Integrieren Sie Milvus mit DSPy
![]()
Was ist DSPy?
DSPy wurde von der Stanford NLP Group entwickelt und ist ein bahnbrechendes programmatisches Framework zur Optimierung von Prompts und Gewichtungen innerhalb von Sprachmodellen. Es ist besonders wertvoll in Szenarien, in denen große Sprachmodelle (LLMs) über mehrere Stufen einer Pipeline integriert werden. Im Gegensatz zu herkömmlichen Prompting-Engineering-Techniken, die auf manuelle Bearbeitung und Optimierung angewiesen sind, verfolgt DSPy einen lernbasierten Ansatz. Durch die Aufnahme von Frage-Antwort-Beispielen erzeugt DSPy dynamisch optimierte Prompts, die auf spezifische Aufgaben zugeschnitten sind. Diese innovative Methodik ermöglicht den nahtlosen Zusammenbau ganzer Pipelines, wodurch die Notwendigkeit ständiger manueller Prompt-Anpassungen entfällt. Die Pythonic-Syntax von DSPy bietet verschiedene zusammensetzbare und deklarative Module, die die Anweisung von LLMs vereinfachen.
Vorteile der Verwendung von DSPy
- Programmieransatz: DSPy bietet einen systematischen Programmieransatz für die Entwicklung von LM-Pipelines, indem Pipelines als Texttransformationsgraphen abstrahiert werden, anstatt nur die LLMs zu instruieren. Seine deklarativen Module ermöglichen einen strukturierten Entwurf und eine Optimierung, die die Trial-and-Error-Methode der traditionellen Prompt-Templates ersetzt.
- Leistungsverbesserung: DSPy demonstriert signifikante Leistungssteigerungen gegenüber bestehenden Methoden. In Fallstudien übertrifft es Standard-Prompting und von Experten erstellte Demonstrationen und zeigt seine Vielseitigkeit und Effektivität, selbst wenn es zu kleineren LM-Modellen kompiliert wird.
- Modularisierte Abstraktion: DSPy abstrahiert effektiv die komplizierten Aspekte der LM-Pipeline-Entwicklung, wie z.B. die Dekomposition, die Feinabstimmung und die Modellauswahl. Mit DSPy kann ein prägnantes Programm nahtlos in Anweisungen für verschiedene Modelle, wie GPT-4, Llama2-13b oder T5-Basis, übersetzt werden, was die Entwicklung rationalisiert und die Leistung erhöht.
Module
Es gibt zahlreiche Komponenten, die zum Aufbau einer LLM-Pipeline beitragen. Im Folgenden werden einige Schlüsselkomponenten beschrieben, um ein grundlegendes Verständnis für die Funktionsweise von DSPy zu vermitteln.
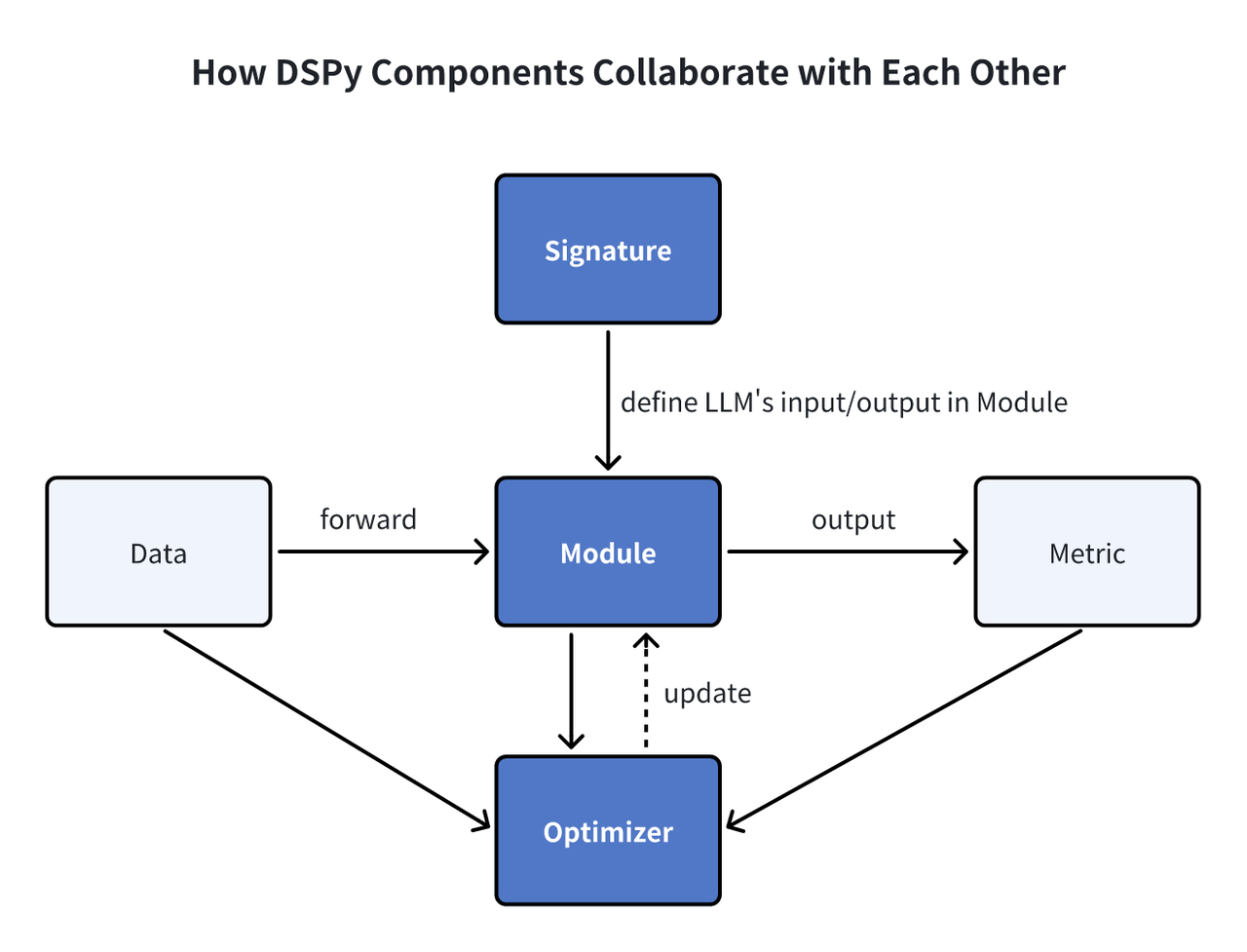 DSPy-Module
DSPy-Module
Unterschrift: Signaturen in DSPy dienen als deklarative Spezifikationen, die das Eingabe-/Ausgabeverhalten von Modulen umreißen und das Sprachmodell bei der Ausführung von Aufgaben leiten. Modul: DSPy-Module dienen als grundlegende Komponenten für Programme, die Sprachmodelle (LMs) nutzen. Sie abstrahieren verschiedene Prompting-Techniken, wie z.B. Chain of Thought oder ReAct, und sind anpassbar, um jede DSPy-Signatur zu behandeln. Mit lernfähigen Parametern und der Fähigkeit, Eingaben zu verarbeiten und Ausgaben zu erzeugen, können diese Module zu größeren Programmen kombiniert werden, wobei sie sich an den NN-Modulen in PyTorch orientieren, aber auf LM-Anwendungen zugeschnitten sind. Optimierer: Optimierer in DSPy nehmen eine Feinabstimmung der Parameter von DSPy-Programmen vor, wie z. B. Prompts und LLM-Gewichte, um bestimmte Metriken wie die Genauigkeit zu maximieren und die Effizienz des Programms zu verbessern.
Warum Milvus in DSPy
DSPy ist ein leistungsfähiger Programmierrahmen, der RAG-Anwendungen unterstützt. Eine solche Anwendung muss nützliche Informationen abrufen, um die Antwortqualität zu verbessern, wofür eine Vektordatenbank erforderlich ist. Milvus ist eine bekannte Open-Source-Vektordatenbank zur Verbesserung der Leistung und Skalierbarkeit. Mit MilvusRM, einem Retriever-Modul in DSPy, wird die Integration von Milvus nahtlos. Jetzt können Entwickler RAG-Programme mit DSPy einfach definieren und optimieren und dabei von den starken Vektorsuchfunktionen von Milvus profitieren. Diese Zusammenarbeit macht RAG-Anwendungen effizienter und skalierbarer, indem sie die Programmierfähigkeiten von DSPy mit den Suchfunktionen von Milvus kombiniert.
Beispiele
Lassen Sie uns nun ein kurzes Beispiel durchgehen, um zu demonstrieren, wie Milvus in DSPy zur Optimierung einer RAG-Anwendung eingesetzt werden kann.
Voraussetzungen
Bevor Sie die RAG-Anwendung erstellen, installieren Sie DSPy und PyMilvus.
$ pip install "dspy-ai[milvus]"
$ pip install -U pymilvus
Laden des Datensatzes
In diesem Beispiel verwenden wir HotPotQA, eine Sammlung von komplexen Frage-Antwort-Paaren, als Trainingsdatensatz. Wir können sie über die Klasse HotPotQA laden.
from dspy.datasets import HotPotQA
# Load the dataset.
dataset = HotPotQA(
train_seed=1, train_size=20, eval_seed=2023, dev_size=50, test_size=0
)
# Tell DSPy that the 'question' field is the input. Any other fields are labels and/or metadata.
trainset = [x.with_inputs("question") for x in dataset.train]
devset = [x.with_inputs("question") for x in dataset.dev]
Einlesen der Daten in die Milvus-Vektor-Datenbank
Geben Sie die Kontextinformationen in die Milvus-Sammlung für die Vektorabfrage ein. Diese Sammlung sollte ein embedding Feld und ein text Feld haben. Wir verwenden in diesem Fall das Modell text-embedding-3-small von OpenAI als Standardfunktion zur Einbettung von Abfragen.
import requests
import os
os.environ["OPENAI_API_KEY"] = "<YOUR_OPENAI_API_KEY>"
MILVUS_URI = "example.db"
MILVUS_TOKEN = ""
from pymilvus import MilvusClient, DataType, Collection
from dspy.retrieve.milvus_rm import openai_embedding_function
client = MilvusClient(uri=MILVUS_URI, token=MILVUS_TOKEN)
if "dspy_example" not in client.list_collections():
client.create_collection(
collection_name="dspy_example",
overwrite=True,
dimension=1536,
primary_field_name="id",
vector_field_name="embedding",
id_type="int",
metric_type="IP",
max_length=65535,
enable_dynamic=True,
)
text = requests.get(
"https://raw.githubusercontent.com/wxywb/dspy_dataset_sample/master/sample_data.txt"
).text
for idx, passage in enumerate(text.split("\n")):
if len(passage) == 0:
continue
client.insert(
collection_name="dspy_example",
data=[
{
"id": idx,
"embedding": openai_embedding_function(passage)[0],
"text": passage,
}
],
)
Definieren Sie MilvusRM.
Nun müssen Sie den MilvusRM definieren.
from dspy.retrieve.milvus_rm import MilvusRM
import dspy
retriever_model = MilvusRM(
collection_name="dspy_example",
uri=MILVUS_URI,
token=MILVUS_TOKEN, # ignore this if no token is required for Milvus connection
embedding_function=openai_embedding_function,
)
turbo = dspy.OpenAI(model="gpt-3.5-turbo")
dspy.settings.configure(lm=turbo)
Signaturen erstellen
Nachdem wir nun die Daten geladen haben, können wir mit der Definition der Signaturen für die Teilaufgaben unserer Pipeline beginnen. Wir können unsere einfache Eingabe question und Ausgabe answer identifizieren, aber da wir eine RAG-Pipeline aufbauen, werden wir kontextbezogene Informationen von Milvus abrufen. Definieren wir also unsere Signatur als context, question --> answer.
class GenerateAnswer(dspy.Signature):
"""Answer questions with short factoid answers."""
context = dspy.InputField(desc="may contain relevant facts")
question = dspy.InputField()
answer = dspy.OutputField(desc="often between 1 and 5 words")
Wir fügen kurze Beschreibungen für die Felder context und answer ein, um klarere Richtlinien dafür zu definieren, was das Modell empfangen und erzeugen soll.
Aufbau der Pipeline
Lassen Sie uns nun die RAG-Pipeline definieren.
class RAG(dspy.Module):
def __init__(self, rm):
super().__init__()
self.retrieve = rm
# This signature indicates the task imposed on the COT module.
self.generate_answer = dspy.ChainOfThought(GenerateAnswer)
def forward(self, question):
# Use milvus_rm to retrieve context for the question.
context = self.retrieve(question).passages
# COT module takes "context, query" and output "answer".
prediction = self.generate_answer(context=context, question=question)
return dspy.Prediction(
context=[item.long_text for item in context], answer=prediction.answer
)
Ausführen der Pipeline und Abrufen der Ergebnisse
Jetzt haben wir diese RAG-Pipeline erstellt. Probieren wir sie aus und holen uns die Ergebnisse.
rag = RAG(retriever_model)
print(rag("who write At My Window").answer)
Townes Van Zandt
Wir können die quantitativen Ergebnisse anhand des Datensatzes auswerten.
from dspy.evaluate.evaluate import Evaluate
from dspy.datasets import HotPotQA
evaluate_on_hotpotqa = Evaluate(
devset=devset, num_threads=1, display_progress=False, display_table=5
)
metric = dspy.evaluate.answer_exact_match
score = evaluate_on_hotpotqa(rag, metric=metric)
print("rag:", score)
Optimieren der Pipeline
Nach der Definition dieses Programms ist der nächste Schritt die Kompilierung. Bei diesem Prozess werden die Parameter in jedem Modul aktualisiert, um die Leistung zu verbessern. Der Kompilierungsprozess hängt von drei entscheidenden Faktoren ab:
- Trainingsmenge: Für diese Demonstration werden wir die 20 Frage-Antwort-Beispiele aus unserem Trainingsdatensatz verwenden.
- Validierungsmetrik: Wir werden eine einfache
validate_context_and_answerMetrik erstellen. Diese Metrik prüft die Genauigkeit der vorhergesagten Antwort und stellt sicher, dass der gefundene Kontext die Antwort enthält. - Spezifischer Optimierer (Teleprompter): Der Compiler von DSPy enthält mehrere Teleprompter, die dazu dienen, Ihre Programme effektiv zu optimieren.
from dspy.teleprompt import BootstrapFewShot
# Validation logic: check that the predicted answer is correct.# Also check that the retrieved context does contain that answer.
def validate_context_and_answer(example, pred, trace=None):
answer_EM = dspy.evaluate.answer_exact_match(example, pred)
answer_PM = dspy.evaluate.answer_passage_match(example, pred)
return answer_EM and answer_PM
# Set up a basic teleprompter, which will compile our RAG program.
teleprompter = BootstrapFewShot(metric=validate_context_and_answer)
# Compile!
compiled_rag = teleprompter.compile(rag, trainset=trainset)
# Now compiled_rag is optimized and ready to answer your new question!
# Now, let’s evaluate the compiled RAG program.
score = evaluate_on_hotpotqa(compiled_rag, metric=metric)
print(score)
print("compile_rag:", score)
Der Ragas-Score ist von seinem vorherigen Wert von 50,0 auf 52,0 gestiegen, was auf eine Verbesserung der Antwortqualität hinweist.
Zusammenfassung
DSPy stellt durch seine programmierbare Schnittstelle, die eine algorithmische und automatische Optimierung von Modellaufforderungen und -gewichtungen ermöglicht, einen Sprung in der Interaktion mit Sprachmodellen dar. Durch den Einsatz von DSPy für die RAG-Implementierung wird die Anpassung an unterschiedliche Sprachmodelle oder Datensätze zum Kinderspiel, was den Bedarf an mühsamen manuellen Eingriffen drastisch reduziert.