LangExtract + Milvus: A Practical Guide to Building a Hybrid Document Processing and Search System
In a previous blog, we compared two popular approaches to code search in many coding agents:
Vector search-powered RAG (semantic retrieval) – used by tools like Cursor
Keyword search with
grep(literal string matching) – used by Claude Code and Gemini
That post sparked a lot of feedback. Some developers argued for RAG, pointing out that grep often includes irrelevant matches and bloats the context. Others defended keyword search, saying precision is everything and embeddings are still too fuzzy to trust.
Both sides have a point. The reality is, there’s no perfect, one-size-fits-all solution.
Rely only on embeddings, and you’ll miss strict rules or exact matches.
Rely only on keywords, and you’ll lose the semantic understanding of what the code (or text) actually means.
This tutorial demonstrates a method for combining both approaches intelligently. We’ll show you how to use LangExtract—a Python library that uses LLMs to turn messy text into structured data with precise source attribution—together with Milvus, an open-source high-performance vector database, to build a more intelligent, high-quality document processing and retrieval system.
Key Technologies We’ll Use
Before we get started building this document processing and retrieval system, let’s take a look at the key technologies we’ll use in this tutorial.
What is LangExtract?
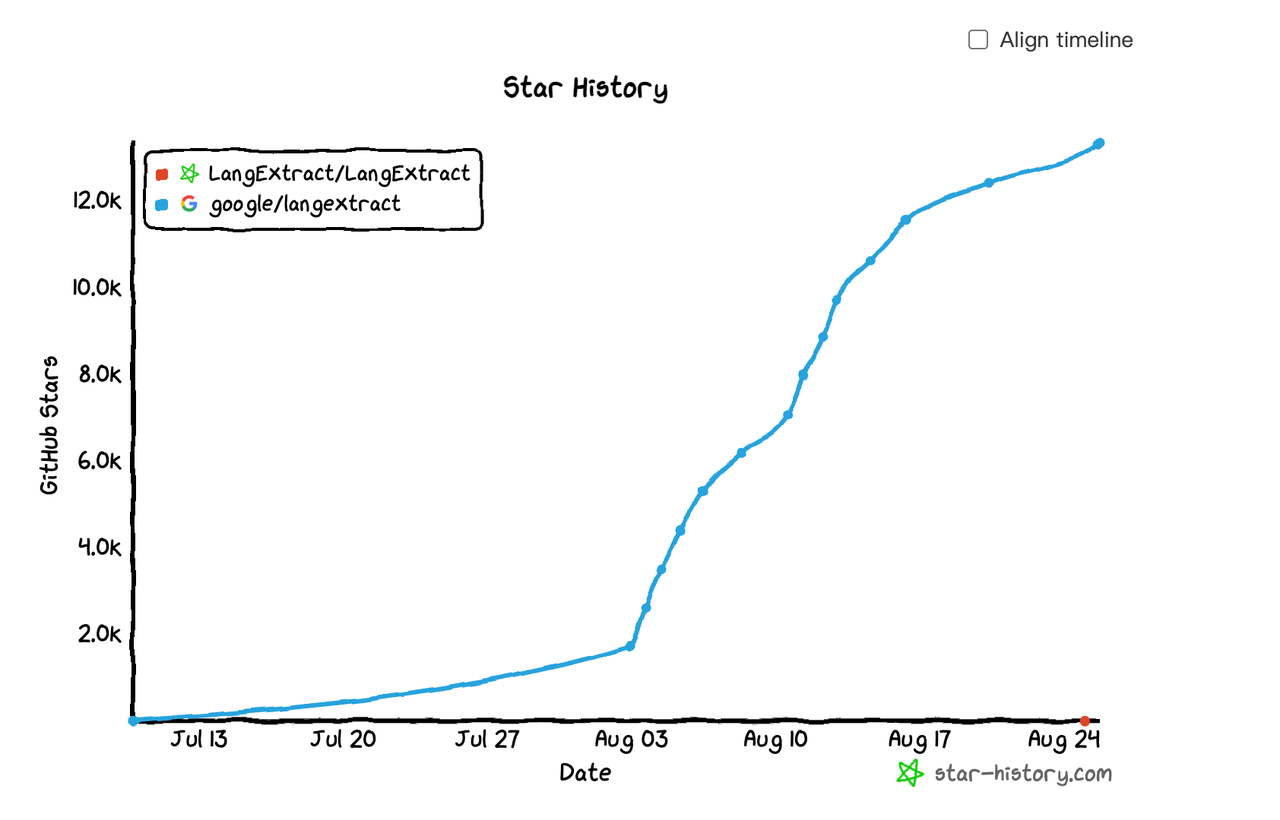
LangExtract is a new Python library, open-sourced by Google, that utilizes LLMs to transform messy, unstructured text into structured data with source attribution. It’s already popular (13K+ GitHub stars) because it makes tasks like information extraction dead simple.
 Key features include:
Key features include:
Structured extraction: Define a schema and extract names, dates, locations, charges, and other relevant information.
Source traceability: Every extracted field is linked back to the original text, reducing the likelihood of hallucinations.
Scales to long docs: Handles millions of characters with chunking + multi-threading.
LangExtract is especially useful in domains such as law, healthcare, and forensics, where precision is crucial. For example, instead of retrieving a giant block of text with RAG, LangExtract can extract just the dates, clauses, or patient demographics you care about—while still preserving semantic context.
What’s Milvus?
Milvus is an open-source vector database with more than 36K+stars on Github and has been adopted by more than 10K enterprise uses across various industries. Milvus is widely used in RAG systems, AI Agents, recommendation engines, anomaly detection, and semantic search, making it a core building block for AI-powered applications.
Building a High-Quality Document Processing System with LangExtract + Milvus
This guide walks you through the process of combining LangExtract and Milvus to build an intelligent document processing and retrieval system.
LangExtract generates clean, structured metadata, and then stores + searches it efficiently with Milvus, giving us the best of both worlds: precise filtering plus semantic retrieval.
Milvus will act as the retrieval backbone, storing both embeddings (for semantic search) and structured metadata extracted by LangExtract, allowing us to run precise and intelligent hybrid queries at scale.
Prerequisites
Before diving in, make sure you have the following dependencies installed:
! pip install --upgrade pymilvus langextract google-genai requests tqdm pandas
We’ll use Gemini as our LLM for this example. You’ll need to set up your API key as an environment variable:
import os
os.environ["GEMINI_API_KEY"] = "AIza*****************"
Setting Up the LangExtract + Milvus Pipeline
Let’s start by defining our pipeline that uses LangExtract for structured information extraction and Milvus as our vector store.
import langextract as lx
import textwrap
from google import genai
from google.genai.types import EmbedContentConfig
from pymilvus import MilvusClient, DataType
import uuid
Configuration and Setup
Now we’ll configure the global parameters for our integration. We’re using Gemini’s embedding model to generate vector representations for our documents.
genai_client = genai.Client()
COLLECTION_NAME = "document_extractions"
EMBEDDING_MODEL = "gemini-embedding-001"
EMBEDDING_DIM = 3072 # Default dimension for gemini-embedding-001
Initializing the Milvus Client
Let’s initialize our Milvus client. For simplicity, we’ll use a local database file, though this approach scales easily to full Milvus server deployments.
client = MilvusClient(uri="./milvus_demo.db")
About MilvusClient parameters:
Setting the uri as a local file (like ./milvus.db) is the most convenient method since it automatically uses Milvus Lite to store all data in this file.
For large-scale data, you can set up a more performant Milvus server on Docker or Kubernetes. In this setup, use the server uri (like[ http://localhost:19530](http://localhost:19530)) instead.
If you prefer Zilliz Cloud (the fully managed cloud service for Milvus), adjust the uri and token to match your Public Endpoint and API key from Zilliz Cloud.
Preparing Sample Data
For this demo, we’ll use movie descriptions as our sample documents. This showcases how LangExtract can extract structured information like genres, characters, and themes from unstructured text.
sample_documents = [
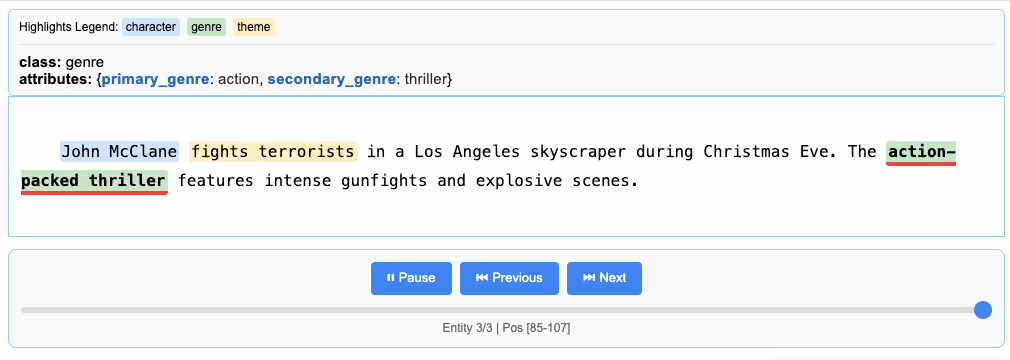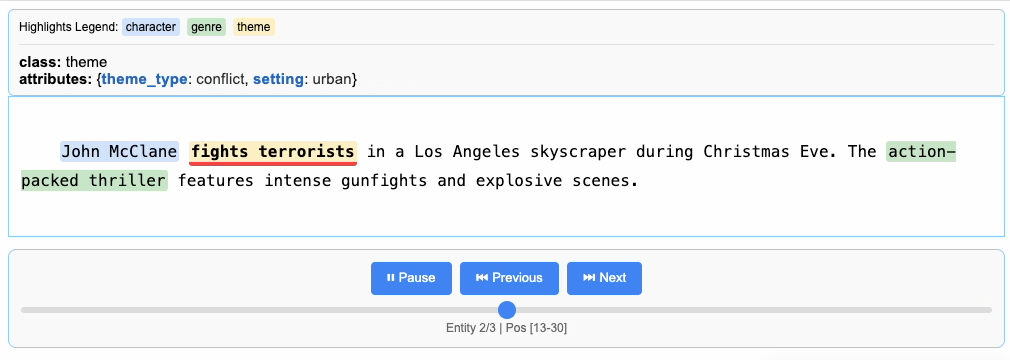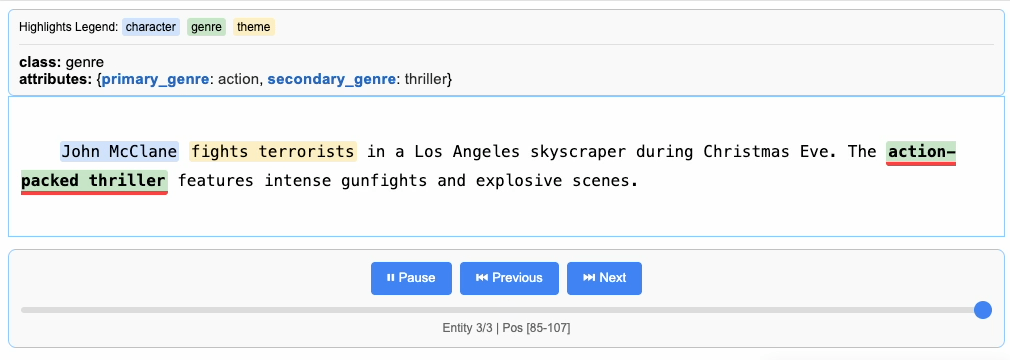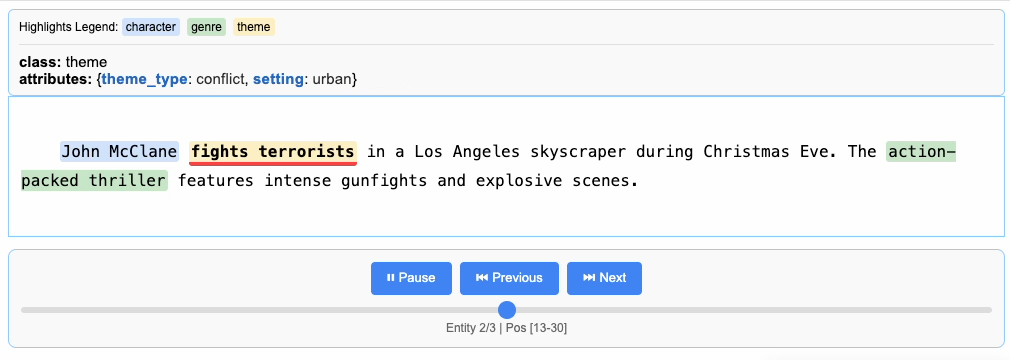
"John McClane fights terrorists in a Los Angeles skyscraper during Christmas Eve. The action-packed thriller features intense gunfights and explosive scenes.",
"A young wizard named Harry Potter discovers his magical abilities at Hogwarts School. The fantasy adventure includes magical creatures and epic battles.",
"Tony Stark builds an advanced suit of armor to become Iron Man. The superhero movie showcases cutting-edge technology and spectacular action sequences.",
"A group of friends get lost in a haunted forest where supernatural creatures lurk. The horror film creates a terrifying atmosphere with jump scares.",
"Two detectives investigate a series of mysterious murders in New York City. The crime thriller features suspenseful plot twists and dramatic confrontations.",
"A brilliant scientist creates artificial intelligence that becomes self-aware. The sci-fi thriller explores the dangers of advanced technology and human survival.",
"A romantic comedy about two friends who fall in love during a cross-country road trip. The drama explores personal growth and relationship dynamics.",
"An evil sorcerer threatens to destroy the magical kingdom. A brave hero must gather allies and master ancient magic to save the fantasy world.",
"Space marines battle alien invaders on a distant planet. The action sci-fi movie features futuristic weapons and intense combat in space.",
"A detective investigates supernatural crimes in Victorian London. The horror thriller combines period drama with paranormal investigation themes.",
]
print("=== LangExtract + Milvus Integration Demo ===")
print(f"Preparing to process {len(sample_documents)} documents")
Setting Up the Milvus Collection
Before we can store our extracted data, we need to create a Milvus collection with the appropriate schema. This collection will store the original document text, vector embeddings, and extracted metadata fields.
print("\n1. Setting up Milvus collection...")
# Drop existing collection if it exists
if client.has_collection(collection_name=COLLECTION_NAME):
client.drop_collection(collection_name=COLLECTION_NAME)
print(f"Dropped existing collection: {COLLECTION_NAME}")
# Create collection schema
schema = client.create_schema(
auto_id=False,
enable_dynamic_field=True,
description="Document extraction results and vector storage",
)
# Add fields - simplified to 3 main metadata fields
schema.add_field(
field_name="id", datatype=DataType.VARCHAR, max_length=100, is_primary=True
)
schema.add_field(
field_name="document_text", datatype=DataType.VARCHAR, max_length=10000
)
schema.add_field(
field_name="embedding", datatype=DataType.FLOAT_VECTOR, dim=EMBEDDING_DIM
)
# Create collection
client.create_collection(collection_name=COLLECTION_NAME, schema=schema)
print(f"Collection '{COLLECTION_NAME}' created successfully")
# Create vector index
index_params = client.prepare_index_params()
index_params.add_index(
field_name="embedding",
index_type="AUTOINDEX",
metric_type="COSINE",
)
client.create_index(collection_name=COLLECTION_NAME, index_params=index_params)
print("Vector index created successfully")
Defining the Extraction Schema
LangExtract uses prompts and examples to guide the LLM in extracting structured information. Let’s define our extraction schema for movie descriptions, specifying exactly what information to extract and how to categorize it.
print("\n2. Extracting tags from documents...")
# Define extraction prompt - for movie descriptions, specify attribute value ranges
prompt = textwrap.dedent(
"""\
Extract movie genre, main characters, and key themes from movie descriptions.
Use exact text for extractions. Do not paraphrase or overlap entities.
For each extraction, provide attributes with values from these predefined sets:
Genre attributes:
- primary_genre: ["action", "comedy", "drama", "horror", "sci-fi", "fantasy", "thriller", "crime", "superhero"]
- secondary_genre: ["action", "comedy", "drama", "horror", "sci-fi", "fantasy", "thriller", "crime", "superhero"]
Character attributes:
- role: ["protagonist", "antagonist", "supporting"]
- type: ["hero", "villain", "detective", "military", "wizard", "scientist", "friends", "investigator"]
Theme attributes:
- theme_type: ["conflict", "investigation", "personal_growth", "technology", "magic", "survival", "romance"]
- setting: ["urban", "space", "fantasy_world", "school", "forest", "victorian", "america", "future"]
Focus on identifying key elements that would be useful for movie search and filtering."""
)
Providing Examples to Improve Extraction Quality
To improve extraction quality and consistency, we’ll provide LangExtract with carefully crafted examples. These examples demonstrate the expected format and help the model understand our specific extraction requirements.
# Provide examples to guide the model - n-shot examples for movie descriptions
# Unify attribute keys to ensure consistency in extraction results
examples = [
lx.data.ExampleData(
text="A space marine battles alien creatures on a distant planet. The sci-fi action movie features futuristic weapons and intense combat scenes.",
extractions=[
lx.data.Extraction(
extraction_class="genre",
extraction_text="sci-fi action",
attributes={"primary_genre": "sci-fi", "secondary_genre": "action"},
),
lx.data.Extraction(
extraction_class="character",
extraction_text="space marine",
attributes={"role": "protagonist", "type": "military"},
),
lx.data.Extraction(
extraction_class="theme",
extraction_text="battles alien creatures",
attributes={"theme_type": "conflict", "setting": "space"},
),
],
),
lx.data.ExampleData(
text="A detective investigates supernatural murders in Victorian London. The horror thriller film combines period drama with paranormal elements.",
extractions=[
lx.data.Extraction(
extraction_class="genre",
extraction_text="horror thriller",
attributes={"primary_genre": "horror", "secondary_genre": "thriller"},
),
lx.data.Extraction(
extraction_class="character",
extraction_text="detective",
attributes={"role": "protagonist", "type": "detective"},
),
lx.data.Extraction(
extraction_class="theme",
extraction_text="supernatural murders",
attributes={"theme_type": "investigation", "setting": "victorian"},
),
],
),
lx.data.ExampleData(
text="Two friends embark on a road trip adventure across America. The comedy drama explores friendship and self-discovery through humorous situations.",
extractions=[
lx.data.Extraction(
extraction_class="genre",
extraction_text="comedy drama",
attributes={"primary_genre": "comedy", "secondary_genre": "drama"},
),
lx.data.Extraction(
extraction_class="character",
extraction_text="two friends",
attributes={"role": "protagonist", "type": "friends"},
),
lx.data.Extraction(
extraction_class="theme",
extraction_text="friendship and self-discovery",
attributes={"theme_type": "personal_growth", "setting": "america"},
),
],
),
]
# Extract from each document
extraction_results = []
for doc in sample_documents:
result = lx.extract(
text_or_documents=doc,
prompt_description=prompt,
examples=examples,
model_id="gemini-2.0-flash",
)
extraction_results.append(result)
print(f"Successfully extracted from document: {doc[:50]}...")
print(f"Completed tag extraction, processed {len(extraction_results)} documents")
Successfully extracted from document: John McClane fights terrorists in a Los Angeles...
...
Completed tag extraction, processed 10 documents
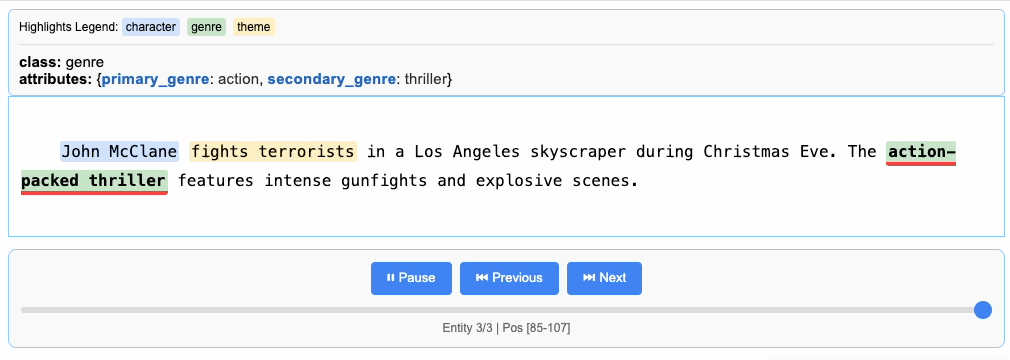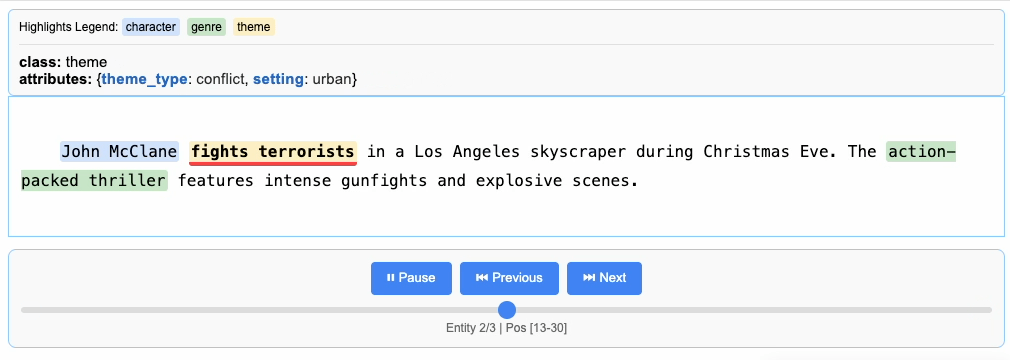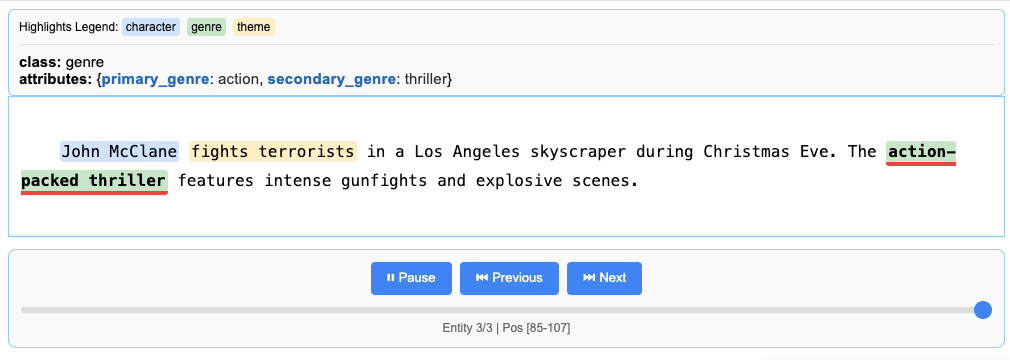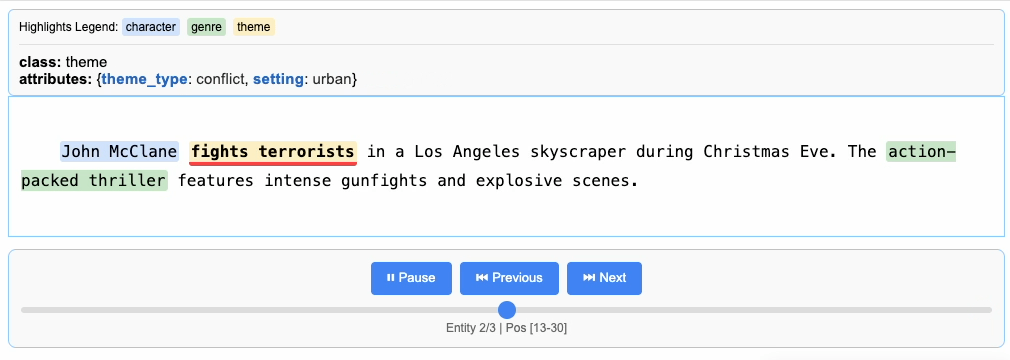
Processing and Vectorizing Results
Now we need to process our extraction results and generate vector embeddings for each document. We’ll also flatten the extracted attributes into separate fields to make them easily searchable in Milvus.
print("\n3. Processing extraction results and generating vectors...")
processed_data = []
for result in extraction_results:
# Generate vectors for documents
embedding_response = genai_client.models.embed_content(
model=EMBEDDING_MODEL,
contents=[result.text],
config=EmbedContentConfig(
task_type="RETRIEVAL_DOCUMENT",
output_dimensionality=EMBEDDING_DIM,
),
)
embedding = embedding_response.embeddings[0].values
print(f"Successfully generated vector: {result.text[:30]}...")
# Initialize data structure, flatten attributes into separate fields
data_entry = {
"id": result.document_id or str(uuid.uuid4()),
"document_text": result.text,
"embedding": embedding,
# Initialize all possible fields with default values
"genre": "unknown",
"primary_genre": "unknown",
"secondary_genre": "unknown",
"character_role": "unknown",
"character_type": "unknown",
"theme_type": "unknown",
"theme_setting": "unknown",
}
# Process extraction results, flatten attributes
for extraction in result.extractions:
if extraction.extraction_class == "genre":
# Flatten genre attributes
data_entry["genre"] = extraction.extraction_text
attrs = extraction.attributes or {}
data_entry["primary_genre"] = attrs.get("primary_genre", "unknown")
data_entry["secondary_genre"] = attrs.get("secondary_genre", "unknown")
elif extraction.extraction_class == "character":
# Flatten character attributes (take first main character's attributes)
attrs = extraction.attributes or {}
if (
data_entry["character_role"] == "unknown"
): # Only take first character's attributes
data_entry["character_role"] = attrs.get("role", "unknown")
data_entry["character_type"] = attrs.get("type", "unknown")
elif extraction.extraction_class == "theme":
# Flatten theme attributes (take first main theme's attributes)
attrs = extraction.attributes or {}
if (
data_entry["theme_type"] == "unknown"
): # Only take first theme's attributes
data_entry["theme_type"] = attrs.get("theme_type", "unknown")
data_entry["theme_setting"] = attrs.get("setting", "unknown")
processed_data.append(data_entry)
print(f"Completed data processing, ready to insert {len(processed_data)} records")
3. Processing extraction results and generating vectors...
Successfully generated vector: John McClane fights terrorists...
...
Completed data processing, ready to insert 10 records
Inserting Data into Milvus
With our processed data ready, let’s insert it into our Milvus collection. This enables us to perform both semantic searches and precise metadata filtering.
print("\n4. Inserting data into Milvus...")
if processed_data:
res = client.insert(collection_name=COLLECTION_NAME, data=processed_data)
print(f"Successfully inserted {len(processed_data)} documents into Milvus")
print(f"Insert result: {res}")
else:
print("No data to insert")
4. Inserting data into Milvus...
Successfully inserted 10 documents into Milvus
Insert result: {'insert_count': 10, 'ids': ['doc_f8797155', 'doc_78c7e586', 'doc_fa3a3ab5', 'doc_64981815', 'doc_3ab18cb2', 'doc_1ea42b18', 'doc_f0779243', 'doc_386590b7', 'doc_3b3ae1ab', 'doc_851089d6']}
Demonstrating Metadata Filtering
One of the key advantages of combining LangExtract with Milvus is the ability to perform precise filtering based on extracted metadata. Let’s see this in action with some filter expression searches.
print("\n=== Filter Expression Search Examples ===")
# Load collection into memory for querying
print("Loading collection into memory...")
client.load_collection(collection_name=COLLECTION_NAME)
print("Collection loaded successfully")
# Search for thriller movies
print("\n1. Searching for thriller movies:")
results = client.query(
collection_name=COLLECTION_NAME,
filter='secondary_genre == "thriller"',
output_fields=["document_text", "genre", "primary_genre", "secondary_genre"],
limit=5,
)
for result in results:
print(f"- {result['document_text'][:100]}...")
print(
f" Genre: {result['genre']} ({result.get('primary_genre')}-{result.get('secondary_genre')})"
)
# Search for movies with military characters
print("\n2. Searching for movies with military characters:")
results = client.query(
collection_name=COLLECTION_NAME,
filter='character_type == "military"',
output_fields=["document_text", "genre", "character_role", "character_type"],
limit=5,
)
for result in results:
print(f"- {result['document_text'][:100]}...")
print(f" Genre: {result['genre']}")
print(
f" Character: {result.get('character_role')} ({result.get('character_type')})"
)
=== Filter Expression Search Examples ===
Loading collection into memory...
Collection loaded successfully
1. Searching for thriller movies:
- A brilliant scientist creates artificial intelligence that becomes self-aware. The sci-fi thriller e...
Genre: sci-fi thriller (sci-fi-thriller)
- Two detectives investigate a series of mysterious murders in New York City. The crime thriller featu...
Genre: crime thriller (crime-thriller)
- A detective investigates supernatural crimes in Victorian London. The horror thriller combines perio...
Genre: horror thriller (horror-thriller)
- John McClane fights terrorists in a Los Angeles skyscraper during Christmas Eve. The action-packed t...
Genre: action-packed thriller (action-thriller)
2. Searching for movies with military characters:
- Space marines battle alien invaders on a distant planet. The action sci-fi movie features futuristic...
Genre: action sci-fi
Character: protagonist (military)
Perfect! Our search results accurately match the “thriller” and “military characters” filter conditions.
Combining Semantic Search with Metadata Filtering
Here’s where the real power of this integration shines: combining semantic vector search with precise metadata filtering. This allows us to find semantically similar content while applying specific constraints based on our extracted attributes.
print("\n=== Semantic Search Examples ===")
# 1. Search for action-related content + only thriller genre
print("\n1. Searching for action-related content + only thriller genre:")
query_text = "action fight combat battle explosion"
query_embedding_response = genai_client.models.embed_content(
model=EMBEDDING_MODEL,
contents=[query_text],
config=EmbedContentConfig(
task_type="RETRIEVAL_QUERY",
output_dimensionality=EMBEDDING_DIM,
),
)
query_embedding = query_embedding_response.embeddings[0].values
results = client.search(
collection_name=COLLECTION_NAME,
data=[query_embedding],
anns_field="embedding",
limit=3,
filter='secondary_genre == "thriller"',
output_fields=["document_text", "genre", "primary_genre", "secondary_genre"],
search_params={"metric_type": "COSINE"},
)
if results:
for result in results[0]:
print(f"- Similarity: {result['distance']:.4f}")
print(f" Text: {result['document_text'][:100]}...")
print(
f" Genre: {result.get('genre')} ({result.get('primary_genre')}-{result.get('secondary_genre')})"
)
# 2. Search for magic-related content + fantasy genre + conflict theme
print("\n2. Searching for magic-related content + fantasy genre + conflict theme:")
query_text = "magic wizard spell fantasy magical"
query_embedding_response = genai_client.models.embed_content(
model=EMBEDDING_MODEL,
contents=[query_text],
config=EmbedContentConfig(
task_type="RETRIEVAL_QUERY",
output_dimensionality=EMBEDDING_DIM,
),
)
query_embedding = query_embedding_response.embeddings[0].values
results = client.search(
collection_name=COLLECTION_NAME,
data=[query_embedding],
anns_field="embedding",
limit=3,
filter='primary_genre == "fantasy" and theme_type == "conflict"',
output_fields=[
"document_text",
"genre",
"primary_genre",
"theme_type",
"theme_setting",
],
search_params={"metric_type": "COSINE"},
)
if results:
for result in results[0]:
print(f"- Similarity: {result['distance']:.4f}")
print(f" Text: {result['document_text'][:100]}...")
print(f" Genre: {result.get('genre')} ({result.get('primary_genre')})")
print(f" Theme: {result.get('theme_type')} ({result.get('theme_setting')})")
print("\n=== Demo Complete ===")
=== Semantic Search Examples ===
1. Searching for action-related content + only thriller genre:
- Similarity: 0.6947
Text: John McClane fights terrorists in a Los Angeles skyscraper during Christmas Eve. The action-packed t...
Genre: action-packed thriller (action-thriller)
- Similarity: 0.6128
Text: Two detectives investigate a series of mysterious murders in New York City. The crime thriller featu...
Genre: crime thriller (crime-thriller)
- Similarity: 0.5889
Text: A brilliant scientist creates artificial intelligence that becomes self-aware. The sci-fi thriller e...
Genre: sci-fi thriller (sci-fi-thriller)
2. Searching for magic-related content + fantasy genre + conflict theme:
- Similarity: 0.6986
Text: An evil sorcerer threatens to destroy the magical kingdom. A brave hero must gather allies and maste...
Genre: fantasy (fantasy)
Theme: conflict (fantasy_world)
=== Demo Complete ===
As you can see, our semantic search results using Milvus both meet the genre filter conditions and show high relevance to our query text content.
What You’ve Built and What It Means
You now have a hybrid document processing system that combines structured extraction with semantic search—no more choosing between accuracy and flexibility. This approach maximizes unstructured data value while ensuring reliability, making it ideal for high-stakes scenarios in finance, healthcare, and legal domains.
The same principles scale across industries: combine structured image analysis with semantic search for better e-commerce recommendations, or apply it to video content for enhanced autonomous driving data mining.
For large-scale deployments managing massive multimodal datasets, our upcoming vector data lake will offer much more cost-effective cold storage, wide table support, and streamlined ETL processing—the natural evolution for production-scale hybrid search systems. Stay tuned.
Have questions or want to share your results? Join the conversation on GitHub or connect with our community on Discord.
- Key Technologies We’ll Use
- What is LangExtract?
- What’s Milvus?
- Building a High-Quality Document Processing System with LangExtract + Milvus
- Prerequisites
- Setting Up the LangExtract + Milvus Pipeline
- Configuration and Setup
- Initializing the Milvus Client
- Preparing Sample Data
- Setting Up the Milvus Collection
- Defining the Extraction Schema
- Providing Examples to Improve Extraction Quality
- Processing and Vectorizing Results
- Inserting Data into Milvus
- Demonstrating Metadata Filtering
- Combining Semantic Search with Metadata Filtering
- What You've Built and What It Means
On This Page
Try Managed Milvus for Free
Zilliz Cloud is hassle-free, powered by Milvus and 10x faster.
Get StartedLike the article? Spread the word



