Búsqueda en embudo con incrustaciones Matryoshka
Tradicionalmente, los requisitos de almacenamiento se reducen aplicando un método de cuantificación o reducción de la dimensionalidad justo antes de construir el índice. Por ejemplo, podemos ahorrar almacenamiento reduciendo la precisión mediante la cuantificación de productos (PQ) o el número de dimensiones mediante el análisis de componentes principales (PCA). Estos métodos analizan todo el conjunto de vectores para encontrar uno más compacto que mantenga las relaciones semánticas entre vectores.
Aunque eficaces, estos enfoques estándar reducen la precisión o la dimensionalidad una sola vez y a una sola escala. Pero, ¿y si pudiéramos mantener varias capas de detalle simultáneamente, como una pirámide de representaciones cada vez más precisas?
He aquí las incrustaciones Matryoshka. Estas ingeniosas construcciones, que deben su nombre a las muñecas rusas (véase la ilustración), integran múltiples escalas de representación en un único vector. A diferencia de los métodos tradicionales de posprocesamiento, las incrustaciones Matryoshka aprenden esta estructura multiescala durante el proceso de entrenamiento inicial. El resultado es notable: no sólo la incrustación completa capta la semántica de entrada, sino que cada prefijo de subconjunto anidado (primera mitad, primer cuarto, etc.) proporciona una representación coherente, aunque menos detallada.
En este cuaderno, examinamos cómo utilizar las incrustaciones Matryoshka con Milvus para la búsqueda semántica. Ilustramos un algoritmo llamado "búsqueda en embudo" que nos permite realizar búsquedas de similitud en un pequeño subconjunto de nuestras dimensiones de incrustación sin que se produzca una caída drástica de la recuperación.
Preparación
$ pip install datasets numpy pandas pymilvus sentence-transformers tqdm
Sólo para CPU:
$ pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cpu
Para CUDA 11.8:
$ pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
El comando de instalación de CUDA 11.8 es sólo un ejemplo. Por favor, confirme su versión CUDA al instalar PyTorch.
import functools
from datasets import load_dataset
import numpy as np
import pandas as pd
import pymilvus
from pymilvus import MilvusClient
from pymilvus import FieldSchema, CollectionSchema, DataType
from sentence_transformers import SentenceTransformer
import torch
import torch.nn.functional as F
from tqdm import tqdm
Cargar el modelo de incrustación Matryoshka
En lugar de utilizar un modelo de incrustación estándar como sentence-transformers/all-MiniLM-L12-v2utilizamos un modelo de Nomic entrenado especialmente para producir incrustaciones Matryoshka.
model = SentenceTransformer(
# Remove 'device='mps' if running on non-Mac device
"nomic-ai/nomic-embed-text-v1.5",
trust_remote_code=True,
device="mps",
)
<All keys matched successfully>
Carga del conjunto de datos, incrustación de elementos y creación de la base de datos vectorial
El siguiente código es una modificación del de la página de documentación "Movie Search with Sentence Transformers and Milvus". En primer lugar, cargamos el conjunto de datos de HuggingFace. Contiene unas 35.000 entradas, cada una de las cuales corresponde a una película que tiene un artículo en Wikipedia. En este ejemplo utilizaremos los campos Title y PlotSummary.
ds = load_dataset("vishnupriyavr/wiki-movie-plots-with-summaries", split="train")
print(ds)
Dataset({
features: ['Release Year', 'Title', 'Origin/Ethnicity', 'Director', 'Cast', 'Genre', 'Wiki Page', 'Plot', 'PlotSummary'],
num_rows: 34886
})
A continuación, nos conectamos a una base de datos Milvus Lite, especificamos el esquema de datos y creamos una colección con este esquema. Almacenaremos tanto la incrustación no normalizada como la primera sexta parte de la incrustación en campos separados. La razón es que necesitamos la primera sexta parte de la Matryoshka para realizar una búsqueda de similitudes, y las 5/6 partes restantes de las incrustaciones para volver a clasificar y mejorar los resultados de la búsqueda.
embedding_dim = 768
search_dim = 128
collection_name = "movie_embeddings"
client = MilvusClient(uri="./wiki-movie-plots-matryoshka.db")
fields = [
FieldSchema(name="id", dtype=DataType.INT64, is_primary=True, auto_id=True),
FieldSchema(name="title", dtype=DataType.VARCHAR, max_length=256),
# First sixth of unnormalized embedding vector
FieldSchema(name="head_embedding", dtype=DataType.FLOAT_VECTOR, dim=search_dim),
# Entire unnormalized embedding vector
FieldSchema(name="embedding", dtype=DataType.FLOAT_VECTOR, dim=embedding_dim),
]
schema = CollectionSchema(fields=fields, enable_dynamic_field=False)
client.create_collection(collection_name=collection_name, schema=schema)
Milvus no admite actualmente la búsqueda en subconjuntos de incrustaciones, por lo que dividimos las incrustaciones en dos partes: la cabeza representa el subconjunto inicial del vector para indexar y buscar, y la cola es el resto. El modelo está entrenado para la búsqueda de similitudes por distancia coseno, por lo que normalizamos las incrustaciones de la cabeza. Sin embargo, para poder calcular posteriormente las similitudes de subconjuntos más grandes, necesitamos almacenar la norma de la incrustación de la cabeza, de modo que podamos desnormalizarla antes de unirla a la cola.
Para realizar la búsqueda a través del primer 1/6 de la incrustación, necesitaremos crear un índice de búsqueda vectorial sobre el campo head_embedding. Más adelante, compararemos los resultados de la "búsqueda en embudo" con una búsqueda vectorial normal, por lo que también crearemos un índice de búsqueda sobre la incrustación completa.
Es importante destacar que utilizamos la métrica de distancia COSINE en lugar de IP, porque de lo contrario tendríamos que realizar un seguimiento de las normas de incrustación, lo que complicaría la implementación (esto tendrá más sentido una vez que se haya descrito el algoritmo de búsqueda de embudo).
index_params = client.prepare_index_params()
index_params.add_index(
field_name="head_embedding", index_type="FLAT", metric_type="COSINE"
)
index_params.add_index(field_name="embedding", index_type="FLAT", metric_type="COSINE")
client.create_index(collection_name, index_params)
Por último, codificamos los resúmenes argumentales de las 35.000 películas e introducimos las incrustaciones correspondientes en la base de datos.
for batch in tqdm(ds.batch(batch_size=512)):
# This particular model requires us to prefix 'search_document:' to stored entities
plot_summary = ["search_document: " + x.strip() for x in batch["PlotSummary"]]
# Output of embedding model is unnormalized
embeddings = model.encode(plot_summary, convert_to_tensor=True)
head_embeddings = embeddings[:, :search_dim]
data = [
{
"title": title,
"head_embedding": head.cpu().numpy(),
"embedding": embedding.cpu().numpy(),
}
for title, head, embedding in zip(batch["Title"], head_embeddings, embeddings)
]
res = client.insert(collection_name=collection_name, data=data)
100%|██████████| 69/69 [05:57<00:00, 5.18s/it]
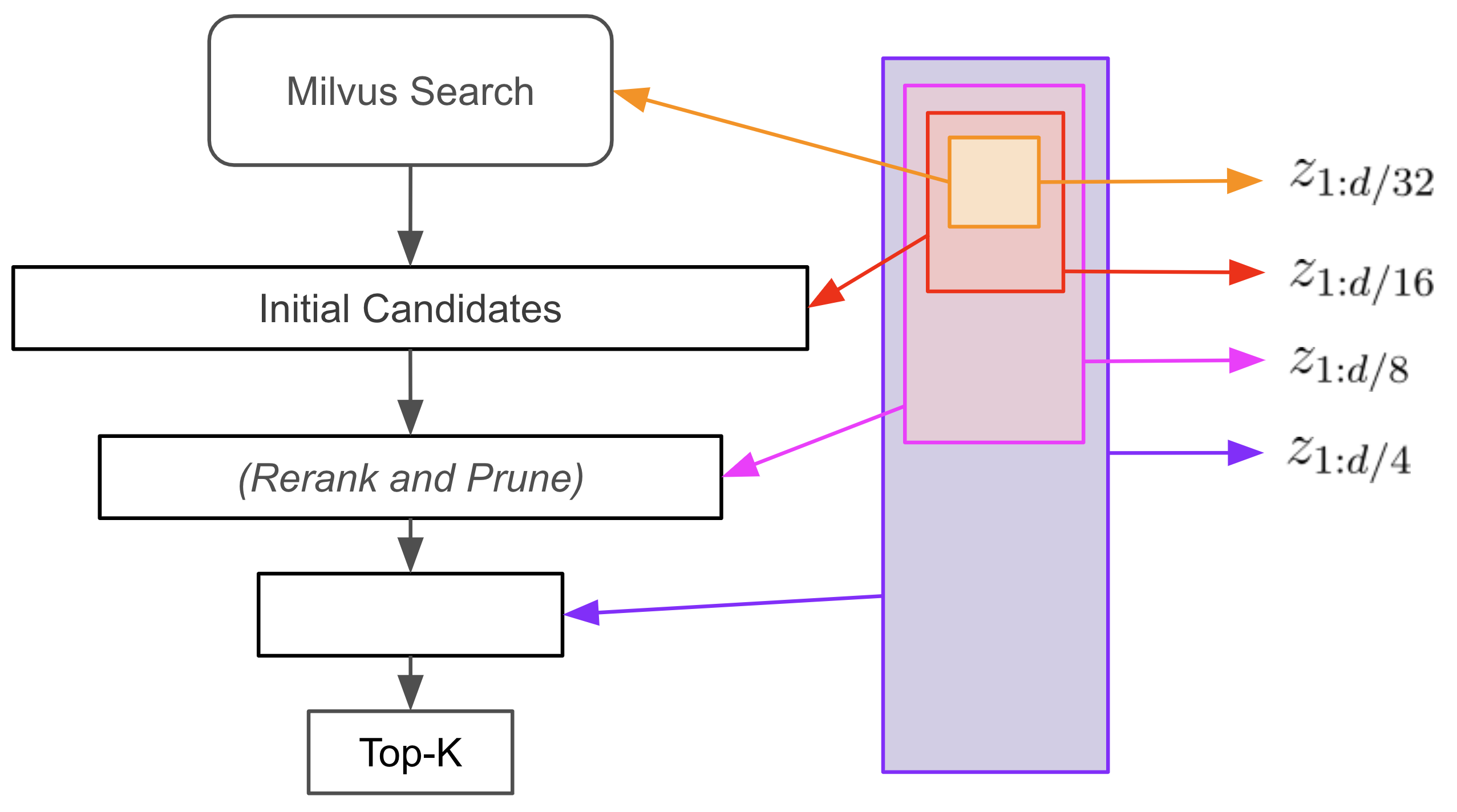
Búsqueda en embudo
Hagamos ahora una "búsqueda en embudo" utilizando el primer 1/6 de las dimensiones de la Matrioska. Tengo tres películas en mente para recuperar y he elaborado mi propio resumen de trama para consultar la base de datos. Incrustamos las consultas y, a continuación, realizamos una búsqueda vectorial en el campo head_embedding, recuperando 128 candidatos a resultado.
queries = [
"An archaeologist searches for ancient artifacts while fighting Nazis.",
"A teenager fakes illness to get off school and have adventures with two friends.",
"A young couple with a kid look after a hotel during winter and the husband goes insane.",
]
# Search the database based on input text
def embed_search(data):
embeds = model.encode(data)
return [x for x in embeds]
# This particular model requires us to prefix 'search_query:' to queries
instruct_queries = ["search_query: " + q.strip() for q in queries]
search_data = embed_search(instruct_queries)
# Normalize head embeddings
head_search = [x[:search_dim] for x in search_data]
# Perform standard vector search on first sixth of embedding dimensions
res = client.search(
collection_name=collection_name,
data=head_search,
anns_field="head_embedding",
limit=128,
output_fields=["title", "head_embedding", "embedding"],
)
En este punto, hemos realizado la búsqueda en un espacio vectorial mucho más pequeño y, por tanto, es probable que hayamos reducido la latencia y los requisitos de almacenamiento del índice en relación con la búsqueda en el espacio completo. Examinemos las 5 primeras coincidencias para cada consulta:
for query, hits in zip(queries, res):
rows = [x["entity"] for x in hits][:5]
print("Query:", query)
print("Results:")
for row in rows:
print(row["title"].strip())
print()
Query: An archaeologist searches for ancient artifacts while fighting Nazis.
Results:
"Pimpernel" Smith
Black Hunters
The Passage
Counterblast
Dominion: Prequel to the Exorcist
Query: A teenager fakes illness to get off school and have adventures with two friends.
Results:
How to Deal
Shorts
Blackbird
Valentine
Unfriended
Query: A young couple with a kid look after a hotel during winter and the husband goes insane.
Results:
Ghostkeeper
Our Vines Have Tender Grapes
The Ref
Impact
The House in Marsh Road
Como vemos, la recuperación se ha visto afectada por el truncamiento de las incrustaciones durante la búsqueda. La búsqueda en embudo soluciona este problema con un truco inteligente: podemos utilizar el resto de las dimensiones de la incrustación para volver a clasificar y podar nuestra lista de candidatos y recuperar el rendimiento de la recuperación sin necesidad de realizar costosas búsquedas vectoriales adicionales.
Para facilitar la exposición del algoritmo de búsqueda en embudo, convertimos los resultados de la búsqueda Milvus para cada consulta en un marco de datos Pandas.
def hits_to_dataframe(hits: pymilvus.client.abstract.Hits) -> pd.DataFrame:
"""
Convert a Milvus search result to a Pandas dataframe. This function is specific to our data schema.
"""
rows = [x["entity"] for x in hits]
rows_dict = [
{"title": x["title"], "embedding": torch.tensor(x["embedding"])} for x in rows
]
return pd.DataFrame.from_records(rows_dict)
dfs = [hits_to_dataframe(hits) for hits in res]
Ahora, para realizar la búsqueda en embudo, iteramos sobre subconjuntos cada vez mayores de las incrustaciones. En cada iteración, volvemos a clasificar los candidatos en función de las nuevas similitudes y eliminamos una fracción de los peor clasificados.
Para concretar, en el paso anterior hemos recuperado 128 candidatos utilizando 1/6 de las dimensiones de la incrustación y la consulta. El primer paso para realizar la búsqueda en embudo es recalcular las similitudes entre las consultas y los candidatos utilizando el primer tercio de las dimensiones. Se eliminan los 64 candidatos inferiores. A continuación, se repite el proceso con los primeros 2/3 de las dimensiones y, después, con todas las dimensiones, eliminando sucesivamente 32 y 16 candidatos.
# An optimized implementation would vectorize the calculation of similarity scores across rows (using a matrix)
def calculate_score(row, query_emb=None, dims=768):
emb = F.normalize(row["embedding"][:dims], dim=-1)
return (emb @ query_emb).item()
# You could also add a top-K parameter as a termination condition
def funnel_search(
df: pd.DataFrame, query_emb, scales=[256, 512, 768], prune_ratio=0.5
) -> pd.DataFrame:
# Loop over increasing prefixes of the embeddings
for dims in scales:
# Query vector must be normalized for each new dimensionality
emb = torch.tensor(query_emb[:dims] / np.linalg.norm(query_emb[:dims]))
# Score
scores = df.apply(
functools.partial(calculate_score, query_emb=emb, dims=dims), axis=1
)
df["scores"] = scores
# Re-rank
df = df.sort_values(by="scores", ascending=False)
# Prune (in our case, remove half of candidates at each step)
df = df.head(int(prune_ratio * len(df)))
return df
dfs_results = [
{"query": query, "results": funnel_search(df, query_emb)}
for query, df, query_emb in zip(queries, dfs, search_data)
]
for d in dfs_results:
print(d["query"], "\n", d["results"][:5]["title"], "\n")
An archaeologist searches for ancient artifacts while fighting Nazis.
0 "Pimpernel" Smith
1 Black Hunters
29 Raiders of the Lost Ark
34 The Master Key
51 My Gun Is Quick
Name: title, dtype: object
A teenager fakes illness to get off school and have adventures with two friends.
21 How I Live Now
32 On the Edge of Innocence
77 Bratz: The Movie
4 Unfriended
108 Simon Says
Name: title, dtype: object
A young couple with a kid look after a hotel during winter and the husband goes insane.
9 The Shining
0 Ghostkeeper
11 Fast and Loose
7 Killing Ground
12 Home Alone
Name: title, dtype: object
Hemos conseguido recuperar la memoria sin realizar ninguna búsqueda vectorial adicional. Cualitativamente, estos resultados parecen ser más eficaces para "En busca del arca perdida" y "El resplandor" que la búsqueda vectorial estándar del tutorial "Búsqueda de películas con Milvus y transformadores de frases", que utiliza un modelo de incrustación diferente. Sin embargo, no es capaz de encontrar "Ferris Bueller's Day Off", a la que volveremos más adelante en el cuaderno. (Véase el artículo Matryoshka Representation Learning para más experimentos cuantitativos y evaluaciones comparativas).
Comparación de la búsqueda en embudo con la búsqueda normal
Comparemos los resultados de nuestra búsqueda en embudo con una búsqueda vectorial estándar en el mismo conjunto de datos con el mismo modelo de incrustación. Realizamos una búsqueda en las incrustaciones completas.
# Search on entire embeddings
res = client.search(
collection_name=collection_name,
data=search_data,
anns_field="embedding",
limit=5,
output_fields=["title", "embedding"],
)
for query, hits in zip(queries, res):
rows = [x["entity"] for x in hits]
print("Query:", query)
print("Results:")
for row in rows:
print(row["title"].strip())
print()
Query: An archaeologist searches for ancient artifacts while fighting Nazis.
Results:
"Pimpernel" Smith
Black Hunters
Raiders of the Lost Ark
The Master Key
My Gun Is Quick
Query: A teenager fakes illness to get off school and have adventures with two friends.
Results:
A Walk to Remember
Ferris Bueller's Day Off
How I Live Now
On the Edge of Innocence
Bratz: The Movie
Query: A young couple with a kid look after a hotel during winter and the husband goes insane.
Results:
The Shining
Ghostkeeper
Fast and Loose
Killing Ground
Home Alone
A excepción de los resultados de "Un adolescente finge una enfermedad para no ir al colegio...", los resultados de la búsqueda en embudo son casi idénticos a los de la búsqueda completa, a pesar de que la búsqueda en embudo se realizó en un espacio de búsqueda de 128 dimensiones frente a las 768 dimensiones de la búsqueda normal.
Investigación del fracaso de la búsqueda en embudo en Ferris Bueller's Day Off
¿Por qué la búsqueda en embudo no consiguió recuperar Ferris Bueller's Day Off? Examinemos si estaba o no en la lista original de candidatos o si se filtró por error.
queries2 = [
"A teenager fakes illness to get off school and have adventures with two friends."
]
# Search the database based on input text
def embed_search(data):
embeds = model.encode(data)
return [x for x in embeds]
instruct_queries = ["search_query: " + q.strip() for q in queries2]
search_data2 = embed_search(instruct_queries)
head_search2 = [x[:search_dim] for x in search_data2]
# Perform standard vector search on subset of embeddings
res = client.search(
collection_name=collection_name,
data=head_search2,
anns_field="head_embedding",
limit=256,
output_fields=["title", "head_embedding", "embedding"],
)
for query, hits in zip(queries, res):
rows = [x["entity"] for x in hits]
print("Query:", queries2[0])
for idx, row in enumerate(rows):
if row["title"].strip() == "Ferris Bueller's Day Off":
print(f"Row {idx}: Ferris Bueller's Day Off")
Query: A teenager fakes illness to get off school and have adventures with two friends.
Row 228: Ferris Bueller's Day Off
Vemos que el problema era que la lista inicial de candidatos no era lo suficientemente grande, o más bien, el resultado deseado no es lo suficientemente similar a la consulta en el nivel más alto de granularidad. Si se cambia de 128 a 256, la recuperación es satisfactoria. Deberíamos establecer una regla empírica para determinar el número de candidatos de un conjunto retenido a fin de evaluar empíricamente la relación entre recuperación y latencia.
dfs = [hits_to_dataframe(hits) for hits in res]
dfs_results = [
{"query": query, "results": funnel_search(df, query_emb)}
for query, df, query_emb in zip(queries2, dfs, search_data2)
]
for d in dfs_results:
print(d["query"], "\n", d["results"][:7]["title"].to_string(index=False), "\n")
A teenager fakes illness to get off school and have adventures with two friends.
A Walk to Remember
Ferris Bueller's Day Off
How I Live Now
On the Edge of Innocence
Bratz: The Movie
Unfriended
Simon Says
¿Importa el orden? Incrustaciones de prefijos y sufijos.
El modelo se entrenó para que funcionara bien al emparejar prefijos recursivamente más pequeños de las incrustaciones. ¿Importa el orden de las dimensiones que utilicemos? Por ejemplo, ¿podríamos tomar subconjuntos de las incrustaciones que sean sufijos? En este experimento, invertimos el orden de las dimensiones en las incrustaciones Matryoshka y realizamos una búsqueda en embudo.
client = MilvusClient(uri="./wikiplots-matryoshka-flipped.db")
fields = [
FieldSchema(name="id", dtype=DataType.INT64, is_primary=True, auto_id=True),
FieldSchema(name="title", dtype=DataType.VARCHAR, max_length=256),
FieldSchema(name="head_embedding", dtype=DataType.FLOAT_VECTOR, dim=search_dim),
FieldSchema(name="embedding", dtype=DataType.FLOAT_VECTOR, dim=embedding_dim),
]
schema = CollectionSchema(fields=fields, enable_dynamic_field=False)
client.create_collection(collection_name=collection_name, schema=schema)
index_params = client.prepare_index_params()
index_params.add_index(
field_name="head_embedding", index_type="FLAT", metric_type="COSINE"
)
client.create_index(collection_name, index_params)
huggingface/tokenizers: The current process just got forked, after parallelism has already been used. Disabling parallelism to avoid deadlocks...
To disable this warning, you can either:
- Avoid using `tokenizers` before the fork if possible
- Explicitly set the environment variable TOKENIZERS_PARALLELISM=(true | false)
for batch in tqdm(ds.batch(batch_size=512)):
plot_summary = ["search_document: " + x.strip() for x in batch["PlotSummary"]]
# Encode and flip embeddings
embeddings = model.encode(plot_summary, convert_to_tensor=True)
embeddings = torch.flip(embeddings, dims=[-1])
head_embeddings = embeddings[:, :search_dim]
data = [
{
"title": title,
"head_embedding": head.cpu().numpy(),
"embedding": embedding.cpu().numpy(),
}
for title, head, embedding in zip(batch["Title"], head_embeddings, embeddings)
]
res = client.insert(collection_name=collection_name, data=data)
100%|██████████| 69/69 [05:50<00:00, 5.08s/it]
# Normalize head embeddings
flip_search_data = [
torch.flip(torch.tensor(x), dims=[-1]).cpu().numpy() for x in search_data
]
flip_head_search = [x[:search_dim] for x in flip_search_data]
# Perform standard vector search on subset of embeddings
res = client.search(
collection_name=collection_name,
data=flip_head_search,
anns_field="head_embedding",
limit=128,
output_fields=["title", "head_embedding", "embedding"],
)
dfs = [hits_to_dataframe(hits) for hits in res]
dfs_results = [
{"query": query, "results": funnel_search(df, query_emb)}
for query, df, query_emb in zip(queries, dfs, flip_search_data)
]
for d in dfs_results:
print(
d["query"],
"\n",
d["results"][:7]["title"].to_string(index=False, header=False),
"\n",
)
An archaeologist searches for ancient artifacts while fighting Nazis.
"Pimpernel" Smith
Black Hunters
Raiders of the Lost Ark
The Master Key
My Gun Is Quick
The Passage
The Mole People
A teenager fakes illness to get off school and have adventures with two friends.
A Walk to Remember
How I Live Now
Unfriended
Cirque du Freak: The Vampire's Assistant
Last Summer
Contest
Day One
A young couple with a kid look after a hotel during winter and the husband goes insane.
Ghostkeeper
Killing Ground
Leopard in the Snow
Stone
Afterglow
Unfaithful
Always a Bride
La recuperación es mucho peor que la búsqueda en embudo o la búsqueda normal, como era de esperar (el modelo de incrustación se entrenó mediante aprendizaje contrastivo en prefijos de las dimensiones de incrustación, no en sufijos).
Resumen
He aquí una comparación de los resultados de búsqueda de los distintos métodos:


