Multimodal Semantic Search with Images and Text
As humans, we interpret the world through our senses. We hear sounds, we see images, video, and text, often layered on top of each other. We understand the world through these multiple modalities and the relationship between them. For artificial intelligence to truly match or exceed human capabilities, it must develop this same ability to understand the world through multiple lenses simultaneously.
In this post and accompanying video (above) and notebook, we’ll showcase recent breakthroughs in models that can process both text and images together. We’ll demonstrate this by building a semantic search application that goes beyond simple keyword matching - it understands the relationship between what users are asking for and the visual content they’re searching through.
What makes this project particularly exciting is that it’s built entirely with open-source tools: the Milvus vector database, HuggingFace’s machine learning libraries, and a dataset of Amazon customer reviews. It’s remarkable to think that just a decade ago, building something like this would have required significant proprietary resources. Today, these powerful components are freely available and can be combined in innovative ways by anyone with the curiosity to experiment.
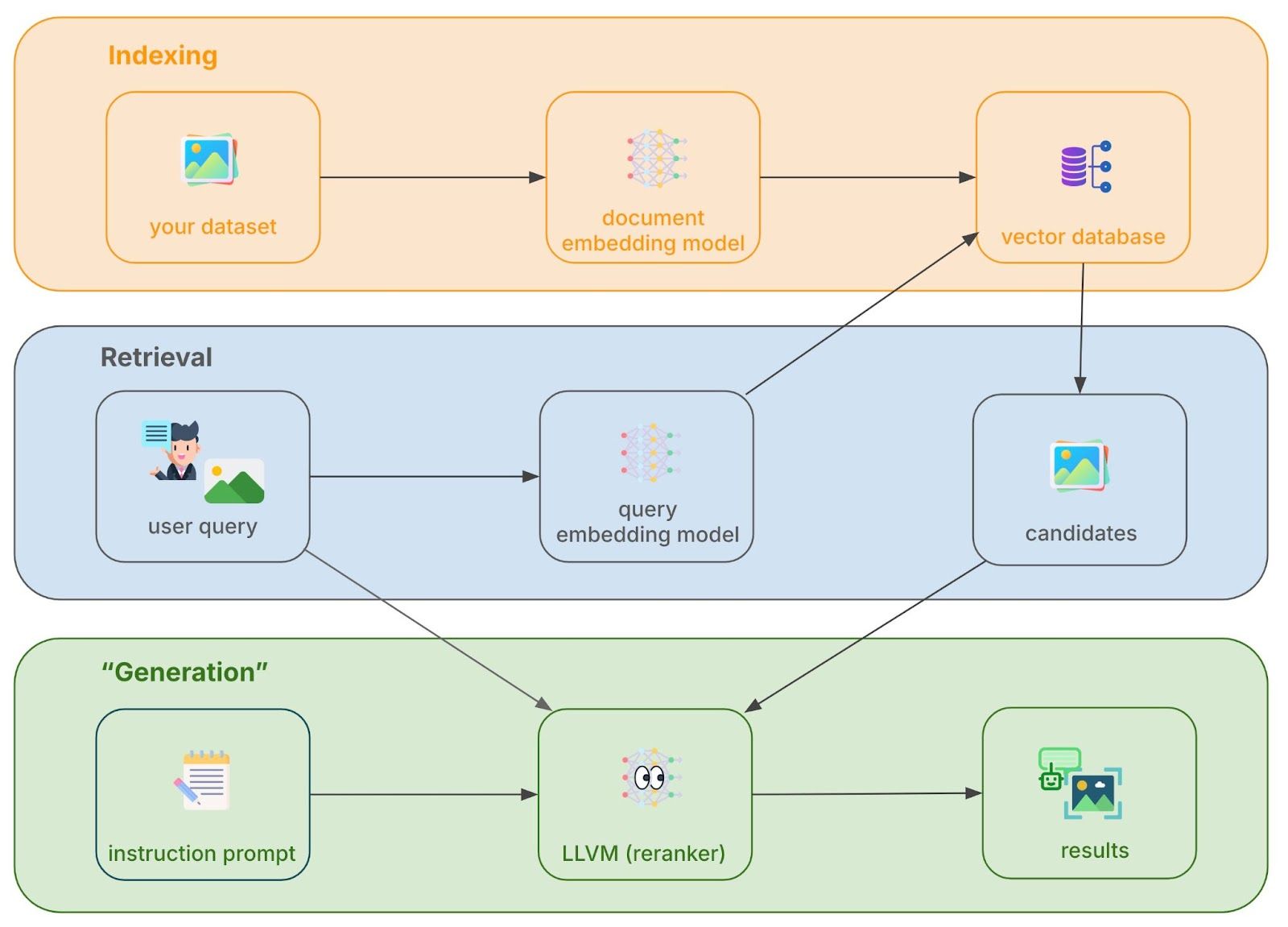
Our multimodal search application is of the type retrieve-and-rerank. If you are familiar with retrieval-augmented-generation (RAG) it is very similar, only that the final output is a list of images that were reranked by a large language-vision model (LLVM). The user’s search query contains both text and image, and the target is a set of images indexed in a vector database. The architecture has three steps - indexing, retrieval, and reranking (akin to “generation”) - which we summarize in turn.
Indexing
Our search application must have something to search. In our case, we use a small subset of the “Amazon Reviews 2023” dataset, which contains both text and images from Amazon customer reviews across all types of products. You can imagine a semantic search like that that we are building as being a useful addition to an ecommerce website. We use 900 images and discard the text, although observe that this notebook can scale to production-size with the right database and inference deployments.
The first piece of “magic” in our pipeline is the choice of embedding model. We use a recently developed multimodal model called Visualized BGE that is able to embed text and images jointly, or either separately, into the same space with a single model where points that are close are semantically similar. Other such models have been developed recently, for instance MagicLens.
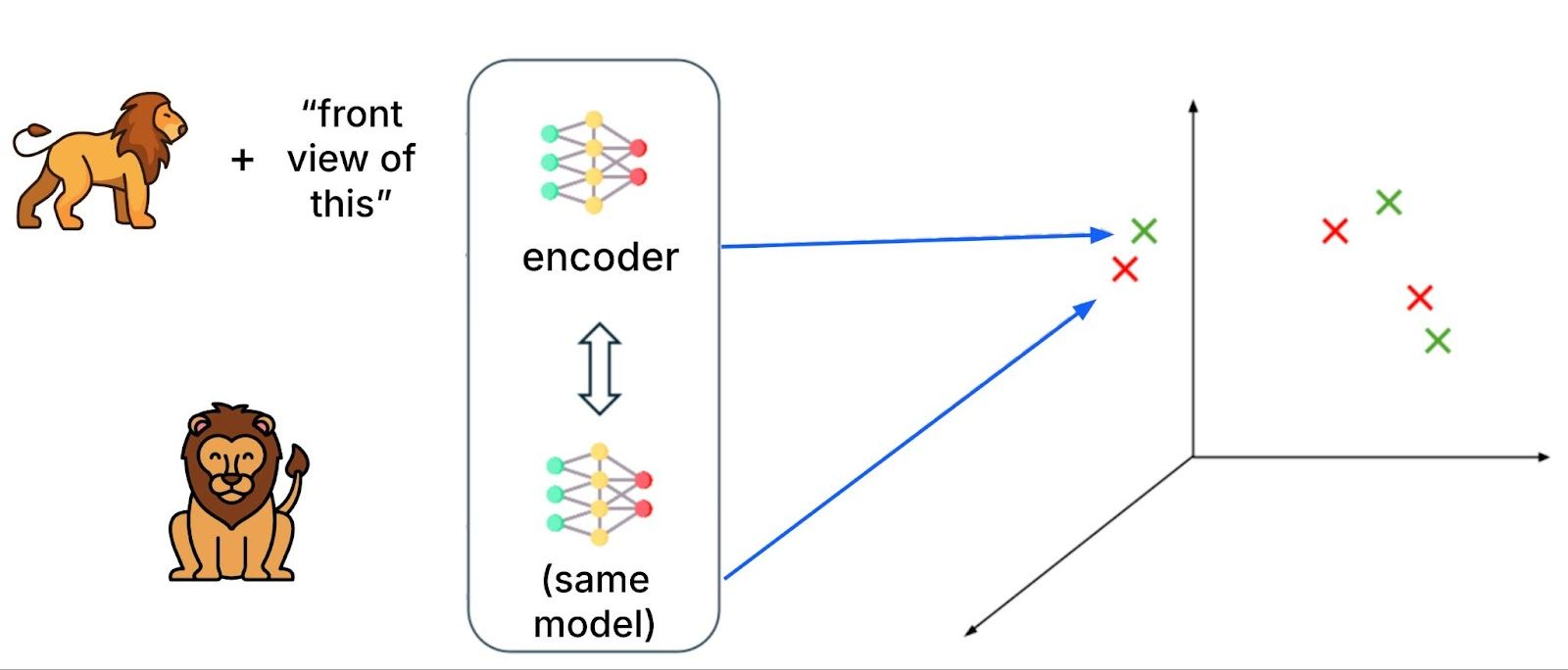
The figure above illustrates: the embedding for [an image of a lion side-on] plus the text “front view of this”, is close to an embedding for [an image of a lion front-on] without text. The same model is used for both text plus image inputs and image-only inputs (as well as text-only inputs). In this way, the model is able to understand the user’s intent in how the query text relates to the query image.
We embed our 900 product images without corresponding text and store the embeddings in a vector database using Milvus.
Retrieval
Now that our database is built, we can serve a user query. Imagine a user comes along with the query: “a phone case with this” plus [an image of a Leopard]. That is, they are searching for phone cases with Leopard skin prints.
Note that the text of the user’s query said “this” rather than “a Leopard’s skin”. Our embedding model must be able to connect “this” to what it refers to, which is an impressive feat given that the previous iteration of models were not able to handle such open-ended instructions. The MagicLens paper gives further examples.

We embed the query text and image jointly and perform a similarity search of our vector database, returning the top nine hits. The results are shown in the figure above, along with the query image of the leopard. It appears that the top hit is not the one that is most relevant to the query. The seventh result appears to be most relevant - it is a phone cover with a leopard skin print.
Generation
It appears our search has failed in that the top result is not the most relevant. However, we can fix this with a reranking step. You may be familiar with reranking of retrieved items as being an important step in many RAG pipelines. We use Phi-3 Vision as the re-ranker model.
We first ask a LLVM to generate a caption of the query image. The LLVM outputs:
“The image shows a close-up of a leopard’s face with a focus on its spotted fur and green eyes.”
We then feed this caption, a single image with the nine results and query image, and construct a text prompt asking the model to re-rank the results, giving the answer as a list and providing a reason for the choice of the top match.

The output is visualized in the figure above - the most relevant item is now the top match - and the reason given is:
“The most suitable item is the one with the leopard theme, which matches the user’s query instruction for a phone case with a similar theme.”
Our LLVM re-ranker was able to perform understanding across images and text, and improve the relevance of the search results. One interesting artifact is that the re-ranker only gave eight results and has dropped one, which highlights the need for guardrails and structured output.
Summary
In this post and the accompanying video and notebook, we have constructed an application for multimodal semantic search across text and images. The embedding model was able to embed text and images jointly or separately into the same space, and the foundation model was able to input text and image while generating text in response. Importantly, the embedding model was able to relate the user’s intent of an open-ended instruction to the query image and in that way specify how the user wanted the results to relate to the input image.
This is just a taste of what is to come in the near future. We will see many applications of multimodal search, multimodal understanding and reasoning, and so on across diverse modalities: image, video, audio, molecules, social networks, tabular data, time-series, the potential is boundless.
And at the core of these systems is a vector database holding the system’s external “memory”. Milvus is an excellent choice for this purpose. It is open-source, fully featured (see this article on full-text search in Milvus 2.5) and scales efficiently to the billions of vectors with web-scale traffic and sub-100ms latency. Find out more at the Milvus docs, join our Discord community, and hope to see you at our next Unstructured Data meetup. Until then!
Resources
Notebook: “Multimodal Search with Amazon Reviews and LLVM Reranking”
Embedding model: Visualized BGE model card
Alt. embedding model: MagicLens model repo
LLVM: Phi-3 Vision model card
Paper: “MagicLens: Self-Supervised Image Retrieval with Open-Ended Instructions”
Dataset: Amazon Reviews 2023
- Indexing
- Retrieval
- Generation
- Summary
- Resources
On This Page
Try Managed Milvus for Free
Zilliz Cloud is hassle-free, powered by Milvus and 10x faster.
Get StartedLike the article? Spread the word



