Búsqueda de texto completo
La búsqueda de texto completo es una función que recupera documentos que contienen términos o frases específicos en conjuntos de datos de texto y, a continuación, clasifica los resultados en función de su relevancia. Esta función supera las limitaciones de la búsqueda semántica, que puede pasar por alto términos precisos, garantizando que usted reciba los resultados más exactos y contextualmente relevantes. Además, simplifica las búsquedas vectoriales al aceptar la entrada de texto sin formato, convirtiendo automáticamente los datos de texto en incrustaciones dispersas sin necesidad de generar manualmente incrustaciones vectoriales.
Esta función, que utiliza el algoritmo BM25 para la puntuación de la relevancia, es especialmente valiosa en escenarios de generación de recuperación aumentada (RAG), donde da prioridad a los documentos que coinciden estrechamente con términos de búsqueda específicos.
Al integrar la búsqueda de texto completo con la búsqueda de vectores densos basada en la semántica, puede mejorar la precisión y la relevancia de los resultados de búsqueda. Para más información, consulte Búsqueda híbrida.
Implementación de BM25
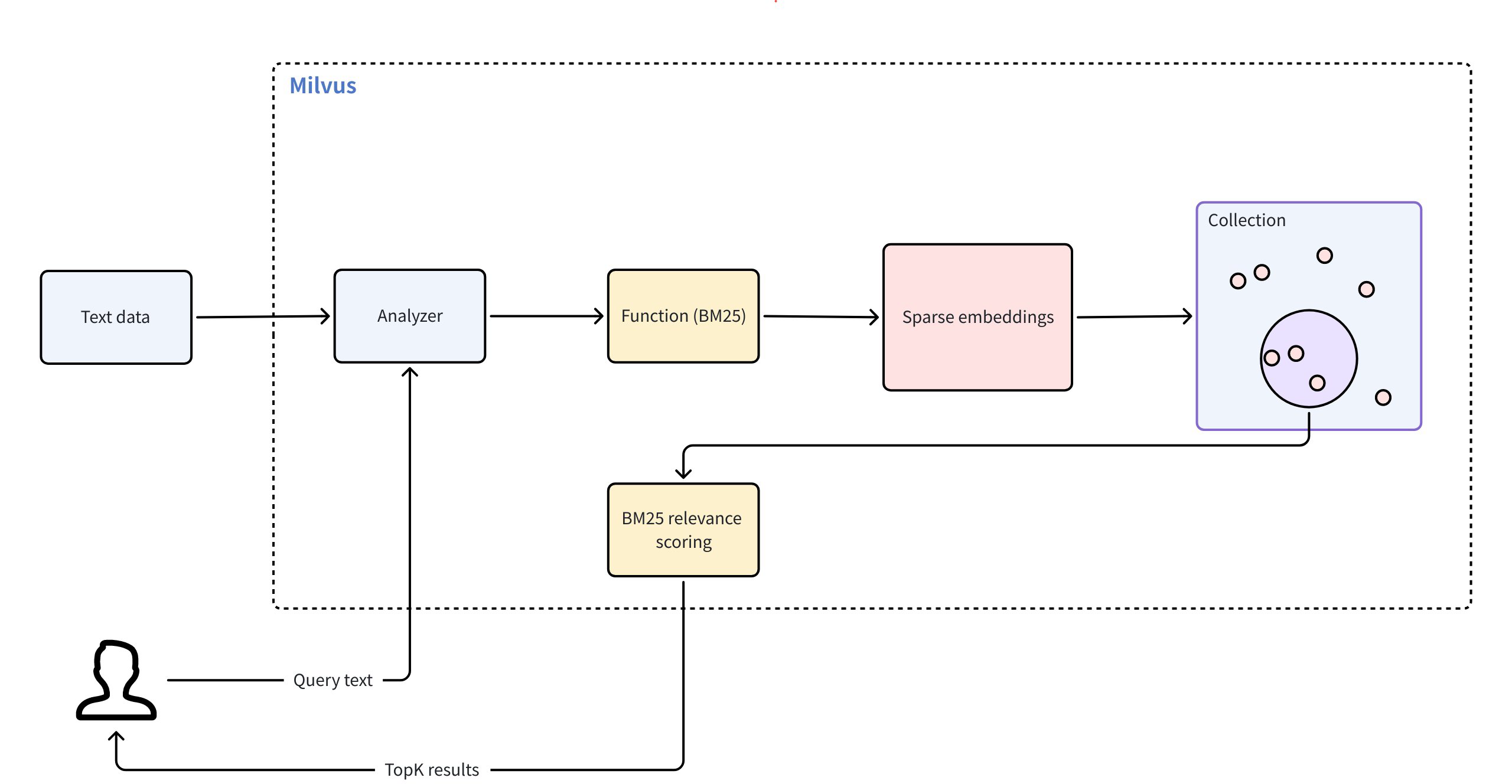
Milvus proporciona búsqueda de texto completo mediante el algoritmo de relevancia BM25, una función de puntuación ampliamente adoptada en los sistemas de recuperación de información, y Milvus la integra en el flujo de trabajo de búsqueda para ofrecer resultados de texto precisos y clasificados por relevancia.
La búsqueda de texto completo en Milvus sigue el siguiente flujo de trabajo:
Entrada de texto sin procesar: Usted inserta documentos de texto o proporciona una consulta utilizando texto sin formato, sin necesidad de modelos de incrustación.
Análisis del texto: Milvus utiliza un analizador para procesar su texto en términos significativos que puedan ser indexados y buscados.
Procesamiento de funciones BM25: Una función integrada transforma estos términos en representaciones vectoriales dispersas optimizadas para la puntuación BM25.
Almacenamiento de colecciones: Milvus almacena las incrustaciones dispersas resultantes en una colección para una recuperación y clasificación rápidas.
Puntuación de relevancia BM25: En el momento de la búsqueda, Milvus aplica la función de puntuación BM25 para calcular la pertinencia de los documentos y devolver los resultados clasificados que mejor se ajusten a los términos de la consulta.
 Búsqueda de texto completo
Búsqueda de texto completo
Para utilizar la búsqueda de texto completo, siga estos pasos principales:
Cree una colección: Configure los campos necesarios y defina una función BM25 que convierta el texto en bruto en incrustaciones dispersas.
Introduzca los datos: Introduzca los documentos de texto en la colección.
Realizar búsquedas: Utilice un texto de consulta en lenguaje natural para obtener resultados clasificados en función de la pertinencia de BM25.
Crear una colección para la búsqueda de texto completo BM25
Para habilitar la búsqueda de texto completo con BM25, debe preparar una colección con los campos necesarios, definir una función BM25 para generar vectores dispersos, configurar un índice y, a continuación, crear la colección.
Definir los campos del esquema
El esquema de su colección debe incluir al menos tres campos obligatorios:
Campo primario: Identifica de forma única cada entidad de la colección.
Campo de texto (
VARCHAR): Almacena documentos de texto sin procesar. Debe configurarenable_analyzer=Truepara que Milvus pueda procesar el texto para la clasificación de relevancia BM25. Por defecto, Milvus utiliza elstandardpara el análisis de texto. Para configurar un analizador diferente, consulte Visión general del analizador.Campo vectorial disperso (
SPARSE_FLOAT_VECTOR): Almacena las incrustaciones dispersas generadas automáticamente por la función BM25.
from pymilvus import MilvusClient, DataType, Function, FunctionType
client = MilvusClient(
uri="http://localhost:19530",
token="root:Milvus"
)
schema = client.create_schema()
schema.add_field(field_name="id", datatype=DataType.INT64, is_primary=True, auto_id=True) # Primary field
schema.add_field(field_name="text", datatype=DataType.VARCHAR, max_length=1000, enable_analyzer=True) # Text field
schema.add_field(field_name="sparse", datatype=DataType.SPARSE_FLOAT_VECTOR) # Sparse vector field; no dim required for sparse vectors
import io.milvus.v2.common.DataType;
import io.milvus.v2.service.collection.request.AddFieldReq;
import io.milvus.v2.service.collection.request.CreateCollectionReq;
CreateCollectionReq.CollectionSchema schema = CreateCollectionReq.CollectionSchema.builder()
.build();
schema.addField(AddFieldReq.builder()
.fieldName("id")
.dataType(DataType.Int64)
.isPrimaryKey(true)
.autoID(true)
.build());
schema.addField(AddFieldReq.builder()
.fieldName("text")
.dataType(DataType.VarChar)
.maxLength(1000)
.enableAnalyzer(true)
.build());
schema.addField(AddFieldReq.builder()
.fieldName("sparse")
.dataType(DataType.SparseFloatVector)
.build());
import (
"context"
"fmt"
"github.com/milvus-io/milvus/client/v2/column"
"github.com/milvus-io/milvus/client/v2/entity"
"github.com/milvus-io/milvus/client/v2/index"
"github.com/milvus-io/milvus/client/v2/milvusclient"
)
ctx, cancel := context.WithCancel(context.Background())
defer cancel()
milvusAddr := "localhost:19530"
client, err := milvusclient.New(ctx, &milvusclient.ClientConfig{
Address: milvusAddr,
})
if err != nil {
fmt.Println(err.Error())
// handle error
}
defer client.Close(ctx)
schema := entity.NewSchema()
schema.WithField(entity.NewField().
WithName("id").
WithDataType(entity.FieldTypeInt64).
WithIsPrimaryKey(true).
WithIsAutoID(true),
).WithField(entity.NewField().
WithName("text").
WithDataType(entity.FieldTypeVarChar).
WithEnableAnalyzer(true).
WithMaxLength(1000),
).WithField(entity.NewField().
WithName("sparse").
WithDataType(entity.FieldTypeSparseVector),
)
import { MilvusClient, DataType } from "@zilliz/milvus2-sdk-node";
const address = "http://localhost:19530";
const token = "root:Milvus";
const client = new MilvusClient({address, token});
const schema = [
{
name: "id",
data_type: DataType.Int64,
is_primary_key: true,
},
{
name: "text",
data_type: "VarChar",
enable_analyzer: true,
enable_match: true,
max_length: 1000,
},
{
name: "sparse",
data_type: DataType.SparseFloatVector,
},
];
console.log(res.results)
export schema='{
"autoId": true,
"enabledDynamicField": false,
"fields": [
{
"fieldName": "id",
"dataType": "Int64",
"isPrimary": true
},
{
"fieldName": "text",
"dataType": "VarChar",
"elementTypeParams": {
"max_length": 1000,
"enable_analyzer": true
}
},
{
"fieldName": "sparse",
"dataType": "SparseFloatVector"
}
]
}'
En la configuración anterior,
id: sirve como clave primaria y se genera automáticamente conauto_id=True.text: almacena los datos de texto sin procesar para las operaciones de búsqueda de texto completo. El tipo de datos debe serVARCHAR, ya queVARCHARes el tipo de datos de cadena de Milvus para el almacenamiento de texto.sparse: un campo vectorial reservado para almacenar incrustaciones dispersas generadas internamente para operaciones de búsqueda de texto completo. El tipo de datos debe serSPARSE_FLOAT_VECTOR.
Definición de la función BM25
La función BM25 convierte el texto tokenizado en vectores dispersos compatibles con la puntuación BM25.
Defina la función y añádala a su esquema:
bm25_function = Function(
name="text_bm25_emb", # Function name
input_field_names=["text"], # Name of the VARCHAR field containing raw text data
output_field_names=["sparse"], # Name of the SPARSE_FLOAT_VECTOR field reserved to store generated embeddings
function_type=FunctionType.BM25, # Set to `BM25`
)
schema.add_function(bm25_function)
import io.milvus.common.clientenum.FunctionType;
import io.milvus.v2.service.collection.request.CreateCollectionReq.Function;
import java.util.*;
schema.addFunction(Function.builder()
.functionType(FunctionType.BM25)
.name("text_bm25_emb")
.inputFieldNames(Collections.singletonList("text"))
.outputFieldNames(Collections.singletonList("sparse"))
.build());
function := entity.NewFunction().
WithName("text_bm25_emb").
WithInputFields("text").
WithOutputFields("sparse").
WithType(entity.FunctionTypeBM25)
schema.WithFunction(function)
const functions = [
{
name: 'text_bm25_emb',
description: 'bm25 function',
type: FunctionType.BM25,
input_field_names: ['text'],
output_field_names: ['sparse'],
params: {},
},
];
export schema='{
"autoId": true,
"enabledDynamicField": false,
"fields": [
{
"fieldName": "id",
"dataType": "Int64",
"isPrimary": true
},
{
"fieldName": "text",
"dataType": "VarChar",
"elementTypeParams": {
"max_length": 1000,
"enable_analyzer": true
}
},
{
"fieldName": "sparse",
"dataType": "SparseFloatVector"
}
],
"functions": [
{
"name": "text_bm25_emb",
"type": "BM25",
"inputFieldNames": ["text"],
"outputFieldNames": ["sparse"],
"params": {}
}
]
}'
Parámetro |
Descripción |
|---|---|
|
Nombre de la función. Esta función convierte el texto en bruto del campo |
|
El nombre del campo |
|
El nombre del campo donde se almacenarán los vectores dispersos generados internamente. Para |
|
El tipo de la función a utilizar. Debe ser |
Si varios campos VARCHAR requieren un tratamiento BM25, defina una función BM25 por campo, cada uno con un nombre y un campo de salida únicos.
Configurar el índice
Después de definir el esquema con los campos necesarios y la función incorporada, configure el índice para su colección.
index_params = client.prepare_index_params()
index_params.add_index(
field_name="sparse",
index_type="SPARSE_INVERTED_INDEX",
metric_type="BM25",
params={
"inverted_index_algo": "DAAT_MAXSCORE",
"bm25_k1": 1.2,
"bm25_b": 0.75
}
)
import io.milvus.v2.common.IndexParam;
Map<String,Object> params = new HashMap<>();
params.put("inverted_index_algo", "DAAT_MAXSCORE");
params.put("bm25_k1", 1.2);
params.put("bm25_b", 0.75);
List<IndexParam> indexes = new ArrayList<>();
indexes.add(IndexParam.builder()
.fieldName("sparse")
.indexType(IndexParam.IndexType.AUTOINDEX)
.metricType(IndexParam.MetricType.BM25)
.extraParams(params)
.build());
indexOption := milvusclient.NewCreateIndexOption("my_collection", "sparse",
index.NewAutoIndex(entity.MetricType(entity.BM25)))
.WithExtraParam("inverted_index_algo", "DAAT_MAXSCORE")
.WithExtraParam("bm25_k1", 1.2)
.WithExtraParam("bm25_b", 0.75)
const index_params = [
{
field_name: "sparse",
metric_type: "BM25",
index_type: "SPARSE_INVERTED_INDEX",
params: {
"inverted_index_algo": "DAAT_MAXSCORE",
"bm25_k1": 1.2,
"bm25_b": 0.75
}
},
];
export indexParams='[
{
"fieldName": "sparse",
"metricType": "BM25",
"indexType": "AUTOINDEX",
"params":{
"inverted_index_algo": "DAAT_MAXSCORE",
"bm25_k1": 1.2,
"bm25_b": 0.75
}
}
]'
Parámetro |
Descripción |
|---|---|
|
El nombre del campo vectorial a indexar. Para la búsqueda de texto completo, debe ser el campo que almacena los vectores dispersos generados. En este ejemplo, establezca el valor |
|
El tipo de índice a crear. |
|
El valor de este parámetro debe establecerse en |
|
Un diccionario de parámetros adicionales específicos del índice. |
|
El algoritmo utilizado para construir y consultar el índice. Valores válidos:
|
|
Controla la saturación de frecuencias de términos. Los valores más altos aumentan la importancia de las frecuencias de términos en la clasificación de documentos. Rango de valores: [1.2, 2.0]. |
|
Controla el grado de normalización de la longitud del documento. Normalmente se utilizan valores entre 0 y 1, con un valor por defecto de 0,75. Un valor de 1 significa que no se normaliza la longitud. Un valor de 1 significa que no se normaliza la longitud, mientras que un valor de 0 significa una normalización completa. |
Crear la colección
Ahora creamos la colección utilizando los parámetros de esquema e índice definidos.
client.create_collection(
collection_name='my_collection',
schema=schema,
index_params=index_params
)
import io.milvus.v2.service.collection.request.CreateCollectionReq;
CreateCollectionReq requestCreate = CreateCollectionReq.builder()
.collectionName("my_collection")
.collectionSchema(schema)
.indexParams(indexes)
.build();
client.createCollection(requestCreate);
err = client.CreateCollection(ctx,
milvusclient.NewCreateCollectionOption("my_collection", schema).
WithIndexOptions(indexOption))
if err != nil {
fmt.Println(err.Error())
// handle error
}
await client.create_collection(
collection_name: 'my_collection',
schema: schema,
index_params: index_params,
functions: functions
);
export CLUSTER_ENDPOINT="http://localhost:19530"
export TOKEN="root:Milvus"
curl --request POST \
--url "${CLUSTER_ENDPOINT}/v2/vectordb/collections/create" \
--header "Authorization: Bearer ${TOKEN}" \
--header "Content-Type: application/json" \
--header "Request-Timeout: 10" \
-d "{
\"collectionName\": \"my_collection\",
\"schema\": $schema,
\"indexParams\": $indexParams
}"
Insertar datos de texto
Después de configurar tu colección e índice, estás listo para insertar datos de texto. En este proceso, sólo necesitas proporcionar el texto en bruto. La función incorporada que definimos anteriormente genera automáticamente el vector disperso correspondiente para cada entrada de texto.
client.insert('my_collection', [
{'text': 'information retrieval is a field of study.'},
{'text': 'information retrieval focuses on finding relevant information in large datasets.'},
{'text': 'data mining and information retrieval overlap in research.'},
])
import com.google.gson.Gson;
import com.google.gson.JsonObject;
import io.milvus.v2.service.vector.request.InsertReq;
Gson gson = new Gson();
List<JsonObject> rows = Arrays.asList(
gson.fromJson("{\"text\": \"information retrieval is a field of study.\"}", JsonObject.class),
gson.fromJson("{\"text\": \"information retrieval focuses on finding relevant information in large datasets.\"}", JsonObject.class),
gson.fromJson("{\"text\": \"data mining and information retrieval overlap in research.\"}", JsonObject.class)
);
client.insert(InsertReq.builder()
.collectionName("my_collection")
.data(rows)
.build());
// go
await client.insert({
collection_name: 'my_collection',
data: [
{'text': 'information retrieval is a field of study.'},
{'text': 'information retrieval focuses on finding relevant information in large datasets.'},
{'text': 'data mining and information retrieval overlap in research.'},
]);
curl --request POST \
--url "${CLUSTER_ENDPOINT}/v2/vectordb/entities/insert" \
--header "Authorization: Bearer ${TOKEN}" \
--header "Content-Type: application/json" \
--header "Request-Timeout: 10" \
-d '{
"data": [
{"text": "information retrieval is a field of study."},
{"text": "information retrieval focuses on finding relevant information in large datasets."},
{"text": "data mining and information retrieval overlap in research."}
],
"collectionName": "my_collection"
}'
Realizar una búsqueda de texto completo
Una vez que haya insertado datos en su colección, puede realizar búsquedas de texto completo utilizando consultas de texto sin procesar. Milvus convierte automáticamente su consulta en un vector disperso y clasifica los resultados de búsqueda coincidentes utilizando el algoritmo BM25, y luego devuelve los resultados topK (limit).
Puede resaltar los términos coincidentes en los resultados de búsqueda configurando un resaltador de texto. Consulte Resaltador de texto para obtener más información.
res = client.search(
collection_name='my_collection',
data=['whats the focus of information retrieval?'],
anns_field='sparse',
output_fields=['text'], # Fields to return in search results; sparse field cannot be output
limit=3,
)
print(res)
import io.milvus.v2.service.vector.request.SearchReq;
import io.milvus.v2.service.vector.request.data.EmbeddedText;
import io.milvus.v2.service.vector.response.SearchResp;
Map<String,Object> searchParams = new HashMap<>();
SearchResp searchResp = client.search(SearchReq.builder()
.collectionName("my_collection")
.data(Collections.singletonList(new EmbeddedText("whats the focus of information retrieval?")))
.annsField("sparse")
.topK(3)
.searchParams(searchParams)
.outputFields(Collections.singletonList("text"))
.build());
annSearchParams := index.NewCustomAnnParam()
resultSets, err := client.Search(ctx, milvusclient.NewSearchOption(
"my_collection", // collectionName
3, // limit
[]entity.Vector{entity.Text("whats the focus of information retrieval?")},
).WithConsistencyLevel(entity.ClStrong).
WithANNSField("sparse").
WithAnnParam(annSearchParams).
WithOutputFields("text"))
if err != nil {
fmt.Println(err.Error())
// handle error
}
for _, resultSet := range resultSets {
fmt.Println("IDs: ", resultSet.IDs.FieldData().GetScalars())
fmt.Println("Scores: ", resultSet.Scores)
fmt.Println("text: ", resultSet.GetColumn("text").FieldData().GetScalars())
}
await client.search(
collection_name: 'my_collection',
data: ['whats the focus of information retrieval?'],
anns_field: 'sparse',
output_fields: ['text'],
limit: 3,
)
curl --request POST \
--url "${CLUSTER_ENDPOINT}/v2/vectordb/entities/search" \
--header "Authorization: Bearer ${TOKEN}" \
--header "Content-Type: application/json" \
--header "Request-Timeout: 10" \
--data-raw '{
"collectionName": "my_collection",
"data": [
"whats the focus of information retrieval?"
],
"annsField": "sparse",
"limit": 3,
"outputFields": [
"text"
],
"searchParams":{
"params":{}
}
}'
Parámetro |
Descripción |
|---|---|
|
Diccionario que contiene los parámetros de búsqueda. |
|
Proporción de términos de baja importancia que se ignoran durante la búsqueda. Para más detalles, consulte Vector disperso. |
|
Texto de consulta en lenguaje natural. Milvus convierte automáticamente su consulta de texto en vectores dispersos utilizando la función BM25 - no proporcione vectores precalculados. |
|
El nombre del campo que contiene los vectores dispersos generados internamente. |
|
Lista de nombres de campos que se mostrarán en los resultados de la búsqueda. Admite todos los campos excepto el campo de vectores dispersos que contiene las incrustaciones generadas por BM25. Los campos de salida habituales son el campo de clave principal (por ejemplo, |
|
Número máximo de primeras coincidencias a devolver. |
FAQ
¿Puedo obtener o acceder a los vectores dispersos generados por la función BM25 en la búsqueda de texto completo?
No, los vectores dispersos generados por la función BM25 no son directamente accesibles o extraíbles en la búsqueda de texto completo. He aquí los detalles:
La función BM25 genera internamente vectores dispersos para la clasificación y la recuperación.
Estos vectores se almacenan en el campo disperso, pero no pueden incluirse en la búsqueda de texto completo.
output_fieldsSólo puede mostrar los campos de texto originales y los metadatos (como
id,text)
Ejemplo:
# ❌ This throws an error - you cannot output the sparse field
client.search(
collection_name='my_collection',
data=['query text'],
anns_field='sparse',
output_fields=['text', 'sparse'] # 'sparse' causes an error
limit=3,
search_params=search_params
)
# ✅ This works - output text fields only
client.search(
collection_name='my_collection',
data=['query text'],
anns_field='sparse',
output_fields=['text']
limit=3,
search_params=search_params
)
¿Por qué tengo que definir un campo vectorial disperso si no puedo acceder a él?
El campo vectorial disperso sirve como índice de búsqueda interna, similar a los índices de bases de datos con los que los usuarios no interactúan directamente.
Justificación del diseño:
Separación de intereses: Usted trabaja con texto (entrada/salida), Milvus maneja vectores (procesamiento interno)
Rendimiento: Los vectores dispersos precalculados permiten una clasificación rápida de BM25 durante las consultas.
Experiencia del usuario: Resume las operaciones vectoriales complejas detrás de una interfaz de texto simple
Si necesita acceso a vectores:
Utilice operaciones manuales de vectores dispersos en lugar de búsquedas de texto completo.
Cree colecciones separadas para flujos de trabajo personalizados de vectores dispersos
Para obtener más información, consulte Vector disperso.