Intégrer Milvus à DSPy
![]()
Qu'est-ce que DSPy ?
DSPy, introduit par le Stanford NLP Group, est un cadre programmatique révolutionnaire conçu pour optimiser les invites et les poids dans les modèles de langage, particulièrement utile dans les scénarios où de grands modèles de langage (LLM) sont intégrés à plusieurs étapes d'un pipeline. Contrairement aux techniques conventionnelles d'ingénierie des messages-guides qui reposent sur l'élaboration et l'ajustement manuels, DSPy adopte une approche basée sur l'apprentissage. En assimilant des exemples de questions-réponses, DSPy génère dynamiquement des messages optimisés, adaptés à des tâches spécifiques. Cette méthodologie innovante permet de réassembler de manière transparente des pipelines entiers, éliminant ainsi le besoin d'ajustements manuels continus des messages-guides. La syntaxe pythonique de DSPy offre divers modules composables et déclaratifs, ce qui simplifie l'instruction des LLM.
Avantages de l'utilisation de DSPy
- Approche de la programmation : DSPy fournit une approche de programmation systématique pour le développement de pipelines LM en abstrayant les pipelines sous forme de graphes de transformation de texte au lieu de se contenter d'inviter les LLM. Ses modules déclaratifs permettent une conception et une optimisation structurées, remplaçant la méthode d'essai et d'erreur des modèles d'invite traditionnels.
- Amélioration des performances : DSPy démontre des gains de performance significatifs par rapport aux méthodes existantes. Grâce à des études de cas, il surpasse les messages-guides standard et les démonstrations créées par des experts, démontrant ainsi sa polyvalence et son efficacité, même lorsqu'il est compilé dans des modèles LM plus petits.
- Abstraction modulaire : DSPy abstrait efficacement les aspects complexes du développement du pipeline LM, tels que la décomposition, le réglage fin et la sélection du modèle. Avec DSPy, un programme concis peut se traduire de manière transparente en instructions pour différents modèles, tels que GPT-4, Llama2-13b ou T5-base, ce qui simplifie le développement et améliore les performances.
Les modules
Il existe de nombreux composants qui contribuent à la construction d'un pipeline LLM. Nous décrirons ici quelques composants clés afin de fournir une compréhension de haut niveau du fonctionnement de DSPy.
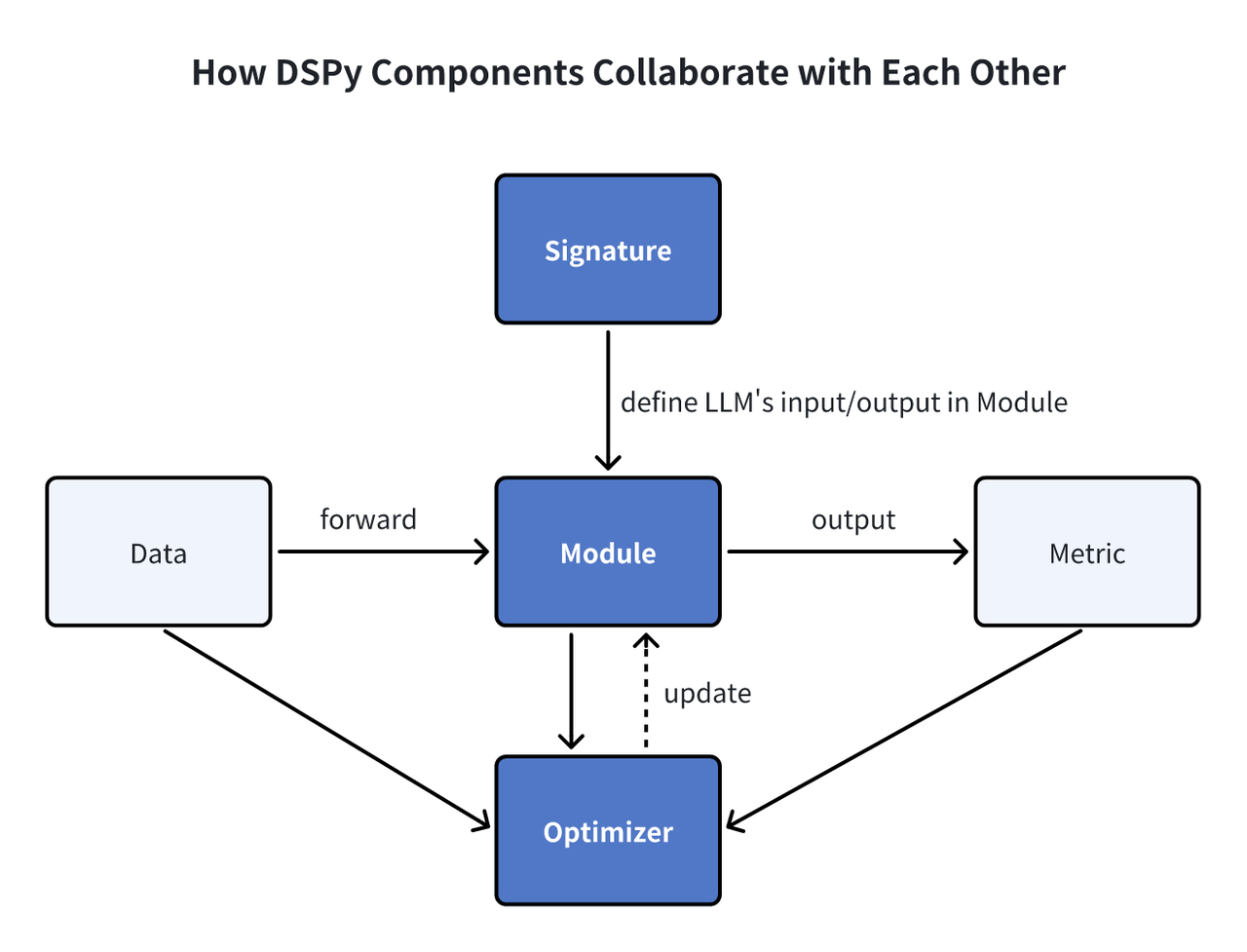 Modules DSPy
Modules DSPy
Signature : Les signatures dans DSPy servent de spécifications déclaratives, décrivant le comportement d'entrée/sortie des modules, guidant le modèle de langage dans l'exécution des tâches. Module : Les modules DSPy servent de composants fondamentaux pour les programmes exploitant les modèles de langage (LM). Ils abstraient diverses techniques d'incitation, telles que la chaîne de pensée ou ReAct, et sont adaptables pour gérer n'importe quelle signature DSPy. Avec des paramètres apprenables et la capacité de traiter des entrées et de produire des sorties, ces modules peuvent être combinés pour former des programmes plus importants, en s'inspirant des modules NN de PyTorch, mais adaptés aux applications LM. Optimiseur : Les optimiseurs de DSPy affinent les paramètres des programmes DSPy, tels que les invites et les poids LLM, afin de maximiser les mesures spécifiées telles que la précision, améliorant ainsi l'efficacité du programme.
Pourquoi Milvus dans DSPy ?
DSPy est un cadre de programmation puissant qui stimule les applications RAG. Une telle application doit récupérer des informations utiles pour améliorer la qualité des réponses, ce qui nécessite une base de données vectorielle. Milvus est une base de données vectorielle open-source bien connue qui permet d'améliorer les performances et l'évolutivité. Avec MilvusRM, un module de récupération dans DSPy, l'intégration de Milvus devient transparente. Désormais, les développeurs peuvent facilement définir et optimiser les programmes RAG à l'aide de DSPy, en tirant parti des puissantes capacités de recherche vectorielle de Milvus. Cette collaboration rend les applications RAG plus efficaces et évolutives, en combinant les capacités de programmation de DSPy avec les fonctions de recherche de Milvus.
Exemples d'applications
Voyons maintenant un exemple rapide pour démontrer comment tirer parti de Milvus dans DSPy pour optimiser une application RAG.
Conditions préalables
Avant de construire l'application RAG, installez DSPy et PyMilvus.
$ pip install "dspy-ai[milvus]"
$ pip install -U pymilvus
Chargement de l'ensemble de données
Dans cet exemple, nous utilisons le HotPotQA, une collection de paires de questions-réponses complexes, comme ensemble de données d'entraînement. Nous pouvons les charger via la classe HotPotQA.
from dspy.datasets import HotPotQA
# Load the dataset.
dataset = HotPotQA(
train_seed=1, train_size=20, eval_seed=2023, dev_size=50, test_size=0
)
# Tell DSPy that the 'question' field is the input. Any other fields are labels and/or metadata.
trainset = [x.with_inputs("question") for x in dataset.train]
devset = [x.with_inputs("question") for x in dataset.dev]
Intégrer les données dans la base de données vectorielles Milvus
Intégrer les informations contextuelles dans la collection Milvus pour la recherche de vecteurs. Cette collection doit comporter un champ embedding et un champ text. Nous utilisons le modèle text-embedding-3-small de l'OpenAI comme fonction d'intégration de requête par défaut dans ce cas.
import requests
import os
os.environ["OPENAI_API_KEY"] = "<YOUR_OPENAI_API_KEY>"
MILVUS_URI = "example.db"
MILVUS_TOKEN = ""
from pymilvus import MilvusClient, DataType, Collection
from dspy.retrieve.milvus_rm import openai_embedding_function
client = MilvusClient(uri=MILVUS_URI, token=MILVUS_TOKEN)
if "dspy_example" not in client.list_collections():
client.create_collection(
collection_name="dspy_example",
overwrite=True,
dimension=1536,
primary_field_name="id",
vector_field_name="embedding",
id_type="int",
metric_type="IP",
max_length=65535,
enable_dynamic=True,
)
text = requests.get(
"https://raw.githubusercontent.com/wxywb/dspy_dataset_sample/master/sample_data.txt"
).text
for idx, passage in enumerate(text.split("\n")):
if len(passage) == 0:
continue
client.insert(
collection_name="dspy_example",
data=[
{
"id": idx,
"embedding": openai_embedding_function(passage)[0],
"text": passage,
}
],
)
Définir MilvusRM.
Vous devez maintenant définir le MilvusRM.
from dspy.retrieve.milvus_rm import MilvusRM
import dspy
retriever_model = MilvusRM(
collection_name="dspy_example",
uri=MILVUS_URI,
token=MILVUS_TOKEN, # ignore this if no token is required for Milvus connection
embedding_function=openai_embedding_function,
)
turbo = dspy.OpenAI(model="gpt-3.5-turbo")
dspy.settings.configure(lm=turbo)
Création de signatures
Maintenant que nous avons chargé les données, commençons à définir les signatures pour les sous-tâches de notre pipeline. Nous pouvons identifier notre entrée simple question et notre sortie answer, mais comme nous construisons un pipeline RAG, nous récupérerons des informations contextuelles de Milvus. Définissons donc notre signature comme context, question --> answer.
class GenerateAnswer(dspy.Signature):
"""Answer questions with short factoid answers."""
context = dspy.InputField(desc="may contain relevant facts")
question = dspy.InputField()
answer = dspy.OutputField(desc="often between 1 and 5 words")
Nous incluons de courtes descriptions pour les champs context et answer afin de définir des lignes directrices plus claires sur ce que le modèle recevra et devrait générer.
Construction du pipeline
Définissons maintenant le pipeline RAG.
class RAG(dspy.Module):
def __init__(self, rm):
super().__init__()
self.retrieve = rm
# This signature indicates the task imposed on the COT module.
self.generate_answer = dspy.ChainOfThought(GenerateAnswer)
def forward(self, question):
# Use milvus_rm to retrieve context for the question.
context = self.retrieve(question).passages
# COT module takes "context, query" and output "answer".
prediction = self.generate_answer(context=context, question=question)
return dspy.Prediction(
context=[item.long_text for item in context], answer=prediction.answer
)
Exécution du pipeline et obtention des résultats
Nous avons maintenant construit ce pipeline RAG. Essayons-le et obtenons des résultats.
rag = RAG(retriever_model)
print(rag("who write At My Window").answer)
Townes Van Zandt
Nous pouvons évaluer les résultats quantitatifs sur le jeu de données.
from dspy.evaluate.evaluate import Evaluate
from dspy.datasets import HotPotQA
evaluate_on_hotpotqa = Evaluate(
devset=devset, num_threads=1, display_progress=False, display_table=5
)
metric = dspy.evaluate.answer_exact_match
score = evaluate_on_hotpotqa(rag, metric=metric)
print("rag:", score)
Optimisation du pipeline
Après avoir défini ce programme, l'étape suivante est la compilation. Ce processus met à jour les paramètres de chaque module afin d'améliorer les performances. Le processus de compilation dépend de trois facteurs essentiels :
- L'ensemble de formation : Nous utiliserons les 20 exemples de questions-réponses de notre ensemble de données de formation pour cette démonstration.
- Mesure de validation : Nous établirons une mesure simple à l'adresse
validate_context_and_answer. Cette mesure permet de vérifier l'exactitude de la réponse prédite et de s'assurer que le contexte récupéré comprend la réponse. - Optimiseur spécifique (téléprompteur) : Le compilateur de DSPy intègre plusieurs téléprompteurs conçus pour optimiser efficacement vos programmes.
from dspy.teleprompt import BootstrapFewShot
# Validation logic: check that the predicted answer is correct.# Also check that the retrieved context does contain that answer.
def validate_context_and_answer(example, pred, trace=None):
answer_EM = dspy.evaluate.answer_exact_match(example, pred)
answer_PM = dspy.evaluate.answer_passage_match(example, pred)
return answer_EM and answer_PM
# Set up a basic teleprompter, which will compile our RAG program.
teleprompter = BootstrapFewShot(metric=validate_context_and_answer)
# Compile!
compiled_rag = teleprompter.compile(rag, trainset=trainset)
# Now compiled_rag is optimized and ready to answer your new question!
# Now, let’s evaluate the compiled RAG program.
score = evaluate_on_hotpotqa(compiled_rag, metric=metric)
print(score)
print("compile_rag:", score)
Le score de Ragas est passé de 50,0 à 52,0, ce qui indique une amélioration de la qualité des réponses.
Résumé
DSPy marque un saut dans les interactions entre les modèles de langage grâce à son interface programmable, qui facilite l'optimisation algorithmique et automatisée des invites et des poids des modèles. En tirant parti de DSPy pour la mise en œuvre de RAG, l'adaptabilité à différents modèles linguistiques ou ensembles de données devient un jeu d'enfant, ce qui réduit considérablement le besoin d'interventions manuelles fastidieuses.