グループ化検索
グループ化検索は、Milvusが指定したフィールドの値によって検索結果をグループ化し、より高いレベルでデータを集約することを可能にします。例えば、基本的なANN検索を使用すると、その書籍に類似した書籍を検索することができますが、グルーピング検索を使用すると、その書籍で説明されているトピックに関連する可能性のある書籍カテゴリを検索することができます。このトピックでは、グルーピング検索の使用方法と主な注意点について説明します。
概要
検索結果のエンティティがスカラー・フィールドで同じ値を共有する場合、これは特定の属性で類似していることを示し、検索結果に悪影響を及ぼす可能性があります。
コレクションに複数のドキュメント(docIdで示される)が格納されているとします。ドキュメントをベクトルに変換するときに、できるだけ多くの意味情報を保持するために、各ドキュメントは、小さくて管理しやすい段落(またはチャンク)に分割され、別々のエンティティとして格納されます。ドキュメントがより小さなセクションに分割されても、ユーザーはどのドキュメントが自分のニーズに最も関連するかを特定することに興味を持つことが多い。
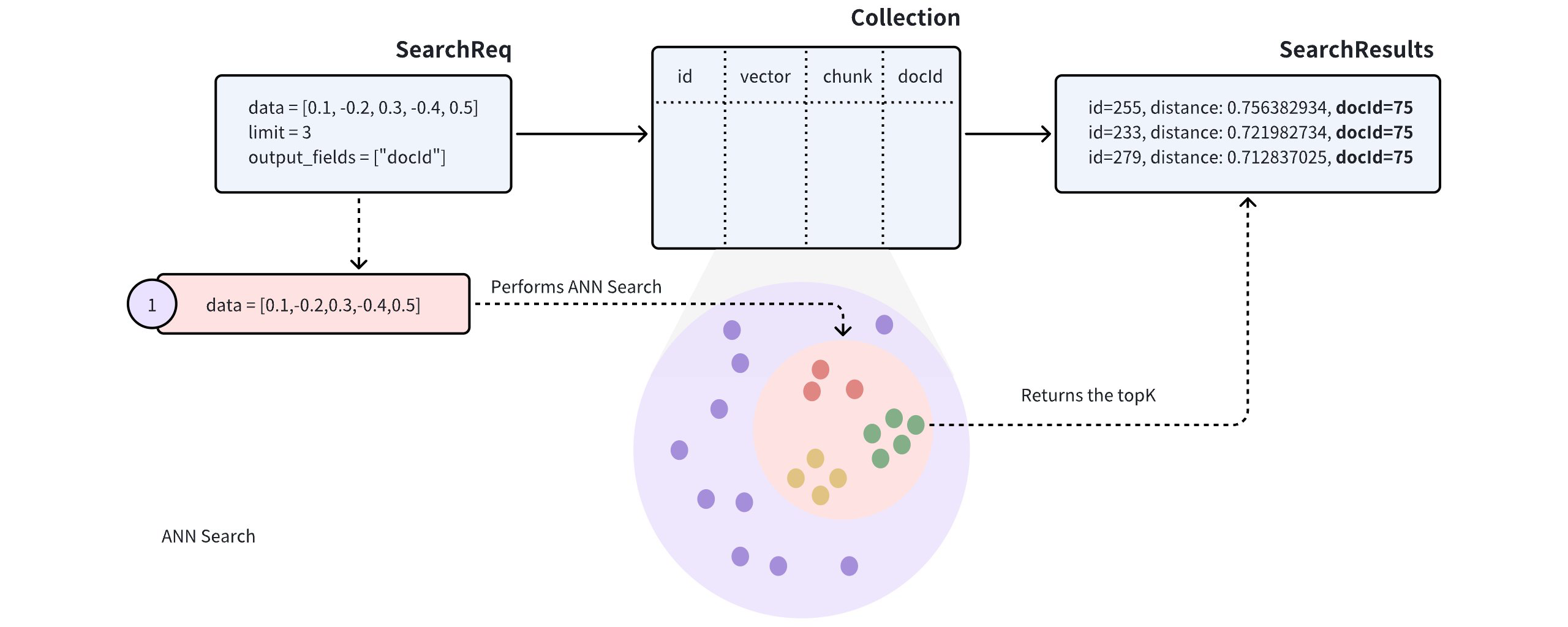 アン検索
アン検索
このようなコレクションに対して近似最近傍(ANN)検索を実行すると、検索結果に同じ文書の複数の段落が含まれ、他の文書が見落とされる可能性があり、意図したユースケースと一致しない場合があります。
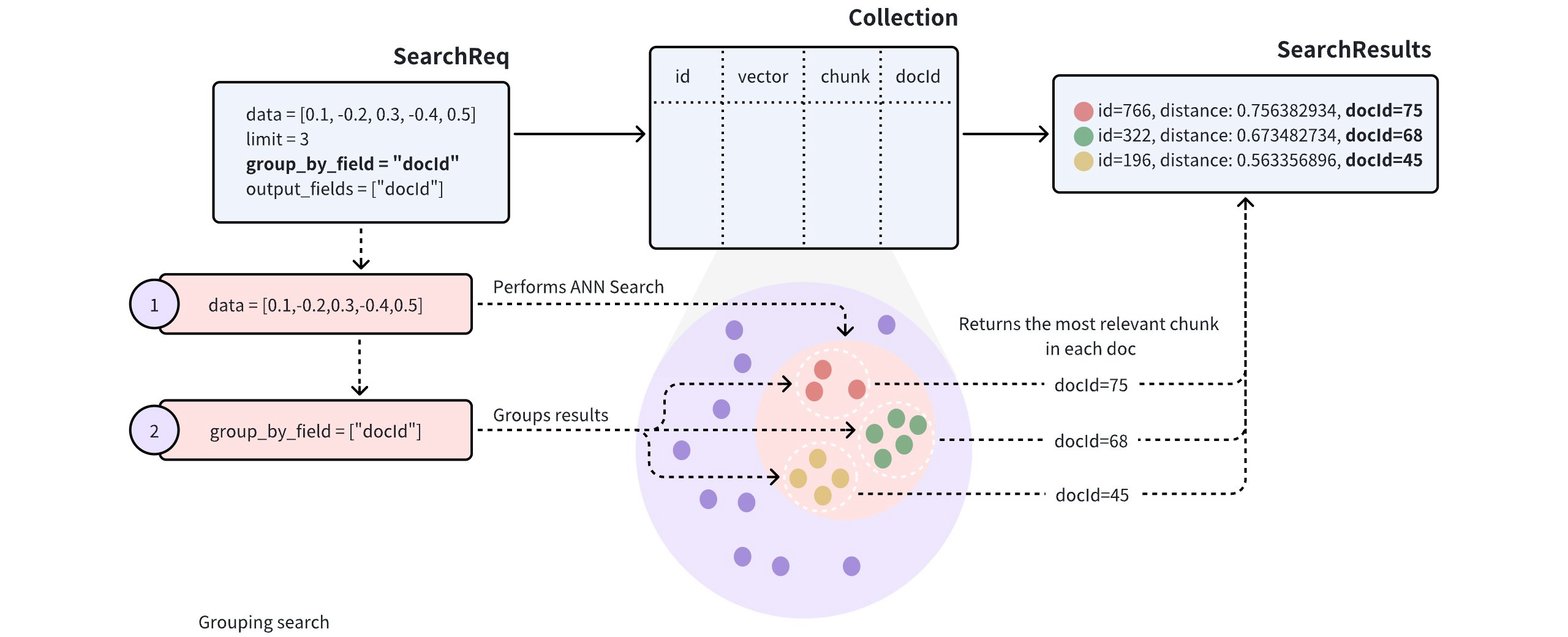 グループ化検索
グループ化検索
検索結果の多様性を高めるために、検索リクエストにgroup_by_field パラメータを追加して、グループ化検索を有効にすることができます。図に示すように、group_by_field をdocId に設定します。このリクエストを受信すると、Milvus は以下のことを行います:
指定されたクエリベクトルに基づいてANN検索を実行し、クエリに最も類似したエンティティをすべて検索します。
指定された
group_by_field(docIdなど) によって検索結果をグループ化します。limitパラメータで定義された各グループの上位結果を、各グループから最も類似したエンティ ティとともに返す。
デフォルトでは、Grouping Search はグループごとに 1 つのエンティティのみを返します。グループごとに返す結果の数を増やしたい場合は、group_size とstrict_group_size パラメータで制御できます。
グループ化検索の実行
このセクションでは、Grouping Search の使用法を示すサンプル・コードを提供します。以下の例では、コレクションにid 、vector 、chunk 、docId のフィールドが含まれていると仮定します。
[
{"id": 0, "vector": [0.3580376395471989, -0.6023495712049978, 0.18414012509913835, -0.26286205330961354, 0.9029438446296592], "chunk": "pink_8682", "docId": 1},
{"id": 1, "vector": [0.19886812562848388, 0.06023560599112088, 0.6976963061752597, 0.2614474506242501, 0.838729485096104], "chunk": "red_7025", "docId": 5},
{"id": 2, "vector": [0.43742130801983836, -0.5597502546264526, 0.6457887650909682, 0.7894058910881185, 0.20785793220625592], "chunk": "orange_6781", "docId": 2},
{"id": 3, "vector": [0.3172005263489739, 0.9719044792798428, -0.36981146090600725, -0.4860894583077995, 0.95791889146345], "chunk": "pink_9298", "docId": 3},
{"id": 4, "vector": [0.4452349528804562, -0.8757026943054742, 0.8220779437047674, 0.46406290649483184, 0.30337481143159106], "chunk": "red_4794", "docId": 3},
{"id": 5, "vector": [0.985825131989184, -0.8144651566660419, 0.6299267002202009, 0.1206906911183383, -0.1446277761879955], "chunk": "yellow_4222", "docId": 4},
{"id": 6, "vector": [0.8371977790571115, -0.015764369584852833, -0.31062937026679327, -0.562666951622192, -0.8984947637863987], "chunk": "red_9392", "docId": 1},
{"id": 7, "vector": [-0.33445148015177995, -0.2567135004164067, 0.8987539745369246, 0.9402995886420709, 0.5378064918413052], "chunk": "grey_8510", "docId": 2},
{"id": 8, "vector": [0.39524717779832685, 0.4000257286739164, -0.5890507376891594, -0.8650502298996872, -0.6140360785406336], "chunk": "white_9381", "docId": 5},
{"id": 9, "vector": [0.5718280481994695, 0.24070317428066512, -0.3737913482606834, -0.06726932177492717, -0.6980531615588608], "chunk": "purple_4976", "docId": 3},
]
検索要求で、group_by_field とoutput_fields の両方をdocId に設定します。Milvusは、指定されたフィールドによって結果をグループ化し、各グループから最も類似したエンティティを返します。返された各エンティティのdocId の値も含みます。
from pymilvus import MilvusClient
client = MilvusClient(
uri="http://localhost:19530",
token="root:Milvus"
)
query_vectors = [
[0.14529211512077012, 0.9147257273453546, 0.7965055218724449, 0.7009258593102812, 0.5605206522382088]]
# Group search results
res = client.search(
collection_name="my_collection",
data=query_vectors,
limit=3,
group_by_field="docId",
output_fields=["docId"]
)
# Retrieve the values in the `docId` column
doc_ids = [result['entity']['docId'] for result in res[0]]
import io.milvus.v2.client.ConnectConfig;
import io.milvus.v2.client.MilvusClientV2;
import io.milvus.v2.service.vector.request.SearchReq
import io.milvus.v2.service.vector.request.data.FloatVec;
import io.milvus.v2.service.vector.response.SearchResp
MilvusClientV2 client = new MilvusClientV2(ConnectConfig.builder()
.uri("http://localhost:19530")
.token("root:Milvus")
.build());
FloatVec queryVector = new FloatVec(new float[]{0.14529211512077012f, 0.9147257273453546f, 0.7965055218724449f, 0.7009258593102812f, 0.5605206522382088f});
SearchReq searchReq = SearchReq.builder()
.collectionName("my_collection")
.data(Collections.singletonList(queryVector))
.topK(3)
.groupByFieldName("docId")
.outputFields(Collections.singletonList("docId"))
.build();
SearchResp searchResp = client.search(searchReq);
List<List<SearchResp.SearchResult>> searchResults = searchResp.getSearchResults();
for (List<SearchResp.SearchResult> results : searchResults) {
System.out.println("TopK results:");
for (SearchResp.SearchResult result : results) {
System.out.println(result);
}
}
// Output
// TopK results:
// SearchResp.SearchResult(entity={docId=5}, score=0.74767184, id=1)
// SearchResp.SearchResult(entity={docId=2}, score=0.6254269, id=7)
// SearchResp.SearchResult(entity={docId=3}, score=0.3611898, id=3)
import (
"context"
"fmt"
"github.com/milvus-io/milvus/client/v2/entity"
"github.com/milvus-io/milvus/client/v2/milvusclient"
)
ctx, cancel := context.WithCancel(context.Background())
defer cancel()
milvusAddr := "localhost:19530"
client, err := milvusclient.New(ctx, &milvusclient.ClientConfig{
Address: milvusAddr,
})
if err != nil {
fmt.Println(err.Error())
// handle error
}
defer client.Close(ctx)
queryVector := []float32{0.3580376395471989, -0.6023495712049978, 0.18414012509913835, -0.26286205330961354, 0.9029438446296592}
resultSets, err := client.Search(ctx, milvusclient.NewSearchOption(
"my_collection", // collectionName
3, // limit
[]entity.Vector{entity.FloatVector(queryVector)},
).WithANNSField("vector").
WithGroupByField("docId").
WithOutputFields("docId"))
if err != nil {
fmt.Println(err.Error())
// handle error
}
for _, resultSet := range resultSets {
fmt.Println("IDs: ", resultSet.IDs.FieldData().GetScalars())
fmt.Println("Scores: ", resultSet.Scores)
fmt.Println("docId: ", resultSet.GetColumn("docId").FieldData().GetScalars())
}
import { MilvusClient, DataType } from "@zilliz/milvus2-sdk-node";
const address = "http://localhost:19530";
const token = "root:Milvus";
const client = new MilvusClient({address, token});
var query_vector = [0.3580376395471989, -0.6023495712049978, 0.18414012509913835, -0.26286205330961354, 0.9029438446296592]
res = await client.search({
collection_name: "my_collection",
data: [query_vector],
limit: 3,
group_by_field: "docId"
})
// Retrieve the values in the `docId` column
var docIds = res.results.map(result => result.entity.docId)
export CLUSTER_ENDPOINT="http://localhost:19530"
export TOKEN="root:Milvus"
curl --request POST \
--url "${CLUSTER_ENDPOINT}/v2/vectordb/entities/search" \
--header "Authorization: Bearer ${TOKEN}" \
--header "Content-Type: application/json" \
--header "Request-Timeout: 10" \
-d '{
"collectionName": "my_collection",
"data": [
[0.3580376395471989, -0.6023495712049978, 0.18414012509913835, -0.26286205330961354, 0.9029438446296592]
],
"annsField": "vector",
"limit": 3,
"groupingField": "docId",
"outputFields": ["docId"]
}'
上記のリクエストでは、limit=3 は、システムが3つのグループから検索結果を返すことを示しており、各グループにはクエリベクトルに最も類似したエンティティが1つずつ含まれています。
グループ・サイズの設定
デフォルトでは、グループ化検索はグループごとに1つのエンティティのみを返します。グループごとに複数の結果を返したい場合は、group_size とstrict_group_size パラメータを調整してください。
# Group search results
res = client.search(
collection_name="my_collection",
data=query_vectors, # query vector
limit=5, # number of groups to return
group_by_field="docId", # grouping field
group_size=2, # p to 2 entities to return from each group
strict_group_size=True, # return exact 2 entities from each group
output_fields=["docId"]
)
FloatVec queryVector = new FloatVec(new float[]{0.14529211512077012f, 0.9147257273453546f, 0.7965055218724449f, 0.7009258593102812f, 0.5605206522382088f});
SearchReq searchReq = SearchReq.builder()
.collectionName("my_collection")
.data(Collections.singletonList(queryVector))
.topK(5)
.groupByFieldName("docId")
.groupSize(2)
.strictGroupSize(true)
.outputFields(Collections.singletonList("docId"))
.build();
SearchResp searchResp = client.search(searchReq);
List<List<SearchResp.SearchResult>> searchResults = searchResp.getSearchResults();
for (List<SearchResp.SearchResult> results : searchResults) {
System.out.println("TopK results:");
for (SearchResp.SearchResult result : results) {
System.out.println(result);
}
}
// Output
// TopK results:
// SearchResp.SearchResult(entity={docId=5}, score=0.74767184, id=1)
// SearchResp.SearchResult(entity={docId=5}, score=-0.49148706, id=8)
// SearchResp.SearchResult(entity={docId=2}, score=0.6254269, id=7)
// SearchResp.SearchResult(entity={docId=2}, score=0.38515577, id=2)
// SearchResp.SearchResult(entity={docId=3}, score=0.3611898, id=3)
// SearchResp.SearchResult(entity={docId=3}, score=0.19556211, id=4)
import (
"context"
"fmt"
"github.com/milvus-io/milvus/client/v2/entity"
"github.com/milvus-io/milvus/client/v2/milvusclient"
)
ctx, cancel := context.WithCancel(context.Background())
defer cancel()
milvusAddr := "localhost:19530"
client, err := milvusclient.New(ctx, &milvusclient.ClientConfig{
Address: milvusAddr,
})
if err != nil {
fmt.Println(err.Error())
// handle error
}
defer client.Close(ctx)
queryVector := []float32{0.3580376395471989, -0.6023495712049978, 0.18414012509913835, -0.26286205330961354, 0.9029438446296592}
resultSets, err := client.Search(ctx, milvusclient.NewSearchOption(
"my_collection", // collectionName
5, // limit
[]entity.Vector{entity.FloatVector(queryVector)},
).WithANNSField("vector").
WithGroupByField("docId").
WithStrictGroupSize(true).
WithGroupSize(2).
WithOutputFields("docId"))
if err != nil {
fmt.Println(err.Error())
// handle error
}
for _, resultSet := range resultSets {
fmt.Println("IDs: ", resultSet.IDs.FieldData().GetScalars())
fmt.Println("Scores: ", resultSet.Scores)
fmt.Println("docId: ", resultSet.GetColumn("docId").FieldData().GetScalars())
}
import { MilvusClient, DataType } from "@zilliz/milvus2-sdk-node";
const address = "http://localhost:19530";
const token = "root:Milvus";
const client = new MilvusClient({address, token});
var query_vector = [0.3580376395471989, -0.6023495712049978, 0.18414012509913835, -0.26286205330961354, 0.9029438446296592]
res = await client.search({
collection_name: "my_collection",
data: [query_vector],
limit: 5,
group_by_field: "docId",
group_size: 2,
strict_group_size: true
})
// Retrieve the values in the `docId` column
var docIds = res.results.map(result => result.entity.docId)
curl --request POST \
--url "${CLUSTER_ENDPOINT}/v2/vectordb/entities/search" \
--header "Authorization: Bearer ${TOKEN}" \
--header "Content-Type: application/json" \
--header "Request-Timeout: 10" \
-d '{
"collectionName": "my_collection",
"data": [
[0.3580376395471989, -0.6023495712049978, 0.18414012509913835, -0.26286205330961354, 0.9029438446296592]
],
"annsField": "vector",
"limit": 5,
"groupingField": "docId",
"groupSize":2,
"strictGroupSize":true,
"outputFields": ["docId"]
}'
上の例では
group_size:グループごとに返したいエンティティの数を指定します。たとえば、group_size=2を設定すると、各グループ(または各docId)が最も類似した段落(またはチャンク)を2つ返すのが理想的です。group_sizeが設定されていない場合、システムはデフォルトでグループごとに 1 つの結果を返します。strict_group_size:このブーリアン・パラメータは、システムがgroup_sizeで設定されたカウントを厳密に実行するかどうかを制御します。strict_group_size=Trueの場合、そのグループに十分なデータがない場合を除き、group_sizeで指定されたエンティティ数を各グループに含めようとします(たとえば、2つの段落)。デフォルト(strict_group_size=False)では、システムは、各グループにgroup_sizeエンティティが含まれるようにするよりも、limitパラメータで指定されたグループ数を満たすことを優先する。このアプローチは、データ分布が不均一な場合に一般的により効率的である。
パラメータの詳細については、searchを参照してください。
スカラー・フィールドによるグループの順序付けCompatible with Milvus 3.0.x
グループ化検索をorder_by_fields と組み合わせると、スカラー・フィールドでグループを並べ替えることができます。これは、グループ間で多様な結果を得たいが、価格や格付けのようなビジネスに関連した順序に従ってグループを並べたい場合に便利です。
次の例では、検索結果をcategory でグループ化し、グループごとに最大 3 つのエンティ ティを返し、返されたグループをprice で低いものから高いものへと並べ替えます。
res = client.search(
collection_name="product_catalog",
data=query_vectors,
anns_field="embedding",
limit=20,
group_by_field="category",
group_size=3,
strict_group_size=True,
output_fields=["category", "price", "rating"],
order_by_fields=[
{"field": "price", "order": "asc"}
],
)
// java
// nodejs
// go
# restful
上記のリクエストで、limit=20 は、Milvusが20のエンティティではなく、20のグループまで選択することを意味する。group_size=3 のため、フラットな結果リストには、合計で最大60エンティティを含めることができる。
group_by_field とともにorder_by_fields を使用すると、Milvusは各グループの先頭エンティティの指定されたスカラーフィールド値によってグループを順序付けます。各グループ内では、エンティティはクエリ・ベクタに対する類似度スコアで並べ替えられます。
考慮事項
インデックス作成:このグループ化機能は、以下のインデックスタイプでインデックスされたコレクションに対してのみ機能します:flat、ivf_flat、ivf_sq8、hnsw、hnsw_pq、hnsw_prq、hnsw_sq、diskann、sparse_inverted_index。
グループ数:
limitパラメータは、各グループ内の特定のエンティティの数ではなく、検索結果が返されるグループの数を制御する。適切なlimitを設定することで、検索の多様性とクエリ・パフォーマンスを制御することができます。データが高密度に分散している場合やパフォーマンスが懸念される場合は、limitを減らすことで計算コストを削減できます。グループあたりのエンティティ数:
group_sizeパラメータは、グループごとに返されるエンティティの数を制御します。ユースケースに基づいてgroup_sizeを調整すると、検索結果の豊かさが向上します。ただし、データが不均一に分散している場合、特にデータが限られたシナリオでは、group_sizeで指定した数よりも少ないエンティティしか返されないグループもあります。厳格なグループサイズ:
strict_group_size=Trueを指定すると、そのグループに十分なデータがない場合を除き、各グループで指定されたエンティティ数 (group_size) を返そうとします。この設定により、グループごとに一貫したエンティティ数が保証されますが、データ分散が不均一な場合やリソースが限られている場合、パフォーマンスが低下する可能性があります。厳密なエンティティ数が必要でない場合は、strict_group_size=Falseを設定することで、クエリの速度を向上させることができます。クエリ・ベクタがターゲット・コレクションに既に存在する場合は、検索前にそれらを取得する代わりに
idsを使用することを検討してください。詳細については、プライマリ・キー検索を参照してください。