مطابقة النص
تتيح مطابقة النص في ميلفوس استرجاع المستندات بدقة بناءً على مصطلحات محددة. تُستخدم هذه الميزة في المقام الأول للبحث المصفى لتلبية شروط محددة ويمكنها دمج التصفية القياسية لتحسين نتائج الاستعلام، مما يسمح بالبحث عن التشابه داخل المتجهات التي تستوفي المعايير القياسية.
تركز المطابقة النصية على العثور على التكرارات الدقيقة لمصطلحات الاستعلام، دون تسجيل مدى ملاءمة المستندات المتطابقة. إذا كنت ترغب في استرداد المستندات الأكثر صلة بناءً على المعنى الدلالي وأهمية مصطلحات الاستعلام، نوصيك باستخدام البحث في النص الكامل.
نظرة عامة
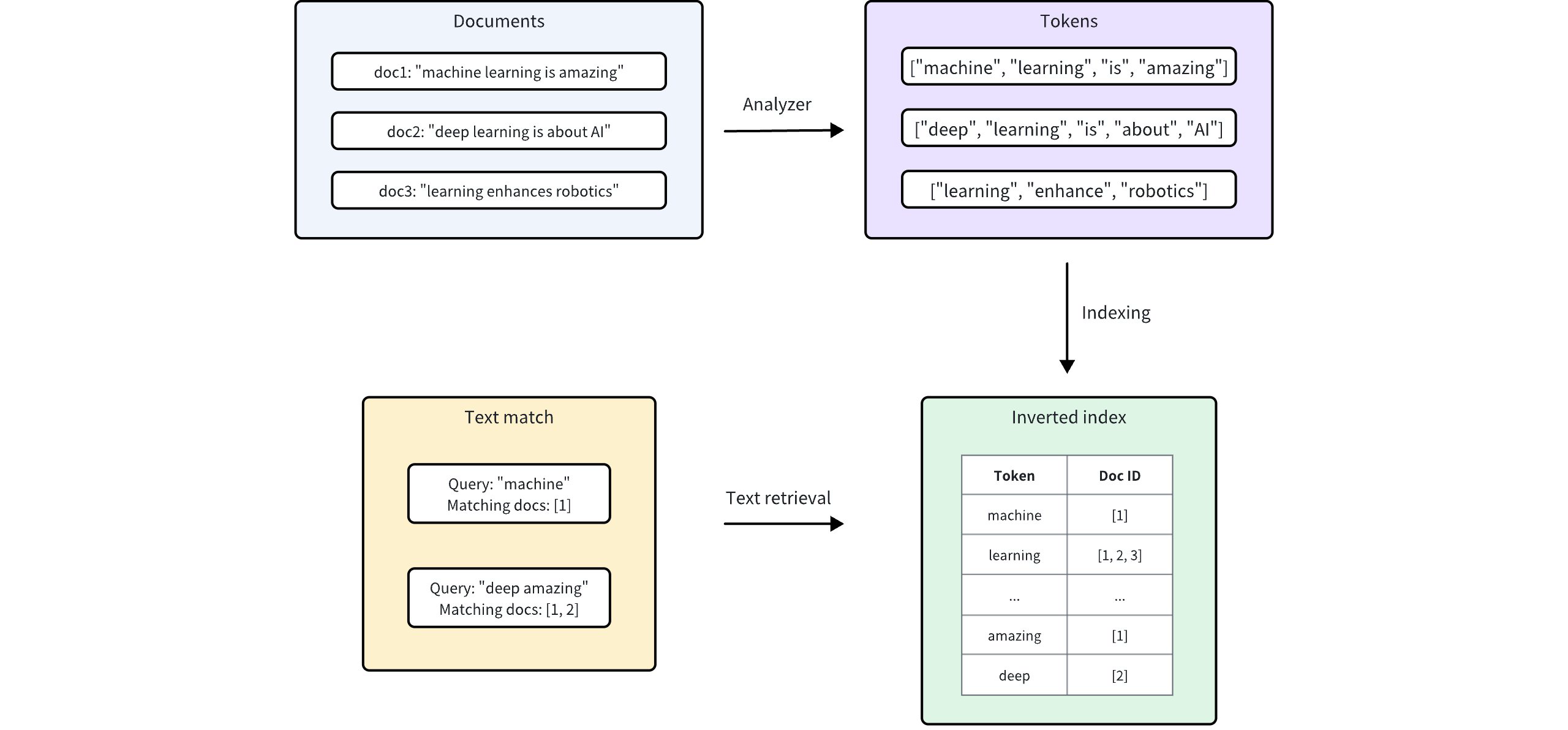
يدمج ميلفوس برنامج Tantivy لتشغيل فهرسه المقلوب الأساسي والبحث النصي القائم على المصطلحات. لكل إدخال نصي، يقوم ميلفوس بفهرسته باتباع الإجراء:
المحلّل: يقوم المحلل بمعالجة النص المدخل عن طريق ترميزه إلى كلمات فردية أو رموز، ثم تطبيق المرشحات حسب الحاجة. وهذا يسمح لميلفوس ببناء فهرس بناءً على هذه الرموز.
الفهرسة: بعد تحليل النص، ينشئ Milvus فهرسًا مقلوبًا يقوم بتعيين كل رمز مميز إلى المستندات التي تحتوي عليه.
عندما يقوم المستخدم بإجراء مطابقة نصية، يتم استخدام الفهرس المقلوب لاسترداد جميع المستندات التي تحتوي على المصطلحات بسرعة. وهذا أسرع بكثير من المسح الضوئي لكل مستند على حدة.
 مطابقة الكلمات الرئيسية
مطابقة الكلمات الرئيسية
تمكين المطابقة النصية
تعمل المطابقة النصية على VARCHAR نوع الحقل، وهو في الأساس نوع بيانات السلسلة في ملفوس. لتمكين مطابقة النص، قم بتعيين كل من enable_analyzer و enable_match على True ثم قم اختياريًا بتكوين محلل لتحليل النص عند تحديد مخطط المجموعة الخاص بك.
قم بتعيين enable_analyzer و enable_match
لتمكين مطابقة النص لحقل معين VARCHAR ، قم بتعيين كل من المعلمات enable_analyzer و enable_match إلى True عند تحديد مخطط الحقل. هذا يوجه Milvus إلى ترميز النص وإنشاء فهرس مقلوب للحقل المحدد، مما يسمح بمطابقة نصية سريعة وفعالة.
from pymilvus import MilvusClient, DataType
schema = MilvusClient.create_schema(enable_dynamic_field=False)
schema.add_field(
field_name="id",
datatype=DataType.INT64,
is_primary=True,
auto_id=True
)
schema.add_field(
field_name='text',
datatype=DataType.VARCHAR,
max_length=1000,
enable_analyzer=True, # Whether to enable text analysis for this field
enable_match=True # Whether to enable text match
)
schema.add_field(
field_name="embeddings",
datatype=DataType.FLOAT_VECTOR,
dim=5
)
import io.milvus.v2.common.DataType;
import io.milvus.v2.service.collection.request.AddFieldReq;
import io.milvus.v2.service.collection.request.CreateCollectionReq;
CreateCollectionReq.CollectionSchema schema = CreateCollectionReq.CollectionSchema.builder()
.enableDynamicField(false)
.build();
schema.addField(AddFieldReq.builder()
.fieldName("id")
.dataType(DataType.Int64)
.isPrimaryKey(true)
.autoID(true)
.build());
schema.addField(AddFieldReq.builder()
.fieldName("text")
.dataType(DataType.VarChar)
.maxLength(1000)
.enableAnalyzer(true)
.enableMatch(true)
.build());
schema.addField(AddFieldReq.builder()
.fieldName("embeddings")
.dataType(DataType.FloatVector)
.dimension(5)
.build());
import "github.com/milvus-io/milvus/client/v2/entity"
schema := entity.NewSchema().WithDynamicFieldEnabled(false)
schema.WithField(entity.NewField().
WithName("id").
WithDataType(entity.FieldTypeInt64).
WithIsPrimaryKey(true).
WithIsAutoID(true),
).WithField(entity.NewField().
WithName("text").
WithDataType(entity.FieldTypeVarChar).
WithEnableAnalyzer(true).
WithEnableMatch(true).
WithMaxLength(1000),
).WithField(entity.NewField().
WithName("embeddings").
WithDataType(entity.FieldTypeFloatVector).
WithDim(5),
)
const schema = [
{
name: "id",
data_type: DataType.Int64,
is_primary_key: true,
},
{
name: "text",
data_type: "VarChar",
enable_analyzer: true,
enable_match: true,
max_length: 1000,
},
{
name: "embeddings",
data_type: DataType.FloatVector,
dim: 5,
},
];
export schema='{
"autoId": true,
"enabledDynamicField": false,
"fields": [
{
"fieldName": "id",
"dataType": "Int64",
"isPrimary": true
},
{
"fieldName": "text",
"dataType": "VarChar",
"elementTypeParams": {
"max_length": 1000,
"enable_analyzer": true,
"enable_match": true
}
},
{
"fieldName": "embeddings",
"dataType": "FloatVector",
"elementTypeParams": {
"dim": "5"
}
}
]
}'
اختياري: تكوين محلل
يعتمد أداء ودقة مطابقة الكلمات المفتاحية على المحلل المحدد. المحللات المختلفة مصممة خصيصًا لمختلف اللغات والتراكيب النصية، لذا فإن اختيار المحلل المناسب يمكن أن يؤثر بشكل كبير على نتائج البحث لحالة الاستخدام الخاصة بك.
بشكل افتراضي، يستخدم Milvus محلل standard ، الذي يقوم بترميز النص استنادًا إلى المسافات البيضاء وعلامات الترقيم، ويزيل الرموز التي يزيد طولها عن 40 حرفًا، ويحول النص إلى أحرف صغيرة. لا حاجة إلى معلمات إضافية لتطبيق هذا الإعداد الافتراضي. لمزيد من المعلومات، راجع Standard.
في الحالات التي تتطلب محللًا مختلفًا، يمكنك تكوين محلل مختلف باستخدام المعلمة analyzer_params. على سبيل المثال، لتطبيق محلل english لمعالجة النص الإنجليزي:
analyzer_params = {
"type": "english"
}
schema.add_field(
field_name='text',
datatype=DataType.VARCHAR,
max_length=200,
enable_analyzer=True,
analyzer_params = analyzer_params,
enable_match = True,
)
Map<String, Object> analyzerParams = new HashMap<>();
analyzerParams.put("type", "english");
schema.addField(AddFieldReq.builder()
.fieldName("text")
.dataType(DataType.VarChar)
.maxLength(200)
.enableAnalyzer(true)
.analyzerParams(analyzerParams)
.enableMatch(true)
.build());
analyzerParams := map[string]any{"type": "english"}
schema.WithField(entity.NewField().
WithName("text").
WithDataType(entity.FieldTypeVarChar).
WithEnableAnalyzer(true).
WithEnableMatch(true).
WithAnalyzerParams(analyzerParams).
WithMaxLength(200),
)
const schema = [
{
name: "id",
data_type: DataType.Int64,
is_primary_key: true,
},
{
name: "text",
data_type: "VarChar",
enable_analyzer: true,
enable_match: true,
max_length: 1000,
analyzer_params: { type: 'english' },
},
{
name: "embeddings",
data_type: DataType.FloatVector,
dim: 5,
},
];
export schema='{
"autoId": true,
"enabledDynamicField": false,
"fields": [
{
"fieldName": "id",
"dataType": "Int64",
"isPrimary": true
},
{
"fieldName": "text",
"dataType": "VarChar",
"elementTypeParams": {
"max_length": 200,
"enable_analyzer": true,
"enable_match": true,
"analyzer_params": {"type": "english"}
}
},
{
"fieldName": "embeddings",
"dataType": "FloatVector",
"elementTypeParams": {
"dim": "5"
}
}
]
}'
يوفر ميلفوس أيضًا العديد من المحللين الآخرين المناسبين للغات والسيناريوهات المختلفة. لمزيد من التفاصيل، راجع نظرة عامة على المحلل.
استخدام مطابقة النص
بمجرد تمكين مطابقة النص لحقل VARCHAR في مخطط مجموعتك، يمكنك إجراء مطابقات نصية باستخدام التعبير TEXT_MATCH.
بناء جملة تعبير TEXT_MATCH
يُستخدم التعبير TEXT_MATCH لتحديد الحقل والمصطلحات المراد البحث عنها. وتكون صيغته على النحو التالي:
TEXT_MATCH(field_name, text)
field_name: اسم حقل VARCHAR المطلوب البحث عنه.text: المصطلحات المطلوب البحث عنها. يمكن الفصل بين المصطلحات المتعددة بمسافات أو محددات أخرى مناسبة بناءً على اللغة والمحلل المهيأ.
بشكل افتراضي، يستخدم TEXT_MATCH منطق المطابقة OR، مما يعني أنه سيعيد المستندات التي تحتوي على أي من المصطلحات المحددة. على سبيل المثال، للبحث عن المستندات التي تحتوي على المصطلح machine أو deep في الحقل text ، استخدم التعبير التالي:
filter = "TEXT_MATCH(text, 'machine deep')"
String filter = "TEXT_MATCH(text, 'machine deep')";
filter := "TEXT_MATCH(text, 'machine deep')"
const filter = "TEXT_MATCH(text, 'machine deep')";
export filter="\"TEXT_MATCH(text, 'machine deep')\""
يمكنك أيضًا دمج عدة تعبيرات TEXT_MATCH باستخدام عوامل تشغيل منطقية لإجراء المطابقة AND.
للبحث عن المستندات التي تحتوي على كل من
machineوdeepفي الحقلtext، استخدم التعبير التالي:filter = "TEXT_MATCH(text, 'machine') and TEXT_MATCH(text, 'deep')"String filter = "TEXT_MATCH(text, 'machine') and TEXT_MATCH(text, 'deep')";filter := "TEXT_MATCH(text, 'machine') and TEXT_MATCH(text, 'deep')"const filter = "TEXT_MATCH(text, 'machine') and TEXT_MATCH(text, 'deep')"export filter="\"TEXT_MATCH(text, 'machine') and TEXT_MATCH(text, 'deep')\""للبحث عن المستندات التي تحتوي على كل من
machineوlearningولكن بدونdeepفي الحقلtext، استخدم التعبيرات التالية:filter = "not TEXT_MATCH(text, 'deep') and TEXT_MATCH(text, 'machine') and TEXT_MATCH(text, 'learning')"String filter = "not TEXT_MATCH(text, 'deep') and TEXT_MATCH(text, 'machine') and TEXT_MATCH(text, 'learning')";filter := "not TEXT_MATCH(text, 'deep') and TEXT_MATCH(text, 'machine') and TEXT_MATCH(text, 'learning')"const filter = "not TEXT_MATCH(text, 'deep') and TEXT_MATCH(text, 'machine') and TEXT_MATCH(text, 'learning')";export filter="\"not TEXT_MATCH(text, 'deep') and TEXT_MATCH(text, 'machine') and TEXT_MATCH(text, 'learning')\""
البحث بمطابقة النص
يمكن استخدام مطابقة النص مع البحث بالتشابه المتجه لتضييق نطاق البحث وتحسين أداء البحث. من خلال تصفية المجموعة باستخدام مطابقة النص قبل البحث عن التشابه المتجه، يمكنك تقليل عدد المستندات التي تحتاج إلى البحث، مما يؤدي إلى تسريع أوقات الاستعلام.
في هذا المثال، يقوم التعبير filter بتصفية نتائج البحث لتضمين المستندات التي تطابق المصطلح المحدد فقط keyword1 أو keyword2. ثم يتم إجراء بحث التشابه المتجه على هذه المجموعة الفرعية المصفاة من المستندات.
يمكنك تمييز المصطلحات المتطابقة في نتائج البحث عن طريق تكوين أداة تمييز النص. راجع أداة تمييز النص للحصول على التفاصيل.
# Match entities with `keyword1` or `keyword2`
filter = "TEXT_MATCH(text, 'keyword1 keyword2')"
# Assuming 'embeddings' is the vector field and 'text' is the VARCHAR field
result = client.search(
collection_name="my_collection", # Your collection name
anns_field="embeddings", # Vector field name
data=[query_vector], # Query vector
filter=filter,
search_params={"params": {"nprobe": 10}},
limit=10, # Max. number of results to return
output_fields=["id", "text"] # Fields to return
)
String filter = "TEXT_MATCH(text, 'keyword1 keyword2')";
SearchResp searchResp = client.search(SearchReq.builder()
.collectionName("my_collection")
.annsField("embeddings")
.data(Collections.singletonList(queryVector)))
.filter(filter)
.topK(10)
.outputFields(Arrays.asList("id", "text"))
.build());
filter := "TEXT_MATCH(text, 'keyword1 keyword2')"
resultSets, err := client.Search(ctx, milvusclient.NewSearchOption(
"my_collection", // collectionName
10, // limit
[]entity.Vector{entity.FloatVector(queryVector)},
).WithANNSField("embeddings").
WithFilter(filter).
WithOutputFields("id", "text"))
if err != nil {
fmt.Println(err.Error())
// handle error
}
// Match entities with `keyword1` or `keyword2`
const filter = "TEXT_MATCH(text, 'keyword1 keyword2')";
// Assuming 'embeddings' is the vector field and 'text' is the VARCHAR field
const result = await client.search(
collection_name: "my_collection", // Your collection name
anns_field: "embeddings", // Vector field name
data: [query_vector], // Query vector
filter: filter,
params: {"nprobe": 10},
limit: 10, // Max. number of results to return
output_fields: ["id", "text"] //Fields to return
);
export filter="\"TEXT_MATCH(text, 'keyword1 keyword2')\""
export CLUSTER_ENDPOINT="http://localhost:19530"
export TOKEN="root:Milvus"
curl --request POST \
--url "${CLUSTER_ENDPOINT}/v2/vectordb/entities/search" \
--header "Authorization: Bearer ${TOKEN}" \
--header "Content-Type: application/json" \
--header "Request-Timeout: 10" \
-d '{
"collectionName": "my_collection",
"annsField": "embeddings",
"data": [[0.19886812562848388, 0.06023560599112088, 0.6976963061752597, 0.2614474506242501, 0.838729485096104]],
"filter": '"$filter"',
"searchParams": {
"params": {
"nprobe": 10
}
},
"limit": 10,
"outputFields": ["text","id"]
}'
الاستعلام مع مطابقة النص
يمكن أيضًا استخدام مطابقة النص للتصفية العددية في عمليات الاستعلام. من خلال تحديد تعبير TEXT_MATCH في المعلمة expr للطريقة query() ، يمكنك استرداد المستندات التي تطابق المصطلحات المحددة.
يسترجع المثال أدناه المستندات التي يحتوي فيها الحقل text على المصطلحين keyword1 و keyword2.
# Match entities with both `keyword1` and `keyword2`
filter = "TEXT_MATCH(text, 'keyword1') and TEXT_MATCH(text, 'keyword2')"
result = client.query(
collection_name="my_collection",
filter=filter,
output_fields=["id", "text"]
)
String filter = "TEXT_MATCH(text, 'keyword1') and TEXT_MATCH(text, 'keyword2')";
QueryResp queryResp = client.query(QueryReq.builder()
.collectionName("my_collection")
.filter(filter)
.outputFields(Arrays.asList("id", "text"))
.build()
);
filter = "TEXT_MATCH(text, 'keyword1') and TEXT_MATCH(text, 'keyword2')"
resultSet, err := client.Query(ctx, milvusclient.NewQueryOption("my_collection").
WithFilter(filter).
WithOutputFields("id", "text"))
if err != nil {
fmt.Println(err.Error())
// handle error
}
// Match entities with both `keyword1` and `keyword2`
const filter = "TEXT_MATCH(text, 'keyword1') and TEXT_MATCH(text, 'keyword2')";
const result = await client.query(
collection_name: "my_collection",
filter: filter,
output_fields: ["id", "text"]
)
export filter="\"TEXT_MATCH(text, 'keyword1') and TEXT_MATCH(text, 'keyword2')\""
export CLUSTER_ENDPOINT="http://localhost:19530"
export TOKEN="root:Milvus"
curl --request POST \
--url "${CLUSTER_ENDPOINT}/v2/vectordb/entities/query" \
--header "Authorization: Bearer ${TOKEN}" \
--header "Content-Type: application/json" \
--header "Request-Timeout: 10" \
-d '{
"collectionName": "my_collection",
"filter": '"$filter"',
"outputFields": ["id", "text"]
}'
الاعتبارات
يؤدي تمكين مطابقة المصطلحات لحقل ما إلى إنشاء فهرس مقلوب، مما يستهلك موارد التخزين. ضع في اعتبارك تأثير التخزين عند اتخاذ قرار تمكين هذه الميزة، حيث يختلف بناءً على حجم النص والرموز الفريدة والمحلل المستخدم.
بمجرد تحديد محلل في المخطط الخاص بك، تصبح إعداداته دائمة لتلك المجموعة. إذا قررت أن محللًا مختلفًا يناسب احتياجاتك بشكل أفضل، يمكنك التفكير في إسقاط المجموعة الحالية وإنشاء مجموعة جديدة بتكوين المحلل المطلوب.
قواعد الهروب في تعبيرات
filter:يتم تفسير الأحرف المحاطة بعلامات اقتباس مزدوجة أو علامات اقتباس مفردة داخل التعبيرات على أنها ثوابت سلسلة. إذا كان ثابت السلسلة يتضمن أحرف هروب، فيجب تمثيل أحرف الهروب بتسلسل الهروب. على سبيل المثال، استخدم
\\لتمثيل\و\\tلتمثيل علامة تبويب\tو\\nلتمثيل سطر جديد.إذا كان ثابت السلسلة محاطًا بعلامات اقتباس مفردة، يجب تمثيل علامة اقتباس مفردة داخل الثابت على أنه
\\'بينما يمكن تمثيل علامة الاقتباس المزدوجة إما"أو\\". مثال:'It\\'s milvus'.إذا كان ثابت السلسلة محاطًا بعلامات اقتباس مزدوجة، يجب تمثيل علامة اقتباس مزدوجة داخل الثابت على أنه
\\"بينما يمكن تمثيل علامة الاقتباس المفردة إما'أو\\'. مثال:"He said \\"Hi\\"".