What Milvus version to start with
Selecting the appropriate Milvus version is foremost to the success of any project leveraging vector search technology. With different Milvus versions tailored to varying requirements, understanding the importance of selecting the correct version is crucial for achieving the desired results.
The right Milvus version can help a developer to learn and prototype quickly or help optimize resource utilization, streamline development efforts, and ensure compatibility with existing infrastructure and tools. Ultimately, it is about maintaining developer productivity and improving efficiency, reliability, and user satisfaction.
Available Milvus versions
Three versions of Milvus are available for developers, and all are open source. The three versions are Milvus Lite, Milvus Standalone, and Milvus Cluster, which differ in features and how users plan to use Milvus in the short and long term. So, let’s explore these individually.
Milvus Lite
As the name suggests, Milvus Lite is a lightweight version that integrates seamlessly with Google Colab and Jupyter Notebook. It is packaged as a single binary with no additional dependencies, making it easy to install and run on your machine or embed in Python applications. Additionally, Milvus Lite includes a CLI-based Milvus standalone server, providing flexibility for running it directly on your machine. Whether you embed it within your Python code or utilize it as a standalone server is entirely up to your preference and specific application requirements.
Features and Capabilities
Milvus Lite includes all core Milvus vector search features.
Search Capabilities: Supports top-k, range, and hybrid searches, including metadata filtering, to cater to diverse search requirements.
Index Types and Similarity Metrics: Offers support for 11 index types and five similarity metrics, providing flexibility and customization options for your specific use case.
Data Processing: Enables batch (Apache Parquet, Arrays, JSON) and stream processing, with seamless integration through connectors for Airbyte, Apache Kafka, and Apache Spark.
CRUD Operations: Offers full CRUD support (create, read, update/upsert, delete), empowering users with comprehensive data management capabilities.
Applications and limitations
Milvus Lite is ideal for rapid prototyping and local development, offering support for quick setup and experimentation with small-scale datasets on your machine. However, its limitations become apparent when transitioning to production environments with larger datasets and more demanding infrastructure requirements. As such, while Milvus Lite is an excellent tool for initial exploration and testing, it may not be suitable for deploying applications in high-volume or production-ready settings.
Available Resources
Milvus Standalone
Milvus offers two operational modes: Standalone and Cluster. Both modes are identical in core vector database features and differ in data size support and scalability requirements. This distinction allows you to select the mode that best aligns with your dataset size, traffic volume, and other infrastructure requirements for production.
Milvus Standalone is a mode of operation for the Milvus vector database system where it operates independently as a single instance without any clustering or distributed setup. Milvus runs on a single server or machine in this mode, providing functionalities such as indexing and searching for vectors. It is suitable for situations where the data and traffic volume scale is relatively small and does not require the distributed capabilities provided by a clustered setup.
Features and Capabilities
High Performance: Conduct vector searches on massive datasets (billions or more) with exceptional speed and efficiency.
Search Capabilities: Supports top-k, range, and hybrid searches, including metadata filtering, to cater to diverse search requirements.
Index Types and Similarity Metrics: Offers support for 11 index types and 5 similarity metrics, providing flexibility and customization options for your specific use case.
Data Processing: Enables both batch (Apache Parquet, Arrays, Json) and stream processing, with seamless integration through connectors for Airbyte, Apache Kafka, and Apache Spark.
Scalability: Achieve dynamic scalability with component-level scaling, allowing for seamless scaling up and down based on demand. Milvus can autoscale at a component level, optimizing resource allocation for enhanced efficiency.
Multi-Tenancy: Supports multi-tenancy with the capability to manage up to 10,000 collections/partitions in a cluster, providing efficient resource utilization and isolation for different users or applications.
CRUD Operations: Offers full CRUD support (create, read, update/upsert, delete), empowering users with comprehensive data management capabilities.
Essential components:
Milvus: The core functional component.
etcd: The metadata engine responsible for accessing and storing metadata from Milvus’ internal components, including proxies, index nodes, and more.
MinIO: The storage engine responsible for data persistence within Milvus.
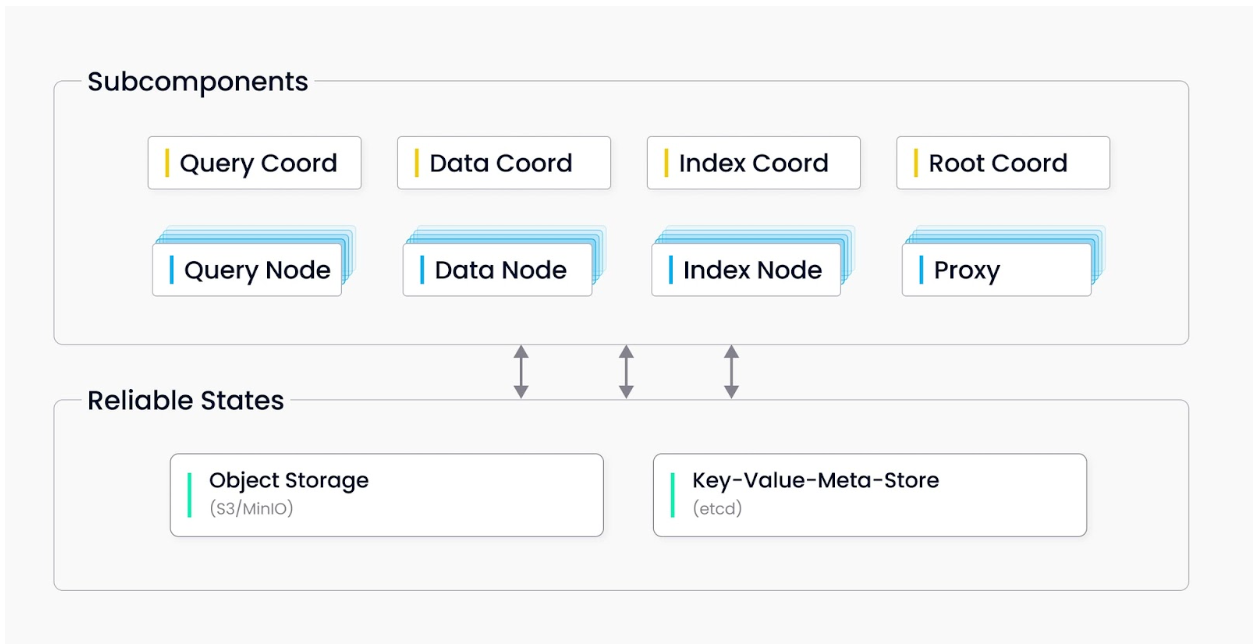
Figure 1: Milvus Standalone Architecture
Available Resources
Documentation
Milvus Cluster
Milvus Cluster is a mode of operation for the Milvus vector database system where it operates and is distributed across multiple nodes or servers. In this mode, Milvus instances are clustered together to form a unified system that can handle larger volumes of data and higher traffic loads compared to a standalone setup. Milvus Cluster offers scalability, fault tolerance, and load balancing features, making it suitable for scenarios that need to handle big data and serve many concurrent queries efficiently.
Features and Capabilities
Inherits all features available in Milvus Standalone, including high-performance vector search, support for multiple index types and similarity metrics, and seamless integration with batch and stream processing frameworks.
Offers unparalleled availability, performance, and cost optimization by leveraging distributed computing and load balancing across multiple nodes.
Enables deploying and scaling secure, enterprise-grade workloads with lower total costs by efficiently utilizing resources across the cluster and optimizing resource allocation based on workload demands.
Essential components:
Milvus Cluster includes eight microservice components and three third-party dependencies. All microservices can be deployed on Kubernetes independently from each other.
Microservice components
Root coord
Proxy
Query coord
Query node
Index coord
Index node
Data coord
Data node
Third-party dependencies
etcd: Stores metadata for various components in the cluster.
MinIO: Responsible for data persistence of large files in the cluster, such as index and binary log files.
Pulsar: Manages logs of recent mutation operations, outputs streaming log, and provides log publish-subscribe services.
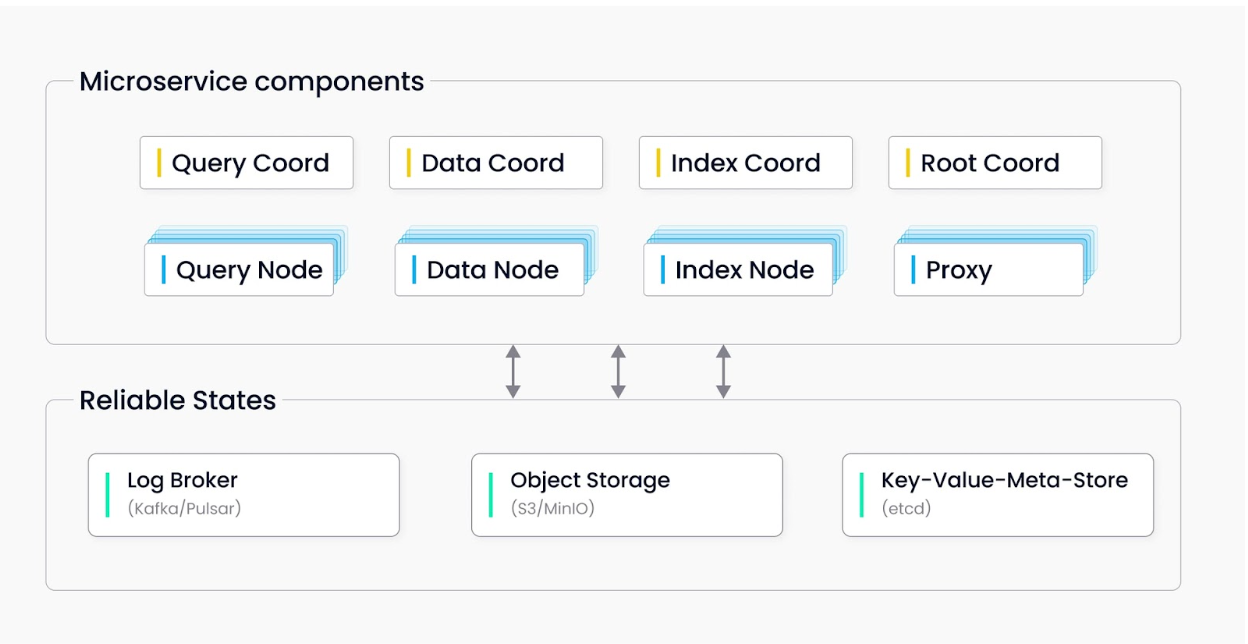
Figure 2: Milvus Cluster Architecture
Available Resources
Documentation | How to get started
Making the Decision on which Milvus version to use
When deciding which version of Milvus to use for your project, you must consider factors such as your dataset size, traffic volume, scalability requirements, and production environment constraints. Milvus Lite is perfect for prototyping on your laptop. Milvus Standalone offers high performance and flexibility for conducting vector searches on your datasets, making it suitable for smaller-scale deployments, CI/CD, and offline deployments when you have no Kubernetes support… And finally, Milvus Cluster provides unparalleled availability, scalability, and cost optimization for enterprise-grade workloads, making it the preferred choice for large-scale, highly available production environments.
There is another version that is a hassle-free version, and that is a managed version of Milvus called Zilliz Cloud.
Ultimately, the Milvus version will depend on your specific use case, infrastructure requirements, and long-term goals. By carefully evaluating these factors and understanding the features and capabilities of each version, you can make an informed decision that aligns with your project’s needs and objectives. Whether you choose Milvus Standalone or Milvus Cluster, you can leverage the power of vector databases to enhance the performance and efficiency of your AI applications.
- Available Milvus versions
- Milvus Lite
- Milvus Standalone
- Milvus Cluster
- Making the Decision on which Milvus version to use
On This Page
Try Managed Milvus for Free
Zilliz Cloud is hassle-free, powered by Milvus and 10x faster.
Get Started




Like the article? Spread the word