Costruire un sistema RAG usando Langflow con Milvus
Questa guida mostra come utilizzare Langflow per costruire una pipeline di Retrieval-Augmented Generation (RAG) con Milvus.
Il sistema RAG migliora la generazione del testo recuperando prima i documenti rilevanti da una base di conoscenza e poi generando nuove risposte basate su questo contesto. Milvus viene utilizzato per memorizzare e recuperare le incorporazioni di testo, mentre Langflow facilita l'integrazione del reperimento e della generazione in un flusso di lavoro visivo.
Langflow consente di costruire facilmente pipeline RAG, in cui pezzi di testo vengono incorporati, memorizzati in Milvus e recuperati quando vengono effettuate interrogazioni pertinenti. Questo permette al modello linguistico di generare risposte contestualmente informate.
Milvus funge da database vettoriale scalabile che trova rapidamente testi semanticamente simili, mentre Langflow consente di gestire il modo in cui la pipeline gestisce il recupero del testo e la generazione delle risposte. Insieme, forniscono un modo efficiente per costruire una robusta pipeline RAG per applicazioni avanzate basate sul testo.
Prerequisiti
Prima di eseguire questo notebook, assicurarsi di aver installato le seguenti dipendenze:
$ python -m pip install langflow -U
Tutorial
Una volta installate tutte le dipendenze, avviare una dashboard di Langflow digitando il seguente comando:
$ python -m langflow run
Verrà quindi visualizzata una dashboard come mostrato di seguito:  langflow
langflow
Vogliamo creare un progetto Vector Store, quindi per prima cosa dobbiamo fare clic sul pulsante Nuovo progetto. Si aprirà un pannello e sceglieremo l'opzione Vector Store RAG:  panel
panel
Una volta creato il progetto Vector Store Rag, il vector store predefinito è AstraDB, mentre noi vogliamo usare Milvus. Dobbiamo quindi sostituire i due moduli astraDB con Milvus per poter usare Milvus come archivio vettoriale. 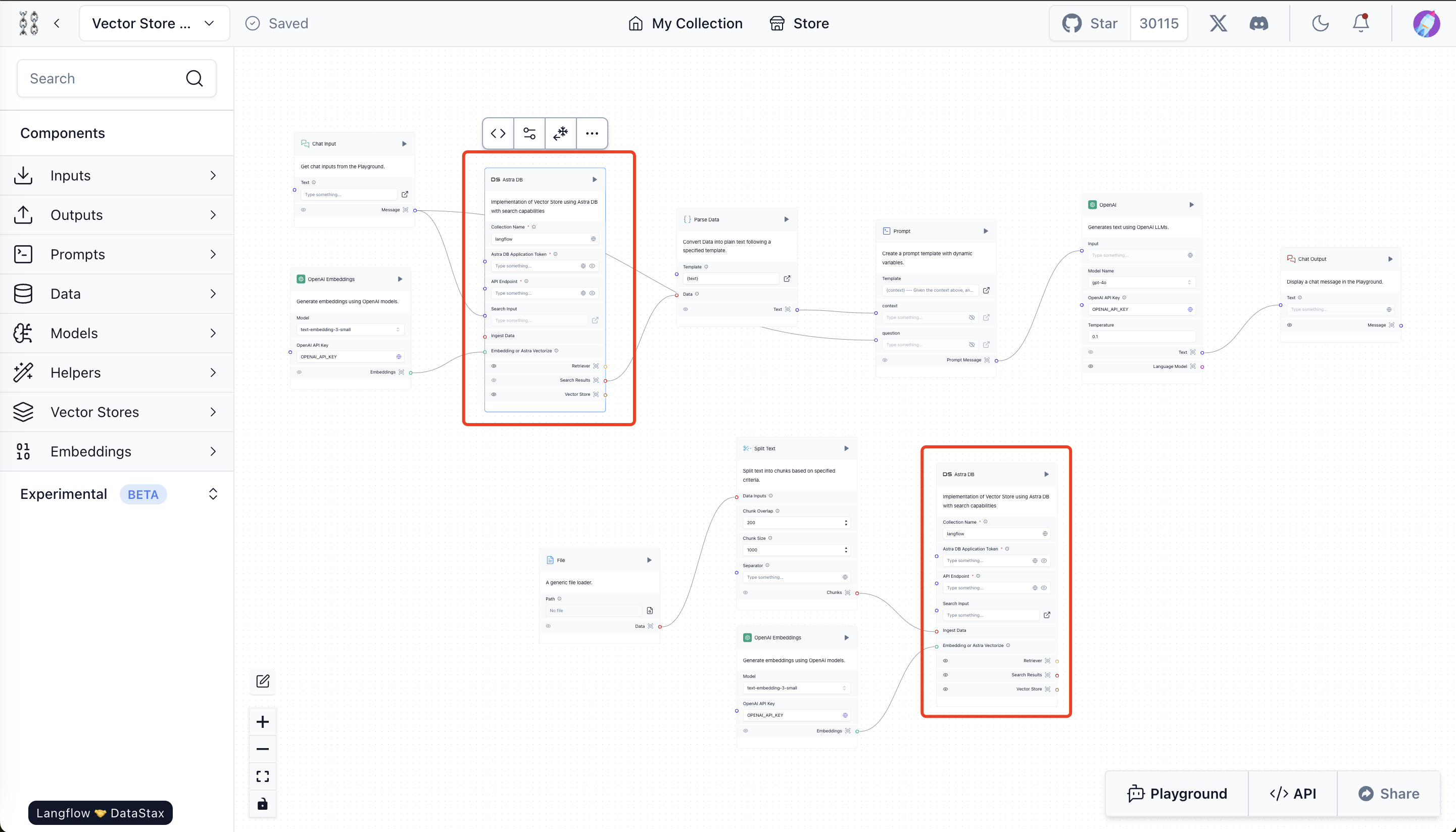 astraDB
astraDB
Passi per sostituire astraDB con Milvus:
- Rimuovere le schede esistenti di Vector Store. Fare clic su due schede di astraDB contrassegnate in rosso nell'immagine precedente e premere backspace per eliminarle.
- Fare clic sull'opzione Vector Store nella barra laterale, scegliere Milvus e trascinarlo nell'area di disegno. Eseguire questa operazione due volte, poiché sono necessarie due schede Milvus, una per memorizzare il flusso di lavoro di elaborazione dei file e una per il flusso di lavoro di ricerca.
- Collegare i moduli Milvus al resto dei componenti. Vedere l'immagine sottostante come riferimento.
- Configurare le credenziali Milvus per entrambi i moduli Milvus. Il modo più semplice è usare Milvus Lite, impostando l'URI di connessione su milvus_demo.db. Se si dispone di un server Milvus distribuito autonomamente o su Zilliz Cloud, impostare l'URI di connessione sull'endpoint del server e la password di connessione sul token (per Milvus è la concatenazione di "
: ", per Zilliz Cloud è la chiave API). Vedere l'immagine sottostante come riferimento:
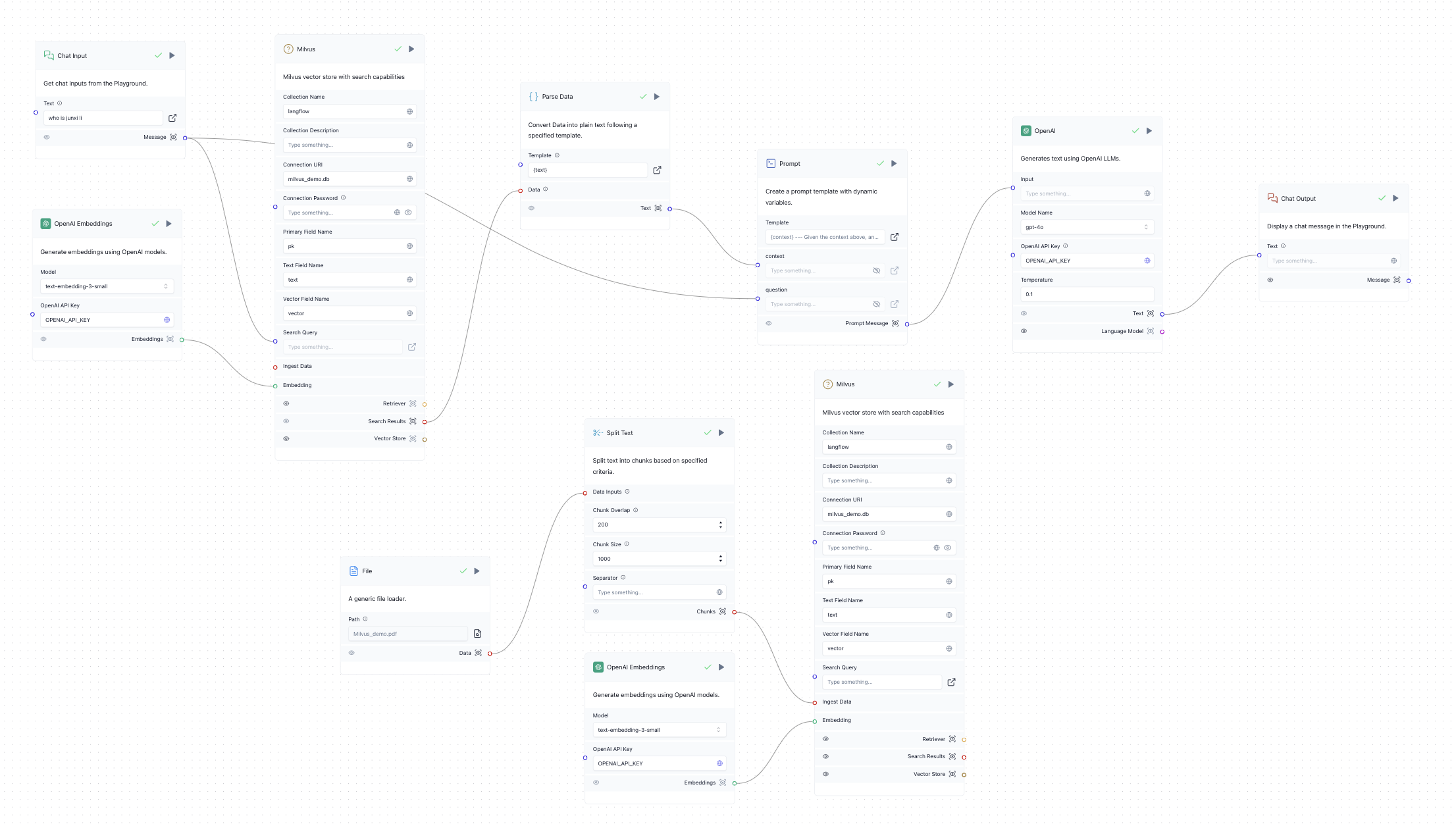 Dimostrazione della struttura di Milvus
Dimostrazione della struttura di Milvus
Inserire le conoscenze nel sistema RAG
- Caricare un file come base di conoscenza di LLM attraverso il modulo file in basso a sinistra. Qui abbiamo caricato un file contenente una breve introduzione a Milvus.
- Eseguire il flusso di lavoro di inserimento premendo il pulsante di esecuzione sul modulo Milvus in basso a destra. In questo modo si inserisce la conoscenza nell'archivio vettoriale di Milvus.
- Verificare se le conoscenze sono in memoria. Aprire l'area di gioco e chiedere qualsiasi cosa relativa al file caricato.
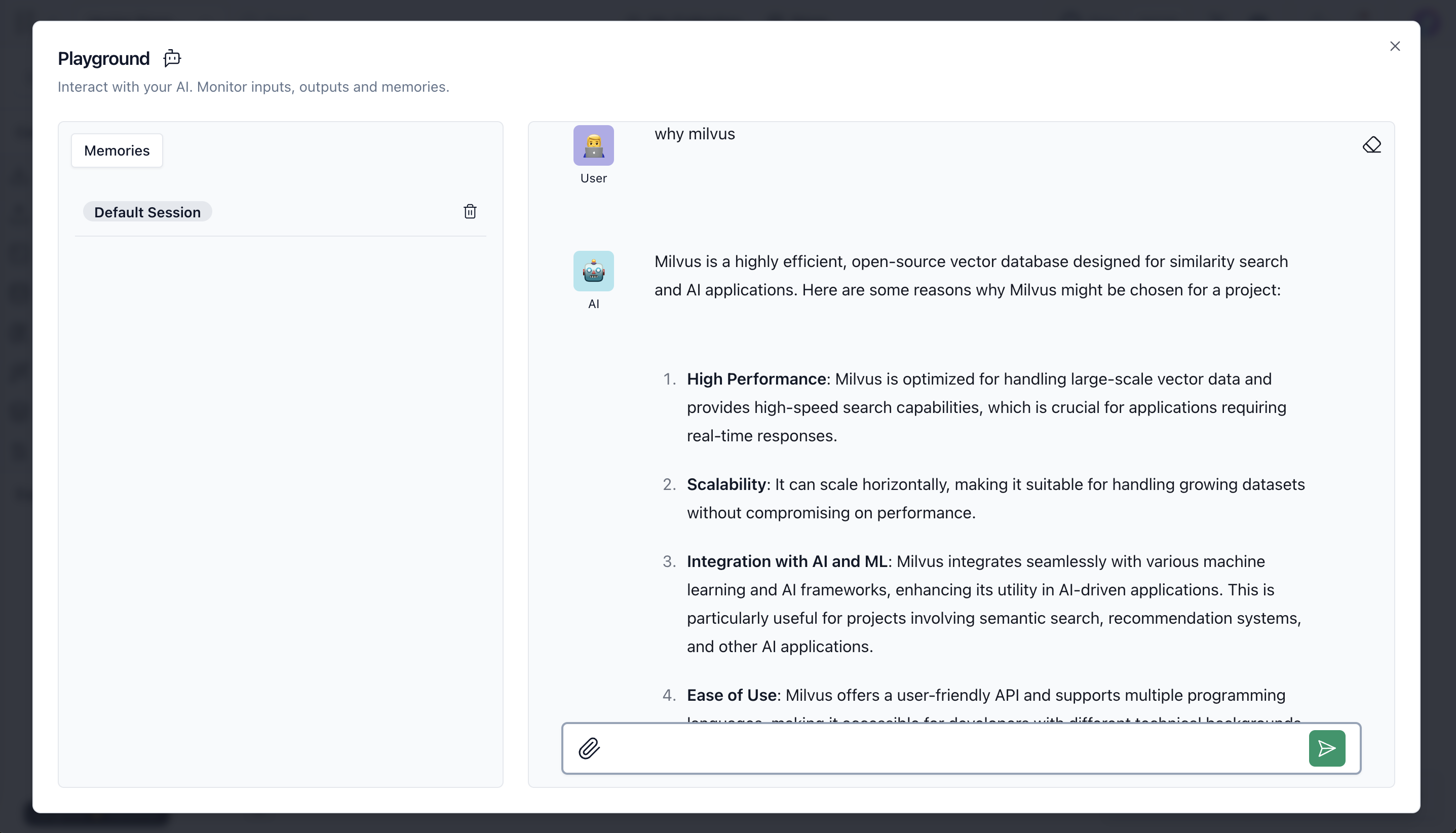 perché Milvus
perché Milvus