Introducing Milvus 2.5: Full-Text Search, More Powerful Metadata Filtering, and Usability Improvements!
Overview
We are thrilled to present the latest version of Milvus, 2.5, which introduces a powerful new capability: full-text search, also known as lexical or keyword search. If you are new to search, full-text search allows you to find documents by searching for specific words or phrases within them, similar to how you search in Google. This complements our existing semantic search capabilities, which understand the meaning behind your search rather than just matching exact words.
We use the industry-standard BM25 metric for document similarity, and our implemention is based on sparse vectors, allowing for more efficient storage and retrieval. For those unfamiliar with the term, sparse vectors are a way to represent text where most values are zero, making them very efficient to store and process—imagine a huge spreadsheet where only a few cells contain numbers, and the rest are empty. This approach fits well into Milvus’s product philosophy where the vector is the core search entity.
An additional noteworthy aspect of our implementation is the capability to insert and query text directly rather than having users first manually convert text into sparse vectors. This takes Milvus one step closer towards fully processing unstructured data.
But this is just the beginning. With the release of 2.5, we updated the Milvus product roadmap. In future product iterations of Milvus, our focus will be on evolving Milvus’s capabilities in four key directions:
- Streamlined unstructured data processing;
- Better search quality and efficiency;
- Easier data management;
- Lowering costs through algorithmic and design advances
Our aim is to build data infrastructure that can both efficiently store and effectively retrieve information in the AI era.
Full-text Search via Sparse-BM25
Although semantic search typically has better contexual awareness and intent understanding, when a user needs to search for specific proper nouns, serial numbers, or a completely-matching phrase, full-text retrieval with keyword matching often produces more accurate results.
To illustrate this with an example:
- Semantic search excels when you ask: “Find documents about renewable energy solutions”
- Full-text search is better when you need: "Find documents mentioning Tesla Model 3 2024"
In our previous version (Milvus 2.4), users had to pre-process their text using a separate tool (the BM25EmbeddingFunction module to the PyMilvus) on their own machines before they could search it This approach had several limitations: it couldn’t handle growing datasets well, required extra setup steps, and made the whole process more complicated than necessary. For the technically minded, the key limitations were that it could only work on a single machine; the vocabulary and other corpus statistics used for BM25 scoring couldn’t be updated as the corpus changed; and converting text to vectors on the client side is less intuitive working withtext directly.
Milvus 2.5 simplifies everything. Now you can work with your text directly:
- Store your original text documents as they are
- Search using natural language queries
- Get results back in readable form
Behind the scenes, Milvus handles all the complex vector conversions automatically making it easier to work with text data. This is what we call our “Doc in, Doc out” approach—you work with readable text, and we handle the rest.
Techical Implementation
For those interested in the technical details, Milvus 2.5 adds the full-text search capability through its built-in Sparse-BM25 implementation, including:
- A Tokenizer built on tantivy: Milvus now integrates with the thriving tantivy ecosystem
- Capability to ingest and retrieve raw documents: Support for direct ingestion and query of text data
- BM25 relevance scoring: Internalize BM25 scoring, implemented based on sparse vector
We chose to work with the well-developed tantivy ecosystem and build the Milvus text tokenizer on tantivy. In the future, Milvus will support more tokenizers and expose the tokenization process to help users better understand the retrieval quality. We will also explore deep learning-based tokenizers and stemmer strategies to further optimize the performance of full-text search. Below is sample code for using and configuring the tokenizer:
# Tokenizer configuration
schema.add_field(
field_name='text',
datatype=DataType.VARCHAR,
max_length=65535,
enable_analyzer=True, # Enable tokenizer on this column
analyzer_params={"type": "english"}, # Configure tokenizer parameters, here we choose the english template, fine-grained configuration is also supported
enable_match=True, # Build an inverted index for Text_Match
)
After configuring the tokenizer in the collection schema, users can register the text to bm25 function via add_function method. This will run internally in the Milvus server. All subsequent data flows such as additions, deletions, modifications, and queries can be completed by operating on the raw text string, as opposed to the vector representation. See below code example for how to ingest text and conduct full-text search with the new API:
# Define the mapping relationship between raw text data and vectors on the schema
bm25_function = Function(
name="text_bm25_emb",
input_field_names=["text"], # Input text field
output_field_names=["sparse"], # Internal mapping sparse vector field
function_type=FunctionType.BM25, # Model for processing mapping relationship
)
schema.add_function(bm25_function)
...
# Support for raw text in/out
MilvusClient.insert('demo', [
{'text': 'Artificial intelligence was founded as an academic discipline in 1956.'},
{'text': 'Alan Turing was the first person to conduct substantial research in AI.'},
{'text': 'Born in Maida Vale, London, Turing was raised in southern England.'},
])
MilvusClient.search(
collection_name='demo',
data=['Who started AI research?'],
anns_field='sparse',
limit=3
)
We have adopted an implementation of BM25 relevance scoring that represents queries and documents as sparse vectors, called Sparse-BM25. This unlocks many optimizations based on sparse vector, such as:
Milvus achieves hybrid search capabilities through its cutting-edge Sparse-BM25 implementation, which integrates full-text search into the vector database architecture. By representing term frequencies as sparse vectors instead of traditional inverted indexes, Sparse-BM25 enables advanced optimizations, such as graph indexing, product quantization (PQ), and scalar quantization (SQ). These optimizations minimize memory usage and accelerate search performance. Similar to inverted index approach, Milvus supports taking raw text as input and generating sparse vectors internally. This make it able to work with any tokenizer and grasp any word shown in the dynamicly changing corpus.
Additionally, heuristic-based pruning discards low-value sparse vectors, further enhancing efficiency without compromising accuracy. Unlike previous approach using sparse vector, it can adapt to a growing corpus, not the accuracy of BM25 scoring.
- Building graph indexes on the sparse vector, which performs better than inverted index on queries with long text as inverted index needs more steps to finish matching the tokens in the query;
- Leveraging approximation techniques to speed up search with only minor impact on retrieval quality, such as vector quantization and heuristic based pruning;
- Unifying the interface and data model for performing semantic search and full-text search, thus enhancing the user experience.
# Creating an index on the sparse column
index_params.add_index(
field_name="sparse",
index_type="AUTOINDEX", # Default WAND index
metric_type="BM25" # Configure relevance scoring through metric_type
)
# Configurable parameters at search time to speed up search
search_params = {
'params': {'drop_ratio_search': 0.6}, # WAND search parameter configuration can speed up search
}
In summary, Milvus 2.5 has expanded its search capability beyond semantic search by introducing full-text retrieval, making it easier for users to build high quality AI applications. These are just initial steps in the space of Sparse-BM25 search and we anticipate that there will be further optimization measures to try in the future.
Text Matching Search Filters
A second text search feature released with Milvus 2.5 is Text Match, which allows the user to filter the search to entries containing a specific text string. This feature is also built on the basis of tokenization and is activated with enable_match=True.
It is worth noting that with Text Match, the processing of the query text is based on the logic of OR after tokenization. For example, in the example below, the result will return all documents (using the ‘text’ field) that contain either ‘vector’ or 'database’.
filter = "TEXT_MATCH(text, 'vector database')"
If your scenario requires matching both ‘vector’ and 'database’, then you need to write two separate Text Matches and overlay them with AND to achieve your goal.
filter = "TEXT_MATCH(text, 'vector') and TEXT_MATCH(text, 'database')"
Significant Enhancement in Scalar Filtering Performance
Our emphasis on scalar filtering performance originates from our discovery that the combination of vector retrieval and metadata filtering can greatly improve query performance and accuracy in various scenarios. These scenarios range from image search applications such as corner case identification in autonomous driving to complex RAG scenarios in enterprise knowledge bases. Thus, it is highly suitable for enterprise users to implement in large-scale data application scenarios.
In practice, many factors like how much data you’re filtering, how your data is organized, and how you’re searching can affect performance. To address this, Milvus 2.5 introduces three new types of indexes—BitMap Index, Array Inverted Index, and the Inverted Index after tokenizing the Varchar text field. These new indexes can significantly improve performance in real-world use cases.
Specifically:
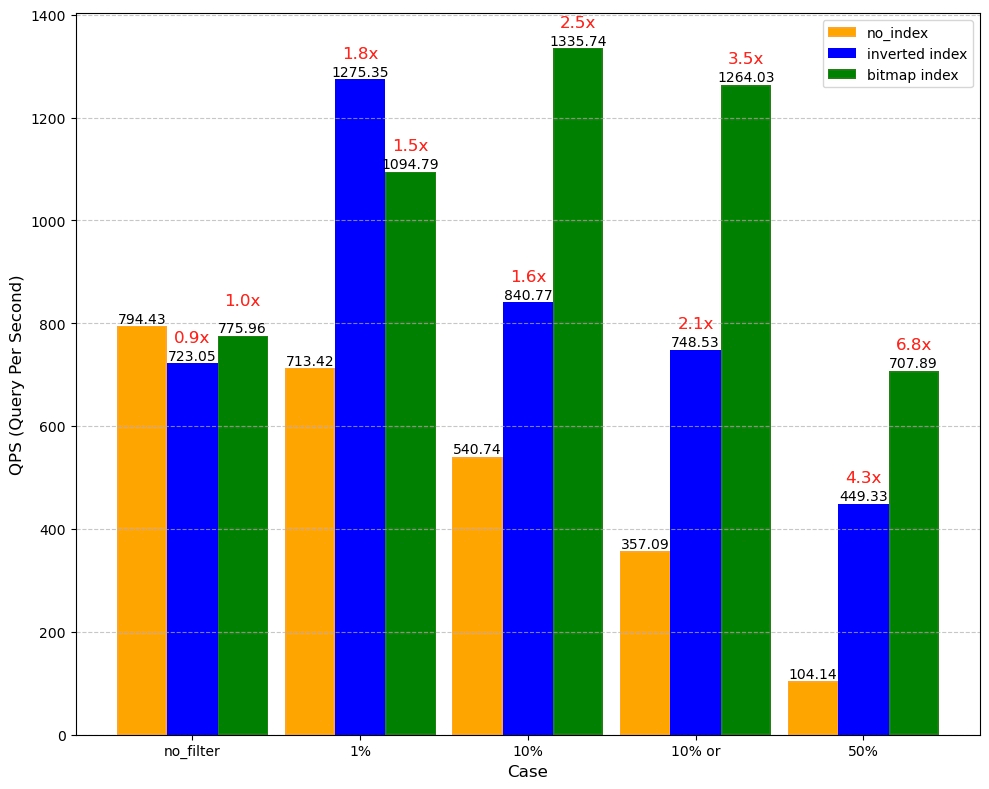
- BitMap Index can be used to accelerate tag filtering (common operators include in, array_contains, etc.), and is suitable for scenarios with fewer field category data (data cardinality). The principle is to determine whether a row of data has a certain value on a column, with 1 for yes and 0 for no, and then maintain a BitMap list. The following chart shows the performance test comparison we conducted based on a customer’s business scenario. In this scenario, the data volume is 500 million, the data category is 20, different values have different distribution proportions (1%, 5%, 10%, 50%), and the performance under different filtering amounts also varies. With 50% filtering, we can achieve a 6.8-fold performance gain through BitMap Index. It’s worth noting that as cardinality increases, compared to BitMap Index, Inverted Index will show more balanced performance.
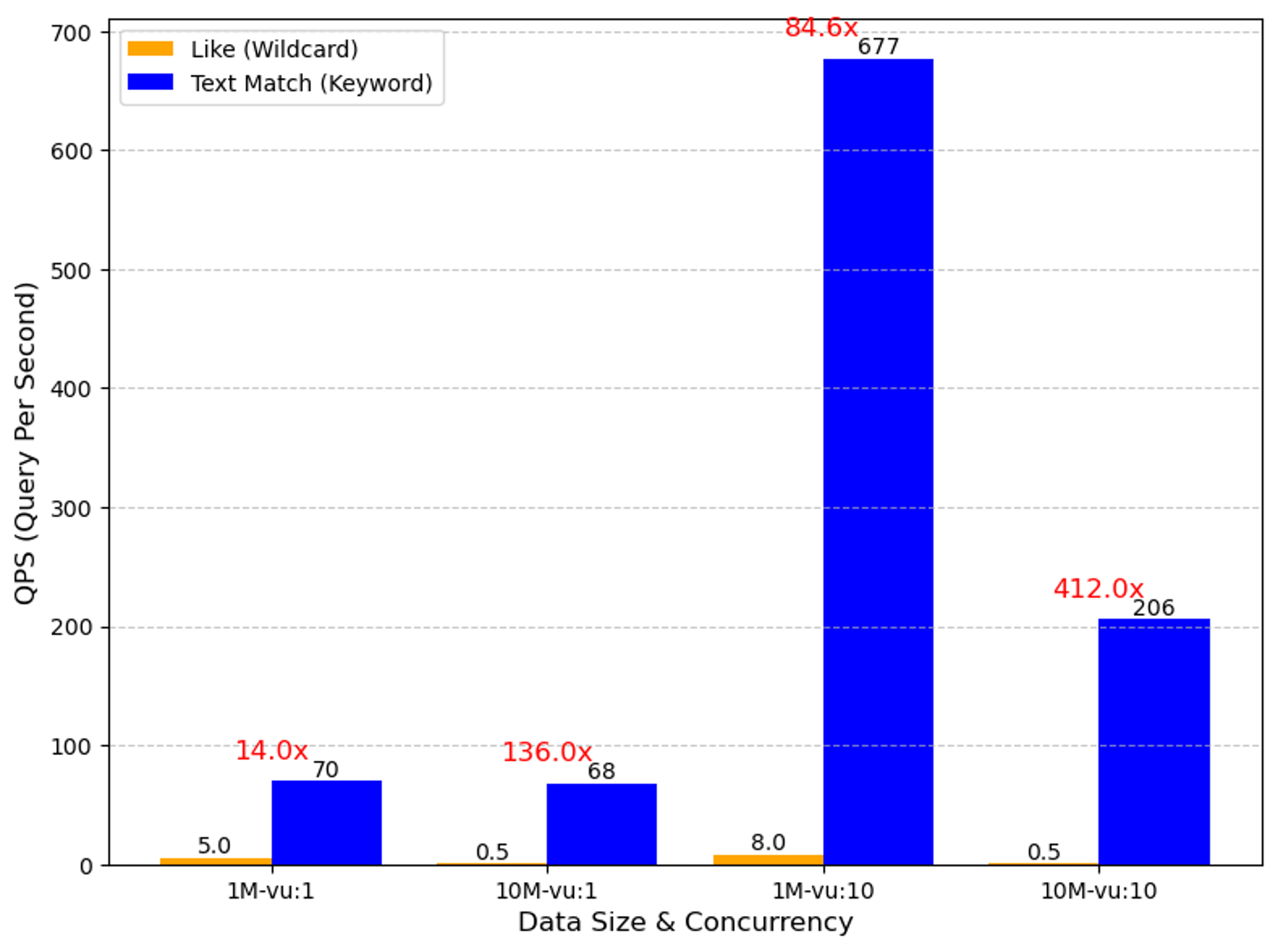
- Text Match is based on the Inverted Index after the text field is tokenized. Its performance far exceeds the Wildcard Match (i.e., like + %) function we provided in 2.4. According to our internal test results, the advantages of Text Match are very clear, especially in concurrent query scenarios, where it can achieve up to a 400-fold QPS increase.
In terms of JSON data processing, we plan to introduce in subsequent versions of 2.5.x the building of inverted indices for user-specified keys and default location information recording for all keys to speed up parsing. We expect both of these areas to significantly enhance the query performance of JSON and Dynamic Field. We plan to showcase more information in future release notes and technical blogs, so stay tuned!
New Management Interface
Managing a database shouldn’t require a computer science degree, but we know database administrators need powerful tools. That’s why we’ve introduced the Cluster Management WebUI, a new web-based interface accessible at your cluster’s address on port 9091/webui. This observability tool provides:
- Real-time monitoring dashboards showing cluster-wide metrics
- Detailed memory and performance analytics per node
- Segment information and slow query tracking
- System health indicators and node status
- Easy-to-use troubleshooting tools for complex system issues
While this interface is still in beta, we’re actively developing it based on user feedback from database administrators. Future updates will include AI-assisted diagnostics, more interactive management features, and enhanced cluster observability capabilities.
Documentation and Developer Experience
We’ve completely revamped our documentation and SDK/API experience to make Milvus more accessible while maintaining depth for experienced users. The improvements include:
- A restructured documentation system with clearer progression from basic to advanced concepts
- Interactive tutorials and real-world examples that showcase practical implementations
- Comprehensive API references with practical code samples
- A more user-friendly SDK design that simplifies common operations
- Illustrated guides that make complex concepts easier to understand
- An AI-powered documentation assistant (ASK AI) for quick answers
The updated SDK/API focuses on improving developer experience through more intuitive interfaces and better integration with the documentation. We believe you’ll notice these improvements when working with the 2.5.x series.
However, we know documentation and SDK development is an ongoing process. We’ll continue optimizing both the content structure and SDK design based on community feedback. Join our Discord channel to share your suggestions and help us improve further.
Summary
Milvus 2.5 contains 13 new features and several system-level optimizations, contributed not just by Zilliz but the open-source community. We have only touched on a few of them in this post and encourage you to visit our release note and official documents for more information!
- Overview
- Full-text Search via Sparse-BM25
- Techical Implementation
- Text Matching Search Filters
- Significant Enhancement in Scalar Filtering Performance
- New Management Interface
- Documentation and Developer Experience
- Summary
On This Page
Try Managed Milvus for Free
Zilliz Cloud is hassle-free, powered by Milvus and 10x faster.
Get StartedLike the article? Spread the word



