Harness Engineering: The Execution Layer AI Agents Actually Need
Mitchell Hashimoto built HashiCorp and co-created Terraform. In February 2026, he published a blog post describing a habit he’d developed while working with AI agents: every time an agent made a mistake, he engineered a permanent fix into the agent’s environment. He called it “engineering the harness.” Within weeks, OpenAI and Anthropic published engineering articles expanding on the idea. The term Harness Engineering had arrived.
It resonated because it names a problem every engineer building AI agents has already hit. Prompt engineering gets you better single-turn outputs. Context engineering manages what the model sees. But neither addresses what happens when an agent runs autonomously for hours, making hundreds of decisions without supervision. That’s the gap Harness Engineering fills — and it almost always depends on hybrid search (hybrid full-text and semantic search) to work.
What Is Harness Engineering?
Harness Engineering is the discipline of designing the execution environment around an autonomous AI agent. It defines which tools the agent can call, where it gets information, how it validates its own decisions, and when it should stop.
To understand why it matters, consider three layers of AI agent development:
| Layer | What It Optimizes | Scope | Example |
|---|---|---|---|
| Prompt Engineering | What you say to the model | Single exchange | Few-shot examples, chain-of-thought prompts |
| Context Engineering | What the model can see | Context window | Document retrieval, history compression |
| Harness Engineering | The world the agent operates in | Multi-hour autonomous execution | Tools, validation logic, architectural constraints |
Prompt Engineering optimizes the quality of a single exchange — phrasing, structure, examples. One conversation, one output.
Context Engineering manages how much information the model can see at once — which documents to retrieve, how to compress history, what fits in the context window and what gets dropped.
Harness Engineering builds the world the agent operates in. Tools, knowledge sources, validation logic, architectural constraints — everything that determines whether an agent can run reliably across hundreds of decisions without human supervision.
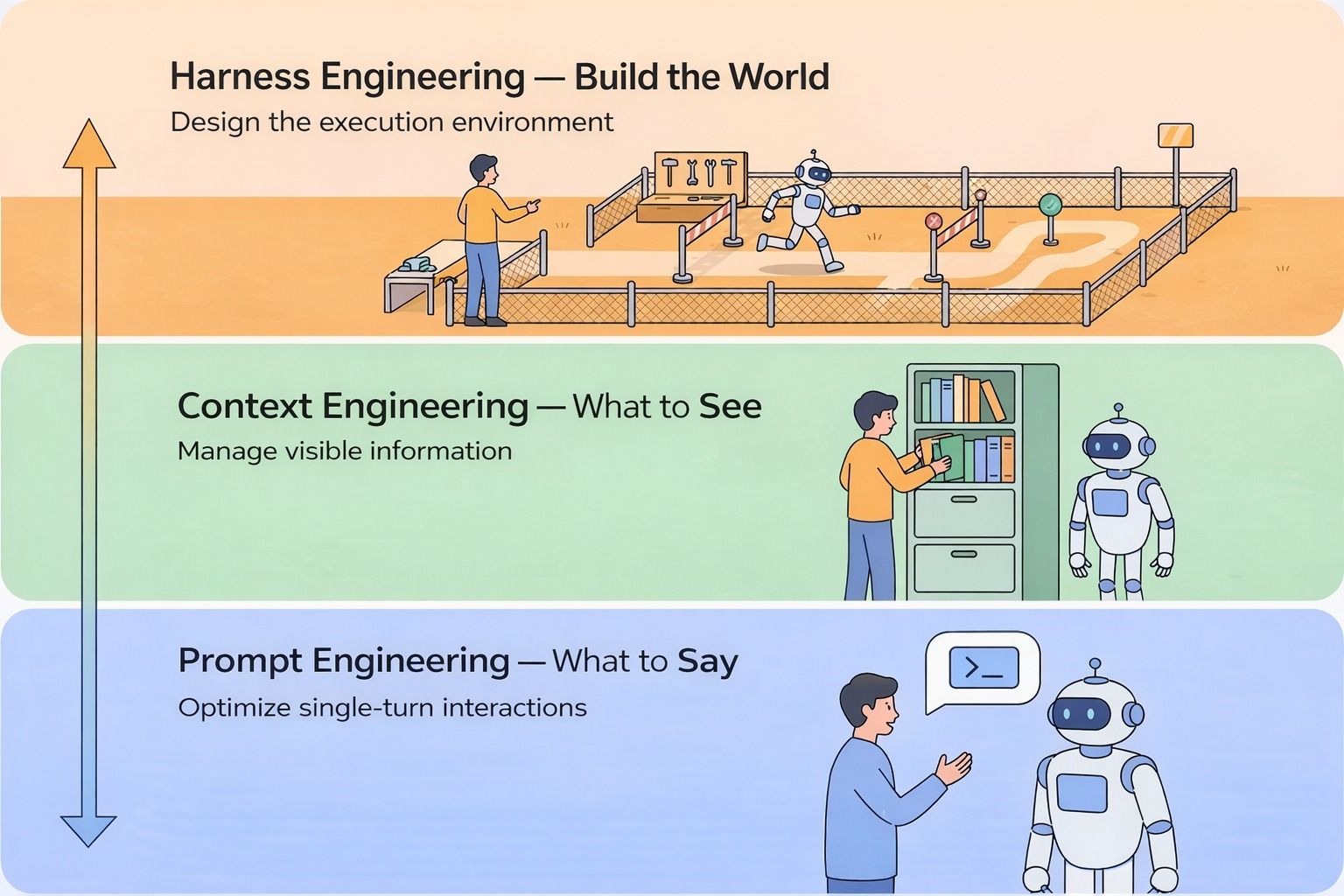 Three layers of AI agent development: Prompt Engineering optimizes what you say, Context Engineering manages what the model sees, and Harness Engineering designs the execution environment
Three layers of AI agent development: Prompt Engineering optimizes what you say, Context Engineering manages what the model sees, and Harness Engineering designs the execution environment
The first two layers shape the quality of a single turn. The third shapes whether an agent can operate for hours without you watching.
These aren’t competing approaches. They’re a progression. As agent capability grows, the same team moves through all three — often within a single project.
How OpenAI Used Harness Engineering to Build a Million-Line Codebase and Lessons They Learnt
OpenAI ran an internal experiment that puts Harness Engineering in concrete terms. They described it in their engineering blog post, “Harness Engineering: Leveraging Codex in an Agent-First World”. A three-person team started with an empty repository in late August 2025. For five months, they wrote no code themselves — every line was generated by Codex, OpenAI’s AI-powered coding agent. The result: one million lines of production code and 1,500 merged pull requests.
The interesting part isn’t the output. It’s the four problems they hit and the harness-layer solutions they built.
Problem 1: No Shared Understanding of the Codebase
What abstraction layer should the agent use? What are the naming conventions? Where did last week’s architecture discussion land? Without answers, the agent guessed — and guessed wrong — repeatedly.
The first instinct was a single AGENTS.md file containing every convention, rule, and historical decision. It failed for four reasons. Context is scarce, and a bloated instruction file crowded out the actual task. When everything is marked important, nothing is. Documentation rots — rules from week two become wrong by week eight. And a flat document can’t be mechanically verified.
The fix: shrink AGENTS.md to 100 lines. Not rules — a map. It points to a structured docs/ directory containing design decisions, execution plans, product specs, and reference docs. Linters and CI verify that cross-links stay intact. The agent navigates to exactly what it needs.
The underlying principle: if something isn’t in context at runtime, it doesn’t exist for the agent.
Problem 2: Human QA Couldn’t Keep Pace with Agent Output
The team plugged Chrome DevTools Protocol into Codex. The agent could screenshot UI paths, observe runtime events, and query logs with LogQL and metrics with PromQL. They set a concrete threshold: a service had to start in under 800 milliseconds before a task was considered complete. Codex tasks ran for over six hours at a stretch — typically while engineers slept.
Problem 3: Architectural Drift Without Constraints
Without guardrails, the agent reproduced whatever patterns it found in the repo — including bad ones.
The fix: strict layered architecture with a single enforced dependency direction — Types → Config → Repo → Service → Runtime → UI. Custom linters enforced these rules mechanically, with error messages that included the fix instruction inline.
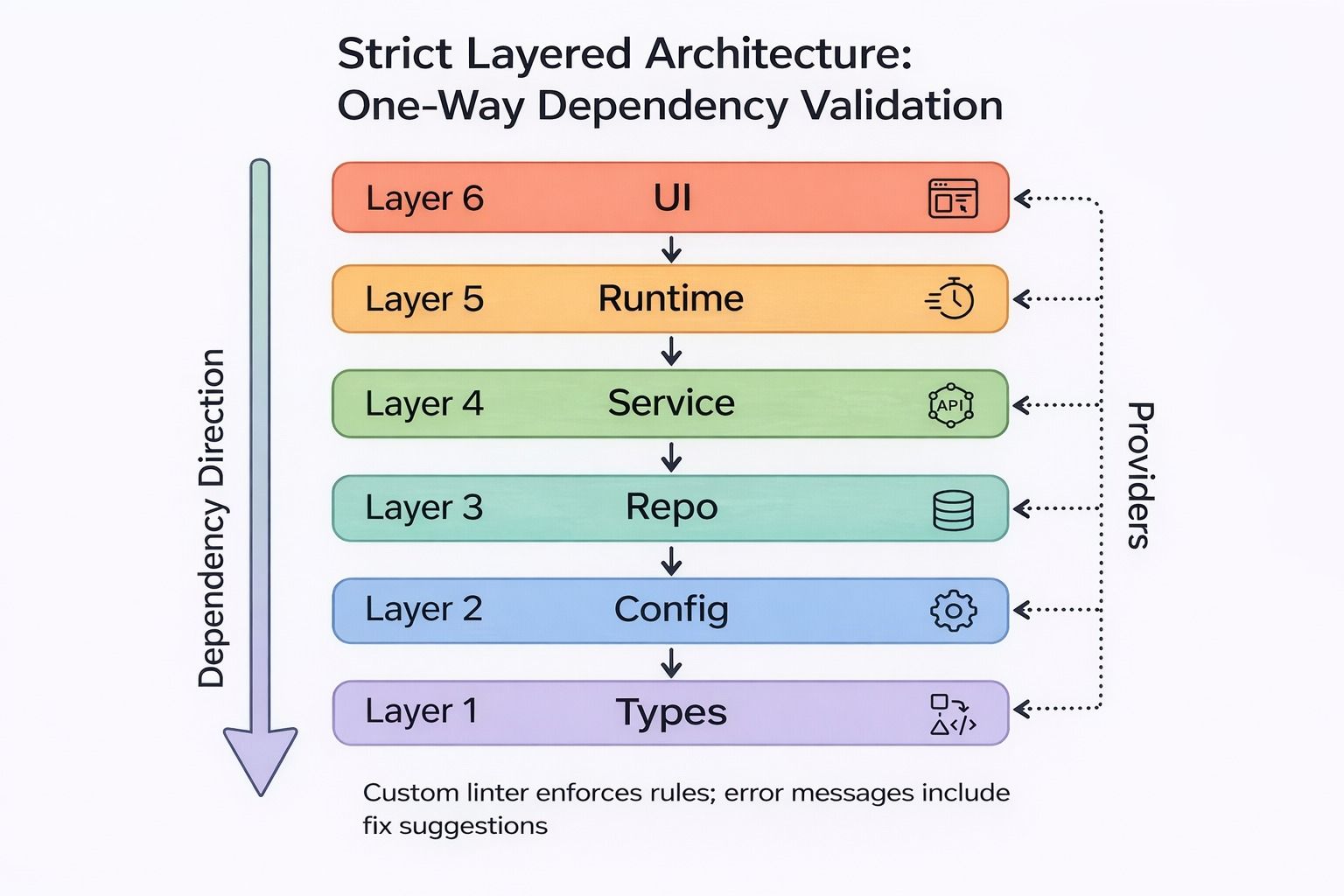 Strict layered architecture with one-way dependency validation: Types at the base, UI at the top, custom linters enforce rules with inline fix suggestions
Strict layered architecture with one-way dependency validation: Types at the base, UI at the top, custom linters enforce rules with inline fix suggestions
In a human team, this constraint usually arrives when a company scales to hundreds of engineers. For a coding agent, it’s a prerequisite from day one. The faster an agent moves without constraints, the worse the architectural drift.
Problem 4: Silent Technical Debt
The solution: encode the project’s core principles into the repository, then run background Codex tasks on a schedule to scan for deviations and submit refactoring PRs. Most merged automatically within a minute — small continuous payments rather than periodic reckoning.
Why AI Agents Can’t Grade Their Own Work
OpenAI’s experiment proved Harness Engineering works. But separate research exposed a failure mode inside it: agents are systematically bad at evaluating their own output.
The problem appears in two forms.
Context anxiety. As the context window fills, agents begin wrapping up tasks prematurely — not because the work is done, but because they sense the window limit approaching. Cognition, the team behind the AI coding agent Devin, documented this behavior while rebuilding Devin for Claude Sonnet 4.5: the model became aware of its own context window and started taking shortcuts well before actually running out of room.
Their fix was pure harness engineering. They enabled the 1M-token context beta but capped actual usage at 200K tokens — tricking the model into believing it had ample runway. The anxiety vanished. No model change required; just a smarter environment.
The most common general mitigation is compaction: summarize history and let the same agent continue with compressed context. This preserves continuity but doesn’t eliminate the underlying behavior. An alternative is context reset: clear the window, spin up a fresh instance, and hand off state through a structured artifact. This removes the anxiety trigger entirely but demands a complete handoff document — gaps in the artifact mean gaps in the new agent’s understanding.
Self-evaluation bias. When agents assess their own output, they score it high. Even on tasks with objective pass/fail criteria, the agent spots a problem, talks itself into believing it’s not serious, and approves work that should fail.
The fix borrows from GANs (Generative Adversarial Networks): separate the generator from the evaluator completely. In a GAN, two neural networks compete — one generates, one judges — and that adversarial tension forces quality up. The same dynamic applies to multi-agent systems.
Anthropic tested this with a three-agent harness — Planner, Generator, Evaluator — against a solo agent on the task of building a 2D retro game engine. They describe the full experiment in “Harness Design for Long-Running Application Development” (Anthropic, 2026). The Planner expands a short prompt into a full product spec, deliberately leaving implementation details unspecified — early over-specification cascades into downstream errors. The Generator implements features in sprints, but before writing code, it signs a sprint contract with the Evaluator: a shared definition of “done.” The Evaluator uses Playwright (Microsoft’s open-source browser automation framework) to click through the application like a real user, testing UI, API, and database behavior. If anything fails, the sprint fails.
The solo agent produced a game that technically launched, but entity-to-runtime connections were broken at the code level — discoverable only by reading the source. The three-agent harness produced a playable game with AI-assisted level generation, sprite animation, and sound effects.
 Comparison of solo agent versus three-agent harness: solo agent ran 20 minutes at nine dollars with broken core functionality, while the full harness ran 6 hours at two hundred dollars producing a fully functional game with AI-assisted features
Comparison of solo agent versus three-agent harness: solo agent ran 20 minutes at nine dollars with broken core functionality, while the full harness ran 6 hours at two hundred dollars producing a fully functional game with AI-assisted features
The three-agent architecture cost roughly 20x more. The output crossed from unusable to usable. That’s the core trade Harness Engineering makes: structural overhead in exchange for reliability.
The Retrieval Problem Inside Every Agent Harness
Both patterns — the structured docs/ system and the Generator/Evaluator sprint cycle — share a silent dependency: the agent must find the right information from a live, evolving knowledge base when it needs it.
This is harder than it looks. Take a concrete example: the Generator is executing Sprint 3, implementing user authentication. Before writing code, it needs two kinds of information.
First, a semantic search query: what are this product’s design principles around user sessions? The relevant document might use “session management” or “access control” — not “user authentication.” Without semantic understanding, retrieval misses it.
Second, an exact-match query: which documents reference the validateToken function? A function name is an arbitrary string with no semantic meaning. Embedding-based retrieval can’t reliably find it. Only keyword matching works.
These two queries happen simultaneously. They can’t be separated into sequential steps.
Pure vector search fails on exact match. Traditional BM25 fails on semantic queries and can’t predict which vocabulary a document will use. Before Milvus 2.5, the only option was two parallel retrieval systems — a vector index and a full-text index — running concurrently at query time with custom result-fusion logic. For a live docs/ repository with continuous updates, both indexes had to stay in sync: every document change triggered reindexing in two places, with the constant risk of inconsistency.
How Milvus 2.6 Solves Agent Retrieval with a Single Hybrid Pipeline
Milvus is an open-source vector database designed for AI workloads. Milvus 2.6’s Sparse-BM25 collapses the dual-pipeline retrieval problem into a single system.
At ingest, Milvus generates two representations simultaneously: a dense embedding for semantic retrieval and a TF-encoded sparse vector for BM25 scoring. Global IDF statistics update automatically as documents are added or removed — no manual reindex triggers. At query time, a natural-language input generates both query vector types internally. Reciprocal Rank Fusion (RRF) merges the ranked results, and the caller receives a single unified result set.
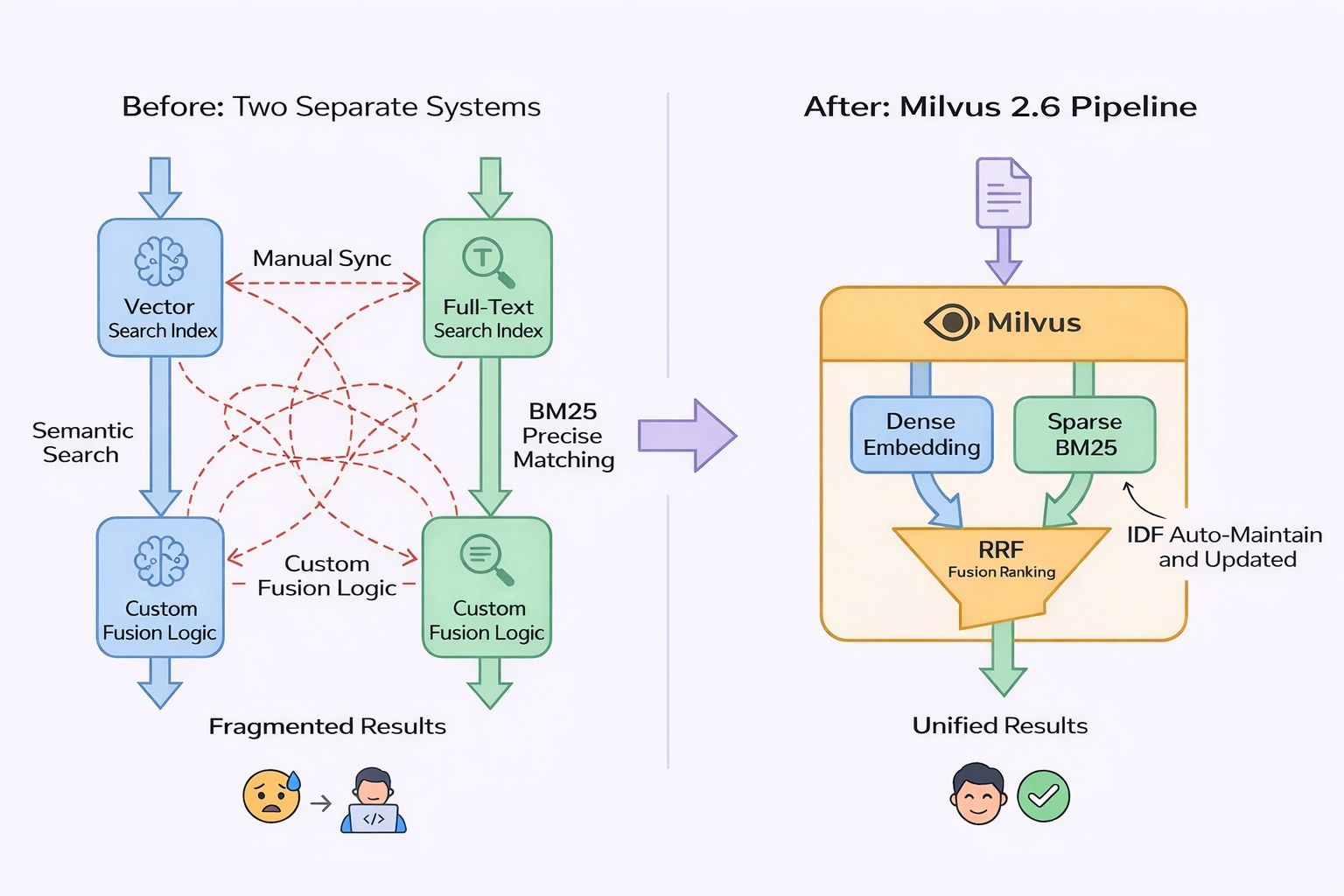 Before and after: two separate systems with manual sync, fragmented results, and custom fusion logic versus Milvus 2.6 single pipeline with dense embedding, Sparse BM25, RRF fusion, and automatic IDF maintenance producing unified results
Before and after: two separate systems with manual sync, fragmented results, and custom fusion logic versus Milvus 2.6 single pipeline with dense embedding, Sparse BM25, RRF fusion, and automatic IDF maintenance producing unified results
One interface. One index to maintain.
On the BEIR benchmark — a standard evaluation suite covering 18 heterogeneous retrieval datasets — Milvus achieves 3–4x higher throughput than Elasticsearch at equivalent recall, with up to 7x QPS improvement on specific workloads. For the sprint scenario, a single query finds both the session design principle (semantic path) and every document mentioning validateToken (exact path). The docs/ repository updates continuously; BM25 IDF maintenance means a newly written document participates in the next query’s scoring without any batch rebuild.
This is the retrieval layer built for exactly this class of problem. When an agent harness needs to search a living knowledge base — code documentation, design decisions, sprint history — single-pipeline hybrid search isn’t a nice-to-have. It’s what makes the rest of the harness work.
The Best Harness Components Are Designed to Be Deleted
Every component in a harness encodes an assumption about model limitations. Sprint decomposition was necessary when models lost coherence on long tasks. Context reset was necessary when models experienced anxiety near the window limit. Evaluator agents became necessary when self-evaluation bias was unmanageable.
These assumptions expire. Cognition’s context-window trick may become unnecessary as models develop genuine long-context stamina. As models continue to improve, other components will become unnecessary overhead that slows agents down without adding reliability.
Harness Engineering isn’t a fixed architecture. It’s a system recalibrated with every new model release. The first question after any major upgrade isn’t “what can I add?” It’s “what can I remove?”
The same logic applies to retrieval. As models handle longer contexts more reliably, chunking strategies and retrieval timing will shift. Information that needs careful fragmentation today may be ingestible as full pages tomorrow. The retrieval infrastructure adapts alongside the model.
Every component in a well-built harness is waiting to be made redundant by a smarter model. That’s not a problem. That’s the goal.
Get Started with Milvus
If you’re building agent infrastructure that needs hybrid retrieval — semantic and keyword search in one pipeline — here’s where to start:
- Read the Milvus 2.6 release notes for full details on Sparse-BM25, automatic IDF maintenance, and performance benchmarks.
- Join the Milvus community to ask questions and share what you’re building.
- Book a free Milvus Office Hours session to walk through your use case with a vector database expert.
- If you’d rather skip infrastructure setup, Zilliz Cloud (fully managed Milvus) offers a free tier to get started with $100 free credits upon registration with work email.
- Star us on GitHub: milvus-io/milvus — 43k+ stars and growing.
Frequently Asked Questions
What is harness engineering and how is it different from prompt engineering?
Prompt engineering optimizes what you say to a model in a single exchange — phrasing, structure, examples. Harness Engineering builds the execution environment around an autonomous AI agent: the tools it can call, the knowledge it can access, the validation logic that checks its work, and the constraints that prevent architectural drift. Prompt engineering shapes one conversation turn. Harness Engineering shapes whether an agent can operate reliably for hours across hundreds of decisions without human supervision.
Why do AI agents need both vector search and BM25 at the same time?
Agents must answer two fundamentally different retrieval queries simultaneously. Semantic queries — what are our design principles around user sessions? — require dense vector embeddings to match conceptually related content regardless of vocabulary. Exact-match queries — which documents reference the validateToken function? — require BM25 keyword scoring, because function names are arbitrary strings with no semantic meaning. A retrieval system that handles only one mode will systematically miss queries of the other type.
How does Milvus Sparse-BM25 work for agent knowledge retrieval?
At ingest, Milvus generates a dense embedding and a TF-encoded sparse vector for each document simultaneously. Global IDF statistics update in real time as the knowledge base changes — no manual reindexing required. At query time, both vector types are generated internally, Reciprocal Rank Fusion merges the ranked results, and the agent receives a single unified result set. The entire pipeline runs through one interface and one index — critical for continuously updated knowledge bases like a code documentation repository.
When should I add an evaluator agent to my agent harness?
Add a separate Evaluator when your Generator’s output quality cannot be verified by automated tests alone, or when self-evaluation bias has caused missed defects. The key principle: the Evaluator must be architecturally separate from the Generator — shared context reintroduces the same bias you’re trying to eliminate. The Evaluator should have access to runtime tools (browser automation, API calls, database queries) to test behavior, not just review code. Anthropic’s research found that this GAN-inspired separation moved output quality from “technically launches but broken” to “fully functional with features the solo agent never attempted.”
- What Is Harness Engineering?
- How OpenAI Used Harness Engineering to Build a Million-Line Codebase and Lessons They Learnt
- Why AI Agents Can't Grade Their Own Work
- The Retrieval Problem Inside Every Agent Harness
- How Milvus 2.6 Solves Agent Retrieval with a Single Hybrid Pipeline
- The Best Harness Components Are Designed to Be Deleted
- Get Started with Milvus
- Frequently Asked Questions
On This Page
Try Managed Milvus for Free
Zilliz Cloud is hassle-free, powered by Milvus and 10x faster.
Get StartedLike the article? Spread the word



