Why I’m Against Claude Code’s Grep-Only Retrieval? It Just Burns Too Many Tokens
AI coding assistants are exploding. In just the last two years, tools like Cursor, Claude Code, Gemini CLI, and Qwen Code have gone from curiosities to everyday companions for millions of developers. But behind this rapid rise lies a brewing fight over something deceptively simple: how should an AI coding assistant actually search your codebase for context?
Right now, there are two approaches:
Vector search-powered RAG (semantic retrieval).
Keyword search with grep (literal string matching).
Claude Code and Gemini have chosen the latter. In fact, a Claude engineer openly admitted on Hacker News that Claude Code doesn’t use RAG at all. Instead, it just greps your repo line by line (what they call “agentic search”)—no semantics, no structure, just raw string matching.

That revelation split the community:
Supporters defend grep’s simplicity. It’s fast, exact, and—most importantly—predictable. With programming, they argue, precision is everything, and today’s embeddings are still too fuzzy to trust.
Critics see grep as a dead end. It drowns you in irrelevant matches, burns tokens, and stalls your workflow. Without semantic understanding, it’s like asking your AI to debug blindfolded.
Both sides have a point. And after building and testing my own solution, I can say this: vector search-based RAG approach changes the game. Not only does it make search dramatically faster and more accurate, but it also reduces token usage by 40% or more. (Skip to the Claude Context part for my approach)
So why is grep so limiting? And how can vector search actually deliver better results in practice? Let’s break it down.
What’s Wrong with Claude Code’s Grep-Only Code Search?
I ran into this problem while debugging a thorny issue. Claude Code fired off grep queries across my repo, dumping giant blobs of irrelevant text back at me. One minute in, I still hadn’t found the relevant file. Five minutes later, I finally had the right 10 lines—but they’d been buried in 500 lines of noise.
That’s not an edge case. Skimming Claude Code’s GitHub issues shows plenty of frustrated developers running into the same wall:
issue1: https://github.com/anthropics/claude-code/issues/1315
issue2: https://github.com/anthropics/claude-code/issues/4556
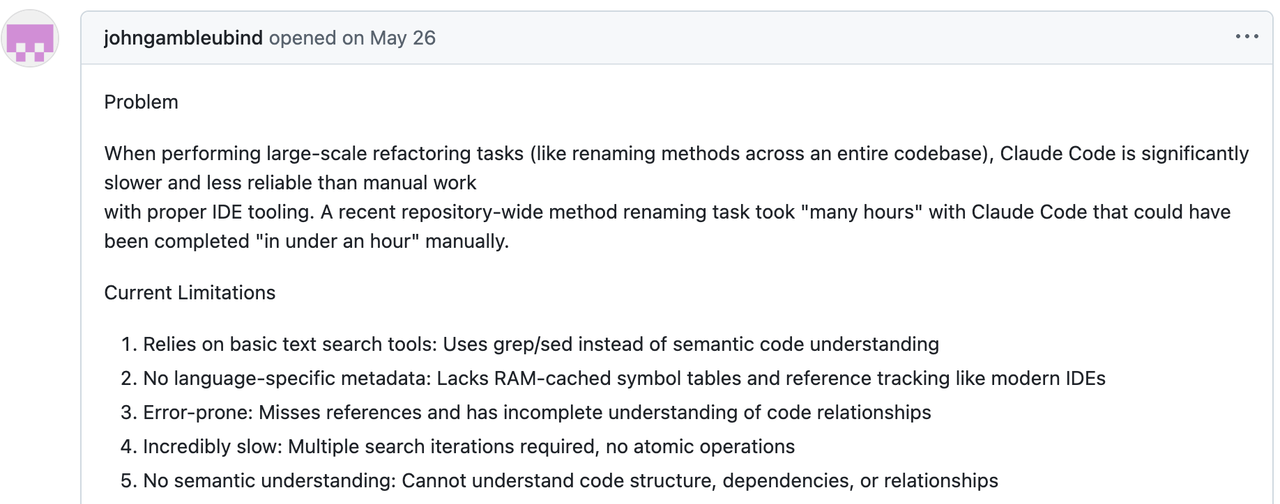
The community’s frustration boils down to three pain points:
Token bloat. Every grep dump shovels massive amounts of irrelevant code into the LLM, driving up costs that scale horribly with repo size.
Time tax. You’re stuck waiting while the AI plays twenty questions with your codebase, killing focus and flow.
Zero context. Grep matches literal strings. It has no sense of meaning or relationships, so you’re effectively searching blind.
That’s why the debate matters: grep isn’t just “old school,” it’s actively holding back AI-assisted programming.
Claude Code vs Cursor: Why the Latter Has Better Code Context
When it comes to code context, Cursor has done a better job. From day one, Cursor has leaned into codebase indexing: break your repo into meaningful chunks, embed those chunks into vectors, and retrieve them semantically whenever the AI needs context. This is textbook Retrieval-Augmented Generation (RAG) applied to code, and the results speak for themselves: tighter context, fewer tokens wasted, and faster retrieval.

Claude Code, by contrast, has doubled down on simplicity. No indexes, no embeddings—just grep. That means every search is literal string matching, with no understanding of structure or semantics. It’s fast in theory, but in practice, developers often end up sifting through haystacks of irrelevant matches before finding the one needle they actually need.
| Claude Code | Cursor | |
|---|---|---|
| Search Accuracy | Only surfaces exact matches—misses anything named differently. | Finds semantically relevant code even when keywords don’t match exactly. |
| Efficiency | Grep dumps massive blobs of code into the model, driving up token costs. | Smaller, higher-signal chunks reduce token load by 30–40%. |
| Scalability | Re-greps the repo every time, which slows down as projects grow. | Indexes once, then retrieves at scale with minimal lag. |
| Philosophy | Stay minimal—no extra infrastructure. | Index everything, retrieve intelligently. |
So why hasn’t Claude (or Gemini, or Cline) followed Cursor’s lead? The reasons are partly technical and partly cultural. Vector retrieval isn’t trivial—you need to solve chunking, incremental updates, and large-scale indexing. But more importantly, Claude Code is built around minimalism: no servers, no indexes, just a clean CLI. Embeddings and vector DBs don’t fit that design philosophy.
That simplicity is appealing—but it also caps the ceiling of what Claude Code can deliver. Cursor’s willingness to invest in real indexing infrastructure is why it feels more powerful today.
Claude Context: an Open-Source Project for Adding Semantic Code Search to Claude Code
Claude Code is a strong tool—but it has poor code context. Cursor solved this with codebase indexing, but Cursor is closed-source, locked behind subscriptions, and pricey for individuals or small teams.
That gap is why we started building our own open-source solution: Claude Context.
Claude Context is an open-source MCP plugin that brings semantic code search to Claude Code (and any other AI coding agent that speaks MCP). Instead of brute-forcing your repo with grep, it integrates vector databases with embedding models to give LLMs deep, targeted context from your entire codebase. The result: sharper retrieval, less token waste, and a far better developer experience.
Here is how we built it:
Technologies We Use
🔌 Interface Layer: MCP as the Universal Connector
We wanted this to work everywhere—not just Claude. MCP (Model Context Protocol) acts like the USB standard for LLMs, letting external tools plug in seamlessly. By packaging Claude Context as an MCP server, it works not only with Claude Code but also with Gemini CLI, Qwen Code, Cline, and even Cursor.
🗄️ Vector Database: Zilliz Cloud
For the backbone, we chose Zilliz Cloud (a fully managed service built on Milvus). It’s high-performance, cloud-native, elastic, and designed for AI workloads like codebase indexing. That means low-latency retrieval, near-infinite scale, and rock-solid reliability.
🧩 Embedding Models: Flexible by DesignDifferent teams have different needs, so Claude Context supports multiple embedding providers out of the box:
OpenAI embeddings for stability and wide adoption.
Voyage embeddings for code-specialized performance.
Ollama for privacy-first local deployments.
Additional models can be slotted in as requirements evolve.
💻 Language Choice: TypeScript
We debated Python vs. TypeScript. TypeScript won—not just for application-level compatibility (VSCode plugins, web tooling) but also because Claude Code and Gemini CLI themselves are TypeScript-based. That makes integration seamless and keeps the ecosystem coherent.
System Architecture
Claude Context follows a clean, layered design:
Core modules handle the heavy lifting: code parsing, chunking, indexing, retrieval, and synchronization.
User interface handles integrations—MCP servers, VSCode plugins, or other adapters.
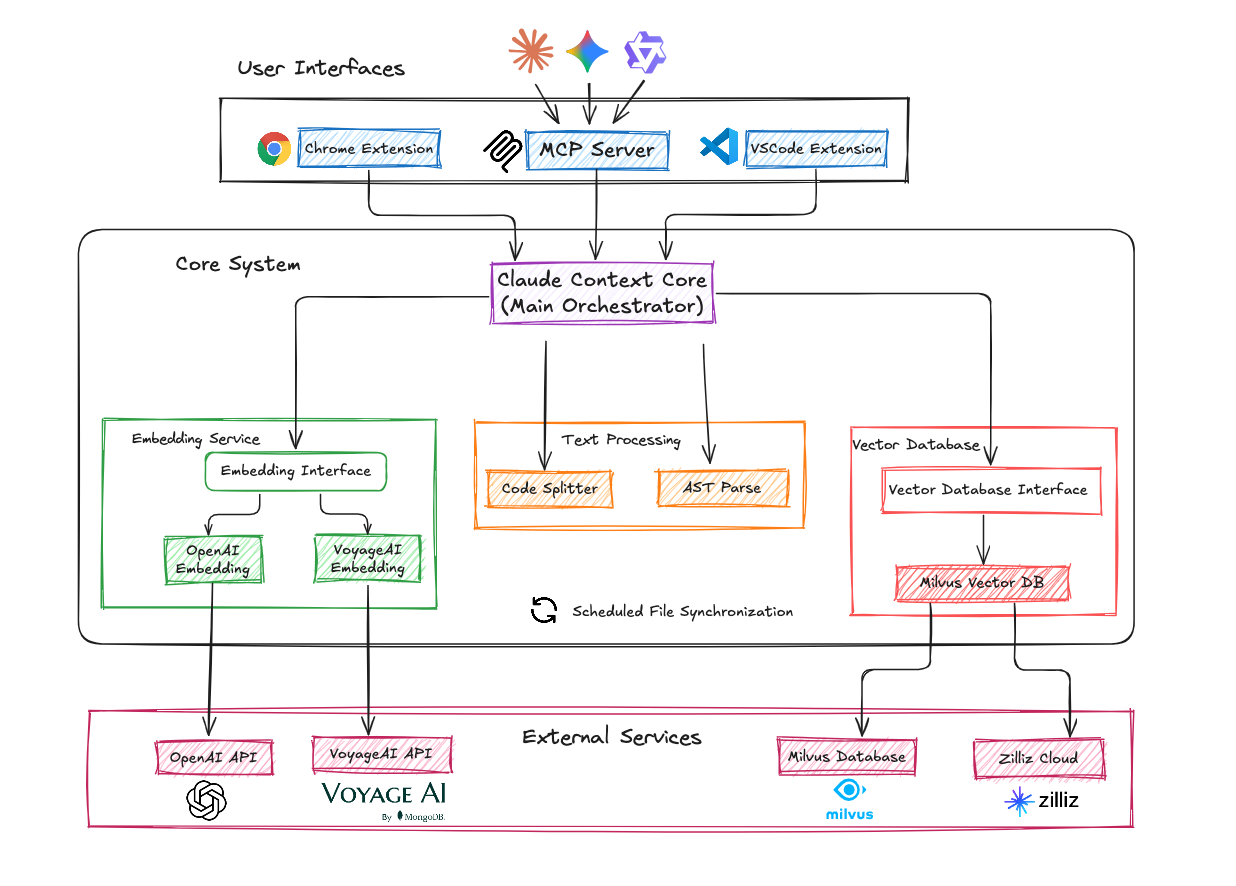
This separation keeps the core engine reusable across different environments while letting integrations evolve quickly as new AI coding assistants emerge.
Core Module Implementation
The core modules form the foundation of the entire system. They abstract vector databases, embedding models, and other components into composable modules that create a Context object, enabling different vector databases and embedding models for different scenarios.
import { Context, MilvusVectorDatabase, OpenAIEmbedding } from '@zilliz/claude-context-core';
// Initialize embedding provider
const embedding = new OpenAIEmbedding(...);
// Initialize vector database
const vectorDatabase = new MilvusVectorDatabase(...);
// Create context instance
const context = new Context({embedding, vectorDatabase});
// Index your codebase with progress tracking
const stats = await context.indexCodebase('./your-project');
// Perform semantic search
const results = await context.semanticSearch('./your-project', 'vector database operations');
Solving Key Technical Challenges
Building Claude Context wasn’t just about wiring up embeddings and a vector DB. The real work came in solving the hard problems that make or break code indexing at scale. Here’s how we approached the three biggest challenges:
Challenge 1: Intelligent Code Chunking
Code can’t just be split by lines or characters. That creates messy, incomplete fragments and strips away the logic that makes code understandable.
We solved this with two complementary strategies:
AST-Based Chunking (Primary Strategy)
This is the default approach, using tree-sitter parsers to understand code syntax structure and split along semantic boundaries: functions, classes, methods. This delivers:
Syntax completeness – no chopped functions or broken declarations.
Logical coherence – related logic stays together for better semantic retrieval.
Multi-language support – works across JS, Python, Java, Go, and more via tree-sitter grammars.
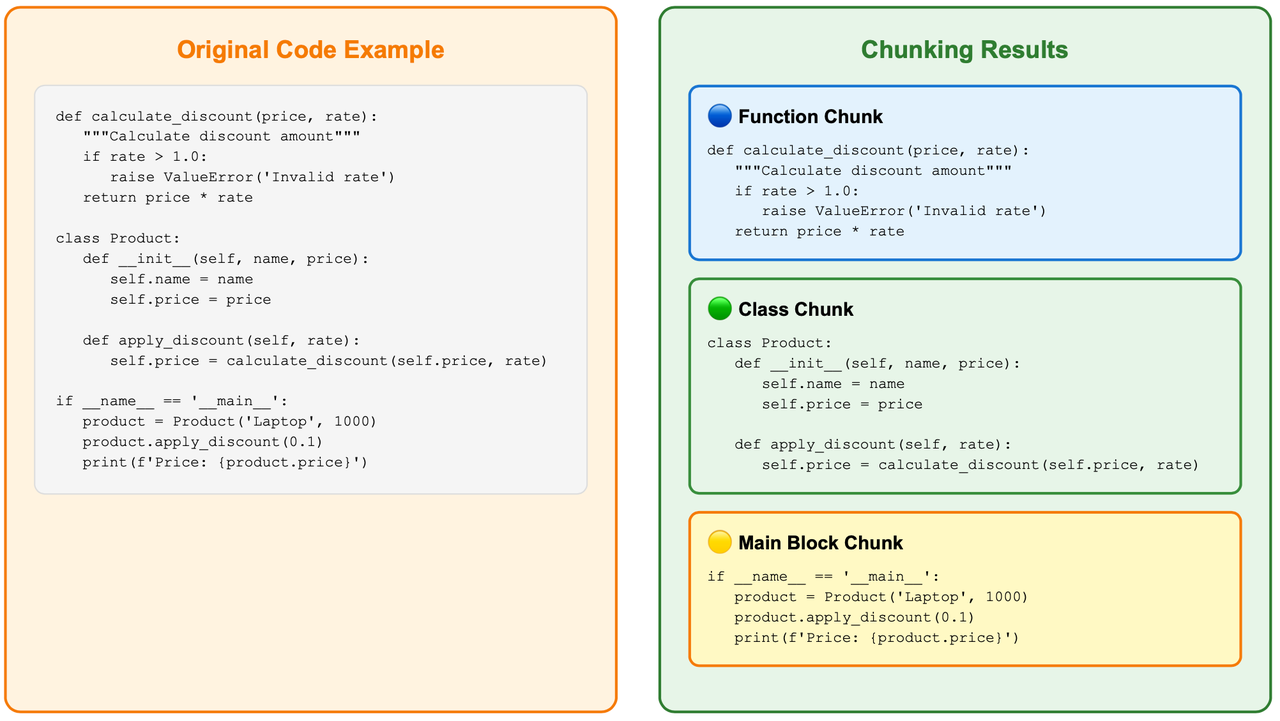
LangChain Text Splitting (Fallback Strategy)
For languages that AST can’t parse or when parsing fails, LangChain’s RecursiveCharacterTextSplitter provides a reliable backup.
// Use recursive character splitting to maintain code structure
const splitter = RecursiveCharacterTextSplitter.fromLanguage(language, {
chunkSize: 1000,
chunkOverlap: 200,
});
It’s less “intelligent” than AST, but highly reliable—ensuring developers are never left stranded. Together, these two strategies balance semantic richness with universal applicability.
Challenge 2: Handling Code Changes Efficiently
Managing code changes represents one of the biggest challenges in code indexing systems. Re-indexing entire projects for minor file modifications would be completely impractical.
To solve this problem, we built the Merkle Tree-based synchronization mechanism.
Merkle Trees: The Foundation of Change Detection
Merkle Trees create a hierarchical “fingerprint” system where each file has its own hash fingerprint, folders have fingerprints based on their contents, and everything culminates in a unique root node fingerprint for the entire codebase.
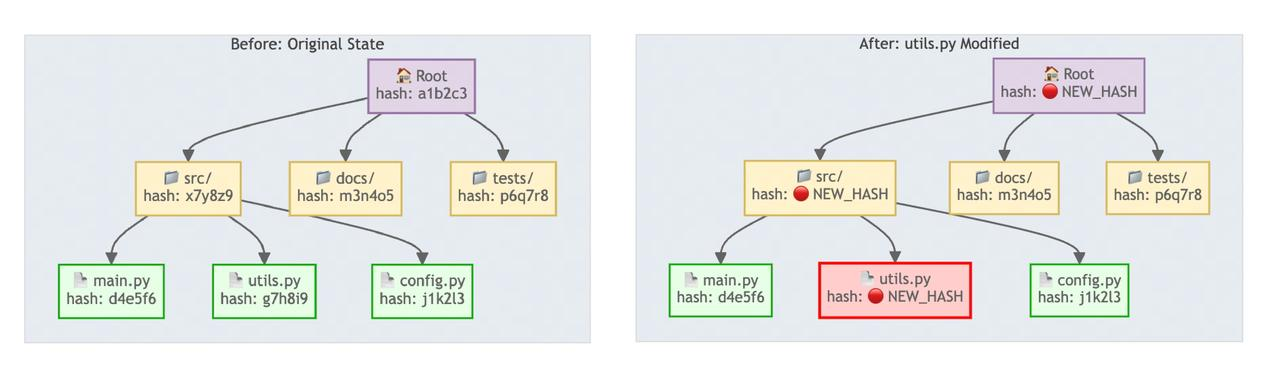
When file content changes, the hash fingerprints cascade upward through each layer to the root node. This enables rapid change detection by comparing hash fingerprints layer by layer from the root downward, quickly identifying and localizing file modifications without full project re-indexing.
The system performs handshake synchronization checks every 5 minutes using a streamlined three-phase process:
Phase 1: Lightning-Fast Detection calculates the entire codebase’s Merkle root hash and compares it with the previous snapshot. Identical root hashes mean no changes occurred—the system skips all processing in milliseconds.
Phase 2: Precise Comparison triggers when root hashes differ, performing detailed file-level analysis to identify exactly which files were added, deleted, or modified.
Phase 3: Incremental Updates recalculates vectors only for changed files and updates the vector database accordingly, maximizing efficiency.
Local Snapshot Management
All synchronization state persists locally in the user’s ~/.context/merkle/ directory. Each codebase maintains its own independent snapshot file containing file hash tables and serialized Merkle tree data, ensuring accurate state recovery even after program restarts.
This design delivers obvious benefits: most checks complete in milliseconds when no changes exist, only genuinely modified files trigger reprocessing (avoiding massive computational waste), and state recovery works flawlessly across program sessions.
From a user experience perspective, modifying a single function triggers re-indexing for only that file, not the entire project, dramatically improving development efficiency.
Challenge 3: Designing the MCP Interface
Even the smartest indexing engine is useless without a clean developer-facing interface. MCP was the obvious choice, but it introduced unique challenges:
🔹 Tool Design: Keep It Simple
The MCP module serves as the user-facing interface, making user experience the top priority.
Tool design starts with abstracting standard codebase indexing and search operations into two core tools: index_codebase for indexing codebases and search_code for searching code.
This raises an important question: what additional tools are necessary?
The tool count requires careful balance—too many tools create cognitive overhead and confuse LLM tool selection, while too few might miss essential functionality.
Working backward from real-world use cases helps answer this question.
Addressing Background Processing Challenges
Large codebases can take considerable time to index. The naive approach of synchronously waiting for completion forces users to wait several minutes, which is simply unacceptable. Asynchronous background processing becomes essential, but MCP doesn’t natively support this pattern.
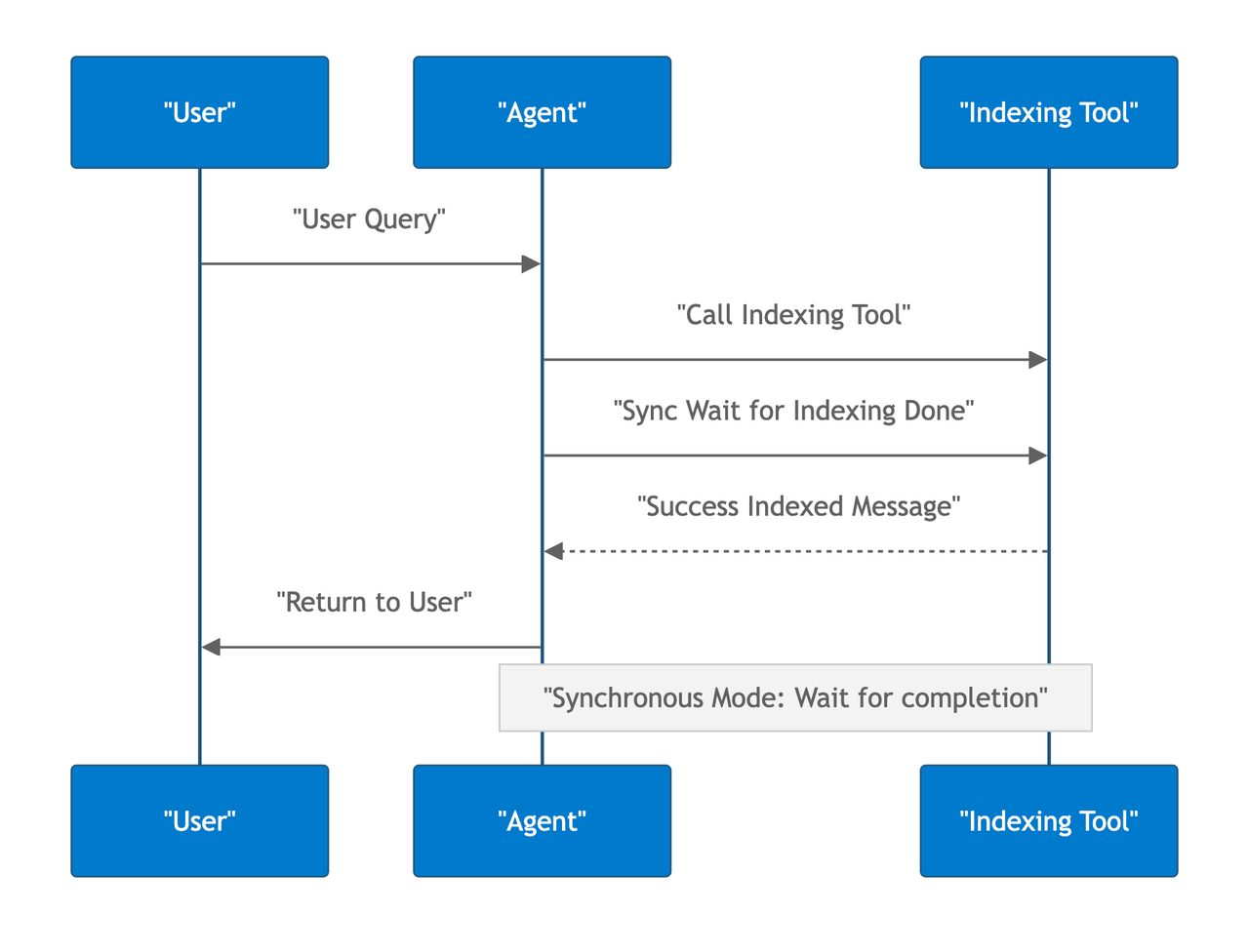 8.png
8.png
Our MCP server runs a background process within the MCP server to handle indexing while immediately returning startup messages to users, allowing them to continue working.
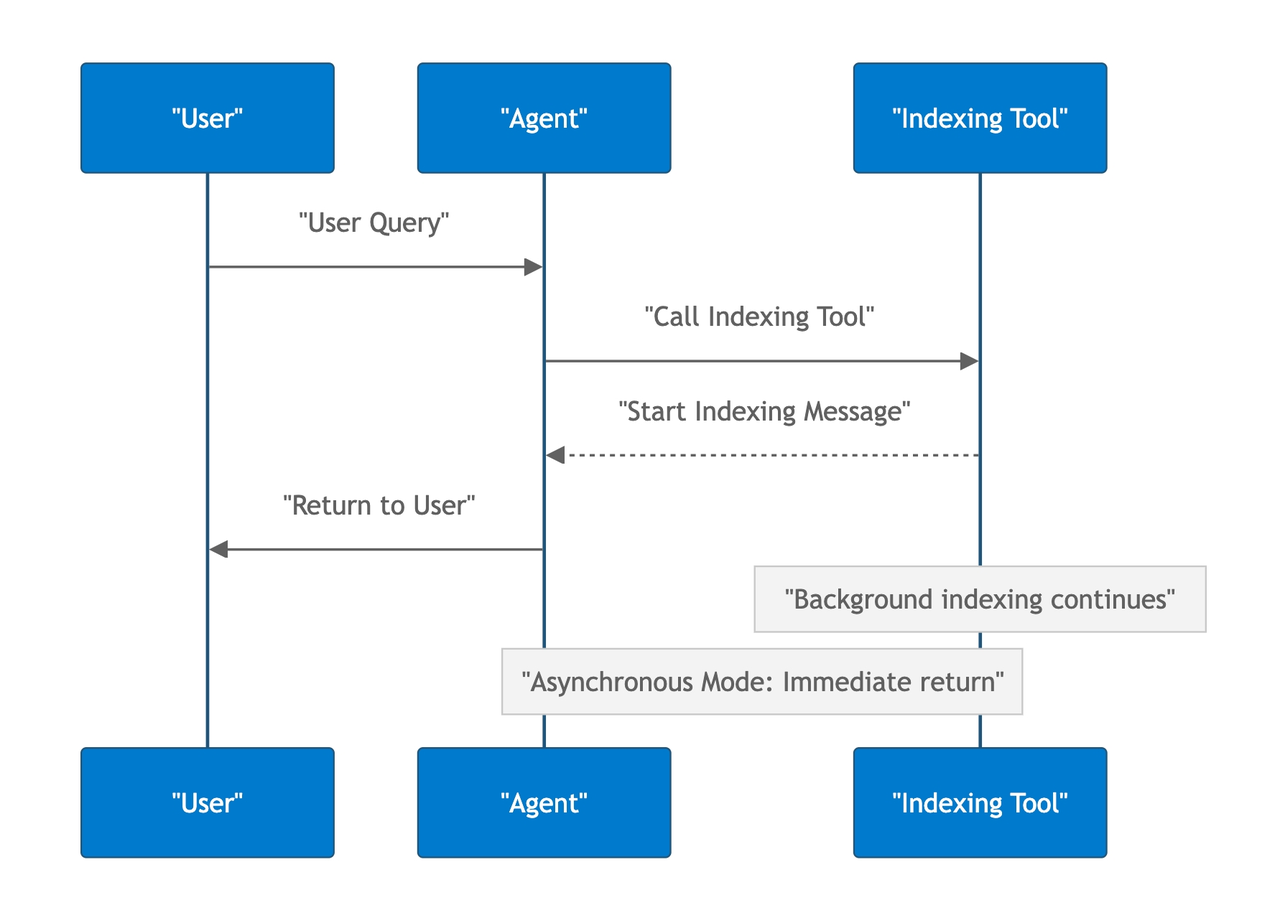 9.png
9.png
This creates a new challenge: how do users track indexing progress?
A dedicated tool for querying indexing progress or status solves this elegantly. The background indexing process asynchronously caches progress information, enabling users to check completion percentages, success status, or failure conditions at any time. Additionally, a manual index clearing tool handles situations where users need to reset inaccurate indexes or restart the indexing process.
Final Tool Design:
index_codebase - Index codebase
search_code - Search code
get_indexing_status - Query indexing status
clear_index - Clear index
Four tools that strike the perfect balance between simplicity and functionality.
🔹 Environment Variable Management
Environment variable management often gets overlooked despite significantly impacting user experience. Requiring separate API key configuration for every MCP Client would force users to configure credentials multiple times when switching between Claude Code and Gemini CLI.
A global configuration approach eliminates this friction by creating a ~/.context/.env file in the user’s home directory:
# ~/.context/.env
OPENAI_API_KEY=your-api-key-here
MILVUS_TOKEN=your-milvus-token
This approach delivers clear benefits: users configure once and use everywhere across all MCP clients, all configurations centralize in a single location for easy maintenance, and sensitive API keys don’t scatter across multiple configuration files.
We also implements a three-tier priority hierarchy: process environment variables take highest priority, global configuration files have medium priority, and default values serve as fallbacks.
This design offers tremendous flexibility: developers can use environment variables for temporary testing overrides, production environments can inject sensitive configurations through system environment variables for enhanced security, and users configure once to work seamlessly across Claude Code, Gemini CLI, and other tools.
At this point, the MCP server’s core architecture is complete, spanning code parsing and vector storage through intelligent retrieval and configuration management. Every component has been carefully designed and optimized to create a system that’s both powerful and user-friendly.
Hands-on Testing
So how does Claude Context actually perform in practice? I tested it against the exact same bug-hunting scenario that initially left me frustrated.
Installation was just one command before launching Claude Code:
claude mcp add claude-context -e OPENAI_API_KEY=your-openai-api-key -e MILVUS_TOKEN=your-zilliz-cloud-api-key -- npx @zilliz/claude-context-mcp@latest
Once my codebase was indexed, I gave Claude Code the same bug description that had previously sent it on a five-minute grep-powered goose chase. This time, through claude-context MCP calls, it immediately pinpointed the exact file and line number, complete with an explanation of the issue.
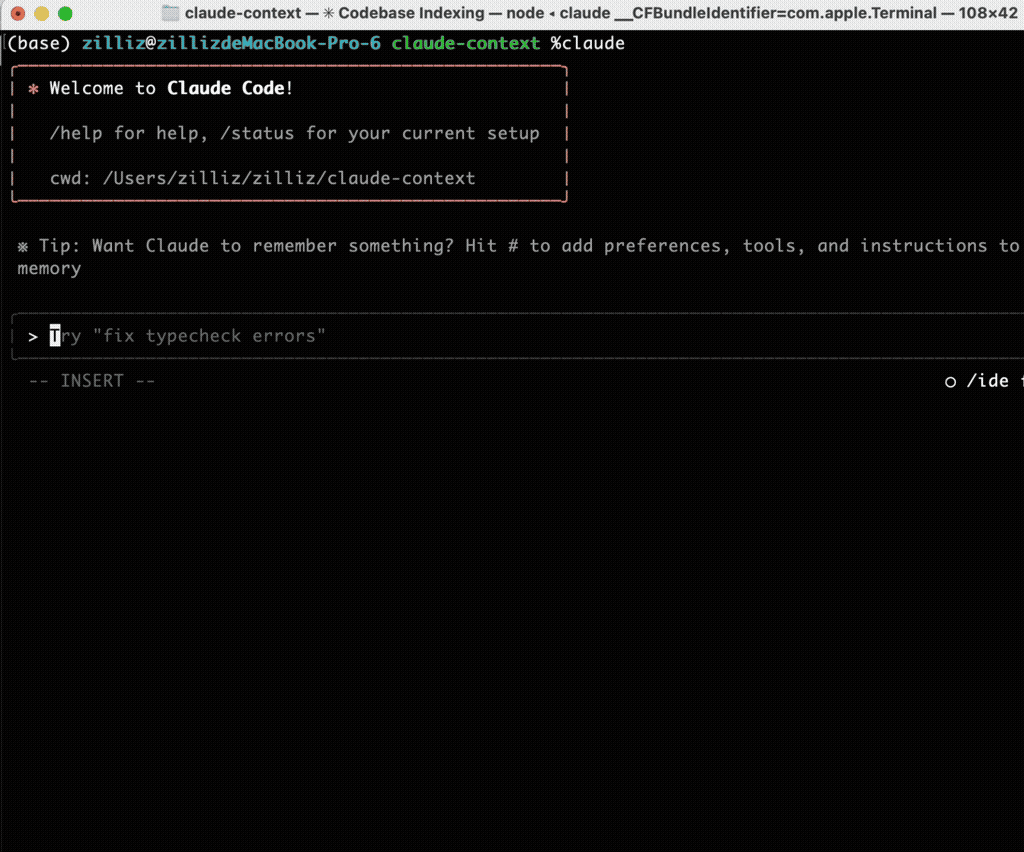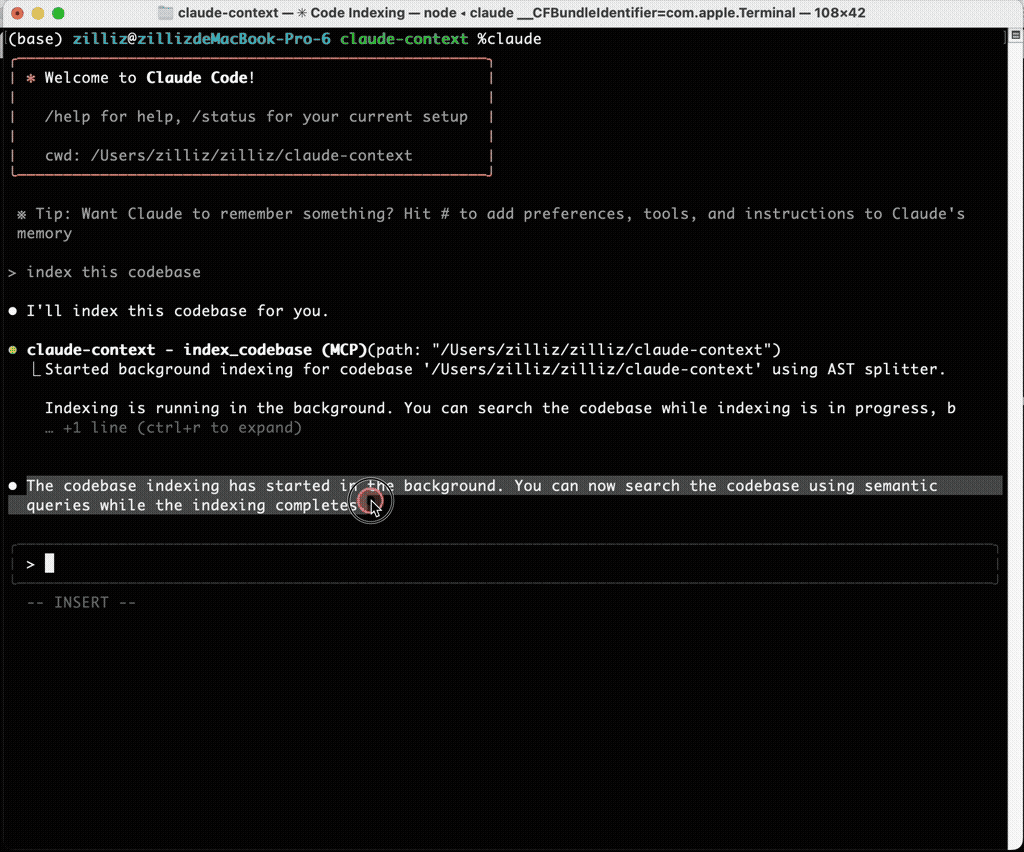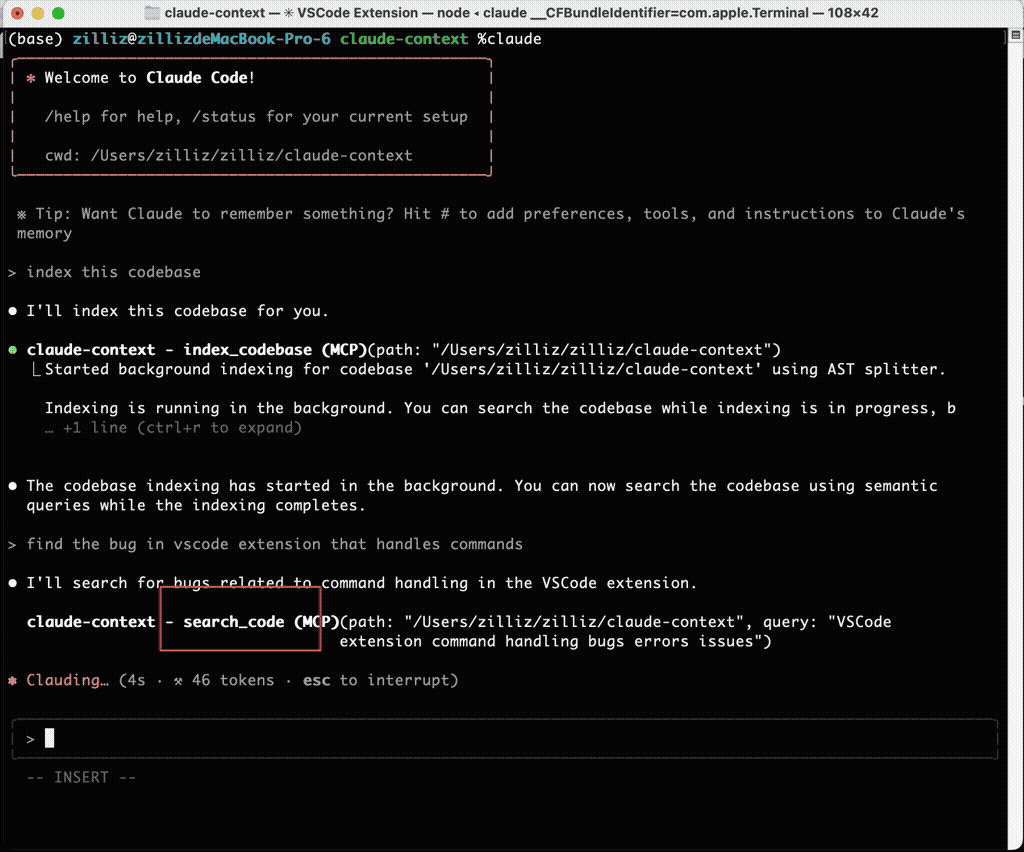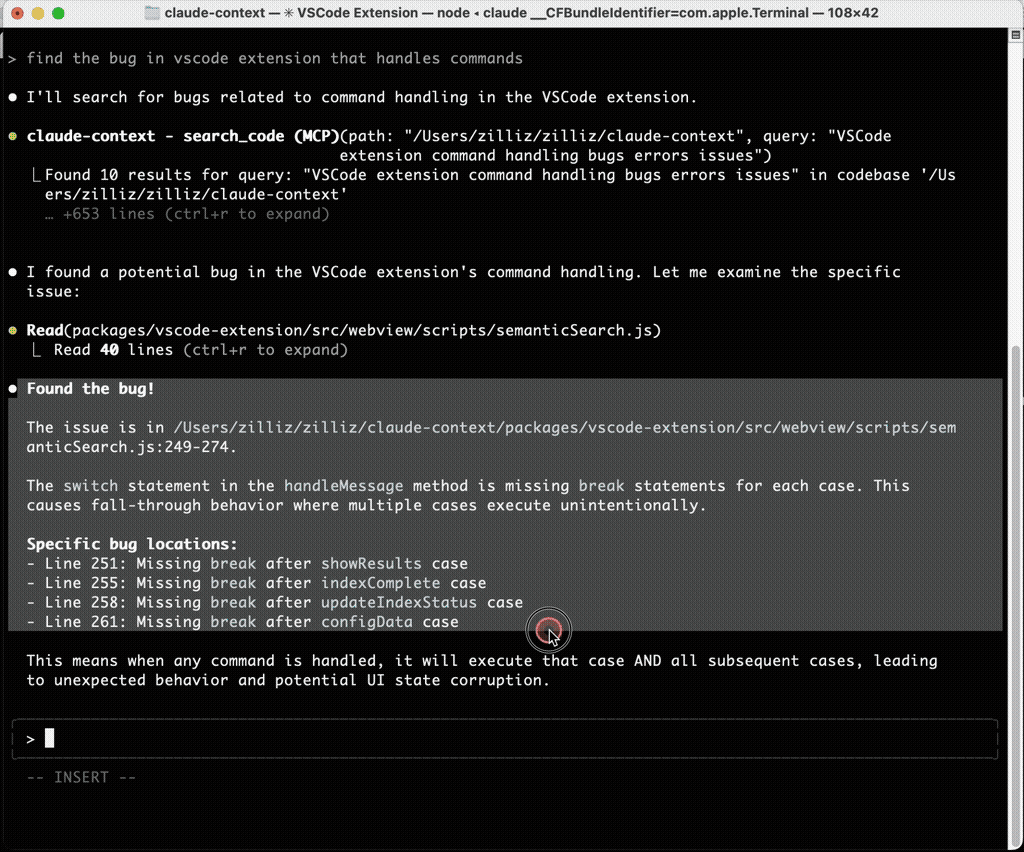
The difference wasn’t subtle—it was night and day.
And it wasn’t just bug hunting. With Claude Context integrated, Claude Code consistently produced higher-quality results across:
Issue resolution
Code refactoring
Duplicate code detection
Comprehensive testing
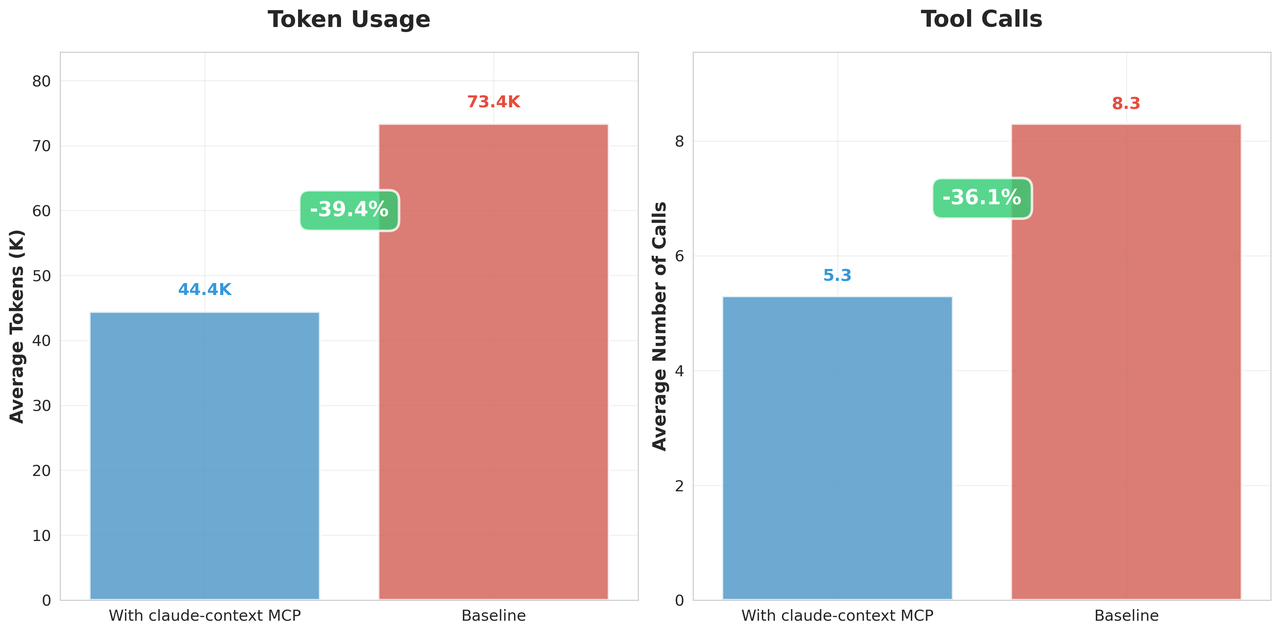
The performance boost shows up in the numbers, too. In side-by-side testing:
Token usage dropped by over 40%, without any loss in recall.
That translates directly into lower API costs and faster responses.
Alternatively, with the same budget, Claude Context delivered far more accurate retrievals.
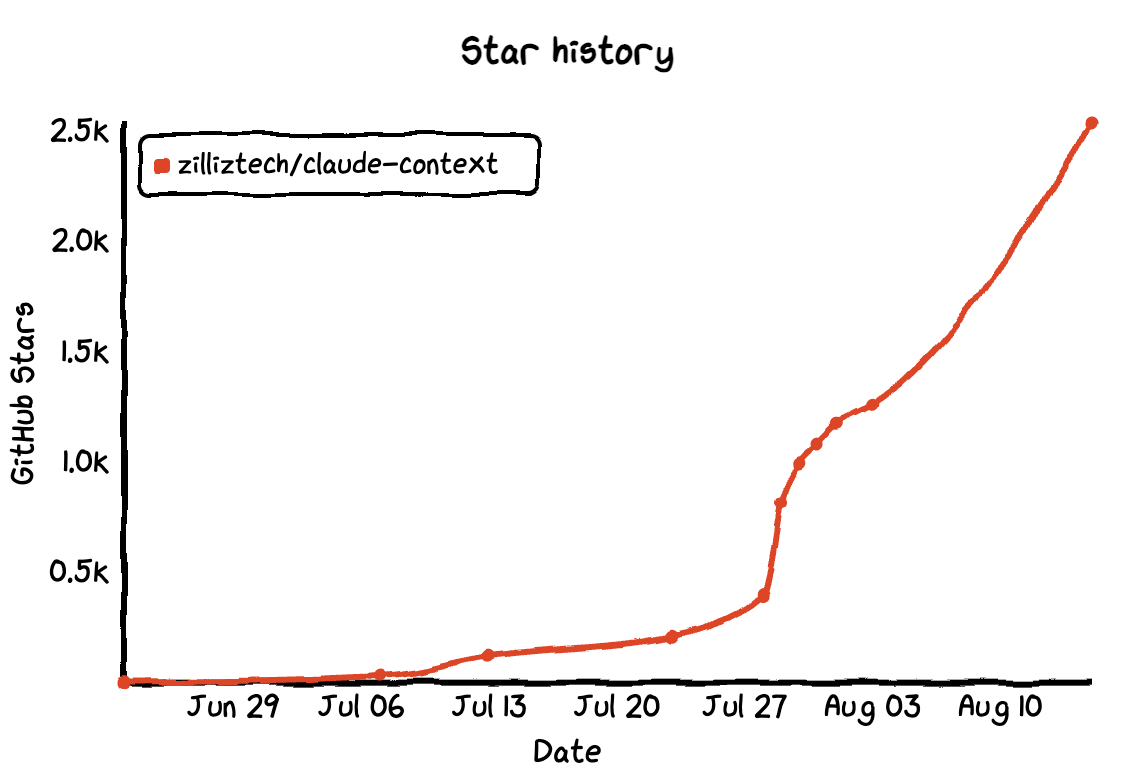
We have open-sourced Claude Context on GitHub, and it has earned 2.6K+ stars already. Thank you all for your support and likes.
You can try it yourself:
Detailed benchmarks and testing methodology are available in the repo—we’d love your feedback.
Looking Forward
What started as a frustration with grep in Claude Code has grown into a solid solution: Claude Context—an open-source MCP plugin that brings semantic, vector-powered search to Claude Code and other coding assistants. The message is simple: developers don’t have to settle for inefficient AI tooling. With RAG and vector retrieval, you can debug faster, cut token costs by 40%, and finally get AI assistance that truly understands your codebase.
And this isn’t limited to Claude Code. Because Claude Context is built on open standards, the same approach works seamlessly with Gemini CLI, Qwen Code, Cursor, Cline, and beyond. No more being locked into vendor trade-offs that prioritize simplicity over performance.
We’d love for you to be part of that future:
Try Claude Context: it is open-source and totally free
Contribute to its development
Or build your own solution using Claude Context
👉 Share your feedback, ask questions, or get help by joining our Discord community.
- What’s Wrong with Claude Code’s Grep-Only Code Search?
- Claude Code vs Cursor: Why the Latter Has Better Code Context
- Claude Context: an Open-Source Project for Adding Semantic Code Search to Claude Code
- Technologies We Use
- System Architecture
- Core Module Implementation
- Solving Key Technical Challenges
- Challenge 1: Intelligent Code Chunking
- Challenge 2: Handling Code Changes Efficiently
- Challenge 3: Designing the MCP Interface
- Hands-on Testing
- Looking Forward
On This Page
Try Managed Milvus for Free
Zilliz Cloud is hassle-free, powered by Milvus and 10x faster.
Get StartedLike the article? Spread the word



