Embedding Function OverviewCompatible with Milvus 2.6.x
The Function module in Milvus allows you to transform raw text data into vector embeddings by automatically calling external embedding service providers (like OpenAI, AWS Bedrock, Google Vertex AI, etc.). With the Function module, you no longer need to manually interface with embedding APIs—Milvus handles the entire process of sending requests to providers, receiving embeddings, and storing them in your collections. For semantic search, you need to provide only raw query data, not a query vector. Milvus generates the query vector with the same model you used for ingestion, compares it to the stored vectors, and returns the most relevant results.
Limits
Any input field that the Function module embeds must always contain a value; if a null is supplied, the module will throw an error.
The Function module processes only fields that are explicitly defined in the collection schema; it does not generate embeddings for dynamic fields.
Input fields to be embedded must be of the
VARCHARtype.The Function module can embed an input field to:
FLOAT_VECTORINT8_VECTOR
Conversions to
BINARY_VECTOR,FLOAT16_VECTOR, orBFLOAT16_VECTORare not supported.
Supported embedding service providers
Provider |
Typical Models |
Embedding Type |
Authentication Method |
|---|---|---|---|
text-embedding-3-* |
|
API key |
|
Deployment-based |
|
API key |
|
text-embedding-v3 |
|
API key |
|
amazon.titan-embed-text-v2 |
|
AK/SK pair |
|
text-embedding-005 |
|
GCP service account JSON credential |
|
voyage-3, voyage-lite-02 |
|
API key |
|
embed-english-v3.0 |
|
API key |
|
BAAI/bge-large-zh-v1.5 |
|
API key |
|
Any TEI-served model |
|
Optional API key |
How it works
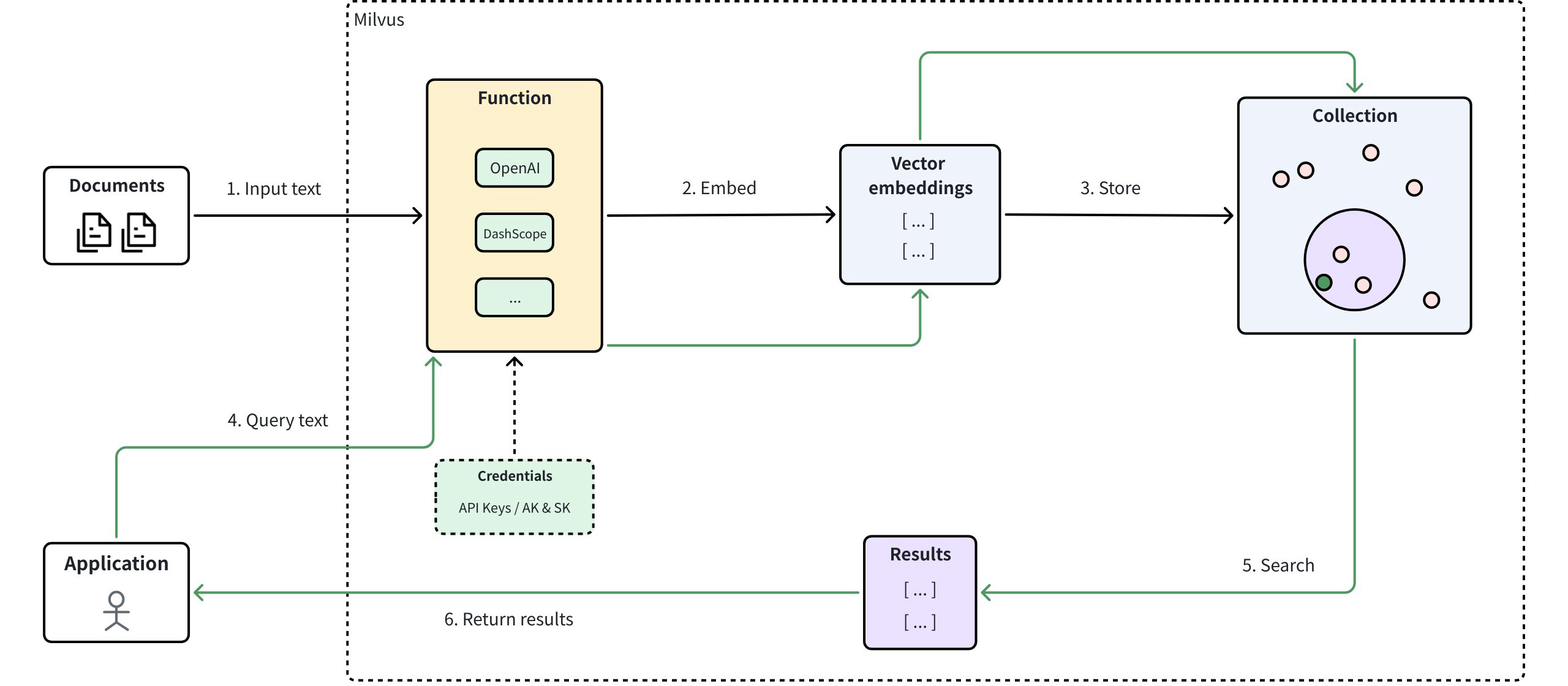
The following diagram shows how the Function works in Milvus.
Input text: Users insert raw data (e.g. documents) into Milvus.
Generate embeddings: The Function module within Milvus automatically calls the configured model provider to convert raw data into vector embeddings.
Store embeddings: The resulting embeddings are stored in explicitly defined vector fields within Milvus collections.
Query text: Users submit text queries to Milvus.
Semantic search: Milvus internally converts queries to vector embeddings, conducts similarity searches against stored embeddings, and retrieves relevant results.
Return results: Milvus returns top-matching results to the application.
 Embedding Function Overview
Embedding Function Overview
Configure credentials
Before using an embedding function with Milvus, configure embedding service credentials for Milvus access.
Milvus lets you supply embedding service credentials in two ways:
Configuration file (
milvus.yaml):The example in this topic demonstrates the recommended setup using
milvus.yaml.Environment variables:
For details on configuring credentials via environment variables, see the embedding service provider’s documentation (for example, OpenAI or Azure OpenAI).
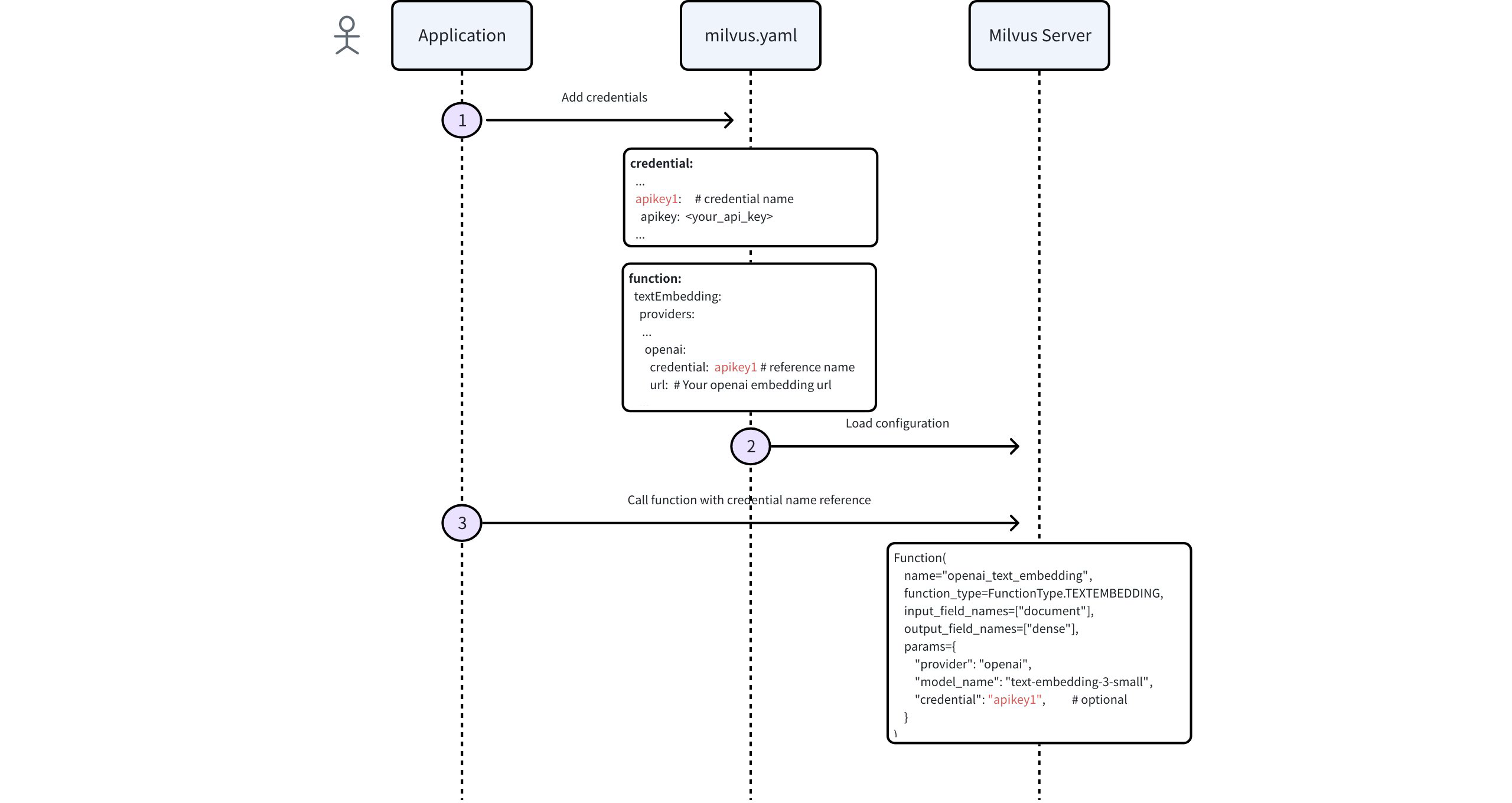
The following diagram shows the process of configuring credentials via Milvus configuration file (milvus.yaml) and then calling the Function within Milvus.
 Credential Config Overflow
Credential Config Overflow
Step 1: Add credentials to Milvus configuration file
In your milvus.yaml file, edit the credential block with entries for each provider you need to access:
# milvus.yaml credential store section
# This section defines all your authentication credentials for external embedding providers
# Each credential gets a unique name (e.g., aksk1, apikey1) that you'll reference elsewhere
credential:
# For AWS Bedrock or services using access/secret key pairs
# 'aksk1' is just an example name - you can choose any meaningful identifier
aksk1:
access_key_id: <YOUR_AK>
secret_access_key: <YOUR_SK>
# For OpenAI, Voyage AI, or other API key-based services
# 'apikey1' is a custom name you choose to identify this credential
apikey1:
apikey: <YOUR_API_KEY>
# For Google Vertex AI using service account credentials
# 'gcp1' is an example name for your Google Cloud credentials
gcp1:
credential_json: <BASE64_OF_JSON>
Step 2: Configure provider settings
In the same configuration file (milvus.yaml), edit the function block to tell Milvus which key to use for embedding service calls:
function:
textEmbedding:
providers:
openai: # calls OpenAI
credential: apikey1 # Reference to the credential label
# url: # (optional) custom url
bedrock: # calls AWS Bedrock
credential: aksk1 # Reference to the credential label
region: us-east-2
vertexai: # calls Google Vertex AI
credential: gcp1 # Reference to the credential label
# url: # (optional) custom url
tei: # Built-in Tiny Embedding model
enable: true # Whether to enable TEI model service
For more information on how to apply Milvus configuration, refer to Configure Milvus on the Fly.
Use embedding function
Once credentials are configured in your Milvus configuration file, follow these steps to define and use embedding functions.
Step 1: Define schema fields
To use an embedding function, create a collection with a specific schema. This schema must include at least three necessary fields:
The primary field that uniquely identifies each entity in a collection.
A scalar field that stores raw data to be embedded.
A vector field reserved to store vector embeddings that the function will generate for the scalar field.
The following example defines a schema with one scalar field "document" for storing textual data and one vector field "dense" for storing embeddings to be generated by the Function module. Remember to set the vector dimension (dim) to match the output of your chosen embedding model.
from pymilvus import MilvusClient, DataType, Function, FunctionType
# Initialize Milvus client
client = MilvusClient(
uri="http://localhost:19530",
)
# Create a new schema for the collection
schema = client.create_schema()
# Add primary field "id"
schema.add_field("id", DataType.INT64, is_primary=True, auto_id=False)
# Add scalar field "document" for storing textual data
schema.add_field("document", DataType.VARCHAR, max_length=9000)
# Add vector field "dense" for storing embeddings.
# IMPORTANT: Set dim to match the exact output dimension of the embedding model.
# For instance, OpenAI's text-embedding-3-small model outputs 1536-dimensional vectors.
# For dense vector, data type can be FLOAT_VECTOR or INT8_VECTOR
schema.add_field("dense", DataType.FLOAT_VECTOR, dim=1536)
// java
// nodejs
// go
# restful
Step 2: Add embedding function to schema
The Function module in Milvus automatically converts raw data stored in a scalar field into embeddings and stores them into the explicitly defined vector field.
The example below adds a Function module (openai_embedding) that converts the scalar field "document" into embeddings, storing the resulting vectors in the "dense" vector field defined earlier.
# Define embedding function (example: OpenAI provider)
text_embedding_function = Function(
name="openai_embedding", # Unique identifier for this embedding function
function_type=FunctionType.TEXTEMBEDDING, # Type of embedding function
input_field_names=["document"], # Scalar field to embed
output_field_names=["dense"], # Vector field to store embeddings
params={ # Provider-specific configuration (highest priority)
"provider": "openai", # Embedding model provider
"model_name": "text-embedding-3-small", # Embedding model
# "credential": "apikey1", # Optional: Credential label
# Optional parameters:
# "dim": "1536", # Optionally shorten the vector dimension
# "user": "user123" # Optional: identifier for API tracking
}
)
# Add the embedding function to your schema
schema.add_function(text_embedding_function)
// java
// nodejs
// go
# restful
Parameter |
Description |
Example Value |
|---|---|---|
|
Unique identifier for the embedding function within Milvus. |
|
|
Type of function used. For text embedding, set the value to Note: Milvus accepts |
|
|
Scalar field containing raw data to be embedded. Currently, this parameter accepts only one field name. |
|
|
Vector field for storing generated embeddings. Currently, this parameter accepts only one field name. |
|
|
Dictionary containing embedding configurations. Note: Parameters within |
|
|
The embedding model provider. |
|
|
Specifies which embedding model to use. |
|
|
The label of a credential defined in the top-level
|
|
|
The number of dimensions for the output embeddings. For OpenAI's third-generation models, you can shorten the full vector to reduce cost and latency without a significant loss of semantic information. For more information, refer to OpenAI announcement blog post. Note: If you shorten the vector dimension, ensure the |
|
|
A user-level identifier for tracking API usage. |
|
For collections with multiple scalar fields requiring text-to-vector conversion, add separate functions to the collection schema, ensuring each function has a unique name and output_field_names value.
Step 3: Configure index
After defining the schema with necessary fields and the built-in function, set up the index for your collection. To simplify this process, use AUTOINDEX as the index_type, an option that allows Milvus to choose and configure the most suitable index type based on the structure of your data.
# Prepare index parameters
index_params = client.prepare_index_params()
# Add AUTOINDEX to automatically select optimal indexing method
index_params.add_index(
field_name="dense",
index_type="AUTOINDEX",
metric_type="COSINE"
)
// java
// nodejs
// go
# restful
Step 4: Create collection
Now create the collection using the schema and index parameters defined.
# Create collection named "demo"
client.create_collection(
collection_name='demo',
schema=schema,
index_params=index_params
)
// java
// nodejs
// go
# restful
Step 5: Insert data
After setting up your collection and index, you’re ready to insert your raw data. In this process, you need only to provide the raw text. The Function module we defined earlier automatically generates the corresponding sparse vector for each text entry.
# Insert sample documents
client.insert('demo', [
{'id': 1, 'document': 'Milvus simplifies semantic search through embeddings.'},
{'id': 2, 'document': 'Vector embeddings convert text into searchable numeric data.'},
{'id': 3, 'document': 'Semantic search helps users find relevant information quickly.'},
])
// java
// nodejs
// go
# restful
Step 6: Perform vector search
After data insertion, perform a semantic search using raw query text. Milvus automatically converts your query into an embedding vector, retrieves relevant documents based on similarity, and returns the top-matching results.
# Perform semantic search
results = client.search(
collection_name='demo',
data=['How does Milvus handle semantic search?'], # Use text query rather than query vector
anns_field='dense', # Use the vector field that stores embeddings
limit=1,
output_fields=['document'],
)
print(results)
# Example output:
# data: ["[{'id': 1, 'distance': 0.8821347951889038, 'entity': {'document': 'Milvus simplifies semantic search through embeddings.'}}]"]
// java
// nodejs
// go
# restful
For more information about search and query operations, refer to Basic Vector Search and Query.
FAQ
What’s the difference between configuring credentials in milvus.yaml vs environment variables?
Both methods work, but using milvus.yaml is the recommended approach as it provides centralized credential management and consistent credential naming across all providers. When using environment variables, the variable names vary depending on the embedding service provider, so refer to each provider’s dedicated page to understand the specific environment variable names required (for example, OpenAI or Azure OpenAI).
What happens if I don’t specify a credential parameter in the function definition?
Milvus follows this credential resolution order:
- First, it looks for the default credential configured for that provider in the
milvus.yamlfile - If no default credential exists in milvus.yaml, it falls back to environment variables (if configured)
- If neither
milvus.yamlcredentials nor environment variables are configured, Milvus will throw an error
How can I verify that embeddings are being generated correctly?
You can check by:
- Querying your collection after insertion to see if the vector field contains data
- Checking the vector field length matches your expected dimensions
- Performing a simple similarity search to verify the embeddings produce meaningful results
When I perform a similarity search, can I use a query vector rather than raw text?
Yes, you can use pre-computed query vectors instead of raw text for similarity search. While the Function module automatically converts raw text queries to embeddings, you can also directly provide vector data to the data parameter in your search operation. Note: The dimension size of your provided query vector must be consistent with the dimension size of the vector embeddings generated by your Function module.
Example:
# Using raw text (Function module converts automatically)
results = client.search(
collection_name='demo',
data=['How does Milvus handle semantic search?'],
anns_field='dense',
limit=1
)
# Using pre-computed query vector (must match stored vector dimensions)
query_vector = [0.1, 0.2, 0.3, ...] # Must be same dimension as stored embeddings
results = client.search(
collection_name='demo',
data=[query_vector],
anns_field='dense',
limit=1
)
// java
// nodejs
// go
# restful