使用 Milvus 进行上下文检索
![]()
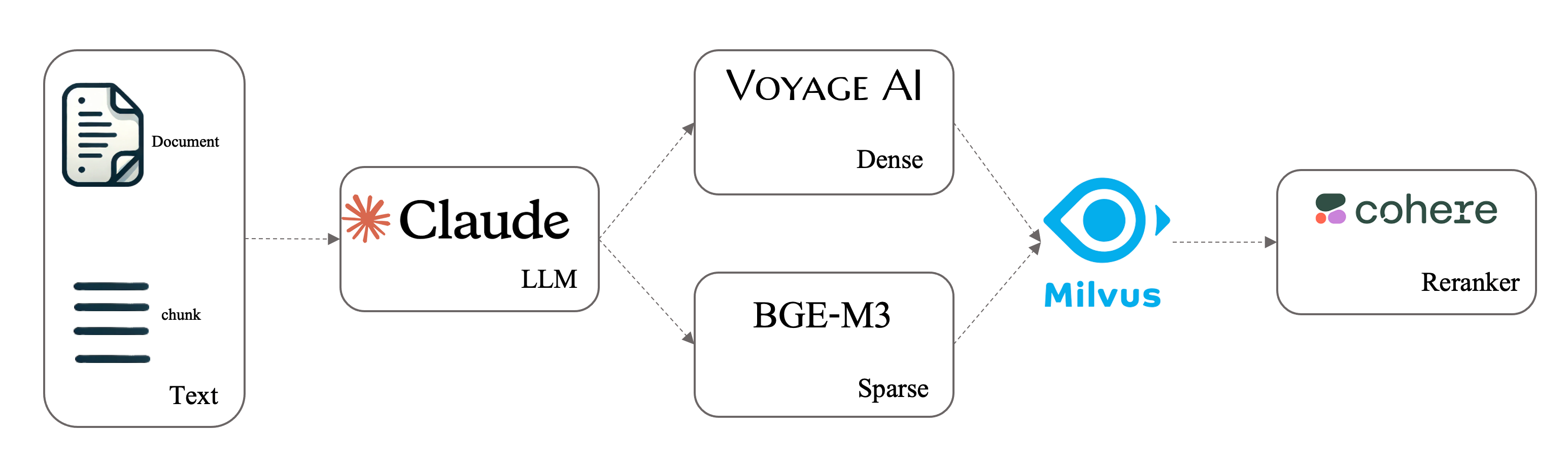 图像 上下文检索( image Contextual Retrieval)是 Anthropic 提出的一种先进检索方法,旨在解决当前检索增强生成(RAG)解决方案中出现的块的语义隔离问题。在当前实用的 RAG 范式中,文档被分成若干个块,使用向量数据库进行查询搜索,检索出最相关的块。然后,LLM 使用这些检索到的分块对查询做出响应。然而,这种分块过程会导致上下文信息的丢失,使检索者难以确定相关性。
图像 上下文检索( image Contextual Retrieval)是 Anthropic 提出的一种先进检索方法,旨在解决当前检索增强生成(RAG)解决方案中出现的块的语义隔离问题。在当前实用的 RAG 范式中,文档被分成若干个块,使用向量数据库进行查询搜索,检索出最相关的块。然后,LLM 使用这些检索到的分块对查询做出响应。然而,这种分块过程会导致上下文信息的丢失,使检索者难以确定相关性。
上下文检索改进了传统的检索系统,在嵌入或索引之前为每个文档分块添加相关上下文,提高了准确性并减少了检索错误。与混合检索和 Rerankers 等技术相结合,它能增强检索增强生成(RAG)系统,尤其适用于大型知识库。此外,当与及时缓存搭配使用时,它还能提供一种具有成本效益的解决方案,显著降低延迟和操作符成本,上下文化块的成本约为每百万文档令牌 1.02 美元。这使其成为处理大型知识库的一种可扩展的高效方法。Anthropic 的解决方案在以下两个方面颇具洞察力:
Document Enhancement:查询重写是现代信息检索中的一项重要技术,通常使用辅助信息使查询更具信息性。同样,为了在 RAG 中获得更好的性能,在索引之前使用 LLM 对文档进行预处理(例如,清理数据源、补充丢失的信息、总结等)可以显著提高检索到相关文档的几率。换句话说,这一预处理步骤有助于使文档在相关性方面更接近查询。Low-Cost Processing by Caching Long Context:使用 LLMs 处理文档时,人们普遍关心的一个问题是成本。KVCache 是一种流行的解决方案,它允许重复使用同一上下文的中间结果。大多数托管 LLM 厂商都将这一功能对用户透明化,而 Anthropic 则让用户控制缓存过程。当缓存命中时,大多数计算都可以被保存(当长上下文保持不变,但每个查询的指令发生变化时,这种情况很常见)。更多详情,请点击此处。
在本笔记本中,我们将演示如何使用 Milvus 与 LLM 执行上下文检索,将密集-稀疏混合检索与 Reranker 结合起来,创建一个逐渐强大的检索系统。数据和实验设置均基于上下文检索。
准备工作
安装依赖项
$ pip install "pymilvus[model]"
$ pip install tqdm
$ pip install anthropic
如果使用的是 Google Colab,要启用刚刚安装的依赖项,可能需要重启运行时(点击屏幕上方的 "运行时 "菜单,从下拉菜单中选择 "重启会话")。
运行代码需要 Cohere、Voyage 和 Anthropic 的 API 密钥。
下载数据
以下命令将下载 Anthropic 原始演示中使用的示例数据。
$ wget https://raw.githubusercontent.com/anthropics/anthropic-cookbook/refs/heads/main/skills/contextual-embeddings/data/codebase_chunks.json
$ wget https://raw.githubusercontent.com/anthropics/anthropic-cookbook/refs/heads/main/skills/contextual-embeddings/data/evaluation_set.jsonl
定义检索器
该类设计灵活,可根据需要选择不同的检索模式。通过在初始化方法中指定选项,你可以决定是使用上下文检索、混合检索(结合密集和稀疏检索方法),还是使用 Reranker 来增强结果。
from pymilvus.model.dense import VoyageEmbeddingFunction
from pymilvus.model.hybrid import BGEM3EmbeddingFunction
from pymilvus.model.reranker import CohereRerankFunction
from typing import List, Dict, Any
from typing import Callable
from pymilvus import (
MilvusClient,
DataType,
AnnSearchRequest,
RRFRanker,
)
from tqdm import tqdm
import json
import anthropic
class MilvusContextualRetriever:
def __init__(
self,
uri="milvus.db",
collection_name="contexual_bgem3",
dense_embedding_function=None,
use_sparse=False,
sparse_embedding_function=None,
use_contextualize_embedding=False,
anthropic_client=None,
use_reranker=False,
rerank_function=None,
):
self.collection_name = collection_name
# For Milvus-lite, uri is a local path like "./milvus.db"
# For Milvus standalone service, uri is like "http://localhost:19530"
# For Zilliz Clond, please set `uri` and `token`, which correspond to the [Public Endpoint and API key](https://docs.zilliz.com/docs/on-zilliz-cloud-console#cluster-details) in Zilliz Cloud.
self.client = MilvusClient(uri)
self.embedding_function = dense_embedding_function
self.use_sparse = use_sparse
self.sparse_embedding_function = None
self.use_contextualize_embedding = use_contextualize_embedding
self.anthropic_client = anthropic_client
self.use_reranker = use_reranker
self.rerank_function = rerank_function
if use_sparse is True and sparse_embedding_function:
self.sparse_embedding_function = sparse_embedding_function
elif sparse_embedding_function is False:
raise ValueError(
"Sparse embedding function cannot be None if use_sparse is False"
)
else:
pass
def build_collection(self):
schema = self.client.create_schema(
auto_id=True,
enable_dynamic_field=True,
)
schema.add_field(field_name="pk", datatype=DataType.INT64, is_primary=True)
schema.add_field(
field_name="dense_vector",
datatype=DataType.FLOAT_VECTOR,
dim=self.embedding_function.dim,
)
if self.use_sparse is True:
schema.add_field(
field_name="sparse_vector", datatype=DataType.SPARSE_FLOAT_VECTOR
)
index_params = self.client.prepare_index_params()
index_params.add_index(
field_name="dense_vector", index_type="FLAT", metric_type="IP"
)
if self.use_sparse is True:
index_params.add_index(
field_name="sparse_vector",
index_type="SPARSE_INVERTED_INDEX",
metric_type="IP",
)
self.client.create_collection(
collection_name=self.collection_name,
schema=schema,
index_params=index_params,
enable_dynamic_field=True,
)
def insert_data(self, chunk, metadata):
dense_vec = self.embedding_function([chunk])[0]
if self.use_sparse is True:
sparse_result = self.sparse_embedding_function.encode_documents([chunk])
if type(sparse_result) == dict:
sparse_vec = sparse_result["sparse"][[0]]
else:
sparse_vec = sparse_result[[0]]
self.client.insert(
collection_name=self.collection_name,
data={
"dense_vector": dense_vec,
"sparse_vector": sparse_vec,
**metadata,
},
)
else:
self.client.insert(
collection_name=self.collection_name,
data={"dense_vector": dense_vec, **metadata},
)
def insert_contextualized_data(self, doc, chunk, metadata):
contextualized_text, usage = self.situate_context(doc, chunk)
metadata["context"] = contextualized_text
text_to_embed = f"{chunk}\n\n{contextualized_text}"
dense_vec = self.embedding_function([text_to_embed])[0]
if self.use_sparse is True:
sparse_vec = self.sparse_embedding_function.encode_documents(
[text_to_embed]
)["sparse"][[0]]
self.client.insert(
collection_name=self.collection_name,
data={
"dense_vector": dense_vec,
"sparse_vector": sparse_vec,
**metadata,
},
)
else:
self.client.insert(
collection_name=self.collection_name,
data={"dense_vector": dense_vec, **metadata},
)
def situate_context(self, doc: str, chunk: str):
DOCUMENT_CONTEXT_PROMPT = """
<document>
{doc_content}
</document>
"""
CHUNK_CONTEXT_PROMPT = """
Here is the chunk we want to situate within the whole document
<chunk>
{chunk_content}
</chunk>
Please give a short succinct context to situate this chunk within the overall document for the purposes of improving search retrieval of the chunk.
Answer only with the succinct context and nothing else.
"""
response = self.anthropic_client.beta.prompt_caching.messages.create(
model="claude-3-haiku-20240307",
max_tokens=1000,
temperature=0.0,
messages=[
{
"role": "user",
"content": [
{
"type": "text",
"text": DOCUMENT_CONTEXT_PROMPT.format(doc_content=doc),
"cache_control": {
"type": "ephemeral"
}, # we will make use of prompt caching for the full documents
},
{
"type": "text",
"text": CHUNK_CONTEXT_PROMPT.format(chunk_content=chunk),
},
],
},
],
extra_headers={"anthropic-beta": "prompt-caching-2024-07-31"},
)
return response.content[0].text, response.usage
def search(self, query: str, k: int = 20) -> List[Dict[str, Any]]:
dense_vec = self.embedding_function([query])[0]
if self.use_sparse is True:
sparse_vec = self.sparse_embedding_function.encode_queries([query])[
"sparse"
][[0]]
req_list = []
if self.use_reranker:
k = k * 10
if self.use_sparse is True:
req_list = []
dense_search_param = {
"data": [dense_vec],
"anns_field": "dense_vector",
"param": {"metric_type": "IP"},
"limit": k * 2,
}
dense_req = AnnSearchRequest(**dense_search_param)
req_list.append(dense_req)
sparse_search_param = {
"data": [sparse_vec],
"anns_field": "sparse_vector",
"param": {"metric_type": "IP"},
"limit": k * 2,
}
sparse_req = AnnSearchRequest(**sparse_search_param)
req_list.append(sparse_req)
docs = self.client.hybrid_search(
self.collection_name,
req_list,
RRFRanker(),
k,
output_fields=[
"content",
"original_uuid",
"doc_id",
"chunk_id",
"original_index",
"context",
],
)
else:
docs = self.client.search(
self.collection_name,
data=[dense_vec],
anns_field="dense_vector",
limit=k,
output_fields=[
"content",
"original_uuid",
"doc_id",
"chunk_id",
"original_index",
"context",
],
)
if self.use_reranker and self.use_contextualize_embedding:
reranked_texts = []
reranked_docs = []
for i in range(k):
if self.use_contextualize_embedding:
reranked_texts.append(
f"{docs[0][i]['entity']['content']}\n\n{docs[0][i]['entity']['context']}"
)
else:
reranked_texts.append(f"{docs[0][i]['entity']['content']}")
results = self.rerank_function(query, reranked_texts)
for result in results:
reranked_docs.append(docs[0][result.index])
docs[0] = reranked_docs
return docs
def evaluate_retrieval(
queries: List[Dict[str, Any]], retrieval_function: Callable, db, k: int = 20
) -> Dict[str, float]:
total_score = 0
total_queries = len(queries)
for query_item in tqdm(queries, desc="Evaluating retrieval"):
query = query_item["query"]
golden_chunk_uuids = query_item["golden_chunk_uuids"]
# Find all golden chunk contents
golden_contents = []
for doc_uuid, chunk_index in golden_chunk_uuids:
golden_doc = next(
(
doc
for doc in query_item["golden_documents"]
if doc["uuid"] == doc_uuid
),
None,
)
if not golden_doc:
print(f"Warning: Golden document not found for UUID {doc_uuid}")
continue
golden_chunk = next(
(
chunk
for chunk in golden_doc["chunks"]
if chunk["index"] == chunk_index
),
None,
)
if not golden_chunk:
print(
f"Warning: Golden chunk not found for index {chunk_index} in document {doc_uuid}"
)
continue
golden_contents.append(golden_chunk["content"].strip())
if not golden_contents:
print(f"Warning: No golden contents found for query: {query}")
continue
retrieved_docs = retrieval_function(query, db, k=k)
# Count how many golden chunks are in the top k retrieved documents
chunks_found = 0
for golden_content in golden_contents:
for doc in retrieved_docs[0][:k]:
retrieved_content = doc["entity"]["content"].strip()
if retrieved_content == golden_content:
chunks_found += 1
break
query_score = chunks_found / len(golden_contents)
total_score += query_score
average_score = total_score / total_queries
pass_at_n = average_score * 100
return {
"pass_at_n": pass_at_n,
"average_score": average_score,
"total_queries": total_queries,
}
def retrieve_base(query: str, db, k: int = 20) -> List[Dict[str, Any]]:
return db.search(query, k=k)
def load_jsonl(file_path: str) -> List[Dict[str, Any]]:
"""Load JSONL file and return a list of dictionaries."""
with open(file_path, "r") as file:
return [json.loads(line) for line in file]
def evaluate_db(db, original_jsonl_path: str, k):
# Load the original JSONL data for queries and ground truth
original_data = load_jsonl(original_jsonl_path)
# Evaluate retrieval
results = evaluate_retrieval(original_data, retrieve_base, db, k)
print(f"Pass@{k}: {results['pass_at_n']:.2f}%")
print(f"Total Score: {results['average_score']}")
print(f"Total queries: {results['total_queries']}")
现在,您需要为下面的实验初始化这些模型。您可以使用 PyMilvus 模型库轻松切换到其他模型。
dense_ef = VoyageEmbeddingFunction(api_key="your-voyage-api-key", model_name="voyage-2")
sparse_ef = BGEM3EmbeddingFunction()
cohere_rf = CohereRerankFunction(api_key="your-cohere-api-key")
Fetching 30 files: 0%| | 0/30 [00:00<?, ?it/s]
path = "codebase_chunks.json"
with open(path, "r") as f:
dataset = json.load(f)
实验一:标准检索
标准检索只使用密集嵌入来检索相关文档。在本实验中,我们将使用 Pass@5 重现原始 repo 中的结果。
standard_retriever = MilvusContextualRetriever(
uri="standard.db", collection_name="standard", dense_embedding_function=dense_ef
)
standard_retriever.build_collection()
for doc in dataset:
doc_content = doc["content"]
for chunk in doc["chunks"]:
metadata = {
"doc_id": doc["doc_id"],
"original_uuid": doc["original_uuid"],
"chunk_id": chunk["chunk_id"],
"original_index": chunk["original_index"],
"content": chunk["content"],
}
chunk_content = chunk["content"]
standard_retriever.insert_data(chunk_content, metadata)
evaluate_db(standard_retriever, "evaluation_set.jsonl", 5)
Evaluating retrieval: 100%|██████████| 248/248 [01:29<00:00, 2.77it/s]
Pass@5: 80.92%
Total Score: 0.8091877880184332
Total queries: 248
实验二:混合检索
现在我们已经利用 Voyage 嵌入获得了可喜的结果,接下来我们将利用生成强大稀疏嵌入的 BGE-M3 模型来执行混合检索。密集检索和稀疏检索的结果将使用 "互斥等级融合"(RRF)方法结合起来,产生混合检索结果。
hybrid_retriever = MilvusContextualRetriever(
uri="hybrid.db",
collection_name="hybrid",
dense_embedding_function=dense_ef,
use_sparse=True,
sparse_embedding_function=sparse_ef,
)
hybrid_retriever.build_collection()
for doc in dataset:
doc_content = doc["content"]
for chunk in doc["chunks"]:
metadata = {
"doc_id": doc["doc_id"],
"original_uuid": doc["original_uuid"],
"chunk_id": chunk["chunk_id"],
"original_index": chunk["original_index"],
"content": chunk["content"],
}
chunk_content = chunk["content"]
hybrid_retriever.insert_data(chunk_content, metadata)
evaluate_db(hybrid_retriever, "evaluation_set.jsonl", 5)
Evaluating retrieval: 100%|██████████| 248/248 [02:09<00:00, 1.92it/s]
Pass@5: 84.69%
Total Score: 0.8469182027649771
Total queries: 248
实验三:上下文检索
混合检索效果有所改善,但如果采用上下文检索方法,效果还能进一步提高。为此,我们将使用 Anthropic 的语言模型,为每个语块预置来自整个文档的上下文。
anthropic_client = anthropic.Anthropic(
api_key="your-anthropic-api-key",
)
contextual_retriever = MilvusContextualRetriever(
uri="contextual.db",
collection_name="contextual",
dense_embedding_function=dense_ef,
use_sparse=True,
sparse_embedding_function=sparse_ef,
use_contextualize_embedding=True,
anthropic_client=anthropic_client,
)
contextual_retriever.build_collection()
for doc in dataset:
doc_content = doc["content"]
for chunk in doc["chunks"]:
metadata = {
"doc_id": doc["doc_id"],
"original_uuid": doc["original_uuid"],
"chunk_id": chunk["chunk_id"],
"original_index": chunk["original_index"],
"content": chunk["content"],
}
chunk_content = chunk["content"]
contextual_retriever.insert_contextualized_data(
doc_content, chunk_content, metadata
)
evaluate_db(contextual_retriever, "evaluation_set.jsonl", 5)
Evaluating retrieval: 100%|██████████| 248/248 [01:55<00:00, 2.15it/s]
Pass@5: 87.14%
Total Score: 0.8713517665130568
Total queries: 248
实验四:使用 Reranker 进行上下文检索
通过添加一个 Cohere Reranker,可以进一步改善结果。我们无需单独初始化一个带有 Reranker 的新检索器,只需简单配置现有检索器即可使用 Reranker,从而提高性能。
contextual_retriever.use_reranker = True
contextual_retriever.rerank_function = cohere_rf
evaluate_db(contextual_retriever, "evaluation_set.jsonl", 5)
Evaluating retrieval: 100%|██████████| 248/248 [02:02<00:00, 2.00it/s]
Pass@5: 90.91%
Total Score: 0.9090821812596005
Total queries: 248
我们已经展示了几种提高检索性能的方法。通过根据具体情况进行更多的临时设计,上下文检索在以低成本预处理文档方面展现出了巨大的潜力,从而打造出更好的 RAG 系统。