Choosing a vector database for ANN search at Reddit
This post was written by Chris Fournie, the Staff Software Engineer at Reddit, and originally published on Reddit, and is reposted here with permission.
In 2024, Reddit teams used a variety of solutions to perform approximate nearest neighbour (ANN) vector search. From Google’s Vertex AI Vector Search and experimenting with using Apache Solr’s ANN vector search for some larger datasets, to Facebook’s FAISS library for smaller datasets (hosted in vertically scaled side-cars). More and more teams at Reddit wanted a broadly supported ANN vector search solution that was cost-effective, had the search features they desired, and could scale to Reddit-sized data. To address this need, in 2025, we sought out the ideal vector database for Reddit teams.
This post describes the process we used to select the best vector database for Reddit’s needs today. It does not describe the best vector database overall, nor the most essential set of functional and non-functional requirements for all situations. It describes what Reddit and its engineering culture valued and prioritized when selecting a vector database. This post may serve as inspiration for your own requirements collection and evaluation, but each organization has its own culture, values, and needs.
Evaluation process
Overall, the selection steps were:
1. Collect context from teams
2. Qualitatively evaluate solutions
3. Quantitatively evaluate top contenders
4. Final selection
1. Collect context from teams
Three pieces of context were collected from teams interested in performing ANN vector search:
Functional requirements (e.g., Hybrid vector and lexical search? Range search queries? Filtering by non-vector attributes?)
Non-functional requirements (e.g, Can it support 1B vectors? Can it reach <100ms P99 latency?)
Vector databases teams were already interested in
Interviewing teams for requirements is not trivial. Many will describe their needs in terms of how they are currently solving a problem, and your challenge is to understand and remove that bias.
For example, a team was already using FAISS for ANN vector search and stated that the new solution must efficiently return 10K results per search call. Upon further discussion, the reason for the 10K results was that they needed to perform post-hoc filtering, and FAISS does not offer filtering ANN results at query time. Their actual problem was that they needed filtering, so any solution that offered efficient filtering would suffice, and returning 10K results was simply a workaround required to improve their recall. They would ideally like to pre-filter the entire collection before finding nearest neighbours.
Asking for the vector databases that teams were already using or were interested in was also valuable. If at least one team had a positive view of their current solution, it’s a sign that vector database could be a useful solution to share across the entire company. If teams only had negative views of a solution, then we should not include it as an option. Accepting solutions that teams were interested in was also a way to make sure that teams felt included in the process and helped us form an initial list of leading contenders to evaluate; there are too many ANN vector search solutions in new and existing databases to exhaustively test all of them.
2. Qualitatively evaluate solutions
Starting with the list of solutions that teams were interested in, to qualitatively evaluate which ANN vector search solution best fit our needs, we:
Researched each solution and scored how well it fulfilled each requirement vs the weighted importance of that requirement
Removed solutions based on qualitative criteria and discussion
Picked our top N solutions to quantitatively test
Our starting list of ANN vector search solutions included:
Qdrant
Weviate
Open Search
Pgvector (already using Postgres as an RDBMS)
Redis (already used as a KV store and cache)
Cassandra (already used for non-ANN search)
Solr (already using for lexical search and experimented with vector search)
Vespa
Pinecone
Vertex AI (already used for ANN vector search)
We then took every functional and non-functional requirement that was mentioned by teams, plus some more constraints representing our engineering values and objectives, made those rows in a spreadsheet, and weighed how important they were (from 1 to 3; shown in the abridged table below).
For each solution we were comparing, we evaluated (on a scale of 0 to 3) how well each system satisfied that requirement (as shown in the table below). Scoring in this way was somewhat subjective, so we picked one system and gave examples of scores with written rationale and had reviewers refer back to those examples. We also gave the following guidance for assigning each score value: assign this value if:
0: No support/evidence of requirement support
1: Basic or inadequate requirement support
2: Requirement reasonably supported
3: Robust requirement support that goes above and beyond comparable solutions
We then created an overall score for each solution by taking the sum of the product of a solution’s requirement score and that requirement’s importance (e.g., Qdrant scored 3 for re-ranking/score combining, which has importance 2, so 3 x 2 = 6, repeat that for all rows and sum together). At the end, we have an overall score that can be used as the basis for ranking and discussing solutions, and which requirements matter most (note that the score is not used to make a final decision but as a discussion tool).
Editor’s note: This review was based on Milvus 2.4. We’ve since rolled out Milvus 2.5, Milvus 2.6, and Milvus 3.0 is right around the corner, so a few numbers may be out of date. Even so, the comparison still offers strong insights and remains very helpful.
| Category | Importance | Qdrant | Milvus (2.4) | Cassandra | Weviate | Solr | Vertex AI |
| Search Type | |||||||
| Hybrid Search | 1 | 3 | 2 | 0 | 2 | 2 | 2 |
| Keyword Search | 1 | 2 | 2 | 2 | 2 | 3 | 1 |
| Approximate NN search | 3 | 3 | 3 | 2 | 2 | 2 | 2 |
| Range Search | 1 | 3 | 3 | 2 | 2 | 0 | 0 |
| Re-ranking/score combining | 2 | 3 | 2 | 0 | 2 | 2 | 1 |
| Indexing Method | |||||||
| HNSW | 3 | 3 | 3 | 2 | 2 | 2 | 0 |
| Supports multiple indexing methods | 3 | 0 | 3 | 1 | 2 | 1 | 1 |
| Quantization | 1 | 3 | 3 | 0 | 3 | 0 | 0 |
| Locality Sensitive Hashing (LSH) | 1 | 0 | 0Note: Milvus 2.6 supports it. | 0 | 0 | 0 | 0 |
| Data | |||||||
| Vector types other than float | 1 | 2 | 2 | 0 | 2 | 2 | 0 |
| Metadata attributes on vectors (supports multiple attribs, a large record size, etc.) | 3 | 3 | 2 | 2 | 2 | 2 | 1 |
| Metadata filtering options (can filter on metadata, has pre/post filtering) | 2 | 3 | 2 | 2 | 2 | 3 | 2 |
| Metadata attribute datatypes (robust schema, e.g. bool, int, string, json, arrays) | 1 | 3 | 3 | 2 | 2 | 3 | 1 |
| Metadata attributes limits (range queries, e.g. 10 < x < 15) | 1 | 3 | 3 | 2 | 2 | 2 | 1 |
| Diversity of results by attribute (e.g. getting not more than N results from each subreddit in a response) | 1 | 2 | 1 | 2 | 3 | 3 | 0 |
| Scale | |||||||
| Hundreds of millions vector index | 3 | 2 | 3 | 1 | 2 | 3 | |
| Billion vector index | 1 | 2 | 2 | 1 | 2 | 2 | |
| Support vectors at least 2k | 2 | 2 | 2 | 2 | 2 | 1 | 1 |
| Support vectors greater than 2k | 2 | 2 | 2 | 2 | 1 | 1 | 1 |
| P95 Latency 50-100ms @ X QPS | 3 | 2 | 2 | 2 | 1 | 1 | 2 |
| P99 Latency <= 10ms @ X QPS | 3 | 2 | 2 | 2 | 3 | 1 | 2 |
| 99.9% availability retrieval | 2 | 2 | 2 | 3 | 2 | 2 | 2 |
| 99.99% availability indexing/storage | 2 | 1 | 1 | 3 | 2 | 2 | 2 |
| Storage Operations | |||||||
| Hostable in AWS | 3 | 2 | 2 | 2 | 2 | 3 | 0 |
| Multi-Region | 1 | 1 | 2 | 3 | 1 | 2 | 2 |
| Zero-downtime upgrades | 1 | 2 | 2 | 3 | 2 | 2 | 1 |
| Multi-Cloud | 1 | 3 | 3 | 3 | 2 | 2 | 0 |
| APIs/Libraries | |||||||
| gRPC | 2 | 2 | 2 | 2 | 2 | 0 | 2 |
| RESTful API | 1 | 3 | 2 | 2 | 2 | 1 | 2 |
| Go Library | 3 | 2 | 2 | 2 | 2 | 1 | 2 |
| Java Library | 2 | 2 | 2 | 2 | 2 | 2 | 2 |
| Python | 2 | 2 | 2 | 2 | 2 | 2 | 2 |
| Other languages (C++, Ruby, etc) | 1 | 2 | 2 | 3 | 2 | 2 | 2 |
| Runtime Operations | |||||||
| Prometheus Metrics | 3 | 2 | 2 | 2 | 3 | 2 | 0 |
| Basic DB Operations | 3 | 2 | 2 | 2 | 2 | 2 | 2 |
| Upserts | 2 | 2 | 2 | 2 | 1 | 2 | 2 |
| Kubernetes Operator | 2 | 2 | 2 | 2 | 2 | 2 | 0 |
| Pagination of results | 2 | 2 | 2 | 2 | 2 | 2 | 0 |
| Embedding lookup by ID | 2 | 2 | 2 | 2 | 2 | 2 | 2 |
| Return Embeddings with Candidate ID and candidate scores | 1 | 3 | 2 | 2 | 2 | 2 | 2 |
| User supplied ID | 2 | 2 | 2 | 2 | 2 | 2 | 2 |
| Able to search in large scale batch context | 1 | 2 | 1 | 1 | 2 | 1 | 2 |
| Backups / Snapshots: supports the ability to create backups of the entire database | 1 | 2 | 2 | 2 | 3 | 3 | 2 |
| Efficient large index support (cold vs hot storage distinction) | 1 | 3 | 2 | 2 | 2 | 1 | 2 |
| Support/Community | |||||||
| Vendor neutrality | 3 | 3 | 2 | 3 | 2 | 3 | 0 |
| Robust api support | 3 | 3 | 3 | 2 | 2 | 2 | 2 |
| Vendor support | 2 | 2 | 2 | 2 | 2 | 2 | 0 |
| Community Velocity | 2 | 3 | 2 | 2 | 2 | 2 | 0 |
| Production Userbase | 2 | 3 | 3 | 2 | 2 | 1 | 2 |
| Community Feel | 1 | 3 | 2 | 2 | 2 | 2 | 1 |
| Github Stars | 1 | 2 | 2 | 2 | 2 | 2 | 0 |
| Configuration | |||||||
| Secrets Handling | 2 | 2 | 2 | 2 | 1 | 2 | 2 |
| Source | |||||||
| Open Source | 3 | 3 | 3 | 3 | 2 | 3 | 0 |
| Language | 2 | 3 | 3 | 2 | 3 | 2 | 0 |
| Releases | 2 | 3 | 3 | 2 | 2 | 2 | 2 |
| Upstream testing | 1 | 2 | 3 | 3 | 2 | 2 | 2 |
| Availability of documentation | 3 | 3 | 3 | 2 | 1 | 2 | 1 |
| Cost | |||||||
| Cost Effective | 2 | 2 | 2 | 2 | 2 | 2 | 1 |
| Performance | |||||||
| Support for tuning resource utilization for CPU, memory, and disk | 3 | 2 | 2 | 2 | 2 | 2 | 2 |
| Multi-node (pod) sharding | 3 | 2 | 2 | 3 | 2 | 2 | 2 |
| Have the ability to tune the system to balance between latency and throughput | 2 | 2 | 2 | 3 | 2 | 2 | 2 |
| User-defined partitioning (writes) | 1 | 3 | 2 | 3 | 1 | 2 | 0 |
| Multi-tenant | 1 | 3 | 2 | 1 | 3 | 2 | 2 |
| Partitioning | 2 | 2 | 2 | 3 | 2 | 2 | 2 |
| Replication | 2 | 2 | 2 | 3 | 2 | 2 | 2 |
| Redundancy | 1 | 2 | 2 | 3 | 2 | 2 | 2 |
| Automatic Failover | 3 | 2 | 0 Note: Milvus 2.6 supports it. | 3 | 2 | 2 | 2 |
| Load Balancing | 2 | 2 | 2 | 3 | 2 | 2 | 2 |
| GPU Support | 1 | 0 | 2 | 0 | 0 | 0 | 0 |
| Qdrant | Milvus | Cassandra | Weviate | Solr | Vertex AI | ||
| Overall solution scores | 292 | 281 | 264 | 250 | 242 | 173 |
We discussed the overall and requirement scores of the various systems and sought to understand whether we had appropriately weighted the importance of the requirements and whether some requirements were so important that they should be considered core constraints. One such requirement we identified was whether the solution was open-source or not, because we desired a solution that we could become involved with, contribute towards, and quickly fix small issues if we experienced them at our scale. Contributing to and using open-source software is an important part of Reddit’s engineering culture. This eliminated the hosted-only solutions (Vertex AI, Pinecone) from our consideration.
During discussions, we found that a few other key requirements were of outsized importance to us:
Scale and reliability: we wanted to see evidence of other companies running the solution with 100M+ or even 1B vectors
Community: We wanted a solution with a healthy community with a lot of momentum in this rapidly maturing space
Expressive metadata types and filtering to enable more of our use-cases (filtering by date, boolean, etc.)
Supports for multiple index types (not just HNSW or DiskANN) to better fit performance for our many unique use-cases
The result of our discussions and honing of key requirements led us to choose to test (in order) quantitatively:
Qdrant
Milvus
Vespa, and
Weviate
Unfortunately, decisions like this take time and resources, and no organization has unlimited amounts of either. Given our budget, we decided to test Qdrant and Milvus, and to leave testing Vespa and Weviate as stretch goals.
Qdrant vs Milvus was also an interesting test of two different architectures:
Qdrant: Homogeneous node types that perform all ANN vector database operations
Milvus: Heterogeneous node types (Milvus; one for queries, another for indexing, another for data ingest, a proxy, etc.)
Which one was easy to set up (a test of their documentation)? Which one was easy to run (a test of their resiliency features and polish)? And which one performed best for the use cases and scale that we cared about? These questions we sought to answer as we quantitatively compared the solutions.
3. Quantitatively evaluate top contenders
We wanted to better understand how scalable each solution was, and in the process, experience what it would be like to set up, configure, maintain, and run each solution at scale. To do this, we collected three datasets of document and query vectors for three different use-cases, set up each solution with similar resources within Kubernetes, loaded documents into each solution, and sent identical query loads using Grafana’s K6 with a ramping arrival rate executor to warm systems up before then hitting a target throughput (e.g., 100 QPS).
We tested throughput, the breaking point of each solution, the relationship between throughput and latency, and how they react to losing nodes under load (error rate, latency impact, etc.). Of key interest was the effect of filtering on latency. We also had simple yes/no tests to verify that a capability in documentation worked as described (e.g., upserts, delete, get by ID, user administration, etc.) and to experience the ergonomics of those APIs.
Testing was done on Milvus v2.4 and Qdrant v1.12. Due to time constraints, we did not exhaustively tune or test all types of index settings; similar settings were used with each solution, with a bias towards high ANN recall, and tests focused on the performance of HNSW indexes. Similar CPU and memory resources were also given to each solution.
In our experimentation, we found a few interesting differences between the two solutions. In the following experiments, each solution had approximately 340M Reddit post vectors of 384 dimensions each, for HNSW, M=16, and efConstruction=100.
In one experiment, we found that for the same query throughput (100 QPS with no ingestion at the same time), adding filtering affected the latency of Milvus more than Qdrant.
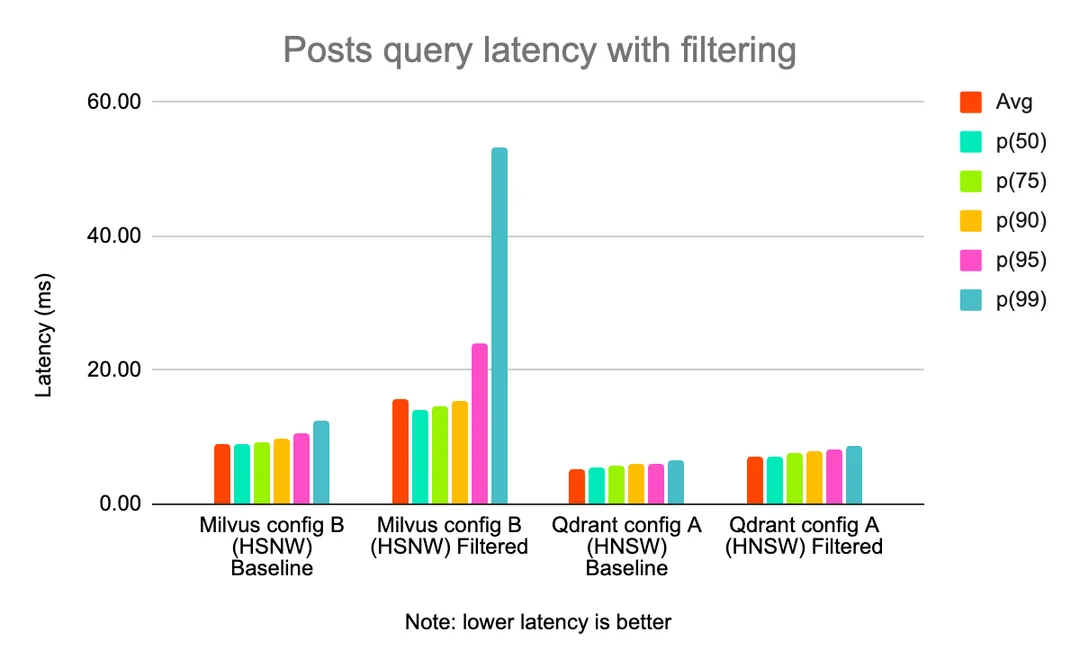
Posts query latency with filtering
In another, we found that there was far more of an interaction between ingestion and query load on Qdrant than on Milvus (shown below at constant throughput). This is likely due to their architecture; Milvus splits much of its ingestion over separate node types from those that serve query traffic, whereas Qdrant serves both ingestion and query traffic from the same nodes.
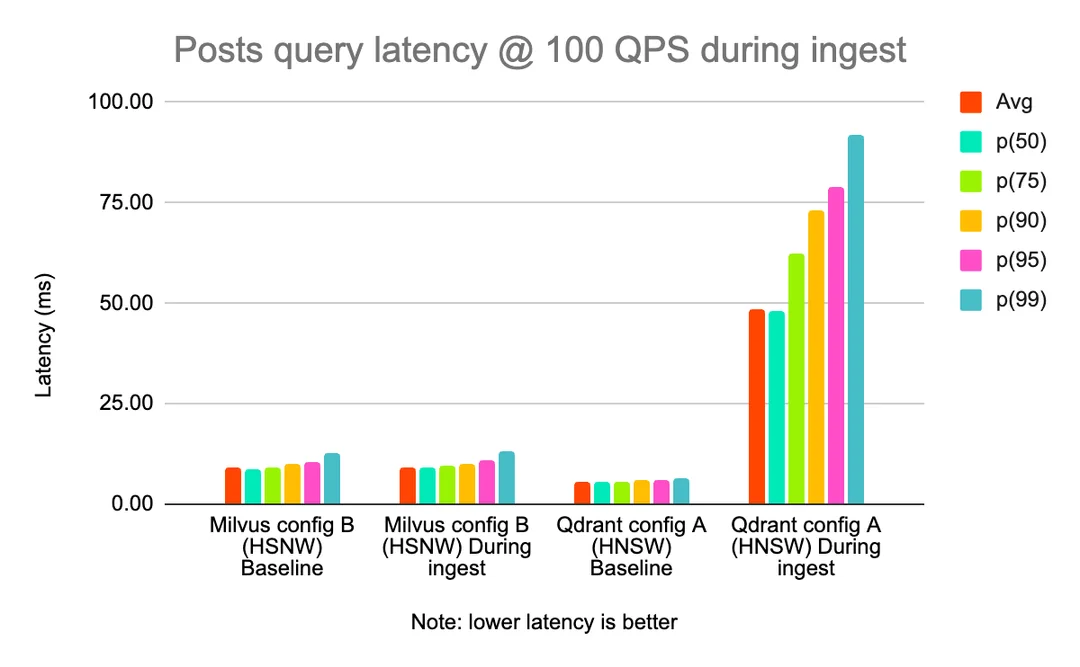
Posts query latency @ 100 QPS during ingest
When testing the diversity of results by attribute (e.g. getting not more than N results from each subreddit in a response), we found that for the same throughput, Milvus had worse latency than Qdrant (at 100 QPS).
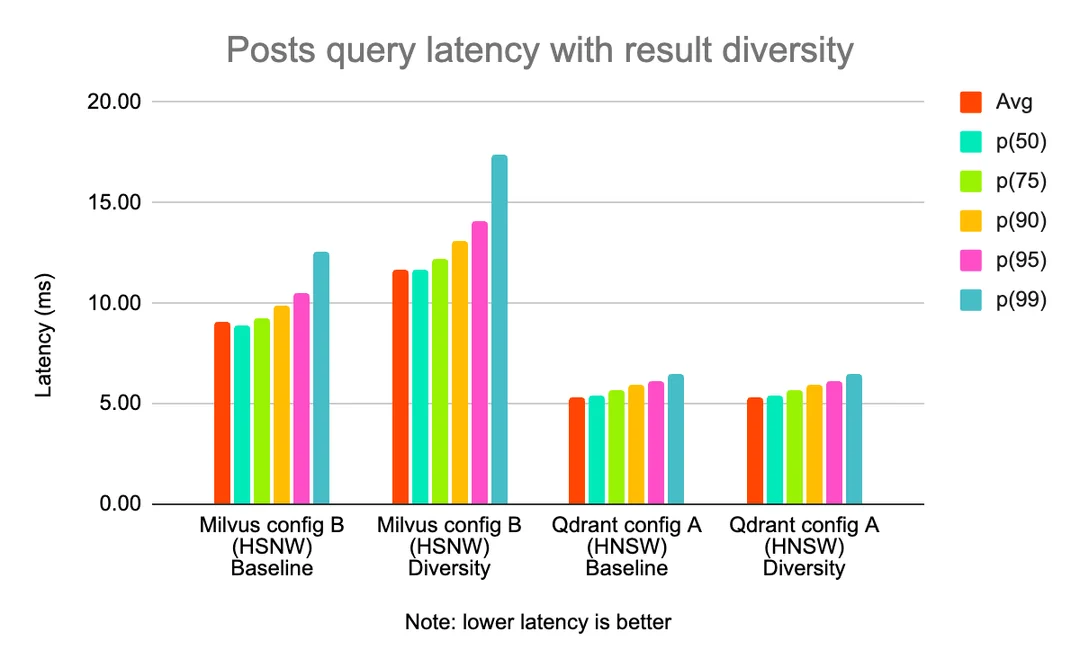
Post query latency with result diversity
We also wanted to see how effectively each solution scaled when more replicas of data were added (i.e. the replication factor, RF, was increased from 1 to 2). Initially, looking at RF=1, Qdrant was able to give us satisfactory latency for more throughput than Milvus (higher QPS not shown because tests did not complete without errors).
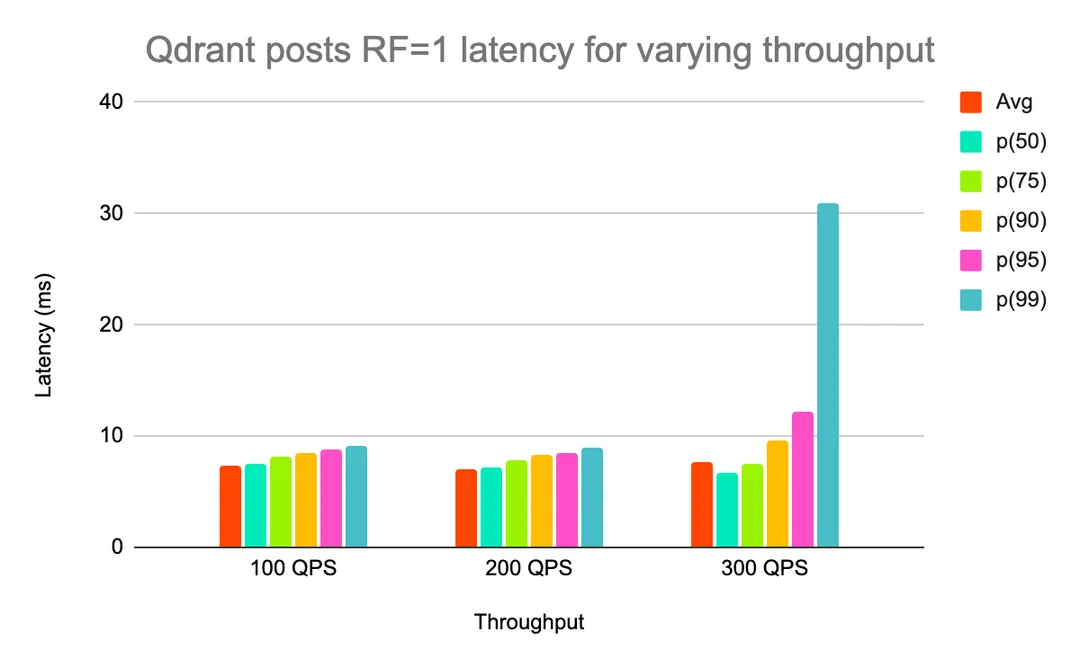
Qdrant posts RF=1 latency for varying throughput
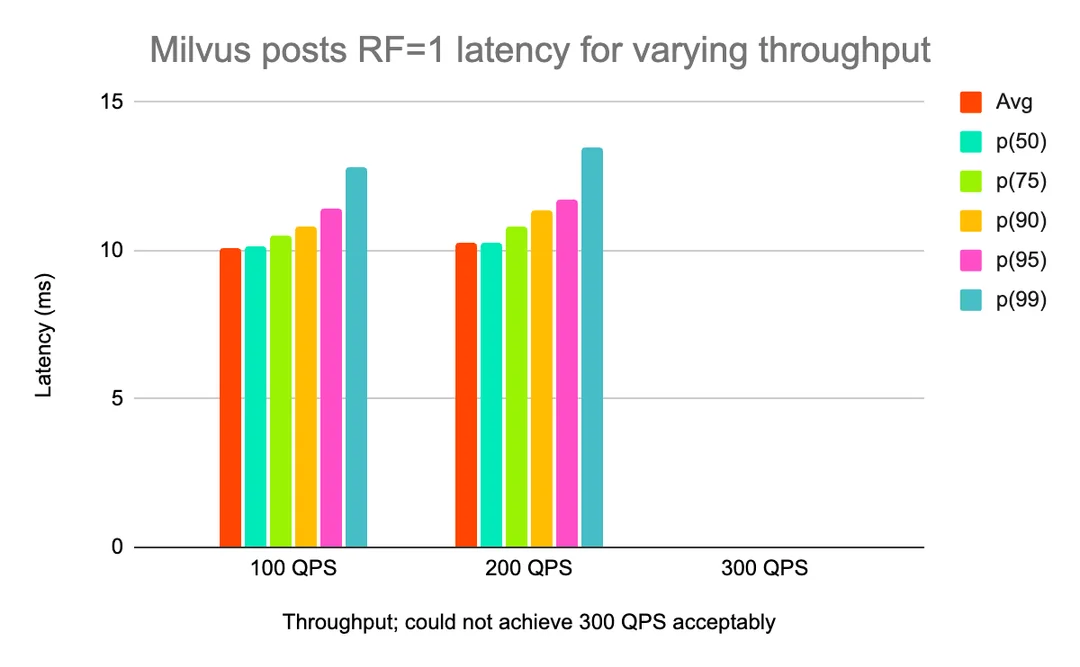
Milvus posts RF=1 latency for varying throughput
However, when increasing the replication factor, Qdrant’s p99 latency improved, but Milvus was able to sustain higher throughput than Qdrant was, with acceptable latency (Qdrant 400 QPS not shown because the test did not complete due to high latency and errors).
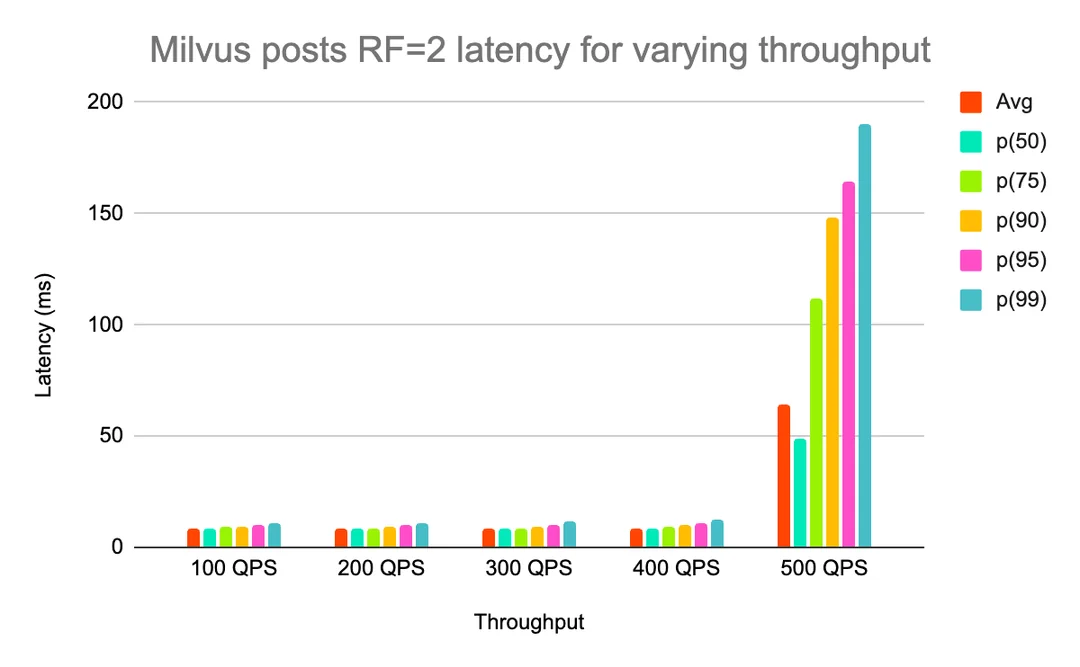
Milvus posts RF=2 latency for varying throughput

Qdrant posts RF=2 latency for varying throughput
Due to time constraints, we did not have enough time to compare ANN recall between solutions on our datasets, but we did take into account the ANN recall measurements for solutions provided by https://ann-benchmarks.com/ on publicly available datasets.
4. Final selection
Performance-wise, without much tuning and only using HNSW, Qdrant appeared to have better raw latency in many tests than Milvus. Milvus looked like it would, however, scale better with increased replication, and had better isolation between ingestion and query load due to its multiple-node-type architecture.
Operation-wise, despite the complexity of Milvus’ architecture (multiple node types, relying upon an external write-ahead log like Kafka and a metadata store like etcd), we had an easier time debugging and fixing Milvus than Qdrant when either solution entered a bad state. Milvus also has automatic rebalancing when increasing the replication factor of a collection, whereas in open-source Qdrant, manual creation or dropping of shards is required to increase the replication factor (a feature we would have had to build ourselves or use the non-open-source version).
Milvus is a more “Reddit-shaped” technology than Qdrant; it shares more similarities with the rest of our tech stack. Milvus is written in Golang, our preferred backend programming language, and thus easier for us to contribute to than Qdrant, which is written in Rust. Milvus has excellent project velocity for its open-source offering compared to Qdrant, and it met more of our key requirements.
In the end, both solutions met most of our requirements, and in some cases, Qdrant had a performance edge, but we felt that we could scale Milvus further, felt more comfortable running it, and it was a better match for our organization than Qdrant. We wish we had had more time to test Vespa and Weaviate, but they too may have been selected out for organizational fit (Vespa being Java-based) and architecture (Weaviate being single-node-type like Qdrant).
Key takeaways
Challenge the requirements you are given and try to remove existing solution bias.
Score candidate solutions, and use that to inform the discussion of essential requirements, not as a be-all end-all
Quantitatively evaluate solutions, but along the way, take note of what it’s like to work with the solution.
Pick the solution that fits best within your organization from a maintenance, cost, usability, and performance perspective, not just because a solution performs the best.
Acknowledgements
This evaluation work was performed by Ben Kochie, Charles Njoroge, Amit Kumar, and me. Thanks also to others who contributed to this work, including Annie Yang, Konrad Reiche, Sabrina Kong, and Andrew Johnson, for qualitative solution research.
Editor’s Notes
We want to give a genuine thank-you to the Reddit engineering team — not just for choosing Milvus for their vector search workloads, but for taking the time to publish such a detailed and fair evaluation. It’s rare to see this level of transparency in how real engineering teams compare databases, and their write-up will be helpful to anyone in the Milvus community (and beyond) who’s trying to make sense of the growing vector database landscape.
As Chris mentioned in the post, there’s no single “best” vector database. What matters is whether a system fits your workload, constraints, and operational philosophy. Reddit’s comparison reflects that reality well. Milvus doesn’t top every category, and that’s completely expected given the trade-offs across different data models and performance goals.
One thing worth clarifying: Reddit’s evaluation used Milvus 2.4, which was the stable release at the time. Some features — like LSH and several index optimizations — either didn’t exist yet or weren’t mature in 2.4, so a few scores naturally reflect that older baseline. Since then, we’ve released Milvus 2.5 and then Milvus 2.6, and it’s a very different system in terms of performance, efficiency, and flexibility. The community response has been strong, and many teams have already upgraded.
Here’s a quick look at what’s new in Milvus 2.6:
Up to 72% lower memory usage and 4× faster queries with RaBitQ 1-bit quantization
50% cost reduction with intelligent tiered storage
4× faster BM25 full-text search compared to Elasticsearch
100× faster JSON filtering with the new Path Index
A new zero-disk architecture for fresher search at lower cost
A simpler “data-in, data-out” workflow for embedding pipelines
Support for 100K+ collections to handle large multi-tenant environments
If you want the full breakdown, here are a few good follow-ups:
Blog: Introducing Milvus 2.6: Affordable Vector Search at Billion Scale
VDBBench 1.0: Real-World Benchmarking for Vector Databases - Milvus Blog
Have questions or want a deep dive on any feature? Join our Discord channel or file issues on GitHub. You can also book a 20-minute one-on-one session to get insights, guidance, and answers to your questions through Milvus Office Hours.
- Evaluation process
- 1. Collect context from teams
- 2. Qualitatively evaluate solutions
- 3. Quantitatively evaluate top contenders
- 4. Final selection
- Key takeaways
- Acknowledgements
- Editor’s Notes
On This Page
Try Managed Milvus for Free
Zilliz Cloud is hassle-free, powered by Milvus and 10x faster.
Get StartedLike the article? Spread the word



