Aufbau eines RAG-Systems mit Langflow und Milvus
Dieser Leitfaden zeigt, wie man Langflow verwendet, um eine Retrieval-Augmented Generation (RAG) Pipeline mit Milvus zu erstellen.
Das RAG-System verbessert die Texterzeugung, indem es zunächst relevante Dokumente aus einer Wissensbasis abruft und dann neue Antworten auf der Grundlage dieses Kontexts generiert. Milvus wird verwendet, um Texteinbettungen zu speichern und abzurufen, während Langflow die Integration von Abruf und Generierung in einen visuellen Workflow erleichtert.
Langflow ermöglicht den einfachen Aufbau von RAG-Pipelines, bei denen Textabschnitte eingebettet, in Milvus gespeichert und bei relevanten Abfragen abgerufen werden. So kann das Sprachmodell kontextbezogene Antworten generieren.
Milvus dient als skalierbare Vektordatenbank, die schnell semantisch ähnlichen Text findet, während Langflow es Ihnen ermöglicht, zu verwalten, wie Ihre Pipeline den Textabruf und die Generierung von Antworten handhabt. Zusammen bieten sie eine effiziente Möglichkeit, eine robuste RAG-Pipeline für erweiterte textbasierte Anwendungen zu erstellen.
Voraussetzungen
Vergewissern Sie sich, dass Sie die folgenden Abhängigkeiten installiert haben, bevor Sie dieses Notizbuch ausführen:
$ python -m pip install langflow -U
Tutorial
Sobald alle Abhängigkeiten installiert sind, starten Sie ein Langflow-Dashboard, indem Sie den folgenden Befehl eingeben:
$ python -m langflow run
Daraufhin öffnet sich ein Dashboard wie unten gezeigt: 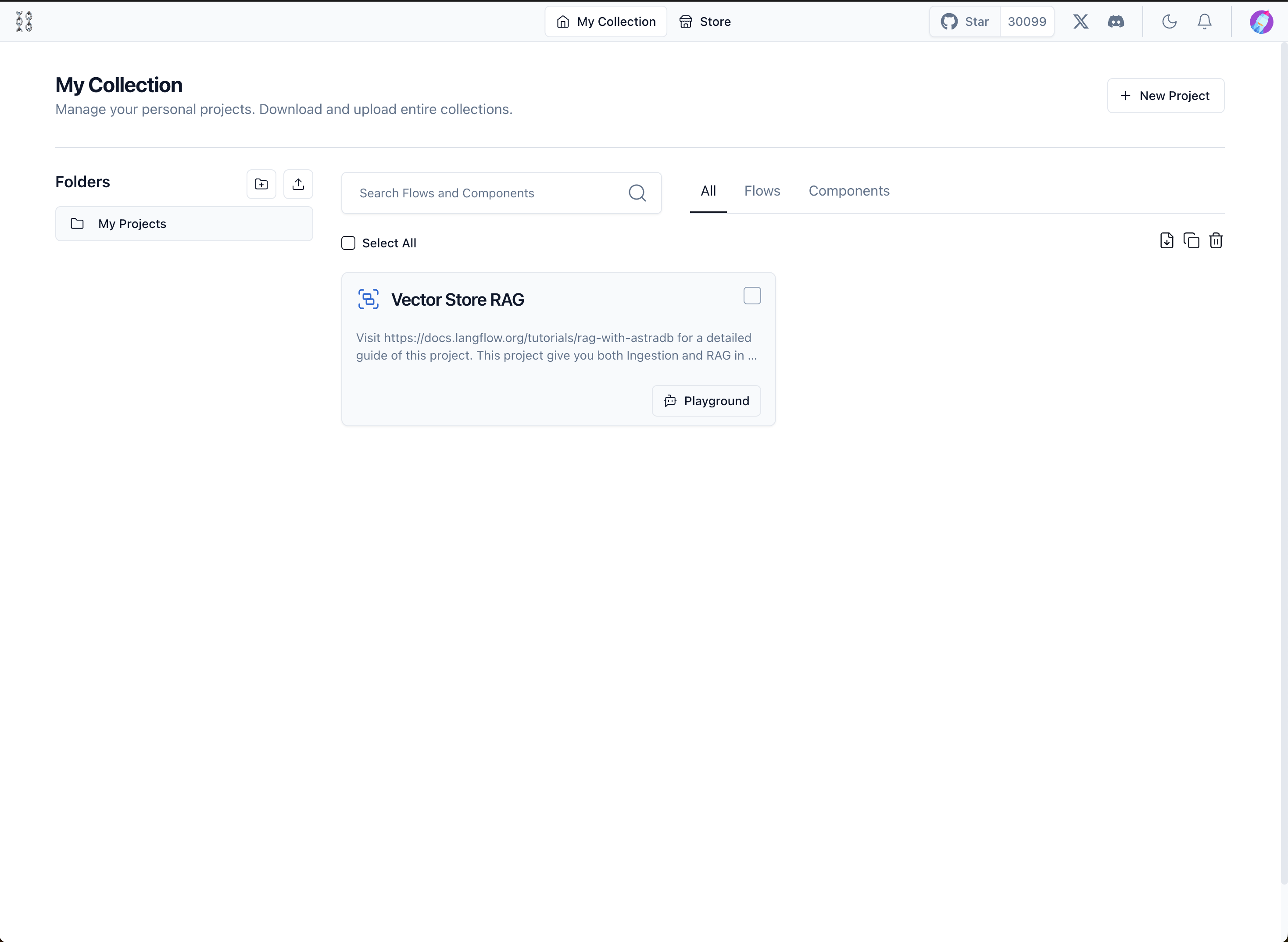 langflow
langflow
Wir wollen ein Vector Store-Projekt erstellen, also müssen wir zuerst auf die Schaltfläche Neues Projekt klicken. Es öffnet sich ein Fenster, in dem wir die Option Vector Store RAG auswählen:  panel
panel
Sobald das Vector Store Rag-Projekt erfolgreich erstellt wurde, ist der Standard-Vektorspeicher AstraDB, während wir Milvus verwenden wollen. Also müssen wir diese beiden astraDB-Module durch Milvus ersetzen, um Milvus als Vektorspeicher zu verwenden. 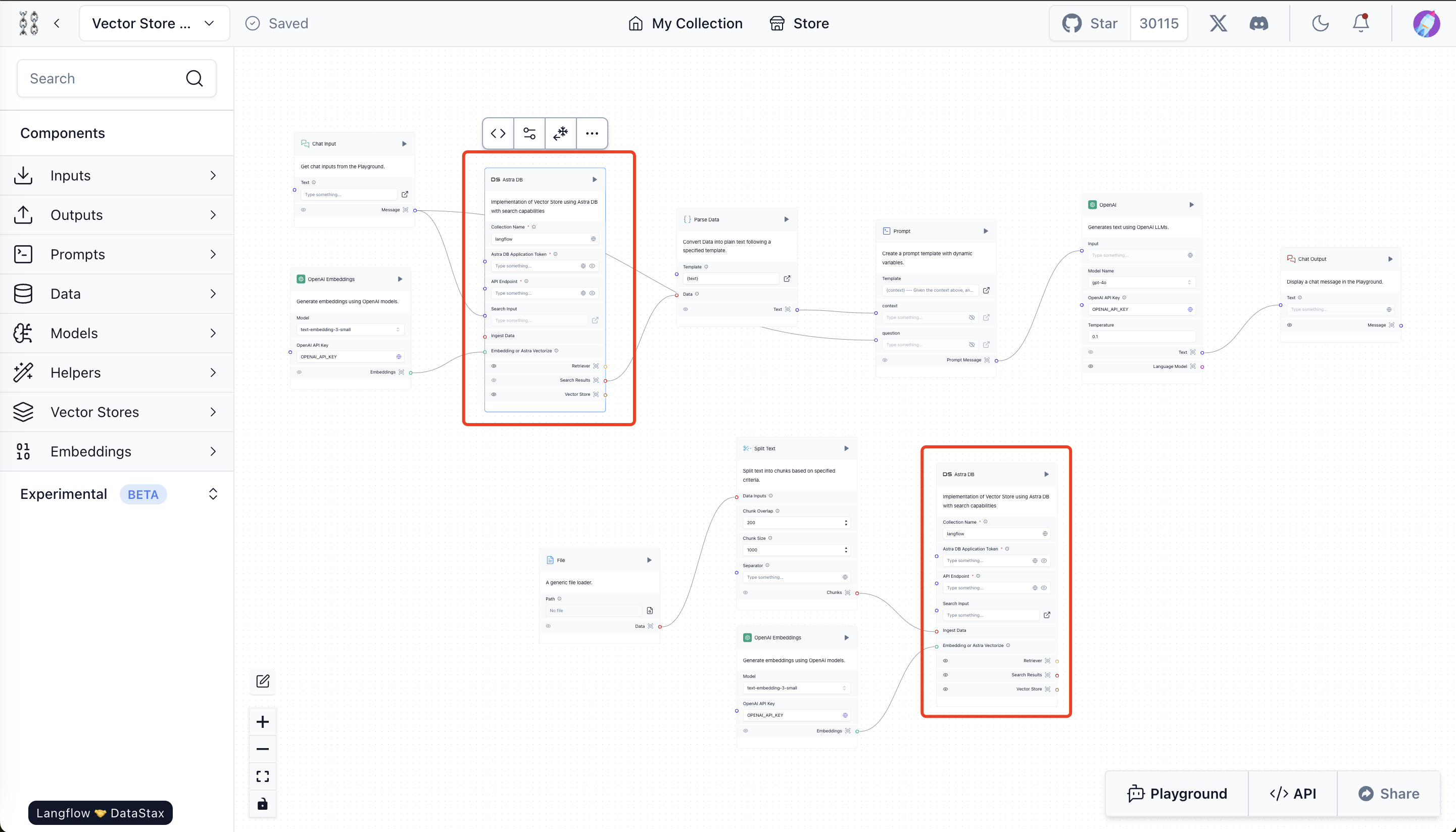 astraDB
astraDB
Schritte zum Ersetzen von astraDB durch Milvus:
- Entfernen Sie die vorhandenen Karten des Vektorspeichers. Klicken Sie auf die beiden rot markierten AstraDB-Karten in der obigen Abbildung und drücken Sie die Rücktaste, um sie zu löschen.
- Klicken Sie auf die Option Vector Store in der Seitenleiste, wählen Sie Milvus und ziehen Sie es in den Canvas. Tun Sie dies zweimal, da wir 2 Milvus-Karten benötigen, eine für die Speicherung des Dateiverarbeitungs-Workflows und eine für den Such-Workflow.
- Verknüpfen Sie die Milvus-Module mit den übrigen Komponenten. Siehe das Bild unten als Referenz.
- Konfigurieren Sie die Milvus-Anmeldeinformationen für beide Milvus-Module. Am einfachsten ist es, Milvus Lite zu verwenden, indem Sie den Connection URI auf milvus_demo.db setzen. Wenn Sie einen Milvus-Server im Eigenbetrieb oder in der Zilliz-Cloud haben, setzen Sie die Connection URI auf den Server-Endpunkt und das Connection Password auf den Token (für Milvus ist das die Verkettung "
: ", für die Zilliz-Cloud ist es der API-Schlüssel). Siehe Bild unten als Referenz:
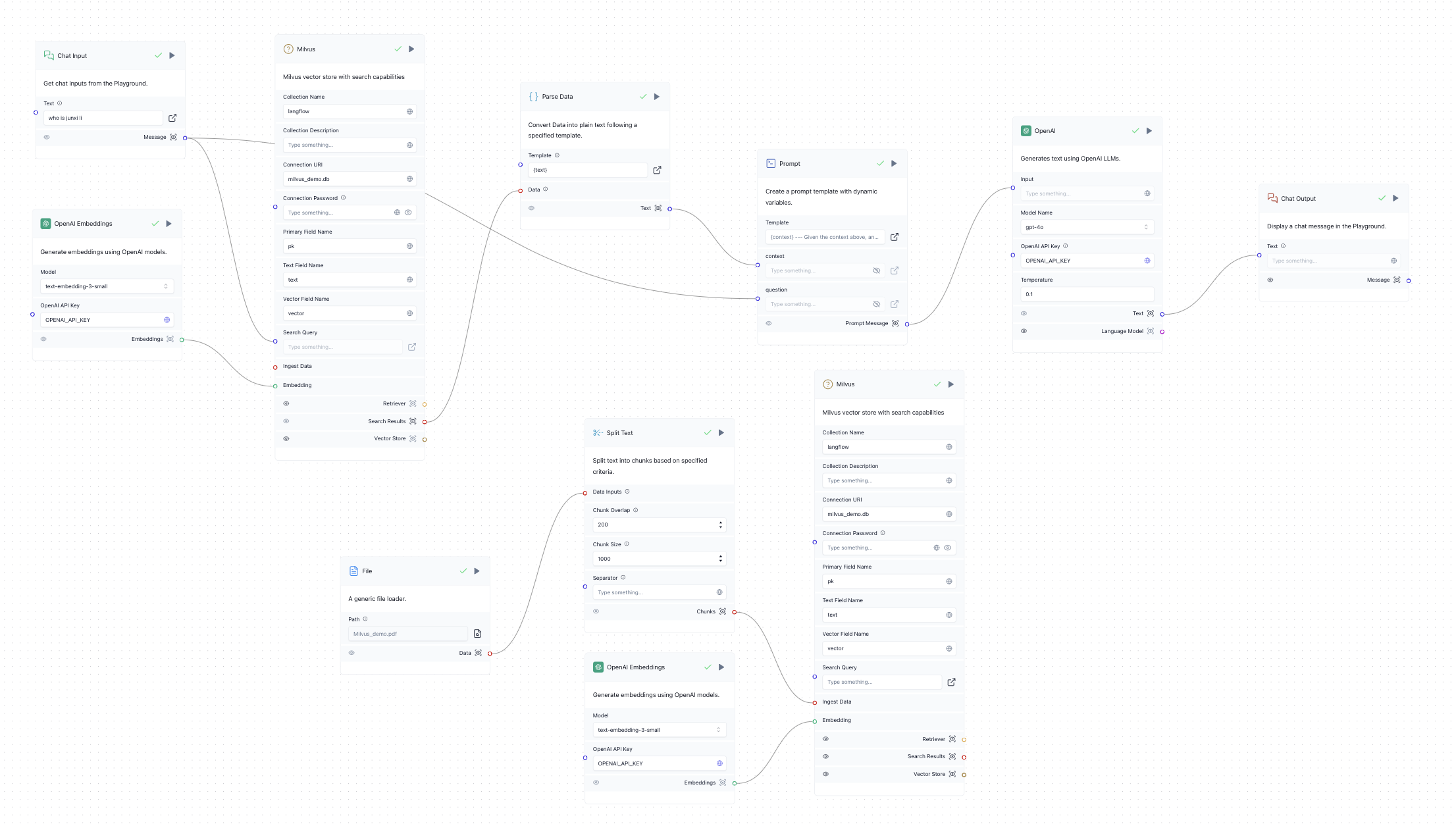 Milvus Struktur Demo
Milvus Struktur Demo
Wissen in das RAG-System einbinden
- Laden Sie eine Datei als LLM-Wissensbasis über das Dateimodul unten links hoch. Hier haben wir eine Datei hochgeladen, die eine kurze Einführung in Milvus enthält.
- Starten Sie den Einfüge-Workflow, indem Sie auf die Schaltfläche "Ausführen" im Milvus-Modul unten rechts klicken. Dadurch wird das Wissen in den Milvus-Vektorspeicher eingefügt.
- Testen Sie, ob das Wissen im Speicher ist. Öffnen Sie die Spielwiese und stellen Sie Fragen zu der hochgeladenen Datei.
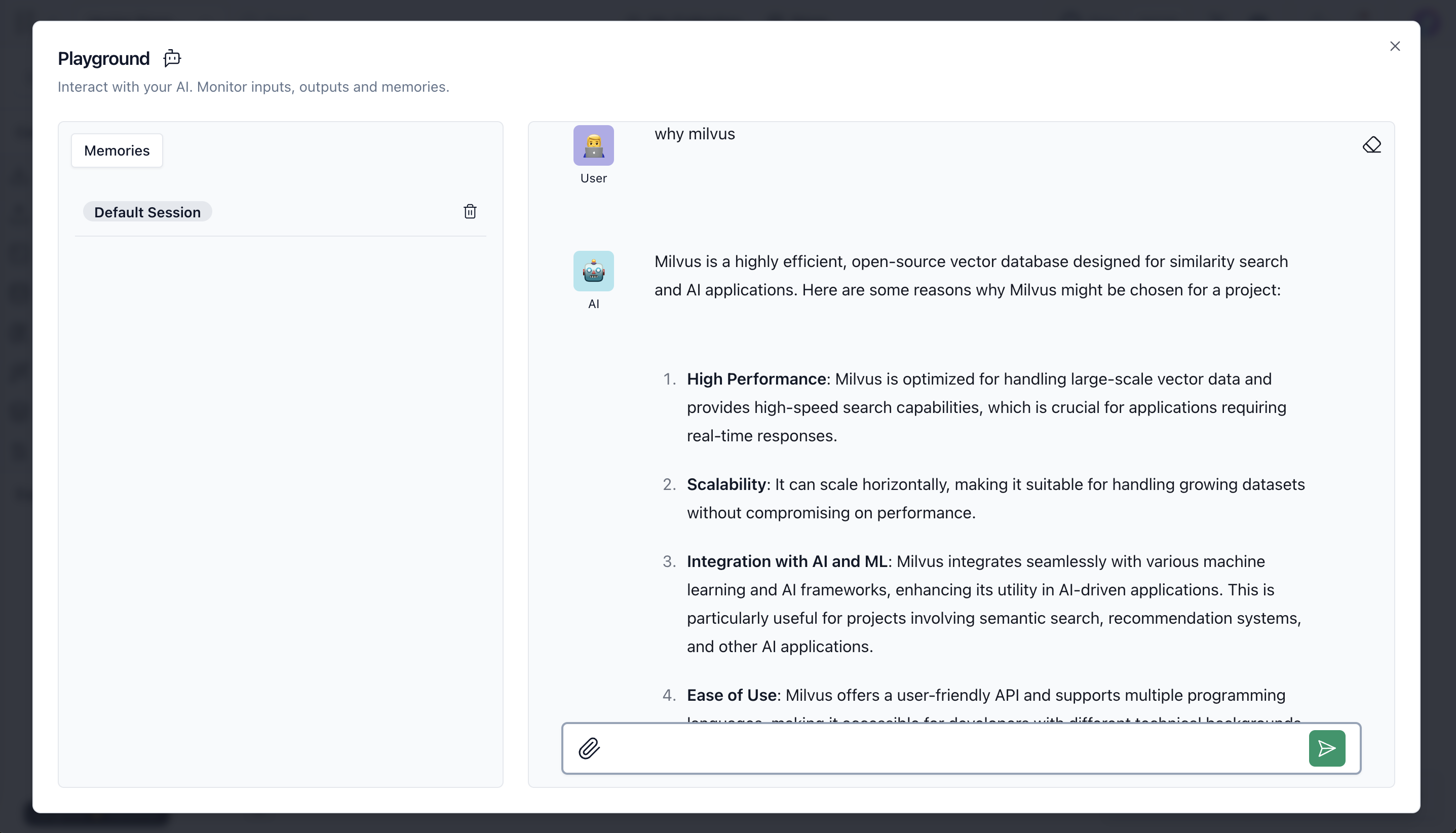 warum Milvus
warum Milvus