Desagregação Armazenamento/Computação
Seguindo o princípio da desagregação do plano de dados e do plano de controlo, o Milvus é composto por quatro camadas que são mutuamente independentes em termos de escalabilidade e de recuperação de desastres.
Camada de acesso
Composta por um grupo de proxies sem estado, a camada de acesso é a camada frontal do sistema e o ponto final para os utilizadores. Valida os pedidos dos clientes e reduz os resultados devolvidos:
- O proxy é, por si só, apátrida. Fornece um endereço de serviço unificado utilizando componentes de balanceamento de carga como o Nginx, o Kubernetes Ingress, o NodePort e o LVS.
- Como o Milvus utiliza uma arquitetura de processamento paralelo massivo (MPP), o proxy agrega e pós-processa os resultados intermédios antes de devolver os resultados finais ao cliente.
Serviço de coordenação
O serviço coordenador atribui tarefas aos nós de trabalho e funciona como o cérebro do sistema. As tarefas que assume incluem a gestão da topologia do cluster, o equilíbrio de carga, a geração de carimbos de data/hora, a declaração de dados e a gestão de dados.
Existem três tipos de coordenadores: coordenador de raiz (root coord), coordenador de dados (data coord) e coordenador de consulta (query coord).
Coordenador raiz (root coord)
O coordenador raiz trata os pedidos de linguagem de definição de dados (DDL) e de linguagem de controlo de dados (DCL), tais como criar ou eliminar colecções, partições ou índices, bem como gerir a emissão de TSO (timestamp Oracle) e de time ticker.
Coordenador de consultas (query coord)
O coordenador de consultas gere a topologia e o equilíbrio de carga para os nós de consulta, e a transferência de segmentos em crescimento para segmentos selados.
Coordenador de dados (data coord)
O coordenador de dados gere a topologia dos nós de dados e dos nós de índice, mantém os metadados e desencadeia as operações de descarga, compactação e construção de índices e outras operações de dados em segundo plano.
Nós de trabalho
Os nós de trabalho são executores "burros" que seguem as instruções do serviço de coordenação e executam comandos de linguagem de manipulação de dados (DML) a partir do proxy. Os nós de trabalho não têm estado graças à separação do armazenamento e da computação e podem facilitar a expansão do sistema e a recuperação de desastres quando implantados no Kubernetes. Há três tipos de nós de trabalho:
Nó de consulta
Os nós de consulta recuperam dados de registo incrementais e transformam-nos em segmentos crescentes, subscrevendo o corretor de registo, carregam dados históricos do armazenamento de objectos e executam uma pesquisa híbrida entre dados vectoriais e escalares.
Nó de dados
Os nós de dados recuperam dados de registo incrementais subscrevendo o corretor de registos, processam pedidos de mutação e empacotam dados de registo em instantâneos de registo e armazenam-nos no armazenamento de objectos.
Nó de índice
Os nós de índice criam índices. Eles não precisam ser residentes na memória e podem ser implementados com a estrutura sem servidor.
Armazenamento
O armazenamento é o osso do sistema, responsável pela persistência dos dados. É composto por meta storage, log broker e object storage.
Meta-armazenamento
O meta-armazenamento armazena instantâneos de metadados, como o esquema de coleção e os pontos de verificação do consumo de mensagens. O armazenamento de metadados exige uma disponibilidade extremamente elevada, uma forte consistência e suporte de transacções, pelo que o Milvus escolheu o etcd para este fim. A Milvus também utiliza o etcd para registo de serviços e verificações de saúde.
Armazenamento de objectos
O armazenamento de objectos armazena ficheiros de instantâneos de registos, ficheiros de índice para dados escalares e vectoriais e resultados de consultas intermédias. O Milvus utiliza o MinIO como armazenamento de objectos e pode ser facilmente implementado no AWS S3 e no Azure Blob, dois dos serviços de armazenamento mais populares e económicos do mundo. No entanto, o armazenamento de objectos tem uma latência de acesso elevada e cobra pelo número de consultas. Para melhorar o seu desempenho e reduzir os custos, a Milvus planeia implementar a separação de dados cold-hot num conjunto de cache baseado em memória ou SSD.
Corretor de registos
O corretor de registos é um sistema pub-sub que suporta a reprodução. É responsável pela persistência de dados de streaming e pela notificação de eventos. Ele também garante a integridade dos dados incrementais quando os nós de trabalho se recuperam de uma falha no sistema. O Milvus Distributed utiliza o Pulsar como corretor de registos, enquanto o Milvus Standalone utiliza o RocksDB. O corretor de logs pode ser prontamente substituído por plataformas de armazenamento de dados de streaming, como o Kafka.
O Milvus segue o princípio do "registo como dados", pelo que não mantém uma tabela física, mas garante a fiabilidade dos dados através da persistência do registo e de registos instantâneos.
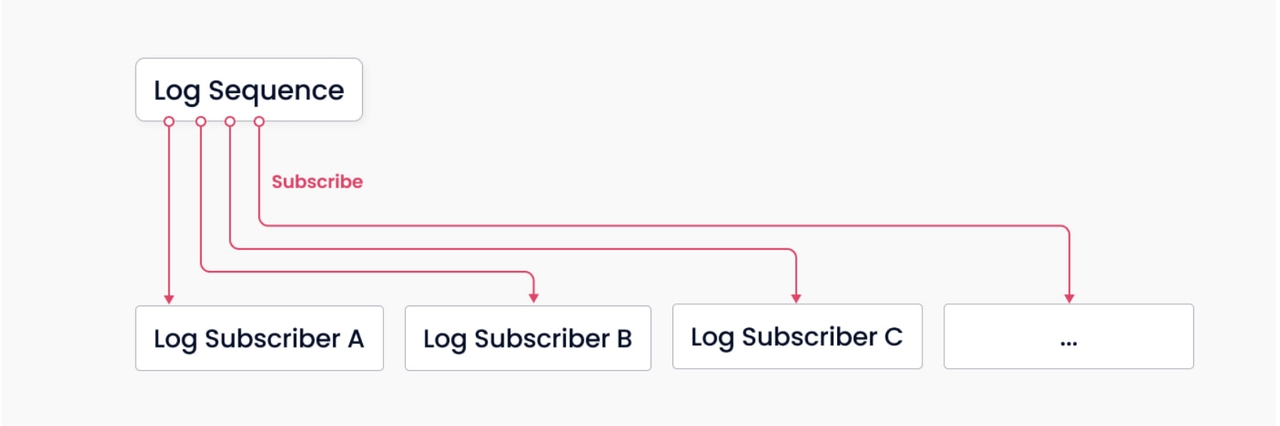 Mecanismo de registo
Mecanismo de registo
O corretor de registos é a espinha dorsal do Milvus. É responsável pela persistência dos dados e pela desagregação da leitura-escrita, graças ao seu mecanismo inato de pub-sub. A ilustração acima mostra uma representação simplificada do mecanismo, em que o sistema está dividido em duas funções, o corretor de registos (para manter a sequência de registos) e o assinante de registos. O primeiro regista todas as operações que alteram os estados da coleção; o segundo subscreve a sequência de registos para atualizar os dados locais e fornece serviços sob a forma de cópias só de leitura. O mecanismo pub-sub também abre espaço para a extensibilidade do sistema em termos de captura de dados de alteração (CDC) e implementação globalmente distribuída.
O que vem a seguir
- Leia Componentes principais para obter mais detalhes sobre a arquitetura Milvus.