете текстовые документы или задаете запрос, используя обычный текст, без использования моделей встраивания.
Анализ текста: Milvus использует анализатор для преобразования текста в содержательные термины, которые можно индексировать и искать.
Обработка функций BM25: Встроенная функция преобразует эти термины в разреженные векторные представления, оптимизированные для скоринга BM25.
Хранилище коллекций: Milvus сохраняет полученные разреженные вкрапления в коллекции для быстрого поиска и ранжирования.
Оценка релевантности BM25: Во время поиска Milvus применяет функцию оценки релевантности BM25 для расчета релевантности документов и возвращает ранжированные результаты, которые наилучшим образом соответствуют условиям запроса.
 Полнотекстовый поиск
Полнотекстовый поиск
Чтобы использовать полнотекстовый поиск, выполните следующие основные действия:
Создайте коллекцию: Задайте необходимые поля и определите функцию BM25, которая преобразует необработанный текст в разреженные вкрапления.
Вставьте данные: Добавьте в коллекцию документы с необработанным текстом.
Выполните поиск: Используйте текст запроса на естественном языке для получения ранжированных результатов, основанных на релевантности BM25.
Создание коллекции для полнотекстового поиска BM25
Чтобы включить полнотекстовый поиск на базе BM25, необходимо подготовить коллекцию с необходимыми полями, определить функцию BM25 для генерации разреженных векторов, настроить индекс, а затем создать коллекцию.
Определение полей схемы
Схема вашей коллекции должна включать как минимум три обязательных поля:
Первичное поле: Уникально идентифицирует каждую сущность в коллекции.
Текстовое поле (
VARCHAR): Хранит необработанные текстовые документы. Необходимо установить значениеenable_analyzer=True, чтобы Milvus мог обрабатывать текст для ранжирования релевантности BM25. По умолчанию Milvus используетstandardанализатор для анализа текста. Чтобы настроить другой анализатор, обратитесь к разделу Обзор анализаторов.Разреженное векторное поле (
SPARSE_FLOAT_VECTOR): Хранит разреженные вкрапления, автоматически генерируемые функцией BM25.
from pymilvus import MilvusClient, DataType, Function, FunctionType
client = MilvusClient(
uri="http://localhost:19530",
token="root:Milvus"
)
schema = client.create_schema()
schema.add_field(field_name="id", datatype=DataType.INT64, is_primary=True, auto_id=True) # Primary field
schema.add_field(field_name="text", datatype=DataType.VARCHAR, max_length=1000, enable_analyzer=True) # Text field
schema.add_field(field_name="sparse", datatype=DataType.SPARSE_FLOAT_VECTOR) # Sparse vector field; no dim required for sparse vectors
import io.milvus.v2.common.DataType;
import io.milvus.v2.service.collection.request.AddFieldReq;
import io.milvus.v2.service.collection.request.CreateCollectionReq;
CreateCollectionReq.CollectionSchema schema = CreateCollectionReq.CollectionSchema.builder()
.build();
schema.addField(AddFieldReq.builder()
.fieldName("id")
.dataType(DataType.Int64)
.isPrimaryKey(true)
.autoID(true)
.build());
schema.addField(AddFieldReq.builder()
.fieldName("text")
.dataType(DataType.VarChar)
.maxLength(1000)
.enableAnalyzer(true)
.build());
schema.addField(AddFieldReq.builder()
.fieldName("sparse")
.dataType(DataType.SparseFloatVector)
.build());
import (
"context"
"fmt"
"github.com/milvus-io/milvus/client/v2/column"
"github.com/milvus-io/milvus/client/v2/entity"
"github.com/milvus-io/milvus/client/v2/index"
"github.com/milvus-io/milvus/client/v2/milvusclient"
)
ctx, cancel := context.WithCancel(context.Background())
defer cancel()
milvusAddr := "localhost:19530"
client, err := milvusclient.New(ctx, &milvusclient.ClientConfig{
Address: milvusAddr,
})
if err != nil {
fmt.Println(err.Error())
// handle error
}
defer client.Close(ctx)
schema := entity.NewSchema()
schema.WithField(entity.NewField().
WithName("id").
WithDataType(entity.FieldTypeInt64).
WithIsPrimaryKey(true).
WithIsAutoID(true),
).WithField(entity.NewField().
WithName("text").
WithDataType(entity.FieldTypeVarChar).
WithEnableAnalyzer(true).
WithMaxLength(1000),
).WithField(entity.NewField().
WithName("sparse").
WithDataType(entity.FieldTypeSparseVector),
)
import { MilvusClient, DataType } from "@zilliz/milvus2-sdk-node";
const address = "http://localhost:19530";
const token = "root:Milvus";
const client = new MilvusClient({address, token});
const schema = [
{
name: "id",
data_type: DataType.Int64,
is_primary_key: true,
},
{
name: "text",
data_type: "VarChar",
enable_analyzer: true,
enable_match: true,
max_length: 1000,
},
{
name: "sparse",
data_type: DataType.SparseFloatVector,
},
];
console.log(res.results)
export schema='{
"autoId": true,
"enabledDynamicField": false,
"fields": [
{
"fieldName": "id",
"dataType": "Int64",
"isPrimary": true
},
{
"fieldName": "text",
"dataType": "VarChar",
"elementTypeParams": {
"max_length": 1000,
"enable_analyzer": true
}
},
{
"fieldName": "sparse",
"dataType": "SparseFloatVector"
}
]
}'
В предыдущей конфигурации,
id: служит первичным ключом и автоматически генерируется с помощьюauto_id=True.text: хранит ваши необработанные текстовые данные для операций полнотекстового поиска. Тип данных должен бытьVARCHAR, так какVARCHAR- это строковый тип данных Milvus для хранения текста.sparse: векторное поле, зарезервированное для хранения внутренних разреженных вкраплений для операций полнотекстового поиска. Тип данных должен бытьSPARSE_FLOAT_VECTOR.
Определение функции BM25
Функция BM25 преобразует токенизированный текст в разреженные векторы, которые поддерживают скоринг BM25.
Определите функцию и добавьте ее в свою схему:
bm25_function = Function(
name="text_bm25_emb", # Function name
input_field_names=["text"], # Name of the VARCHAR field containing raw text data
output_field_names=["sparse"], # Name of the SPARSE_FLOAT_VECTOR field reserved to store generated embeddings
function_type=FunctionType.BM25, # Set to `BM25`
)
schema.add_function(bm25_function)
import io.milvus.common.clientenum.FunctionType;
import io.milvus.v2.service.collection.request.CreateCollectionReq.Function;
import java.util.*;
schema.addFunction(Function.builder()
.functionType(FunctionType.BM25)
.name("text_bm25_emb")
.inputFieldNames(Collections.singletonList("text"))
.outputFieldNames(Collections.singletonList("sparse"))
.build());
function := entity.NewFunction().
WithName("text_bm25_emb").
WithInputFields("text").
WithOutputFields("sparse").
WithType(entity.FunctionTypeBM25)
schema.WithFunction(function)
const functions = [
{
name: 'text_bm25_emb',
description: 'bm25 function',
type: FunctionType.BM25,
input_field_names: ['text'],
output_field_names: ['sparse'],
params: {},
},
];
export schema='{
"autoId": true,
"enabledDynamicField": false,
"fields": [
{
"fieldName": "id",
"dataType": "Int64",
"isPrimary": true
},
{
"fieldName": "text",
"dataType": "VarChar",
"elementTypeParams": {
"max_length": 1000,
"enable_analyzer": true
}
},
{
"fieldName": "sparse",
"dataType": "SparseFloatVector"
}
],
"functions": [
{
"name": "text_bm25_emb",
"type": "BM25",
"inputFieldNames": ["text"],
"outputFieldNames": ["sparse"],
"params": {}
}
]
}'
Параметр |
Описание |
|---|---|
|
Имя функции. Эта функция преобразует необработанный текст из поля |
|
Имя поля |
|
Имя поля, в котором будут храниться сгенерированные внутри поля разреженные векторы. Для |
|
Тип используемой функции. Должно быть |
Если несколько полей VARCHAR требуют обработки BM25, определите по одной функции BM25 для каждого поля, с уникальным именем и выходным полем.
Настройка индекса
После определения схемы с необходимыми полями и встроенной функцией настройте индекс для вашей коллекции.
index_params = client.prepare_index_params()
index_params.add_index(
field_name="sparse",
index_type="SPARSE_INVERTED_INDEX",
metric_type="BM25",
params={
"inverted_index_algo": "DAAT_MAXSCORE",
"bm25_k1": 1.2,
"bm25_b": 0.75
}
)
import io.milvus.v2.common.IndexParam;
Map<String,Object> params = new HashMap<>();
params.put("inverted_index_algo", "DAAT_MAXSCORE");
params.put("bm25_k1", 1.2);
params.put("bm25_b", 0.75);
List<IndexParam> indexes = new ArrayList<>();
indexes.add(IndexParam.builder()
.fieldName("sparse")
.indexType(IndexParam.IndexType.AUTOINDEX)
.metricType(IndexParam.MetricType.BM25)
.extraParams(params)
.build());
indexOption := milvusclient.NewCreateIndexOption("my_collection", "sparse",
index.NewAutoIndex(entity.MetricType(entity.BM25)))
.WithExtraParam("inverted_index_algo", "DAAT_MAXSCORE")
.WithExtraParam("bm25_k1", 1.2)
.WithExtraParam("bm25_b", 0.75)
const index_params = [
{
field_name: "sparse",
metric_type: "BM25",
index_type: "SPARSE_INVERTED_INDEX",
params: {
"inverted_index_algo": "DAAT_MAXSCORE",
"bm25_k1": 1.2,
"bm25_b": 0.75
}
},
];
export indexParams='[
{
"fieldName": "sparse",
"metricType": "BM25",
"indexType": "AUTOINDEX",
"params":{
"inverted_index_algo": "DAAT_MAXSCORE",
"bm25_k1": 1.2,
"bm25_b": 0.75
}
}
]'
Параметр |
Описание |
|---|---|
|
Имя векторного поля для индексации. Для полнотекстового поиска это должно быть поле, в котором хранятся сгенерированные разреженные векторы. В этом примере задайте значение |
|
Тип создаваемого индекса. |
|
Значение этого параметра должно быть установлено на |
|
Словарь дополнительных параметров, специфичных для данного индекса. |
|
Алгоритм, используемый для построения и запроса индекса. Допустимые значения:
|
|
Управляет насыщенностью частот терминов. Более высокие значения увеличивают важность частот терминов при ранжировании документов. Диапазон значений: [1.2, 2.0]. |
|
Управляет степенью нормализации длины документа. Обычно используются значения от 0 до 1, по умолчанию около 0,75. Значение 1 означает отсутствие нормализации длины, а значение 0 - полную нормализацию. |
Создание коллекции
Теперь создайте коллекцию, используя заданные параметры схемы и индекса.
client.create_collection(
collection_name='my_collection',
schema=schema,
index_params=index_params
)
import io.milvus.v2.service.collection.request.CreateCollectionReq;
CreateCollectionReq requestCreate = CreateCollectionReq.builder()
.collectionName("my_collection")
.collectionSchema(schema)
.indexParams(indexes)
.build();
client.createCollection(requestCreate);
err = client.CreateCollection(ctx,
milvusclient.NewCreateCollectionOption("my_collection", schema).
WithIndexOptions(indexOption))
if err != nil {
fmt.Println(err.Error())
// handle error
}
await client.create_collection(
collection_name: 'my_collection',
schema: schema,
index_params: index_params,
functions: functions
);
export CLUSTER_ENDPOINT="http://localhost:19530"
export TOKEN="root:Milvus"
curl --request POST \
--url "${CLUSTER_ENDPOINT}/v2/vectordb/collections/create" \
--header "Authorization: Bearer ${TOKEN}" \
--header "Content-Type: application/json" \
--header "Request-Timeout: 10" \
-d "{
\"collectionName\": \"my_collection\",
\"schema\": $schema,
\"indexParams\": $indexParams
}"
Вставка текстовых данных
После настройки коллекции и индекса вы готовы к вставке текстовых данных. В этом процессе вам нужно только предоставить исходный текст. Встроенная функция, которую мы определили ранее, автоматически генерирует соответствующий разреженный вектор для каждой текстовой записи.
client.insert('my_collection', [
{'text': 'information retrieval is a field of study.'},
{'text': 'information retrieval focuses on finding relevant information in large datasets.'},
{'text': 'data mining and information retrieval overlap in research.'},
])
import com.google.gson.Gson;
import com.google.gson.JsonObject;
import io.milvus.v2.service.vector.request.InsertReq;
Gson gson = new Gson();
List<JsonObject> rows = Arrays.asList(
gson.fromJson("{\"text\": \"information retrieval is a field of study.\"}", JsonObject.class),
gson.fromJson("{\"text\": \"information retrieval focuses on finding relevant information in large datasets.\"}", JsonObject.class),
gson.fromJson("{\"text\": \"data mining and information retrieval overlap in research.\"}", JsonObject.class)
);
client.insert(InsertReq.builder()
.collectionName("my_collection")
.data(rows)
.build());
// go
await client.insert({
collection_name: 'my_collection',
data: [
{'text': 'information retrieval is a field of study.'},
{'text': 'information retrieval focuses on finding relevant information in large datasets.'},
{'text': 'data mining and information retrieval overlap in research.'},
]);
curl --request POST \
--url "${CLUSTER_ENDPOINT}/v2/vectordb/entities/insert" \
--header "Authorization: Bearer ${TOKEN}" \
--header "Content-Type: application/json" \
--header "Request-Timeout: 10" \
-d '{
"data": [
{"text": "information retrieval is a field of study."},
{"text": "information retrieval focuses on finding relevant information in large datasets."},
{"text": "data mining and information retrieval overlap in research."}
],
"collectionName": "my_collection"
}'
Выполнение полнотекстового поиска
После того как вы вставили данные в свою коллекцию, вы можете выполнять полнотекстовый поиск с помощью запросов на основе необработанного текста. Milvus автоматически преобразует ваш запрос в разреженный вектор и ранжирует совпадающие результаты поиска с помощью алгоритма BM25, а затем возвращает результаты topK (limit).
Вы можете выделить совпадающие термины в результатах поиска, настроив текстовый маркер. Подробнее см. в разделе "Выделитель текста".
res = client.search(
collection_name='my_collection',
data=['whats the focus of information retrieval?'],
anns_field='sparse',
output_fields=['text'], # Fields to return in search results; sparse field cannot be output
limit=3,
)
print(res)
import io.milvus.v2.service.vector.request.SearchReq;
import io.milvus.v2.service.vector.request.data.EmbeddedText;
import io.milvus.v2.service.vector.response.SearchResp;
Map<String,Object> searchParams = new HashMap<>();
SearchResp searchResp = client.search(SearchReq.builder()
.collectionName("my_collection")
.data(Collections.singletonList(new EmbeddedText("whats the focus of information retrieval?")))
.annsField("sparse")
.topK(3)
.searchParams(searchParams)
.outputFields(Collections.singletonList("text"))
.build());
annSearchParams := index.NewCustomAnnParam()
resultSets, err := client.Search(ctx, milvusclient.NewSearchOption(
"my_collection", // collectionName
3, // limit
[]entity.Vector{entity.Text("whats the focus of information retrieval?")},
).WithConsistencyLevel(entity.ClStrong).
WithANNSField("sparse").
WithAnnParam(annSearchParams).
WithOutputFields("text"))
if err != nil {
fmt.Println(err.Error())
// handle error
}
for _, resultSet := range resultSets {
fmt.Println("IDs: ", resultSet.IDs.FieldData().GetScalars())
fmt.Println("Scores: ", resultSet.Scores)
fmt.Println("text: ", resultSet.GetColumn("text").FieldData().GetScalars())
}
await client.search(
collection_name: 'my_collection',
data: ['whats the focus of information retrieval?'],
anns_field: 'sparse',
output_fields: ['text'],
limit: 3,
)
curl --request POST \
--url "${CLUSTER_ENDPOINT}/v2/vectordb/entities/search" \
--header "Authorization: Bearer ${TOKEN}" \
--header "Content-Type: application/json" \
--header "Request-Timeout: 10" \
--data-raw '{
"collectionName": "my_collection",
"data": [
"whats the focus of information retrieval?"
],
"annsField": "sparse",
"limit": 3,
"outputFields": [
"text"
],
"searchParams":{
"params":{}
}
}'
Параметр |
Описание |
|---|---|
|
Словарь, содержащий параметры поиска. |
|
Доля малозначимых терминов, которые следует игнорировать при поиске. Подробнее см. в разделе "Разреженный вектор". |
|
Необработанный текст запроса на естественном языке. Milvus автоматически преобразует ваш текстовый запрос в разреженные векторы с помощью функции BM25 - не предоставляйте предварительно вычисленные векторы. |
|
Имя поля, содержащего внутренне сгенерированные разреженные векторы. |
|
Список имен полей, возвращаемых в результатах поиска. Поддерживаются все поля , кроме поля разреженного вектора, содержащего сгенерированные BM25 вкрапления. Общие поля вывода включают поле первичного ключа (например, |
|
Максимальное количество возвращаемых совпадений. |
FAQ
Могу ли я вывести или получить доступ к разреженным векторам, сгенерированным функцией BM25, при полнотекстовом поиске?
Нет, разреженные векторы, сгенерированные функцией BM25, не могут быть напрямую доступны или выведены в полнотекстовом поиске. Вот подробности:
Функция BM25 генерирует разреженные векторы для ранжирования и поиска.
Эти векторы хранятся в разреженном поле, но не могут быть включены в
output_fieldsВы можете вывести только исходные текстовые поля и метаданные (например,
id,text).
Пример:
# ❌ This throws an error - you cannot output the sparse field
client.search(
collection_name='my_collection',
data=['query text'],
anns_field='sparse',
output_fields=['text', 'sparse'] # 'sparse' causes an error
limit=3,
search_params=search_params
)
# ✅ This works - output text fields only
client.search(
collection_name='my_collection',
data=['query text'],
anns_field='sparse',
output_fields=['text']
limit=3,
search_params=search_params
)
Зачем мне определять разреженное векторное поле, если я не могу получить к нему доступ?
Разреженное векторное поле служит внутренним поисковым индексом, подобно индексам баз данных, с которыми пользователи не взаимодействуют напрямую.
Обоснование дизайна:
Разделение забот: Вы работаете с текстом (ввод/вывод), Milvus обрабатывает векторы (внутренняя обработка).
Производительность: Предварительно вычисленные разреженные векторы обеспечивают быстрое ранжирование BM25 во время запросов.
Опыт пользователя: Абстрагирование сложных векторных операций за простым текстовым интерфейсом
Если вам нужен доступ к векторам:
Используйте ручные операции с разреженными векторами вместо полнотекстового поиска
Создавайте отдельные коллекции для пользовательских рабочих процессов с разреженными векторами
Подробнее см. в разделе "Разреженный вектор".