전체 텍스트 검색
전체 텍스트 검색은 텍스트 데이터 세트에서 특정 용어나 구문이 포함된 문서를 검색한 다음 관련성에 따라 결과의 순위를 매기는 기능입니다. 이 기능은 정확한 용어를 놓칠 수 있는 시맨틱 검색의 한계를 극복하여 가장 정확하고 문맥과 연관성이 높은 결과를 얻을 수 있도록 해줍니다. 또한, 원시 텍스트 입력을 받아 벡터 임베딩을 수동으로 생성할 필요 없이 텍스트 데이터를 스파스 임베딩으로 자동 변환함으로써 벡터 검색을 간소화합니다.
관련성 점수에 BM25 알고리즘을 사용하는 이 기능은 특정 검색어와 가장 근접하게 일치하는 문서의 우선순위를 정하는 검색 증강 생성(RAG) 시나리오에서 특히 유용합니다.
전체 텍스트 검색과 시맨틱 기반의 고밀도 벡터 검색을 통합하면 검색 결과의 정확도와 관련성을 높일 수 있습니다. 자세한 내용은 하이브리드 검색을 참조하세요.
BM25 구현
Milvus는 정보 검색 시스템에서 널리 채택된 채점 기능인 BM25 관련성 알고리즘으로 구동되는 전체 텍스트 검색을 제공하며, 이를 검색 워크플로우에 통합하여 정확하고 관련성 순위가 높은 텍스트 결과를 제공합니다.
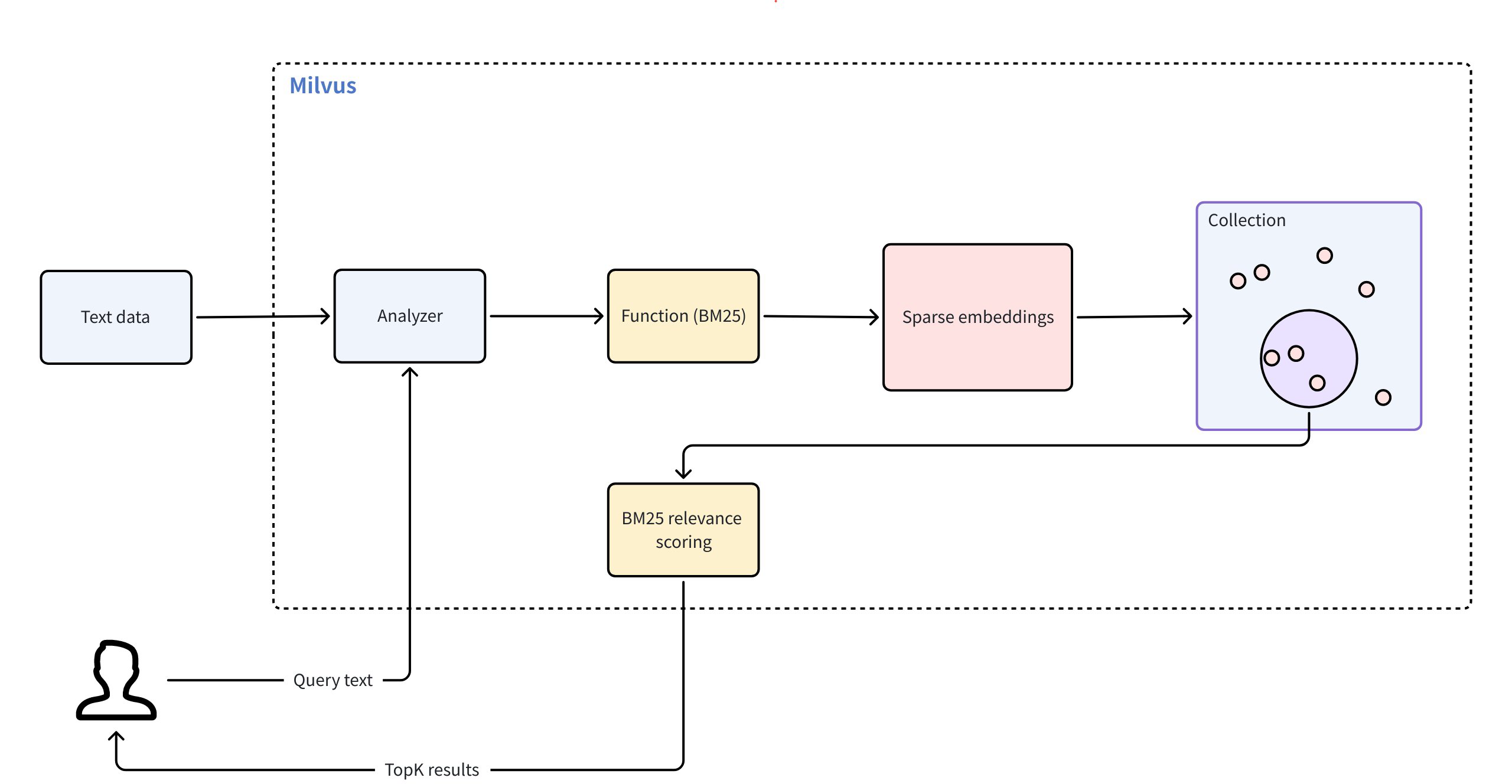
Milvus의 전체 텍스트 검색은 아래의 워크플로우를 따릅니다:
원시 텍스트 입력: 임베딩 모델 없이 텍스트 문서를 삽입하거나 일반 텍스트를 사용하여 쿼리를 입력합니다.
텍스트 분석: Milvus는 분석기를 사용하여 텍스트를 색인 및 검색이 가능한 의미 있는 용어로 처리합니다.
BM25 함수 처리: 내장된 함수가 이러한 용어를 BM25 채점에 최적화된 희소 벡터 표현으로 변환합니다.
컬렉션 저장소: Milvus는 빠른 검색과 순위를 매길 수 있도록 결과 스파스 임베딩을 컬렉션에 저장합니다.
BM25 관련성 점수: 검색 시 Milvus는 BM25 스코어링 기능을 적용하여 문서 관련성을 계산하고 쿼리 용어와 가장 일치하는 순위를 매긴 결과를 반환합니다.
 전체 텍스트 검색
전체 텍스트 검색
전체 텍스트 검색을 사용하려면 다음 주요 단계를 따르세요:
컬렉션을 만듭니다: 필수 필드를 설정하고 원시 텍스트를 스파스 임베딩으로 변환하는 BM25 함수를 정의합니다.
데이터 삽입: 원시 텍스트 문서를 컬렉션에 수집합니다.
검색 수행: 자연어 쿼리 텍스트를 사용하여 BM25 관련성에 따라 순위가 매겨진 결과를 검색합니다.
BM25 전체 텍스트 검색을 위한 컬렉션 만들기
BM25 기반 전체 텍스트 검색을 사용하려면 필수 필드가 포함된 컬렉션을 준비하고, 스파스 벡터를 생성하는 BM25 함수를 정의하고, 인덱스를 구성한 다음 컬렉션을 만들어야 합니다.
스키마 필드 정의
컬렉션 스키마에는 최소 3개의 필수 필드가 포함되어야 합니다:
기본 필드: 컬렉션의 각 엔티티를 고유하게 식별합니다.
텍스트 필드 (
VARCHAR): 원시 텍스트 문서를 저장합니다. Milvus가 BM25 관련성 순위를 위해 텍스트를 처리할 수 있도록enable_analyzer=True을 설정해야 합니다. 기본적으로 Milvus는 텍스트 분석을 위해standard분석기를 사용합니다. 다른 분석기를 구성하려면 분석기 개요를 참조하세요.스파스 벡터 필드 (
SPARSE_FLOAT_VECTOR): BM25 함수에 의해 자동으로 생성된 스파스 임베딩을 저장합니다.
from pymilvus import MilvusClient, DataType, Function, FunctionType
client = MilvusClient(
uri="http://localhost:19530",
token="root:Milvus"
)
schema = client.create_schema()
schema.add_field(field_name="id", datatype=DataType.INT64, is_primary=True, auto_id=True) # Primary field
schema.add_field(field_name="text", datatype=DataType.VARCHAR, max_length=1000, enable_analyzer=True) # Text field
schema.add_field(field_name="sparse", datatype=DataType.SPARSE_FLOAT_VECTOR) # Sparse vector field; no dim required for sparse vectors
import io.milvus.v2.common.DataType;
import io.milvus.v2.service.collection.request.AddFieldReq;
import io.milvus.v2.service.collection.request.CreateCollectionReq;
CreateCollectionReq.CollectionSchema schema = CreateCollectionReq.CollectionSchema.builder()
.build();
schema.addField(AddFieldReq.builder()
.fieldName("id")
.dataType(DataType.Int64)
.isPrimaryKey(true)
.autoID(true)
.build());
schema.addField(AddFieldReq.builder()
.fieldName("text")
.dataType(DataType.VarChar)
.maxLength(1000)
.enableAnalyzer(true)
.build());
schema.addField(AddFieldReq.builder()
.fieldName("sparse")
.dataType(DataType.SparseFloatVector)
.build());
import (
"context"
"fmt"
"github.com/milvus-io/milvus/client/v2/column"
"github.com/milvus-io/milvus/client/v2/entity"
"github.com/milvus-io/milvus/client/v2/index"
"github.com/milvus-io/milvus/client/v2/milvusclient"
)
ctx, cancel := context.WithCancel(context.Background())
defer cancel()
milvusAddr := "localhost:19530"
client, err := milvusclient.New(ctx, &milvusclient.ClientConfig{
Address: milvusAddr,
})
if err != nil {
fmt.Println(err.Error())
// handle error
}
defer client.Close(ctx)
schema := entity.NewSchema()
schema.WithField(entity.NewField().
WithName("id").
WithDataType(entity.FieldTypeInt64).
WithIsPrimaryKey(true).
WithIsAutoID(true),
).WithField(entity.NewField().
WithName("text").
WithDataType(entity.FieldTypeVarChar).
WithEnableAnalyzer(true).
WithMaxLength(1000),
).WithField(entity.NewField().
WithName("sparse").
WithDataType(entity.FieldTypeSparseVector),
)
import { MilvusClient, DataType } from "@zilliz/milvus2-sdk-node";
const address = "http://localhost:19530";
const token = "root:Milvus";
const client = new MilvusClient({address, token});
const schema = [
{
name: "id",
data_type: DataType.Int64,
is_primary_key: true,
},
{
name: "text",
data_type: "VarChar",
enable_analyzer: true,
enable_match: true,
max_length: 1000,
},
{
name: "sparse",
data_type: DataType.SparseFloatVector,
},
];
console.log(res.results)
export schema='{
"autoId": true,
"enabledDynamicField": false,
"fields": [
{
"fieldName": "id",
"dataType": "Int64",
"isPrimary": true
},
{
"fieldName": "text",
"dataType": "VarChar",
"elementTypeParams": {
"max_length": 1000,
"enable_analyzer": true
}
},
{
"fieldName": "sparse",
"dataType": "SparseFloatVector"
}
]
}'
앞의 config,
id는 기본 키 역할을 하며auto_id=True로 자동 생성됩니다.text는 전체 텍스트 검색 작업을 위한 원시 텍스트 데이터를 저장합니다. 데이터 유형은VARCHAR이 텍스트 저장을 위한 Milvus 문자열 데이터 유형이므로VARCHAR여야 합니다.sparse전체 텍스트 검색 작업을 위해 내부적으로 생성된 스파스 임베딩을 저장하기 위해 예약된 벡터 필드입니다. 데이터 유형은SPARSE_FLOAT_VECTOR여야 합니다.
BM25 함수 정의
BM25 함수는 토큰화된 텍스트를 BM25 채점을 지원하는 스파스 벡터로 변환합니다.
함수를 정의하고 스키마에 추가합니다:
bm25_function = Function(
name="text_bm25_emb", # Function name
input_field_names=["text"], # Name of the VARCHAR field containing raw text data
output_field_names=["sparse"], # Name of the SPARSE_FLOAT_VECTOR field reserved to store generated embeddings
function_type=FunctionType.BM25, # Set to `BM25`
)
schema.add_function(bm25_function)
import io.milvus.common.clientenum.FunctionType;
import io.milvus.v2.service.collection.request.CreateCollectionReq.Function;
import java.util.*;
schema.addFunction(Function.builder()
.functionType(FunctionType.BM25)
.name("text_bm25_emb")
.inputFieldNames(Collections.singletonList("text"))
.outputFieldNames(Collections.singletonList("sparse"))
.build());
function := entity.NewFunction().
WithName("text_bm25_emb").
WithInputFields("text").
WithOutputFields("sparse").
WithType(entity.FunctionTypeBM25)
schema.WithFunction(function)
const functions = [
{
name: 'text_bm25_emb',
description: 'bm25 function',
type: FunctionType.BM25,
input_field_names: ['text'],
output_field_names: ['sparse'],
params: {},
},
];
export schema='{
"autoId": true,
"enabledDynamicField": false,
"fields": [
{
"fieldName": "id",
"dataType": "Int64",
"isPrimary": true
},
{
"fieldName": "text",
"dataType": "VarChar",
"elementTypeParams": {
"max_length": 1000,
"enable_analyzer": true
}
},
{
"fieldName": "sparse",
"dataType": "SparseFloatVector"
}
],
"functions": [
{
"name": "text_bm25_emb",
"type": "BM25",
"inputFieldNames": ["text"],
"outputFieldNames": ["sparse"],
"params": {}
}
]
}'
파라미터 |
설명 |
|---|---|
|
함수의 이름입니다. 이 함수는 |
|
텍스트를 스파스 벡터로 변환해야 하는 |
|
내부적으로 생성된 스파스 벡터가 저장될 필드의 이름입니다. |
|
사용할 함수의 유형입니다. |
여러 개의 VARCHAR 필드에 BM25 처리가 필요한 경우, 각 필드마다 고유한 이름과 출력 필드를 가진 하나의 BM25 함수를 정의합니다.
인덱스 구성
필요한 필드와 기본 제공 함수로 스키마를 정의한 후 컬렉션의 인덱스를 설정합니다.
index_params = client.prepare_index_params()
index_params.add_index(
field_name="sparse",
index_type="SPARSE_INVERTED_INDEX",
metric_type="BM25",
params={
"inverted_index_algo": "DAAT_MAXSCORE",
"bm25_k1": 1.2,
"bm25_b": 0.75
}
)
import io.milvus.v2.common.IndexParam;
Map<String,Object> params = new HashMap<>();
params.put("inverted_index_algo", "DAAT_MAXSCORE");
params.put("bm25_k1", 1.2);
params.put("bm25_b", 0.75);
List<IndexParam> indexes = new ArrayList<>();
indexes.add(IndexParam.builder()
.fieldName("sparse")
.indexType(IndexParam.IndexType.AUTOINDEX)
.metricType(IndexParam.MetricType.BM25)
.extraParams(params)
.build());
indexOption := milvusclient.NewCreateIndexOption("my_collection", "sparse",
index.NewAutoIndex(entity.MetricType(entity.BM25)))
.WithExtraParam("inverted_index_algo", "DAAT_MAXSCORE")
.WithExtraParam("bm25_k1", 1.2)
.WithExtraParam("bm25_b", 0.75)
const index_params = [
{
field_name: "sparse",
metric_type: "BM25",
index_type: "SPARSE_INVERTED_INDEX",
params: {
"inverted_index_algo": "DAAT_MAXSCORE",
"bm25_k1": 1.2,
"bm25_b": 0.75
}
},
];
export indexParams='[
{
"fieldName": "sparse",
"metricType": "BM25",
"indexType": "AUTOINDEX",
"params":{
"inverted_index_algo": "DAAT_MAXSCORE",
"bm25_k1": 1.2,
"bm25_b": 0.75
}
}
]'
파라미터 |
설명 |
|---|---|
|
인덱싱할 벡터 필드의 이름입니다. 전체 텍스트 검색의 경우, 생성된 스파스 벡터를 저장하는 필드여야 합니다. 이 예에서는 값을 |
|
생성할 인덱스의 유형. |
|
특히 전체 텍스트 검색 기능을 사용하려면 이 매개변수의 값을 |
|
인덱스와 관련된 추가 매개변수 사전입니다. |
|
인덱스 구축 및 쿼리에 사용되는 알고리즘입니다. 유효한 값입니다:
|
|
용어 빈도 포화도를 제어합니다. 값이 높을수록 문서 순위에서 용어 빈도의 중요도가 높아집니다. 값 범위: [1.2, 2.0]. |
|
문서 길이가 정규화되는 정도를 제어합니다. 일반적으로 0에서 1 사이의 값이 사용되며, 일반적인 기본값은 0.75 정도입니다. 값이 1이면 길이 정규화를 하지 않고, 값이 0이면 전체 정규화를 의미합니다. |
컬렉션 만들기
이제 정의한 스키마 및 인덱스 매개변수를 사용하여 컬렉션을 생성합니다.
client.create_collection(
collection_name='my_collection',
schema=schema,
index_params=index_params
)
import io.milvus.v2.service.collection.request.CreateCollectionReq;
CreateCollectionReq requestCreate = CreateCollectionReq.builder()
.collectionName("my_collection")
.collectionSchema(schema)
.indexParams(indexes)
.build();
client.createCollection(requestCreate);
err = client.CreateCollection(ctx,
milvusclient.NewCreateCollectionOption("my_collection", schema).
WithIndexOptions(indexOption))
if err != nil {
fmt.Println(err.Error())
// handle error
}
await client.create_collection(
collection_name: 'my_collection',
schema: schema,
index_params: index_params,
functions: functions
);
export CLUSTER_ENDPOINT="http://localhost:19530"
export TOKEN="root:Milvus"
curl --request POST \
--url "${CLUSTER_ENDPOINT}/v2/vectordb/collections/create" \
--header "Authorization: Bearer ${TOKEN}" \
--header "Content-Type: application/json" \
--header "Request-Timeout: 10" \
-d "{
\"collectionName\": \"my_collection\",
\"schema\": $schema,
\"indexParams\": $indexParams
}"
텍스트 데이터 삽입
컬렉션과 인덱스를 설정했으면 텍스트 데이터를 삽입할 준비가 되었습니다. 이 과정에서는 원시 텍스트만 제공하면 됩니다. 앞서 정의한 내장 함수는 각 텍스트 항목에 해당하는 스파스 벡터를 자동으로 생성합니다.
client.insert('my_collection', [
{'text': 'information retrieval is a field of study.'},
{'text': 'information retrieval focuses on finding relevant information in large datasets.'},
{'text': 'data mining and information retrieval overlap in research.'},
])
import com.google.gson.Gson;
import com.google.gson.JsonObject;
import io.milvus.v2.service.vector.request.InsertReq;
Gson gson = new Gson();
List<JsonObject> rows = Arrays.asList(
gson.fromJson("{\"text\": \"information retrieval is a field of study.\"}", JsonObject.class),
gson.fromJson("{\"text\": \"information retrieval focuses on finding relevant information in large datasets.\"}", JsonObject.class),
gson.fromJson("{\"text\": \"data mining and information retrieval overlap in research.\"}", JsonObject.class)
);
client.insert(InsertReq.builder()
.collectionName("my_collection")
.data(rows)
.build());
// go
await client.insert({
collection_name: 'my_collection',
data: [
{'text': 'information retrieval is a field of study.'},
{'text': 'information retrieval focuses on finding relevant information in large datasets.'},
{'text': 'data mining and information retrieval overlap in research.'},
]);
curl --request POST \
--url "${CLUSTER_ENDPOINT}/v2/vectordb/entities/insert" \
--header "Authorization: Bearer ${TOKEN}" \
--header "Content-Type: application/json" \
--header "Request-Timeout: 10" \
-d '{
"data": [
{"text": "information retrieval is a field of study."},
{"text": "information retrieval focuses on finding relevant information in large datasets."},
{"text": "data mining and information retrieval overlap in research."}
],
"collectionName": "my_collection"
}'
전체 텍스트 검색 수행
컬렉션에 데이터를 삽입한 후에는 원시 텍스트 쿼리를 사용하여 전체 텍스트 검색을 수행할 수 있습니다. Milvus는 자동으로 쿼리를 스파스 벡터로 변환하고 BM25 알고리즘을 사용하여 일치하는 검색 결과의 순위를 매긴 다음 상위 K (limit) 결과를 반환합니다.
텍스트 형광펜을 구성하여 검색 결과에서 일치하는 용어를 강조 표시할 수 있습니다. 자세한 내용은 텍스트 하이라이터를 참조하세요.
res = client.search(
collection_name='my_collection',
data=['whats the focus of information retrieval?'],
anns_field='sparse',
output_fields=['text'], # Fields to return in search results; sparse field cannot be output
limit=3,
)
print(res)
import io.milvus.v2.service.vector.request.SearchReq;
import io.milvus.v2.service.vector.request.data.EmbeddedText;
import io.milvus.v2.service.vector.response.SearchResp;
Map<String,Object> searchParams = new HashMap<>();
SearchResp searchResp = client.search(SearchReq.builder()
.collectionName("my_collection")
.data(Collections.singletonList(new EmbeddedText("whats the focus of information retrieval?")))
.annsField("sparse")
.topK(3)
.searchParams(searchParams)
.outputFields(Collections.singletonList("text"))
.build());
annSearchParams := index.NewCustomAnnParam()
resultSets, err := client.Search(ctx, milvusclient.NewSearchOption(
"my_collection", // collectionName
3, // limit
[]entity.Vector{entity.Text("whats the focus of information retrieval?")},
).WithConsistencyLevel(entity.ClStrong).
WithANNSField("sparse").
WithAnnParam(annSearchParams).
WithOutputFields("text"))
if err != nil {
fmt.Println(err.Error())
// handle error
}
for _, resultSet := range resultSets {
fmt.Println("IDs: ", resultSet.IDs.FieldData().GetScalars())
fmt.Println("Scores: ", resultSet.Scores)
fmt.Println("text: ", resultSet.GetColumn("text").FieldData().GetScalars())
}
await client.search(
collection_name: 'my_collection',
data: ['whats the focus of information retrieval?'],
anns_field: 'sparse',
output_fields: ['text'],
limit: 3,
)
curl --request POST \
--url "${CLUSTER_ENDPOINT}/v2/vectordb/entities/search" \
--header "Authorization: Bearer ${TOKEN}" \
--header "Content-Type: application/json" \
--header "Request-Timeout: 10" \
--data-raw '{
"collectionName": "my_collection",
"data": [
"whats the focus of information retrieval?"
],
"annsField": "sparse",
"limit": 3,
"outputFields": [
"text"
],
"searchParams":{
"params":{}
}
}'
파라미터 |
설명 |
|---|---|
|
검색 매개변수가 포함된 사전입니다. |
|
검색 중에 무시할 중요도가 낮은 용어의 비율입니다. 자세한 내용은 스파스 벡터를 참조하세요. |
|
자연어로 된 원시 쿼리 텍스트. Milvus는 BM25 함수를 사용하여 텍스트 쿼리를 자동으로 스파스 벡터로 변환하며, 미리 계산된 벡터를 제공하지 않습니다. |
|
내부적으로 생성된 스파스 벡터가 포함된 필드의 이름입니다. |
|
검색 결과에 반환할 필드 이름의 목록입니다. BM25로 생성된 임베딩이 포함된 스파스 벡터 필드를 제외한 모든 필드를 지원합니다. 일반적인 출력 필드에는 기본 키 필드(예: |
|
반환할 상위 일치 항목의 최대 개수입니다. |
FAQ
전체 텍스트 검색에서 BM25 함수에 의해 생성된 스파스 벡터를 출력하거나 액세스할 수 있나요?
아니요, BM25 함수에 의해 생성된 스파스 벡터는 전체 텍스트 검색에서 직접 액세스하거나 출력할 수 없습니다. 자세한 내용은 다음과 같습니다:
BM25 함수는 내부적으로 랭킹 및 검색을 위해 스파스 벡터를 생성합니다.
이러한 벡터는 스파스 필드에 저장되지만 다음에는 포함될 수 없습니다.
output_fields원본 텍스트 필드와 메타데이터(예:
id,text)만 출력할 수 있습니다.
예시:
# ❌ This throws an error - you cannot output the sparse field
client.search(
collection_name='my_collection',
data=['query text'],
anns_field='sparse',
output_fields=['text', 'sparse'] # 'sparse' causes an error
limit=3,
search_params=search_params
)
# ✅ This works - output text fields only
client.search(
collection_name='my_collection',
data=['query text'],
anns_field='sparse',
output_fields=['text']
limit=3,
search_params=search_params
)
액세스할 수 없는데 왜 스파스 벡터 필드를 정의해야 하나요?
스파스 벡터 필드는 사용자가 직접 상호 작용하지 않는 데이터베이스 인덱스와 유사한 내부 검색 인덱스 역할을 합니다.
설계 근거:
관심사 분리: 사용자는 텍스트(입력/출력)로 작업하고, Milvus는 벡터(내부 처리)를 처리합니다.
성능: 사전 계산된 스파스 벡터를 통해 쿼리 중 빠른 BM25 순위 지정 가능
사용자 경험: 간단한 텍스트 인터페이스 뒤에 복잡한 벡터 연산을 추상화합니다.
벡터 액세스가 필요한 경우:
전체 텍스트 검색 대신 수동 스파스 벡터 연산 사용
사용자 정의 스파스 벡터 워크플로우를 위한 별도의 컬렉션 생성
자세한 내용은 스파스 벡터를 참조하세요.